Hello Vih,
We’re sorry for the trouble you had with Adobe Reader, are you getting this error message with all the PDF files or with one specific PDF file?
If it is specific to one PDF file, then it seems that the PDF is corrupt or damaged.
Make sure that you have the latest version of Adobe Reader installed, check for any pending updates of Adobe Reader from help>check for updates, reboot the machine after updating Adobe Reader and check.
If you have the latest version of Adobe Reader installed, please navigate to Adobe Reader’s Preferences from Edit>Preferences>Security(Enhanced)>disable «Enable Protected Mode at Startup» and «Enable Enhanced Security».
Note: Disabling the Protected Mode and Enhanced Security is only for testing purpose, please enable it back.
Is it a Mac or Windows machine and what is the version of the OS installed?
What is the dot version of Adobe Reader installed? To identify, refer to Identify the product and its version for Acrobat and Reader DC
let us know how it goes and share your observation.
Thanks,
Anand Sri.
Как исправить ошибку Adobe Reader 14 в Windows 10
Ошибка Adobe Reader 14 – это сообщение об ошибке, которое появляется у некоторых пользователей при попытке открыть документы PDF. Полное сообщение об ошибке гласит: При открытии этого документа произошла ошибка. При чтении этого документа возникла проблема (14).
Следовательно, пользователи не могут открывать PDF-файлы в AR, когда появляется это сообщение об ошибке. Вот несколько решений, которые могут исправить ошибку Adobe Reader 14.
Решено: ошибка Adobe Acrobat Reader 14
1. Обновите Adobe Reader
Ошибка Adobe Reader 14 часто возникает из-за устаревшего программного обеспечения Adobe. Документы PDF, созданные с использованием новейшего программного обеспечения Adobe, не всегда открываются в более ранних версиях AR. Таким образом, обновление программного обеспечения AR до последней версии, вероятно, решит проблему, если появятся доступные обновления.
Вы можете проверить наличие обновлений, открыв Adobe Reader и нажав Справка > Проверить обновления . Это откроет окно обновления, из которого вы можете обновить программное обеспечение. Вы также можете получить самую последнюю версию AR, нажав Установить сейчас на этой веб-странице.
- СВЯЗАННЫЕ: ИСПРАВЛЕНИЕ: не удается установить Adobe Reader на ПК с Windows
2. Восстановите PDF-файл
Сообщение об ошибке Adobe Reader 14 также может появиться, если файл PDF каким-либо образом поврежден. Таким образом, вам может понадобиться восстановить файл, чтобы открыть его. Вы можете восстановить PDF документы с помощью программного обеспечения DataNumen PDF. Кроме того, следуйте приведенным ниже инструкциям, чтобы восстановить документ PDF с помощью PDFaid.com.
- Сначала нажмите здесь, чтобы открыть веб-утилиту PDFaid.com в вашем браузере.

- Нажмите кнопку Выберите файл PDF на этой странице.
- Затем выберите документ, который не открывается в Adobe Reader.
- Вы можете ввести некоторые дополнительные свойства PDF в текстовые поля.
- Нажмите Восстановить PDF , чтобы восстановить документ.
- Затем нажмите Загрузить PDF , чтобы сохранить восстановленный документ.
3. Извлечение страниц из PDF
Некоторые пользователи подтвердили, что извлечение страниц из документов PDF может исправить ошибку Adobe Reader 14. Затем вам нужно будет открыть страницы отдельно в Adobe Reader после их извлечения. Вот как вы можете извлечь страницы из PDF-файлов с помощью Sejda PDF Extractor.
- Нажмите здесь, чтобы открыть Sejda PDF Extractor в браузере.

- Нажмите кнопку Загрузить файлы PDF , чтобы выбрать документ на жестком диске.
- Или вы можете нажать на маленькую стрелку, чтобы выбрать файл из Google Drive или Dropbox.
- Затем выберите страницы для извлечения из документа, щелкнув по их миниатюрным изображениям.

- Нажмите кнопку Извлечь страницы .
- Затем откроется окно, из которого вы можете нажать Загрузить , чтобы сохранить извлеченный PDF-файл.

- СВЯЗАННЫЕ: полное исправление: ошибка Adobe 16 в Windows 10, 8.1, 7
4. Откройте PDF с альтернативным программным обеспечением
Это разрешение может быть не совсем исправлено, но существует множество альтернатив Adobe Reader. Документ может открыться нормально в альтернативном программном обеспечении PDF и браузерах, таких как Edge. Foxit Reader – это бесплатная альтернатива, с которой вы можете открывать PDF документы. Нажмите кнопку Free Foxit Reader на этой веб-странице, чтобы проверить это.
Универсальное программное обеспечение для открытия файлов (НЛО) также открывает широкий спектр файлов. Таким образом, универсальный просмотрщик файлов может также открыть документ PDF, который нельзя открыть в AR. Это руководство по программному обеспечению содержит дополнительную информацию о НЛО.
Некоторые из этих разрешений, вероятно, исправят ошибку Adobe Reader 14, чтобы вы могли открыть PDF. Некоторые из советов в этой статье могут также исправить документы PDF, которые не открываются в программном обеспечении Adobe.
Я работаю над захватом вызовов postscript к show и сохранением текущего шрифта и размера шрифта для вывода в текстовых объектах pdf.
Но identify выдает ошибку:
И вывод ghostscript не дает мне подробностей, необходимых для понимания проблемы:
Может ли кто-нибудь помочь мне понять, в чем проблема с файлом pdf, который я печатаю?
1 ответ
В PDF-файле есть ряд ошибок. В зависимости от рассматриваемого средства просмотра PDF требуется исправить меньшее или большее их подмножество, чтобы разрешить отображение PDF должным образом.
Потоки содержимого страницы
Содержимое потоков содержимого страницы выглядит так:
Ошибка здесь в инструкции по выбору шрифта:
Операнд имени шрифта F1 задается не как объект имени PDF (распознается по ведущей косой черте), а как некоторый общий литерал, обычно зарезервированный для операторов инструкций.
(Кстати, эти структуры потока контента излишне раздуты, большинство отдельных текстовых объектов рисуют от одного до трех глифов и имеют (всегда идентичные) собственные инструкции по выбору шрифта. Это не ошибка как таковая, но совершенно ненужная)
Кроме того, как уже указывалось в @ usr2564301, длина потока, похоже, уменьшилась на 1.
Ресурсы шрифтов
Ресурсы шрифтов выглядят так:
Прежде всего, проблема в том, что там: как уже указывалось в @KenS, правильное написание — Подтип , а не Подтип .
Есть еще одна проблема в том, чего там нет : поэтому словари ресурсов коротких шрифтов до PDF 1.7 были разрешены только для стандартных 14 шрифтов, а для PDF 2.0 больше не разрешены. Поскольку Palatino-Roman явно не является стандартным 14 шрифтом, ресурс в любом случае неполный.
Согласно Таблице 109 — Записи в словаре шрифтов Типа 1 в ISO 32000-2,
- Тип , Подтип и BaseFont являются обязательными ,
- FirstChar , LastChar , Ширина и FontDescriptor являются обязательными, но в PDF 1.0–1.7 необязательны для стандартные 14 шрифтов ,
- Имяобязательно в PDF 1.0, необязательно в PDF 1.1–1.7, не рекомендуется в PDF 2.0 и
- Кодировка и ToUnicode всегда Необязательны .
В зависимости от используемой вами программы просмотра PDF-файлов требования, вероятно, будут казаться более мягкими, но любой обработчик PDF-файлов может обоснованно отклонить ваши PDF-файлы, если вы не выполните требования спецификации.
Перекрестные ссылки
@ usr2564301 также упоминает, что многие записи таблицы перекрестных ссылок (а также ссылка на начало самой таблицы перекрестных ссылок) отключены на 1.
На самом деле они указывают не на литерал номер объекта / xref , а на пробел перед ним. Поскольку перед числом / литералом следует игнорировать только пробелы, многие обработчики PDF этого не заметят.
3 способа как восстановить поврежденный PDF файл
Как восстановить неисправный документ Adobe Acrobat / Adobe Reader
Документы формата Adobe Reader / Acrobat с расширением *.pdf являются наиболее распространенными на текущий момент. Документ Acrobat, как и любой иной файл, может быть поврежден. Например, при попытке открыть документ с помощью Acrobat или Reader могут появиться различные сообщения об ошибках. Как результат документ прочитать не удается.
Наиболее частой причиной возникновения таких ошибок являет некорректная работа различного программного обеспечения: браузеров, почтовых программ, операционной системы, антивируса, firewall’ов и прочего.
Простые способы решения этой проблемы:
- скачать документ из первоисточника заново
- восстановить копию документа из резервной копии
- восстановить предыдущую версию файла с документом
Если этими способами исправить файл с документом не получается, то компания Adobe, к сожалению, не приводит точного руководства для исправления PDF файлов. Изучение форума https://forums.adobe.com/ не дает прямого ответа, но специалисты предлагают следующие варианты восстановления неисправных *.PDF файлов:
- Извлечение текста из *.PDF файла вручную
- Восстановление неисправного PDF файла с помощью специального онлайн-сервиса
- Восстановление некорректного PDF файла с помощью специальной утилиты
Необходимо последовательно попробовать каждый из этих вариантов восстановления некорректных PDF файлов.
Извлечение текста из *.PDF файла вручную
Если важно и достаточно восстановить только текст из поврежденного PDF файла, то воспользуйтесь каким-либо удобным текстовым редактором, например Notepad++ и откройте с помощью него поврежденный документ. Вы увидите смесь кода Post Script, текста и наборов нечитаемых символов, как в фильме «Матрица». Потом необходимо визуально выделять блоки с текстом в файле и копировать эти блоки в новый текстовый файл. Это будет долгая и кропотливая работа которая позволит извлечь текст из документа Acrobat. Табличные данные, графика и форматирование текста в этом случае восстановить не удастся.
Восстановление неисправного PDF файла с помощью специального онлайн-сервиса
Самый простой, удобный и доступный по цене сервис онлайн-восстановления PDF файлов размещается тут: https://onlinefilerepair.com/ru/pdf
От клиента сервиса требуется:
- выбрать один *.PDF файл, загружаемый на сервис.
- ввести адрес email.
- ввести с картинки символы captcha.
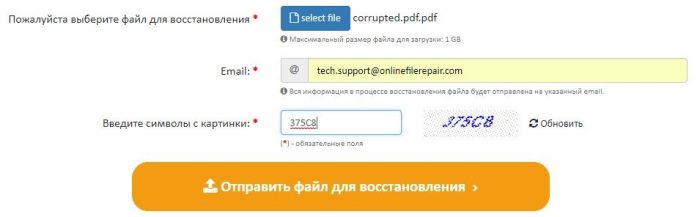
После нажатия на ссылку «Отправить файл для восстановления» браузер передаст выбранный файл на онлайн-сервис. Сервис начнет анализ и обработку закачанного файла Acrobat немедленно. Если документ Acrobat удалось отремонтировать, то будут представлены скриншоты восстановленных страниц, размеры исходного и конечного файла:
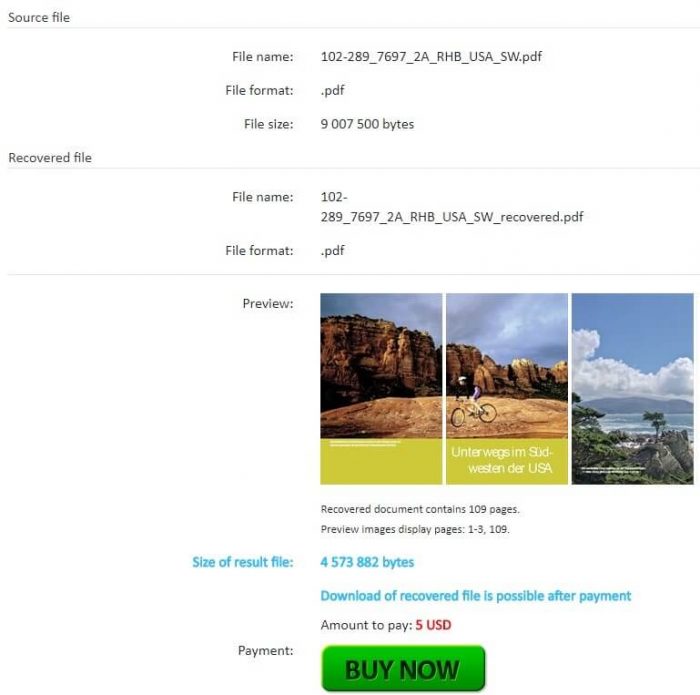
После оплаты $5 за файл размером до 100Мб пользователь получает ссылку на скачивание восстановленного PDF документа Adobe Acrobat / Adobe Reader.
Сервис универсален и работает со всеми операционными системами (Windows, MacOS, iOS, Android) и со всеми видами устройств (компьютер, планшет, телефон).
Восстановление некорректного PDF файла с помощью специальной утилиты
Наиболее распространенной и известной утилитой, предназначенной для лечения неисправных документов Acrobat/Reader, является Recovery Toolbox for PDF (https://pdf.recoverytoolbox.com/ru/). Программная утилита может работать только в операционной системе Windows и стоит от $27. Количество, а также размеры восстанавливаемых файлов не ограничены. У программы нет предварительного просмотра страниц из исправленного PDF документа. В ДЕМО режиме возможно сохранение на диск всего несколько страниц из большого документа Adobe Reader.
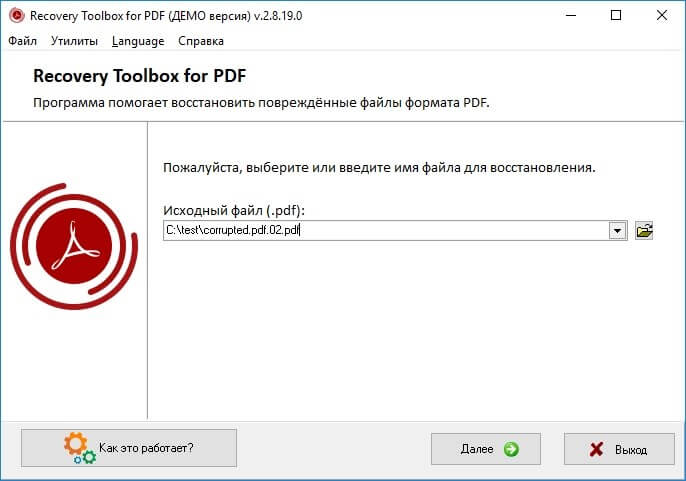
Работа с Recovery Toolbox for PDF очень проста и понятна, так как это обычный пошаговый помощник. Требуется только:
- Ввести некорректный *.pdf файл на диске
- Ввести имя нового PDF файла, куда будут сохранены восстановленные страницы
- Выбрать версию нового PDF файла из списка
Примечание: Recovery Toolbox for PDF работает только на компьютерах с Windows.
Наиболее универсальный способ восстановления любого документа Acrobat это онлайн-сервис https://onlinefilerepair.com/ru/pdf. Если поврежденный документ нельзя передавать третьим лицам или у вас много некорректных документов для исправления, то Recovery Toolbox for PDF будет более оптимальным решением.
Примечание: PDF (Portable Document Format) вероятно наиболее массовый формат для документа т.к. он поддерживается всеми ОС, более безопасный, файл документа Acrobat трудно изменить, а также файл Acrobat документа можно защитить паролем и водяными знаками.
Проблема
При попытке просмотра документов в Adobe Reader или Acrobat появляется сообщение об ошибке «Возникла проблема при чтении этого документа (131)». Вы использовали Adobe ReaderExtensions для применения прав использования PDF-документов при активированном параметре «Полное сохранение».
Иногда указанному выше сообщению об ошибке предшествует следующее сообщение:
«Ошибка на этой странице. Возможно, ее невозможно правильно отобразить в Acrobat. Чтобы устранить проблему, обратитесь к создателю PDF-документа».
Решение
Отключите параметр «Полное сохранение» с помощью инструмента ReaderExtensions и примените права снова. После отключения этого параметра в PDF-файле включается функция пошагового сохранения. Из-за функции пошагового сохранения размер файла несколько увеличивается, а файл сохраняется в Acrobat или Reader быстрее и без повреждений. Если вы для применения прав используете не онлайн-интерфейс, а API, можно включить пошаговое сохранение с помощью объекта PDFUtilitySaveMode. Дополнительная информация об приведена по ссылке
http://help.adobe.com/ru_RU/livecycle/9.0/programLC/help/index.htm?content=001005.html
Дополнительная информация
В следующем выпуске компания Adobe планирует разрешить эту проблему с полным сохранением в ReaderExtensions. Для LiveCycle ES2 SP2 доступно исправление, так что если оно вам нужно, обратитесь в службу поддержки Enterprise.

Как исправить ошибку 1722 при установке Acrobat Reader
Fix Adobe Acrobat internal error (2023 updated)
Adobe Reader — update failed — error 1722 — error 150210
Произошла ошибка при открытии данного документа Отказано в доступе Adobe Reader PDF
ошибка с Adobe Reader, как
invalid plugin detected adobe reader will quit~How to Fix PDF Reader Not Working In Windows 10/8.1/7
How to fix
Acrobat Reader DC Save option error
Новые материалы:
- Как удалить adobe reader 11
- Аналог adobe reader linux
- Сколько стоит подписка на adobe reader
- Как сделать масштаб по умолчанию в adobe reader
- Как сделать рамку в adobe acrobat
- Как откатить обновление adobe reader
- Как adobe acrobat перевести в пдф
- Как сделать масштаб по умолчанию в adobe reader
- Где купить adobe acrobat
- Как установить adobe reader на windows 10
- Где лежат шрифты adobe acrobat
Я работаю над захватом вызовов postscript к show и сохранением текущего шрифта и размера шрифта для вывода в текстовых объектах pdf.
Программа ввода Postscript
Но identify выдает ошибку:
$ identify pd0.pdf
**** Error reading a content stream. The page may be incomplete.
**** File did not complete the page properly and may be damaged.
**** Error reading a content stream. The page may be incomplete.
**** File did not complete the page properly and may be damaged.
**** Error reading a content stream. The page may be incomplete.
**** File did not complete the page properly and may be damaged.
**** This file had errors that were repaired or ignored.
**** Please notify the author of the software that produced this
**** file that it does not conform to Adobe's published PDF
**** specification.
pd0.pdf[0] PBM 612x792 612x792+0+0 16-bit Bilevel Gray 61KB 0.000u 0:00.000
pd0.pdf[1] PBM 612x792 612x792+0+0 16-bit Bilevel Gray 61KB 0.000u 0:00.000
pd0.pdf[2] PBM 612x792 612x792+0+0 16-bit Bilevel Gray 61KB 0.000u 0:00.000
И вывод ghostscript не дает мне подробностей, необходимых для понимания проблемы:
$ gsnd -dPDFDEBUG pd0.pdf
GPL Ghostscript 9.18 (2015-10-05)
Copyright (C) 2015 Artifex Software, Inc. All rights reserved.
This software comes with NO WARRANTY: see the file PUBLIC for details.
<<
/Root 1 0 R
/Size 12 >>
%Resolving: [1 0]
<<
/Type /Catalog /Pages 2 0 R
>>
endobj
%Resolving: [2 0]
<<
/Kids [
3 0 R
6 0 R
9 0 R
]
/Type /Pages /Count 3 >>
endobj
%Resolving: [3 0]
<<
/Parent 2 0 R
/Contents [
5 0 R
]
/MediaBox [
0.0 0.0 612.0 792.0 ]
/Resources <<
/Font <<
/F1 4 0 R
>>
/ProcSet [
/PDF /Text ]
>>
/Type /Page >>
endobj
%Resolving: [6 0]
<<
/Parent 2 0 R
/Contents [
8 0 R
]
/MediaBox [
0.0 0.0 612.0 792.0 ]
/Resources <<
/Font <<
/F2 7 0 R
>>
/ProcSet [
/PDF /Text ]
>>
/Type /Page >>
endobj
%Resolving: [9 0]
<<
/Parent 2 0 R
/Contents [
11 0 R
]
/MediaBox [
0.0 0.0 612.0 792.0 ]
/Resources <<
/Font <<
/F3 10 0 R
>>
/ProcSet [
/PDF /Text ]
>>
/Type /Page >>
endobj
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [1 0]
%Resolving: [1 0]
%Resolving: [1 0]
%Resolving: [1 0]
%Resolving: [2 0]
Processing pages 1 through 3.
Page 1
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [3 0]
%Resolving: [3 0]
%Resolving: [3 0]
%Resolving: [3 0]
%Resolving: [3 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [5 0]
<<
/Length 15660 >>
stream
%FilePosition: 471
endobj
BT
F1
10.0 Tf
%Resolving: [4 0]
<<
/Type /Font /SubType /Type1 /BaseFont /Palatino-Roman >>
endobj
**** Error reading a content stream. The page may be incomplete.
**** File did not complete the page properly and may be damaged.
Page 2
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [3 0]
%Resolving: [6 0]
%Resolving: [6 0]
%Resolving: [6 0]
%Resolving: [6 0]
%Resolving: [6 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [8 0]
<<
/Length 31667 >>
stream
%FilePosition: 16474
endobj
BT
F2
10.0 Tf
%Resolving: [7 0]
<<
/Type /Font /SubType /Type1 /BaseFont /Palatino-Roman >>
endobj
**** Error reading a content stream. The page may be incomplete.
**** File did not complete the page properly and may be damaged.
Page 3
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [3 0]
%Resolving: [6 0]
%Resolving: [9 0]
%Resolving: [9 0]
%Resolving: [9 0]
%Resolving: [9 0]
%Resolving: [9 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [1 0]
%Resolving: [2 0]
%Resolving: [11 0]
<<
/Length 8335 >>
stream
%FilePosition: 48487
endobj
BT
F3
10.0 Tf
%Resolving: [10 0]
<<
/Type /Font /SubType /Type1 /BaseFont /Palatino-Roman >>
endobj
**** Error reading a content stream. The page may be incomplete.
**** File did not complete the page properly and may be damaged.
**** This file had errors that were repaired or ignored.
**** Please notify the author of the software that produced this
**** file that it does not conform to Adobe's published PDF
**** specification.
GS>
Может ли кто-нибудь помочь мне понять, в чем проблема с файлом pdf, который я печатаю?
1 ответ
Лучший ответ
В PDF-файле есть ряд ошибок. В зависимости от рассматриваемого средства просмотра PDF требуется исправить меньшее или большее их подмножество, чтобы разрешить отображение PDF должным образом.
Потоки содержимого страницы
Содержимое потоков содержимого страницы выглядит так:
BT F1 10.0 Tf 30.0 750.0 Td (<< ) Tj ET BT F1 10.0 Tf 50.0 738.0 Td (/) Tj ET [...]
Ошибка здесь в инструкции по выбору шрифта:
F1 10.0 Tf
Операнд имени шрифта F1 задается не как объект имени PDF (распознается по ведущей косой черте), а как некоторый общий литерал, обычно зарезервированный для операторов инструкций.
(Кстати, эти структуры потока контента излишне раздуты, большинство отдельных текстовых объектов рисуют от одного до трех глифов и имеют (всегда идентичные) собственные инструкции по выбору шрифта. Это не ошибка как таковая, но совершенно ненужная)
Кроме того, как уже указывалось в @ usr2564301, длина потока, похоже, уменьшилась на 1.
Ресурсы шрифтов
Ресурсы шрифтов выглядят так:
<<
/Type /Font
/SubType /Type1
/BaseFont /Palatino-Roman
>>
Прежде всего, проблема в том, что там: как уже указывалось в @KenS, правильное написание — Подтип , а не Подтип .
Есть еще одна проблема в том, чего там нет : поэтому словари ресурсов коротких шрифтов до PDF 1.7 были разрешены только для стандартных 14 шрифтов, а для PDF 2.0 больше не разрешены. Поскольку Palatino-Roman явно не является стандартным 14 шрифтом, ресурс в любом случае неполный.
Согласно Таблице 109 — Записи в словаре шрифтов Типа 1 в ISO 32000-2,
- Тип , Подтип и BaseFont являются обязательными ,
- FirstChar , LastChar , Ширина и FontDescriptor являются обязательными, но в PDF 1.0–1.7 необязательны для стандартные 14 шрифтов ,
- Имя обязательно в PDF 1.0, необязательно в PDF 1.1–1.7, не рекомендуется в PDF 2.0 и
- Кодировка и ToUnicode всегда Необязательны .
В зависимости от используемой вами программы просмотра PDF-файлов требования, вероятно, будут казаться более мягкими, но любой обработчик PDF-файлов может обоснованно отклонить ваши PDF-файлы, если вы не выполните требования спецификации.
Перекрестные ссылки
@ usr2564301 также упоминает, что многие записи таблицы перекрестных ссылок (а также ссылка на начало самой таблицы перекрестных ссылок) отключены на 1.
На самом деле они указывают не на литерал номер объекта / xref , а на пробел перед ним. Поскольку перед числом / литералом следует игнорировать только пробелы, многие обработчики PDF этого не заметят.
4
Community
20 Июн 2020 в 12:12