In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of 



In other words, the MSE is the mean 

In matrix notation,

where 



The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as statistical learning, the MSE is often called the test MSE,[4] and is computed as

Estimator[edit]
The MSE of an estimator 

![{displaystyle operatorname {MSE} ({hat {theta }})=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a0e1b3bac58f9ba2d2f4ff8b85b2e35a8f4bf78)
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]

Proof of variance and bias relationship[edit]
![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right]&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]+operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}+2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+operatorname {E} _{theta }left[2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)right]+operatorname {E} _{theta }left[left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)operatorname {E} _{theta }left[{hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]-theta ={text{const.}}&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)left(operatorname {E} _{theta }[{hat {theta }}]-operatorname {E} _{theta }[{hat {theta }}]right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]={text{const.}}&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&=operatorname {Var} _{theta }({hat {theta }})+operatorname {Bias} _{theta }({hat {theta }},theta )^{2}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac524a751828f971013e1297a33ca1cc4c38cd6)
An even shorter proof can be achieved using the well-known formula that for a random variable 


![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=mathbb {E} [({hat {theta }}-theta )^{2}]&=operatorname {Var} ({hat {theta }}-theta )+(mathbb {E} [{hat {theta }}-theta ])^{2}&=operatorname {Var} ({hat {theta }})+operatorname {Bias} ^{2}({hat {theta }})end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/864646cf4426e2b62a3caf9460382eec1a77fe4e)
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size 


which has an expected value equal to the true mean
![{displaystyle operatorname {MSE} left({overline {X}}right)=operatorname {E} left[left({overline {X}}-mu right)^{2}right]=left({frac {sigma }{sqrt {n}}}right)^{2}={frac {sigma ^{2}}{n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4647a2cc4c8f9a4c90b628faad2dcf80c4aae84)
where 
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:

This is unbiased (its expected value is

where 

However, one can use other estimators for 

then we calculate:
![{displaystyle {begin{aligned}operatorname {MSE} (S_{a}^{2})&=operatorname {E} left[left({frac {n-1}{a}}S_{n-1}^{2}-sigma ^{2}right)^{2}right]&=operatorname {E} left[{frac {(n-1)^{2}}{a^{2}}}S_{n-1}^{4}-2left({frac {n-1}{a}}S_{n-1}^{2}right)sigma ^{2}+sigma ^{4}right]&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)operatorname {E} left[S_{n-1}^{2}right]sigma ^{2}+sigma ^{4}&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{2}right]=sigma ^{2}&={frac {(n-1)^{2}}{a^{2}}}left({frac {gamma _{2}}{n}}+{frac {n+1}{n-1}}right)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{4}right]=operatorname {MSE} (S_{n-1}^{2})+sigma ^{4}&={frac {n-1}{na^{2}}}left((n-1)gamma _{2}+n^{2}+nright)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf22322412b8454c706d78671e5d94208675a6e0)
This is minimized when

For a Gaussian distribution, where 



Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be 
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
 |
= the unbiased estimator of the population mean,  |

|
 |
= the unbiased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
Interpretation[edit]
An MSE of zero, meaning that the estimator
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.
In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of
In other words, the MSE is the mean
In matrix notation,
where
The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as statistical learning, the MSE is often called the test MSE,[4] and is computed as
Estimator[edit]
The MSE of an estimator
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]
Proof of variance and bias relationship[edit]
An even shorter proof can be achieved using the well-known formula that for a random variable
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size
which has an expected value equal to the true mean
where
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:
This is unbiased (its expected value is
where
However, one can use other estimators for
then we calculate:
This is minimized when
For a Gaussian distribution, where
Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
|
= the unbiased estimator of the population mean, |
|
|
= the unbiased estimator of the population variance, |
|
|
= the biased estimator of the population variance, |
|
|
= the biased estimator of the population variance, |
|
Interpretation[edit]
An MSE of zero, meaning that the estimator
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.
Материал из MachineLearning.
Перейти к: навигация, поиск
Содержание
- 1 Введение
- 1.1 Постановка вопроса. Виды погрешностей
- 2 Виды мер точности
- 3 Предельные погрешности
- 4 Погрешности округлений при представлении чисел в компьютере
- 5 Погрешности арифметических операций
- 6 Погрешности вычисления функций
- 7 Числовые примеры
- 8 Список литературы
- 9 См. также
Введение
Постановка вопроса. Виды погрешностей
Процесс исследования исходного объекта методом математического моделирования и вычислительного эксперимента неизбежно носит приближенный характер, так как на каждом этапе вносятся погрешности. Построение математической модели связано с упрощением исходного явления, недостаточно точным заданием коэффициентов уравнения и других входных данных. По отношению к численному методу, реализующему данную математическую модель, указанные погрешности являются неустранимыми, поскольку они неизбежны в рамках данной модели.
При переходе от математической модели к численному методу возникают погрешности, называемые погрешностями метода. Они связаны с тем, что всякий численный метод воспроизводит исходную математическую модель приближенно. Наиболее типичными погрешностями метода являются погрешность дискретизации и погрешность округления.
При построении численного метода в качестве аналога исходной математической задачи обычно рассматривается её дискретная модель. Разность решений дискретизированной задачи и исходной называется погрешностью дискретизации. Обычно дискретная модель зависит от некоторого параметра (или их множества) дискретизации, при стремлении которого к нулю должна стремиться к нулю и погрешность дискретизации.
Дискретная модель представляет собой систему большого числа алгебраических уравнений. Для её решения используется тот или иной численный алгоритм. Входные данные этой системы, а именно коэффициенты и правые части, задаются в ЭВМ не точно, а с округлением. В процессе работы алгоритма погрешности округления обычно накапливаются, и в результате, решение, полученное на ЭВМ, будет отличаться от точного решения дискретизированной задачи. Результирующая погрешность называется погрешностью округления (вычислительной погрешностью). Величина этой погрешности определяется двумя факторами: точностью представления вещественных чисел в ЭВМ и чувствительностью данного алгоритма к погрешностям округления.
Итак, следует различать погрешности модели, дискретизации и округления. В вопросе преобладания какой-либо погрешности ответ неоднозначен. В общем случае нужно стремиться, чтобы все погрешности имели один и тот же порядок. Например, нецелесообразно пользоваться разностными схемами, имеющими точность 10−6, если коэффициенты исходных уравнений задаются с точностью 10−2.
Виды мер точности
Мерой точности вычислений являются абсолютные и относительные погрешности. Абсолютная погрешность определяется формулой
где – приближение к точному значению
.
Относительная погрешность определяется формулой
Относительная погрешность часто выражается в процентах. Абсолютная и относительная погрешности тесно связаны с понятием верных значащих цифр. Значащими цифрами числа называют все цифры в его записи, начиная с первой ненулевой цифры слева. Например, число 0,000129 имеет три значащих цифры. Значащая цифра называется верной, если абсолютная погрешность числа не превышает половины веса разряда, соответствующего этой цифре. Например, , абсолютная погрешность
. Записывая число в виде
имеем , следовательно, число имеет две верных значащих цифр (9 и 3).
В общем случае абсолютная погрешность должна удовлетворять следующему неравенству:
где — порядок (вес) старшей цифры,
— количество верных значащих цифр.
В рассматриваемом примере .
Относительная погрешность связана с количеством верных цифр приближенного числа соотношением:
где — старшая значащая цифра числа.
Для двоичного представления чисел имеем .
Тот факт, что число является приближенным значением числа
с абсолютной погрешностью
, записывают в виде
причем числа и
записываются с одинаковым количеством знаков после запятой, например,
или
.
Запись вида
означает, что число является приближенным значение числа
с относительной погрешностью
.
Так как точное решение задачи как правило неизвестно, то погрешности приходится оценивать через исходные данные и особенности алгоритма. Если оценка может быть вычислена до решения задачи, то она называется априорной. Если оценка вычисляется после получения приближенного решения задачи, то она называется апостериорной.
Очень часто степень точности решения задачи характеризуется некоторыми косвенными вспомогательными величинами. Например точность решения системы алгебраических уравнений
характеризуется невязкой
где — приближенное решение системы.
Причём невязка достаточно сложным образом связана с погрешностью решения , причём если невязка мала, то погрешность может быть значительной.
Предельные погрешности
Пусть искомая величина является функцией параметров
— приближенное значение
. Тогда предельной абсолютной погрешностью называется величина
Предельной относительной погрешностью называется величина .
Пусть — приближенное значение
. Предполагаем, что
— непрерывно дифференцируемая функция своих аргументов. Тогда, по формуле Лагранжа,
где .
Отсюда
где .
Можно показать, что при малых эта оценка не может быть существенно улучшена. На практике иногда пользуются грубой (линейной) оценкой
где .
Несложно показать, что:
— предельная погрешность суммы или разности равна сумме предельных погрешностей.
— предельная относительная погрешность произведения или частного приближенного равна сумме предельных относительных погрешностей.
Погрешности округлений при представлении чисел в компьютере
Одним из основных источников вычислительных погрешностей является приближенное представление чисел в компьютере, обусловленное конечностью разрядной сетки (см. Международный стандарт представления чисел с плавающей точкой в ЭВМ). Число , не представимое в компьютере, подвергается округлению, т. е. заменяется близким числом
, представимым в компьютере точно.
Найдем границу относительной погрешности представления числа с плавающей точкой. Допустим, что применяется простейшее округление – отбрасывание всех разрядов числа, выходящих за пределы разрядной сетки. Система счисления – двоичная. Пусть надо записать число, представляющее бесконечную двоичную дробь
где ,
— цифры мантиссы.
Пусть под запись мантиссы отводится t двоичных разрядов. Отбрасывая лишние разряды, получим округлённое число
Абсолютная погрешность округления в этом случае равна
Наибольшая погрешность будет в случае , тогда
Т.к. , где
— мантисса числа
, то всегда
. Тогда
и относительная погрешность равна
. Практически применяют более точные методы округления и погрешность представления чисел равна
( 1 )
т.е. точность представления чисел определяется разрядностью мантиссы .
Тогда приближенно представленное в компьютере число можно записать в виде , где
– «машинный эпсилон» – относительная погрешность представления чисел.
Погрешности арифметических операций
При вычислениях с плавающей точкой операция округления может потребоваться после выполнения любой из арифметических операций. Так умножение или деление двух чисел сводится к умножению или делению мантисс. Так как в общем случае количество разрядов мантисс произведений и частных больше допустимой разрядности мантиссы, то требуется округление мантиссы результатов. При сложении или вычитании чисел с плавающей точкой операнды должны быть предварительно приведены к одному порядку, что осуществляется сдвигом вправо мантиссы числа, имеющего меньший порядок, и увеличением в соответствующее число раз порядка этого числа. Сдвиг мантиссы вправо может привести к потере младших разрядов мантиссы, т.е. появляется погрешность округления.
Округленное в системе с плавающей точкой число, соответствующее точному числу , обозначается через
(от англ. floating – плавающий). Выполнение каждой арифметической операции вносит относительную погрешность, не большую, чем погрешность представления чисел с плавающей точкой (1). Верна следующая запись:
где — любая из арифметических операций,
.
Рассмотрим трансформированные погрешности арифметических операций. Арифметические операции проводятся над приближенными числами, ошибка арифметических операций не учитывается (эту ошибку легко учесть, прибавив ошибку округления соответствующей операции к вычисленной ошибке).
Рассмотрим сложение и вычитание приближенных чисел. Абсолютная погрешность алгебраической суммы нескольких приближенных чисел равна сумме абсолютных погрешностей слагаемых.
Если сумма точных чисел равна
сумма приближенных чисел равна
где — абсолютные погрешности представления чисел.
Тогда абсолютная погрешность суммы равна
Относительная погрешность суммы нескольких чисел равна
( 2 )
где — относительные погрешности представления чисел.
Из (2) следует, что относительная погрешность суммы нескольких чисел одного и того же знака заключена между наименьшей и наибольшей из относительных погрешностей слагаемых:
При сложении чисел разного знака или вычитании чисел одного знака относительная погрешность может быть очень большой (если числа близки между собой). Так как даже при малых величина
может быть очень малой. Поэтому вычислительные алгоритмы необходимо строить таким образом, чтобы избегать вычитания близких чисел.
Необходимо отметить, что погрешности вычислений зависят от порядка вычислений. Далее будет рассмотрен пример сложения трех чисел.
( 3 )
При другой последовательности действий погрешность будет другой:
Из (3) видно, что результат выполнения некоторого алгоритма, искаженный погрешностями округлений, совпадает с результатом выполнения того же алгоритма, но с неточными исходными данными. Т.е. можно применять обратный анализ: свести влияние погрешностей округления к возмущению исходных данных. Тогда вместо (3) будет следующая запись:
где
При умножении и делении приближенных чисел складываются и вычитаются их относительные погрешности.
-
≅
с точностью величин второго порядка малости относительно .
Тогда .
Если , то
≅
При большом числе n арифметических операций можно пользоваться приближенной статистической оценкой погрешности арифметических операций, учитывающей частичную компенсацию погрешностей разных знаков:
где – суммарная погрешность,
– погрешность выполнения операций с плавающей точкой,
– погрешность представления чисел с плавающей точкой.
Погрешности вычисления функций
Рассмотрим трансформированную погрешность вычисления значений функций.
Абсолютная трансформированная погрешность дифференцируемой функции , вызываемая достаточно малой погрешностью аргумента
, оценивается величиной
.
Если , то
.
Абсолютная погрешность дифференцируемой функции многих аргументов , вызываемая достаточно малыми погрешностями
аргументов
оценивается величиной:
-
.
Если , то
.
Практически важно определить допустимую погрешность аргументов и допустимую погрешность функции (обратная задача). Эта задача имеет однозначное решение только для функций одной переменной , если
дифференцируема и
:
-
.
Для функций многих переменных задача не имеет однозначного решения, необходимо ввести дополнительные ограничения. Например, если функция наиболее критична к погрешности
, то:
-
(погрешностью других аргументов пренебрегаем).
Если вклад погрешностей всех аргументов примерно одинаков, то применяют принцип равных влияний:
Числовые примеры
Специфику машинных вычислений можно пояснить на нескольких элементарных примерах.
ПРИМЕР 1. Вычислить все корни уравнения
Точное решение задачи легко найти:
Если компьютер работает при , то свободный член в исходном уравнении будет округлен до
и, с точки зрения представления чисел с плавающей точкой, будет решаться уравнение
, т.е.
, что, очевидно, неверно. В данном случае малые погрешности в задании свободного члена
привели, независимо от метода решения, к погрешности в решении
.
ПРИМЕР 2. Решается задача Коши для обыкновенного дифференциального уравнения 2-го порядка:
Общее решение имеет вид:
При заданных начальных данных точное решение задачи: , однако малая погрешность
в их задании приведет к появлению члена
, который при больших значениях аргумента может существенно исказить решение.
ПРИМЕР 3. Пусть необходимо найти решение обыкновенного дифференциального уравнения:
Его решение: , однако значение
известно лишь приближенно:
, и на самом деле
.
Соответственно, разность будет:
Предположим, что необходимо гарантировать некоторую заданную точность вычислений всюду на отрезке
. Тогда должно выполняться условие:
Очевидно, что:
Отсюда можно получить требования к точности задания начальных данных при
.
Таким образом, требование к заданию точности начальных данных оказываются в раз выше необходимой точности результата решения задачи. Это требование, скорее всего, окажется нереальным.
Решение оказывается очень чувствительным к заданию начальных данных. Такого рода задачи называются плохо обусловленными.
ПРИМЕР 4. Решением системы линейных алгебраических уравнений (СЛАУ):
является пара чисел .
Изменив правую часть системы на , получим возмущенную систему:
с решением , сильно отличающимся от решения невозмущенной системы. Эта система также плохо обусловлена.
ПРИМЕР 5. Рассмотрим методический пример вычислений на модельном компьютере, обеспечивающем точность . Проанализируем причину происхождения ошибки, например, при вычитании двух чисел, взятых с точностью до третьей цифры после десятичной точки
, разность которых составляет
.
В памяти машины эти же числа представляются в виде:
-
, причем
и
Тогда:
Относительная ошибка при вычислении разности будет равна:
Очевидно, что , т.е. все значащие цифры могут оказаться неверными.
ПРИМЕР 6. Рассмотрим рекуррентное соотношение
Пусть при выполнении реальных вычислений с конечной длиной мантиссы на -м шаге возникла погрешность округления, и вычисления проводятся с возмущенным значением
, тогда вместо
получим
, т.е.
.
Следовательно, если , то в процессе вычислений погрешность, связанная с возникшей ошибкой округления, будет возрастать (алгоритм неустойчив). В случае
погрешность не возрастает и численный алгоритм устойчив.
Список литературы
- А.А.Самарский, А.В.Гулин. Численные методы. Москва «Наука», 1989.
- http://www.mgopu.ru/PVU/2.1/nummethods/Chapter1.htm
- http://www.intuit.ru/department/calculate/calcmathbase/1/4.html
См. также
- Практикум ММП ВМК, 4й курс, осень 2008
Содержание:
Регрессионный анализ:
Регрессионным анализом называется раздел математической статистики, объединяющий практические методы исследования корреляционной зависимости между случайными величинами по результатам наблюдений над ними. Сюда включаются методы выбора модели изучаемой зависимости и оценки ее параметров, методы проверки статистических гипотез о зависимости.
Пусть между случайными величинами X и Y существует линейная корреляционная зависимость. Это означает, что математическое ожидание Y линейно зависит от значений случайной величины X. График этой зависимости (линия регрессии Y на X) имеет уравнение 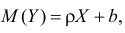
Линейная модель пригодна в качестве первого приближения и в случае нелинейной корреляции, если рассматривать небольшие интервалы возможных значений случайных величин.
Пусть параметры линии регрессии 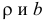 неизвестны, неизвестна и величина коэффициента корреляции
неизвестны, неизвестна и величина коэффициента корреляции  Над случайными величинами X и Y проделано n независимых наблюдений, в результате которых получены n пар значений:
Над случайными величинами X и Y проделано n независимых наблюдений, в результате которых получены n пар значений: 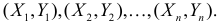 Эти результаты могут служить источником информации о неизвестных значениях
Эти результаты могут служить источником информации о неизвестных значениях 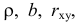 надо только уметь эту информацию извлечь оттуда.
надо только уметь эту информацию извлечь оттуда.
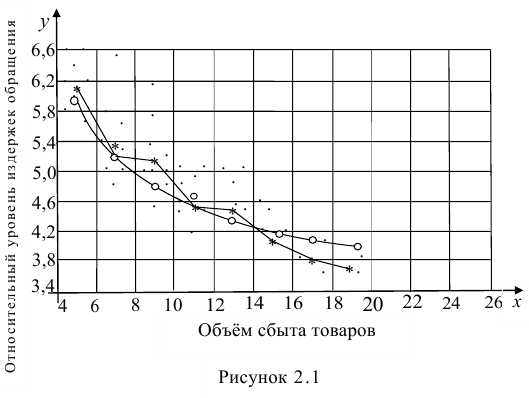
Неизвестная нам линия регрессии 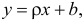 как и всякая линия регрессии, имеет то отличительное свойство, что средний квадрат отклонений значений Y от нее минимален. Поэтому в качестве оценок для можно принять те их значения, при которых имеет минимум функция
как и всякая линия регрессии, имеет то отличительное свойство, что средний квадрат отклонений значений Y от нее минимален. Поэтому в качестве оценок для можно принять те их значения, при которых имеет минимум функция 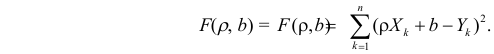
Такие значения , согласно необходимым условиям экстремума, находятся из системы уравнений:
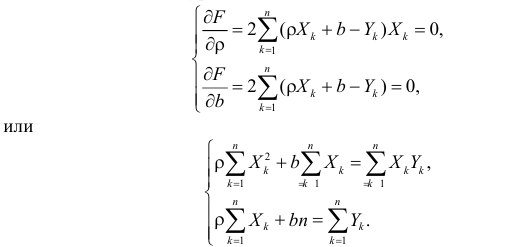
Решения этой системы уравнений дают оценки называемые оценками по методу наименьших квадратов.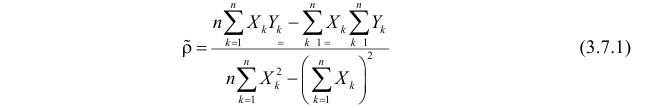
и
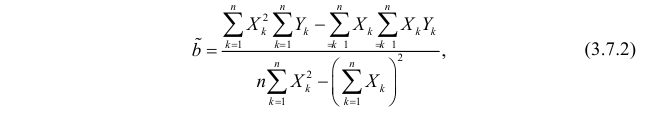
Известно, что оценки по методу наименьших квадратов являются несмещенными и, более того, среди всех несмещенных оценок обладают наименьшей дисперсией. Для оценки коэффициента корреляции можно воспользоваться тем, что 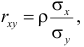 где
где 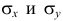 средние квадратические отклонения случайных величин X и Y соответственно. Обозначим через
средние квадратические отклонения случайных величин X и Y соответственно. Обозначим через 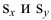 оценки этих средних квадратических отклонений на основе опытных данных. Оценки можно найти, например, по формуле (3.1.3). Тогда для коэффициента корреляции имеем оценку
оценки этих средних квадратических отклонений на основе опытных данных. Оценки можно найти, например, по формуле (3.1.3). Тогда для коэффициента корреляции имеем оценку 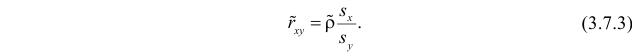
По методу наименьших квадратов можно находить оценки параметров линии регрессии и при нелинейной корреляции. Например, для линии регрессии вида 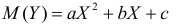 оценки параметров
оценки параметров  находятся из условия минимума функции
находятся из условия минимума функции
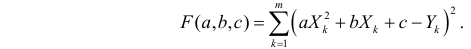
Пример:
По данным наблюдений двух случайных величин найти коэффициент корреляции и уравнение линии регрессии Y на X 
Решение. Вычислим величины, необходимые для использования формул (3.7.1)–(3.7.3):
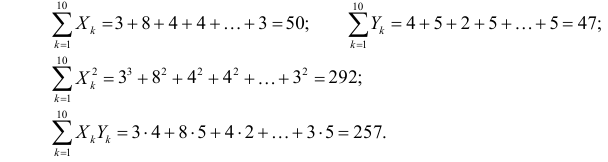
По формулам (3.7.1) и (3.7.2) получим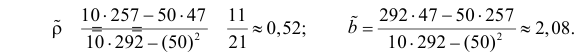
Итак, оценка линии регрессии имеет вид 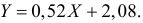 Так как
Так как 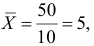 то по формуле (3.1.3)
то по формуле (3.1.3)
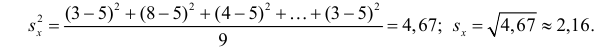
Аналогично, 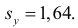 Поэтому в качестве оценки коэффициента корреляции имеем по формуле (3.7.3) величину
Поэтому в качестве оценки коэффициента корреляции имеем по формуле (3.7.3) величину 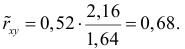
Ответ. 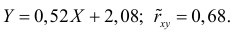
Пример:
Получена выборка значений величин X и Y
Для представления зависимости между величинами предполагается использовать модель 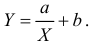 Найти оценки параметров
Найти оценки параметров 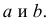
Решение. Рассмотрим сначала задачу оценки параметров этой модели в общем виде. Линия 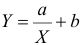 играет роль линии регрессии и поэтому параметры ее можно найти из условия минимума функции (сумма квадратов отклонений значений Y от линии должна быть минимальной по свойству линии регрессии)
играет роль линии регрессии и поэтому параметры ее можно найти из условия минимума функции (сумма квадратов отклонений значений Y от линии должна быть минимальной по свойству линии регрессии)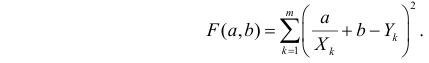
Необходимые условия экстремума приводят к системе из двух уравнений: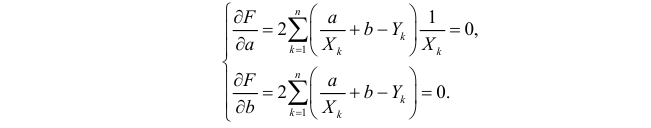
Откуда
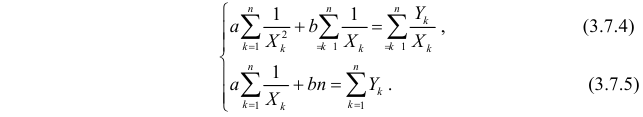
Решения системы уравнений (3.7.4) и (3.7.5) и будут оценками по методу наименьших квадратов для параметров 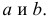
На основе опытных данных вычисляем: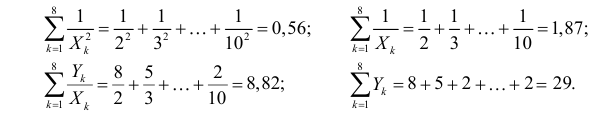
В итоге получаем систему уравнений (?????) и (?????) в виде 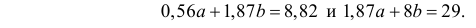
Эта система имеет решения 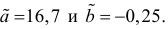
Ответ. 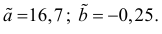
Если наблюдений много, то результаты их обычно группируют и представляют в виде корреляционной таблицы.
В этой таблице 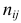 равно числу наблюдений, для которых X находится в интервале
равно числу наблюдений, для которых X находится в интервале 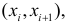 а Y – в интервале
а Y – в интервале 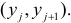 Через
Через 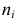 обозначено число наблюдений, при которых
обозначено число наблюдений, при которых 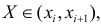 а Y произвольно. Число наблюдений, при которых
а Y произвольно. Число наблюдений, при которых 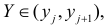 а X произвольно, обозначено через
а X произвольно, обозначено через 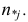
Если величины дискретны, то вместо интервалов указывают отдельные значения этих величин. Для непрерывных случайных величин представителем каждого интервала считают его середину и полагают, что 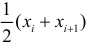 и
и 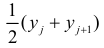 наблюдались
наблюдались 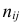 раз.
раз.
При больших значениях X и Y можно для упрощения вычислений перенести начало координат и изменить масштаб по каждой из осей, а после завершения вычислений вернуться к старому масштабу.
Пример:
Проделано 80 наблюдений случайных величин X и Y. Результаты наблюдений представлены в виде таблицы. Найти линию регрессии Y на X. Оценить коэффициент корреляции.

Решение. Представителем каждого интервала будем считать его середину. Перенесем начало координат и изменим масштаб по каждой оси так, чтобы значения X и Y были удобны для вычислений. Для этого перейдем к новым переменным 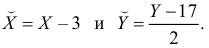 Значения этих новых переменных указаны соответственно в самой верхней строке и самом левом столбце таблицы.
Значения этих новых переменных указаны соответственно в самой верхней строке и самом левом столбце таблицы.
Чтобы иметь представление о виде линии регрессии, вычислим средние значения  при фиксированных значениях
при фиксированных значениях 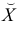 :
:
Нанесем эти значения на координатную плоскость, соединив для наглядности их отрезками прямой (рис. 3.7.1).
По виду полученной ломанной линии можно предположить, что линия регрессии Y на X является прямой. Оценим ее параметры. Для этого сначала вычислим с учетом группировки данных в таблице все величины, необходимые для использования формул (3.31–3.33): 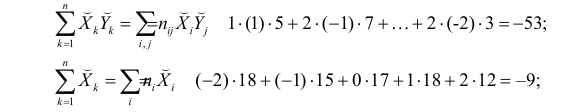
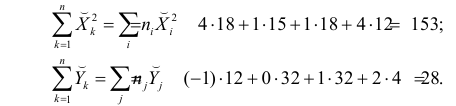
Тогда
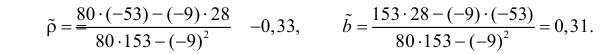
В новом масштабе оценка линии регрессии имеет вид 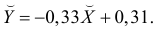 График этой прямой линии изображен на рис. 3.7.1.
График этой прямой линии изображен на рис. 3.7.1.
Для оценки 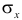 по корреляционной таблице можно воспользоваться формулой (3.1.3):
по корреляционной таблице можно воспользоваться формулой (3.1.3):
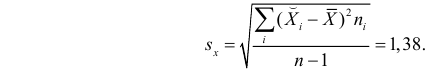
Подобным же образом можно оценить 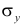 величиной
величиной 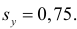 Тогда оценкой коэффициента корреляции может служить величина
Тогда оценкой коэффициента корреляции может служить величина 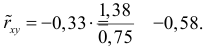
Вернемся к старому масштабу:
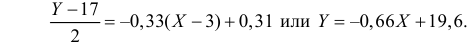
Коэффициент корреляции пересчитывать не нужно, так как это величина безразмерная и от масштаба не зависит.
Ответ. 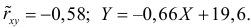
Пусть некоторые физические величины X и Y связаны неизвестной нам функциональной зависимостью 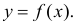 Для изучения этой зависимости производят измерения Y при разных значениях X. Измерениям сопутствуют ошибки и поэтому результат каждого измерения случаен. Если систематической ошибки при измерениях нет, то
Для изучения этой зависимости производят измерения Y при разных значениях X. Измерениям сопутствуют ошибки и поэтому результат каждого измерения случаен. Если систематической ошибки при измерениях нет, то 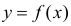 играет роль линии регрессии и все свойства линии регрессии приложимы к
играет роль линии регрессии и все свойства линии регрессии приложимы к 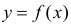 . В частности,
. В частности, 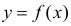 обычно находят по методу наименьших квадратов.
обычно находят по методу наименьших квадратов.
Регрессионный анализ
Основные положения регрессионного анализа:
Основная задача регрессионного анализа — изучение зависимости между результативным признаком Y и наблюдавшимся признаком X, оценка функции регрессий.
Предпосылки регрессионного анализа:
- Y — независимые случайные величины, имеющие постоянную дисперсию;
- X— величины наблюдаемого признака (величины не случайные);
- условное математическое ожидание
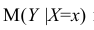 можно представить в виде
можно представить в виде 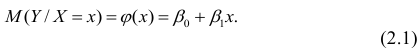
Выражение (2.1), как уже упоминалось в п. 1.2, называется функцией регрессии (или модельным уравнением регрессии) Y на X. Оценке в этом выражении подлежат параметры  называемые коэффициентами регрессии, а также
называемые коэффициентами регрессии, а также 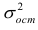 — остаточная дисперсия.
— остаточная дисперсия.
Остаточной дисперсией называется та часть рассеивания результативного признака, которую нельзя объяснить действием наблюдаемого признака; Остаточная дисперсия может служить для оценки точности подбора вида функции регрессии (модельного уравнения регрессии), полноты набора признаков, включенных в анализ. Оценки параметров функции регрессии находят, используя метод наименьших квадратов.
В данном вопросе рассмотрен линейный регрессионный анализ. Линейным он называется потому, что изучаем лишь те виды зависимостей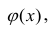 которые линейны по оцениваемым параметрам, хотя могут быть нелинейны по переменным X. Например, зависимости
которые линейны по оцениваемым параметрам, хотя могут быть нелинейны по переменным X. Например, зависимости 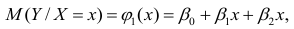
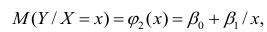
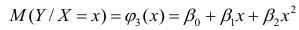 линейны относительно параметров
линейны относительно параметров 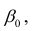
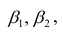 хотя вторая и третья зависимости нелинейны относительно переменных х. Вид зависимости
хотя вторая и третья зависимости нелинейны относительно переменных х. Вид зависимости 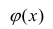 выбирают, исходя из визуальной оценки характера расположения точек на поле корреляции; опыта предыдущих исследований; соображений профессионального характера, основанных и знании физической сущности процесса.
выбирают, исходя из визуальной оценки характера расположения точек на поле корреляции; опыта предыдущих исследований; соображений профессионального характера, основанных и знании физической сущности процесса.
Важное место в линейном регрессионном анализе занимает так называемая «нормальная регрессия». Она имеет место, если сделать предположения относительно закона распределения случайной величины Y. Предпосылки «нормальной регрессии»:
- Y — независимые случайные величины, имеющие постоянную дисперсию и распределенные по нормальному закону;
- X— величины наблюдаемого признака (величины не случайные);
- условное математическое ожидание
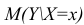 можно представить в виде (2.1).
можно представить в виде (2.1).
В этом случае оценки коэффициентов регрессии — несмещённые с минимальной дисперсией и нормальным законом распределения. Из этого положения следует что при «нормальной регрессии» имеется возможность оценить значимость оценок коэффициентов регрессии, а также построить доверительный интервал для коэффициентов регрессии и условного математического ожидания M(YX=x).
Линейная регрессия
Рассмотрим простейший случай регрессионного анализа — модель вида (2.1), когда зависимость 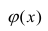 линейна и по оцениваемым параметрам, и
линейна и по оцениваемым параметрам, и
по переменным. Оценки параметров модели (2.1) 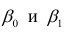 обозначил
обозначил 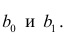 Оценку остаточной дисперсии
Оценку остаточной дисперсии 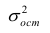 обозначим
обозначим 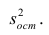 Подставив в формулу (2.1) вместо параметров их оценки, получим уравнение регрессии
Подставив в формулу (2.1) вместо параметров их оценки, получим уравнение регрессии 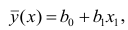 коэффициенты которого
коэффициенты которого 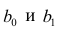 находят из условия минимума суммы квадратов отклонений измеренных значений результативного признака
находят из условия минимума суммы квадратов отклонений измеренных значений результативного признака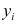 от вычисленных по уравнению регрессии
от вычисленных по уравнению регрессии 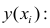
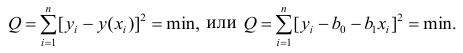
Составим систему нормальных уравнений: первое уравнение
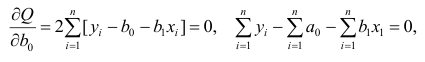
откуда 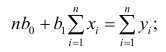
второе уравнение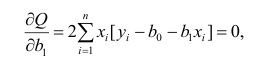
откуда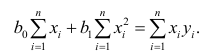
Итак,
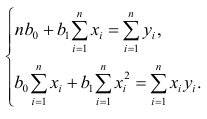
Оценки, полученные по способу наименьших квадратов, обладают минимальной дисперсией в классе линейных оценок. Решая систему (2.2) относительно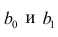 найдём оценки параметров
найдём оценки параметров 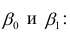
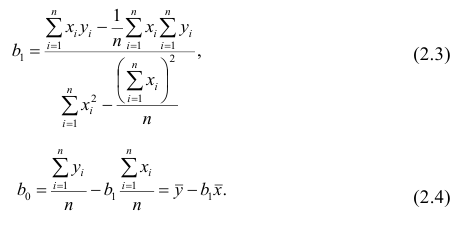
Остаётся получить оценку параметра 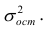 . Имеем
. Имеем
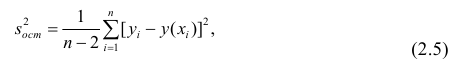
где т — количество наблюдений.
Еслит велико, то для упрощения расчётов наблюдавшиеся данные принята группировать, т.е. строить корреляционную таблицу. Пример построения такой таблицы приведен в п. 1.5. Формулы для нахождения коэффициентов регрессии по сгруппированным данным те же, что и для расчёта по несгруппированным данным, но суммы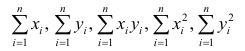 заменяют на
заменяют на
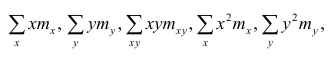
где  — частоты повторений соответствующих значений переменных. В дальнейшем часто используется этот наглядный приём вычислений.
— частоты повторений соответствующих значений переменных. В дальнейшем часто используется этот наглядный приём вычислений.
Нелинейная регрессия
Рассмотрим случай, когда зависимость нелинейна по переменным х, например модель вида
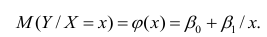
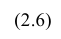
На рис. 2.1 изображено поле корреляции. Очевидно, что зависимость между Y и X нелинейная и её графическим изображением является не прямая, а кривая. Оценкой выражения (2.6) является уравнение регрессии
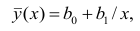
где 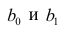 —оценки коэффициентов регрессии
—оценки коэффициентов регрессии 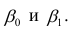
Принцип нахождения коэффициентов тот же — метод наименьших квадратов, т.е.
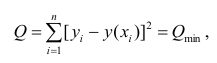
или
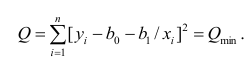
Дифференцируя последнее равенство по 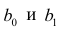 и приравнивая правые части нулю, получаем так называемую систему нормальных уравнений:
и приравнивая правые части нулю, получаем так называемую систему нормальных уравнений:
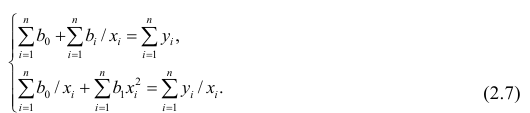
В общем случае нелинейной зависимости между переменными Y и X связь может выражаться многочленом k-й степени от x:
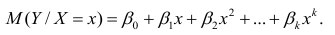
Коэффициенты регрессии определяют по принципу наименьших квадратов. Система нормальных уравнений имеет вид
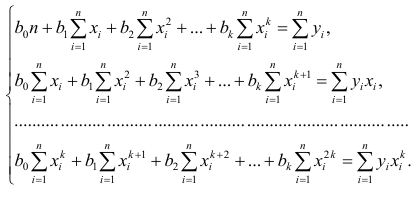
Вычислив коэффициенты системы, её можно решить любым известным способом.
Оценка значимости коэффициентов регрессии. Интервальная оценка коэффициентов регрессии
Проверить значимость оценок коэффициентов регрессии — значит установить, достаточна ли величина оценки для статистически обоснованного вывода о том, что коэффициент регрессии отличен от нуля. Для этого проверяют гипотезу о равенстве нулю коэффициента регрессии, соблюдая предпосылки «нормальной регрессии». В этом случае вычисляемая для проверки нулевой гипотезы 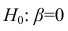 статистика
статистика

имеет распределение Стьюдента с к= n-2 степенями свободы (b — оценка коэффициента регрессии, 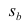 — оценка среднеквадратического отклонения
— оценка среднеквадратического отклонения
коэффициента регрессии, иначе стандартная ошибка оценки). По уровню значимости а и числу степеней свободы к находят по таблицам распределения Стьюдента (см. табл. 1 приложений) критическое значение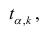 удовлетворяющее условию
удовлетворяющее условию 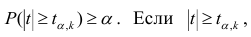 то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают, коэффициент считают значимым. При
то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают, коэффициент считают значимым. При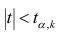 нет оснований отвергать нулевую гипотезу.
нет оснований отвергать нулевую гипотезу.
Оценки среднеквадратического отклонения коэффициентов регрессии вычисляют по следующим формулам:
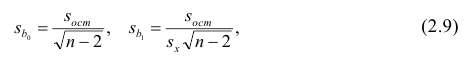
где 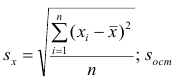 — оценка остаточной дисперсии, вычисляемая по
— оценка остаточной дисперсии, вычисляемая по
формуле (2.5).
Доверительный интервал для значимых параметров строят по обычной схеме. Из условия
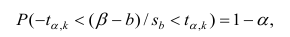
где а — уровень значимости, находим

Интервальная оценка для условного математического ожидания
Линия регрессии характеризует изменение условного математического ожидания результативного признака от вариации остальных признаков.
Точечной оценкой условного математического ожидания 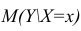 является условное среднее
является условное среднее 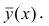 Кроме точечной оценки для
Кроме точечной оценки для 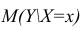 можно
можно
построить доверительный интервал в точке 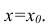
Известно, что 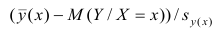 имеет распределение
имеет распределение
Стьюдента с k=n—2 степенями свободы. Найдя оценку среднеквадратического отклонения для условного среднего, можно построить доверительный интервал для условного математического ожидания 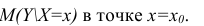
Оценку дисперсии условного среднего вычисляют по формуле
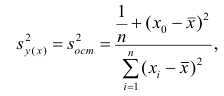
или для интервального ряда
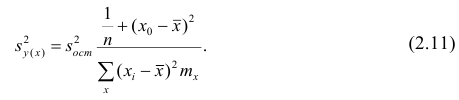
Доверительный интервал находят из условия
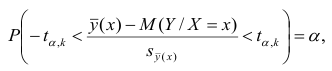
где а — уровень значимости. Отсюда
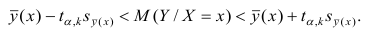
Доверительный интервал для условного математического ожидания можно изобразить графически (рис, 2.2).
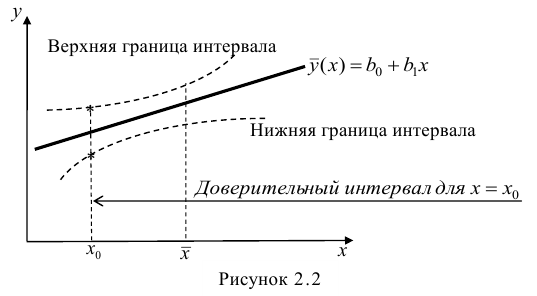
Из рис. 2.2 видно, что в точке 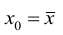 границы интервала наиболее близки друг другу. Расположение границ доверительного интервала показывает, что прогнозы по уравнению регрессии, хороши только в случае, если значение х не выходит за пределы выборки, по которой вычислено уравнение регрессии; иными словами, экстраполяция по уравнению регрессии может привести к значительным погрешностям.
границы интервала наиболее близки друг другу. Расположение границ доверительного интервала показывает, что прогнозы по уравнению регрессии, хороши только в случае, если значение х не выходит за пределы выборки, по которой вычислено уравнение регрессии; иными словами, экстраполяция по уравнению регрессии может привести к значительным погрешностям.
Проверка значимости уравнения регрессии
Оценить значимость уравнения регрессии — значит установить, соответствует ли математическая, модель, выражающая зависимость между Y и X, экспериментальным данным. Для оценки значимости в предпосылках «нормальной регрессии» проверяют гипотезу 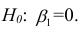 Если она отвергается, то считают, что между Y и X нет связи (или связь нелинейная). Для проверки нулевой гипотезы используют основное положение дисперсионного анализа о разбиении суммы квадратов на слагаемые. Воспользуемся разложением
Если она отвергается, то считают, что между Y и X нет связи (или связь нелинейная). Для проверки нулевой гипотезы используют основное положение дисперсионного анализа о разбиении суммы квадратов на слагаемые. Воспользуемся разложением 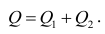 — Общая сумма квадратов отклонений результативного признака
— Общая сумма квадратов отклонений результативного признака
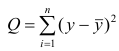 разлагается на
разлагается на 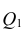 (сумму, характеризующую влияние признака
(сумму, характеризующую влияние признака
X) и 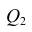 (остаточную сумму квадратов, характеризующую влияние неучтённых факторов). Очевидно, чем меньше влияние неучтённых факторов, тем лучше математическая модель соответствует экспериментальным данным, так как вариация У в основном объясняется влиянием признака X.
(остаточную сумму квадратов, характеризующую влияние неучтённых факторов). Очевидно, чем меньше влияние неучтённых факторов, тем лучше математическая модель соответствует экспериментальным данным, так как вариация У в основном объясняется влиянием признака X.
Для проверки нулевой гипотезы вычисляют статистику 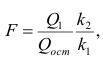 которая имеет распределение Фишера-Снедекора с А
которая имеет распределение Фишера-Снедекора с А степенями свободы (в п — число наблюдений). По уровню значимости а и числу степеней свободы
степенями свободы (в п — число наблюдений). По уровню значимости а и числу степеней свободы  находят по таблицам F-распределение для уровня значимости а=0,05 (см. табл. 3 приложений) критическое значение
находят по таблицам F-распределение для уровня значимости а=0,05 (см. табл. 3 приложений) критическое значение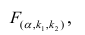 удовлетворяющее условию
удовлетворяющее условию 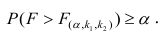 . Если
. Если 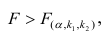 нулевую гипотезу отвергают, уравнение считают значимым. Если
нулевую гипотезу отвергают, уравнение считают значимым. Если 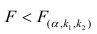 то нет оснований отвергать нулевую гипотезу.
то нет оснований отвергать нулевую гипотезу.
Многомерный регрессионный анализ
В случае, если изменения результативного признака определяются действием совокупности других признаков, имеет место многомерный регрессионный анализ. Пусть результативный признак У, а независимые признаки 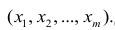 Для многомерного случая предпосылки регрессионного анализа можно сформулировать следующим образом: У -независимые случайные величины со средним
Для многомерного случая предпосылки регрессионного анализа можно сформулировать следующим образом: У -независимые случайные величины со средним 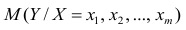 и постоянной дисперсией
и постоянной дисперсией 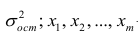 — линейно независимые векторы
— линейно независимые векторы 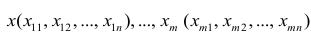 . Все положения, изложенные в п.2.1, справедливы для многомерного случая. Рассмотрим модель вида
. Все положения, изложенные в п.2.1, справедливы для многомерного случая. Рассмотрим модель вида
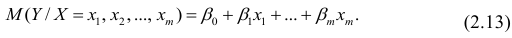
Оценке подлежат параметры 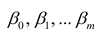 и остаточная дисперсия.
и остаточная дисперсия.
Заменив параметры их оценками, запишем уравнение регрессии
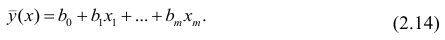
Коэффициенты в этом выражении находят методом наименьших квадратов.
Исходными данными для вычисления коэффициентов 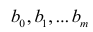 является выборка из многомерной совокупности, представляемая обычно в виде матрицы X и вектора Y:
является выборка из многомерной совокупности, представляемая обычно в виде матрицы X и вектора Y:

Как и в двумерном случае, составляют систему нормальных уравнений
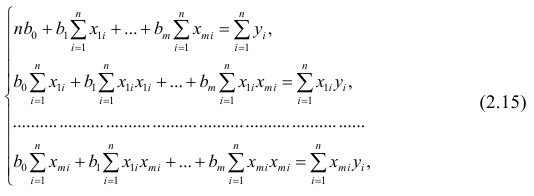
которую можно решить любым способом, известным из линейной алгебры. Рассмотрим один из них — способ обратной матрицы. Предварительно преобразуем систему уравнений. Выразим из первого уравнения значение 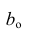 через остальные параметры:
через остальные параметры:
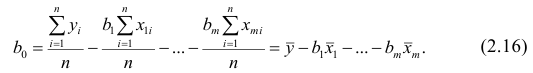
Подставим в остальные уравнения системы вместо 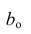 полученное выражение:
полученное выражение:
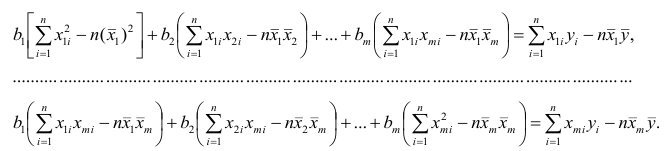
Пусть С — матрица коэффициентов при неизвестных параметрах 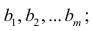
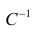 — матрица, обратная матрице С;
— матрица, обратная матрице С; 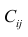 — элемент, стоящий на пересечении i-Й строки и i-го столбца матрицы
— элемент, стоящий на пересечении i-Й строки и i-го столбца матрицы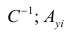 — выражение
— выражение
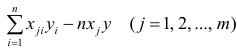 . Тогда, используя формулы линейной алгебры,
. Тогда, используя формулы линейной алгебры,
запишем окончательные выражения для параметров:
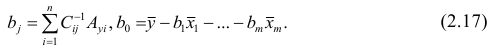
Оценкой остаточной дисперсии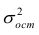 является
является
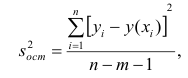
где 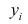 — измеренное значение результативного признака;
— измеренное значение результативного признака;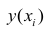 значение результативного признака, вычисленное по уравнению регрессий.
значение результативного признака, вычисленное по уравнению регрессий.
Если выборка получена из нормально распределенной генеральной совокупности, то, аналогично изложенному в п. 2.4, можно проверить значимость оценок коэффициентов регрессии, только в данном случае статистику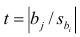 вычисляют для каждого j-го коэффициента регрессии
вычисляют для каждого j-го коэффициента регрессии
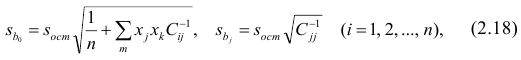
где 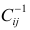 —элемент обратной матрицы, стоящий на пересечении i-й строки и j-
—элемент обратной матрицы, стоящий на пересечении i-й строки и j-
го столбца;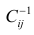 —диагональный элемент обратной матрицы.
—диагональный элемент обратной матрицы.
При заданном уровне значимости а и числе степеней свободы к=n— m—1 по табл. 1 приложений находят критическое значение 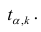 Если
Если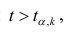 то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают. Оценку коэффициента считают значимой. Такую проверку производят последовательно для каждого коэффициента регрессии. Если
то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают. Оценку коэффициента считают значимой. Такую проверку производят последовательно для каждого коэффициента регрессии. Если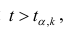 то нет оснований отвергать нулевую гипотезу, оценку коэффициента регрессии считают незначимой.
то нет оснований отвергать нулевую гипотезу, оценку коэффициента регрессии считают незначимой.
Для значимых коэффициентов регрессии целесообразно построить доверительные интервалы по формуле (2.10). Для оценки значимости уравнения регрессии следует проверить нулевую гипотезу о том, что все коэффициенты регрессии (кроме свободного члена) равны нулю: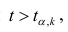
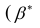 — вектор коэффициентов регрессии). Нулевую гипотезу проверяют, так же как и в п. 2.6, с помощью статистики
— вектор коэффициентов регрессии). Нулевую гипотезу проверяют, так же как и в п. 2.6, с помощью статистики 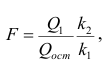 , где
, где 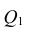 — сумма квадратов, характеризующая влияние признаков X;
— сумма квадратов, характеризующая влияние признаков X; 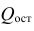 — остаточная сумма квадратов, характеризующая влияние неучтённых факторов;
— остаточная сумма квадратов, характеризующая влияние неучтённых факторов; 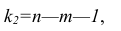
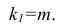 Для уровня значимости а и числа степеней свободы
Для уровня значимости а и числа степеней свободы 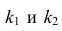 по табл. 3 приложений находят критическое значение
по табл. 3 приложений находят критическое значение 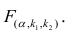 Если
Если 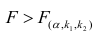 то нулевую гипотезу об одновременном равенстве нулю коэффициентов регрессии отвергают. Уравнение регрессии считают значимым. При
то нулевую гипотезу об одновременном равенстве нулю коэффициентов регрессии отвергают. Уравнение регрессии считают значимым. При 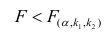 нет оснований отвергать нулевую гипотезу, уравнение регрессии считают незначимым.
нет оснований отвергать нулевую гипотезу, уравнение регрессии считают незначимым.
Факторный анализ
Основные положения. В последнее время всё более широкое распространение находит один из новых разделов многомерного статистического анализа — факторный анализ. Первоначально этот метод
разрабатывался для объяснения многообразия корреляций между исходными параметрами. Действительно, результатом корреляционного анализа является матрица коэффициентов корреляций. При малом числе параметров можно произвести визуальный анализ этой матрицы. С ростом числа параметра (10 и более) визуальный анализ не даёт положительных результатов. Оказалось, что всё многообразие корреляционных связей можно объяснить действием нескольких обобщённых факторов, являющихся функциями исследуемых параметров, причём сами обобщённые факторы при этом могут быть и неизвестны, однако их можно выразить через исследуемые параметры.
Один из основоположников факторного анализа Л. Терстоун приводит такой пример: несколько сотен мальчиков выполняют 20 разнообразных гимнастических упражнений. Каждое упражнение оценивают баллами. Можно рассчитать матрицу корреляций между 20 упражнениями. Это большая матрица размером 20><20. Изучая такую матрицу, трудно уловить закономерность связей между упражнениями. Нельзя ли объяснить скрытую в таблице закономерность действием каких-либо обобщённых факторов, которые в результате эксперимента непосредственно, не оценивались? Оказалось, что обо всех коэффициентах корреляции можно судить по трём обобщённым факторам, которые и определяют успех выполнения всех 20 гимнастических упражнений: чувство равновесия, усилие правого плеча, быстрота движения тела.
Дальнейшие разработки факторного анализа доказали, что этот метод может быть с успехом применён в задачах группировки и классификации объектов. Факторный анализ позволяет группировать объекты со сходными сочетаниями признаков и группировать признаки с общим характером изменения от объекта к объекту. Действительно, выделенные обобщённые факторы можно использовать как критерии при классификации мальчиков по способностям к отдельным группам гимнастических упражнений.
Методы факторного анализа находят применение в психологии и экономике, социологии и экономической географии. Факторы, выраженные через исходные параметры, как правило, легко интерпретировать как некоторые существенные внутренние характеристики объектов.
Факторный анализ может быть использован и как самостоятельный метод исследования, и вместе с другими методами многомерного анализа, например в сочетании с регрессионным анализом. В этом случае для набора зависимых переменных наводят обобщённые факторы, которые потом входят в регрессионный анализ в качестве переменных. Такой подход позволяет сократить число переменных в регрессионном анализе, устранить коррелированность переменных, уменьшить влияние ошибок и в случае ортогональности выделенных факторов значительно упростить оценку значимости переменных.
Представление, информации в факторном анализе
Для проведения факторного анализа информация должна быть представлена в виде двумерной таблицы чисел размерностью 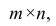 аналогичной приведенной в п. 2.7 (матрица исходных данных). Строки этой матрицы должны соответствовать объектам наблюдений
аналогичной приведенной в п. 2.7 (матрица исходных данных). Строки этой матрицы должны соответствовать объектам наблюдений 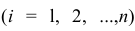 столбцы — признакам
столбцы — признакам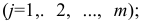 таким образом, каждый признак является как бы статистическим рядом, в котором наблюдения варьируют от объекта к объекту. Признаки, характеризующие объект наблюдения, как правило, имеют различную размерность. Чтобы устранить влияние размерности и обеспечить сопоставимость признаков, матрицу исходных данных обычно нормируют, вводя единый масштаб. Самым распространенным видом нормировки является стандартизация. От переменных
таким образом, каждый признак является как бы статистическим рядом, в котором наблюдения варьируют от объекта к объекту. Признаки, характеризующие объект наблюдения, как правило, имеют различную размерность. Чтобы устранить влияние размерности и обеспечить сопоставимость признаков, матрицу исходных данных обычно нормируют, вводя единый масштаб. Самым распространенным видом нормировки является стандартизация. От переменных 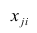 переходят к переменным
переходят к переменным 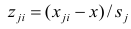 В дальнейшем, говоря о матрице исходных переменных, всегда будем иметь в виду стандартизованную матрицу.
В дальнейшем, говоря о матрице исходных переменных, всегда будем иметь в виду стандартизованную матрицу.
Основная модель факторного анализа. Основная модель факторного анализа имеет вид
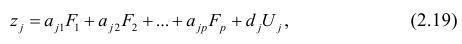
где 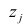 -j-й признак (величина случайная);
-j-й признак (величина случайная); 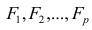 — общие факторы (величины случайные, имеющие нормальный закон распределения);
— общие факторы (величины случайные, имеющие нормальный закон распределения); 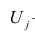 — характерный фактор;
— характерный фактор; 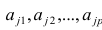 — факторные нагрузки, характеризующие существенность влияния каждого фактора (параметры модели, подлежащие определению);
— факторные нагрузки, характеризующие существенность влияния каждого фактора (параметры модели, подлежащие определению);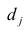 — нагрузка характерного фактора.
— нагрузка характерного фактора.
Модель предполагает, что каждый из j признаков, входящих в исследуемый набор и заданных в стандартной форме, может быть представлен в виде линейной комбинации небольшого числа общих факторов 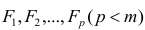 и характерного фактора
и характерного фактора 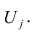
Термин «общий фактор» подчёркивает, что каждый такой фактор имеет существенное значение для анализа всех признаков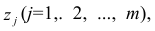 , т.е.
, т.е.
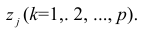
Термин «характерный фактор» показывает, что он относится только к данному j-му признаку. Это специфика признака, которая не может быть, выражена через факторы 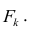
Факторные нагрузки 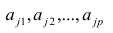 . характеризуют величину влияния того или иного общего фактора в вариации данного признака. Основная задача факторного анализа — определение факторных нагрузок. Факторная модель относится к классу аппроксимационных. Параметры модели должны быть выбраны так, чтобы наилучшим образом аппроксимировать корреляции между наблюдаемыми признаками.
. характеризуют величину влияния того или иного общего фактора в вариации данного признака. Основная задача факторного анализа — определение факторных нагрузок. Факторная модель относится к классу аппроксимационных. Параметры модели должны быть выбраны так, чтобы наилучшим образом аппроксимировать корреляции между наблюдаемыми признаками.
Для j-го признака и i-го объекта модель (2.19) можно записать в. виде
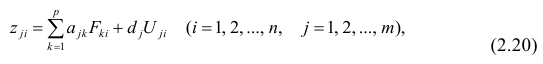
где 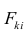 значение k-го фактора для i-го объекта.
значение k-го фактора для i-го объекта.
Дисперсию признака 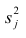 можно разложить на составляющие: часть, обусловленную действием общих факторов, — общность
можно разложить на составляющие: часть, обусловленную действием общих факторов, — общность 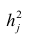 и часть, обусловленную действием j-го характера фактора, характерность
и часть, обусловленную действием j-го характера фактора, характерность 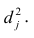 Все переменные представлены в стандартизированном виде, поэтому дисперсий у-го признака
Все переменные представлены в стандартизированном виде, поэтому дисперсий у-го признака 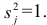 Дисперсия признака может быть выражена через факторы и в конечном счёте через факторные нагрузки.
Дисперсия признака может быть выражена через факторы и в конечном счёте через факторные нагрузки.
Если общие и характерные факторы не коррелируют между собой, то дисперсию j-го признака можно представить в виде
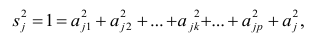
где 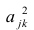 —доля дисперсии признака
—доля дисперсии признака  приходящаяся на k-й фактор.
приходящаяся на k-й фактор.
Полный вклад k-го фактора в суммарную дисперсию признаков
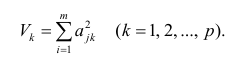
Вклад общих факторов в суммарную дисперсию 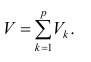
Факторное отображение
Используя модель (2.19), запишем выражения для каждого из параметров:
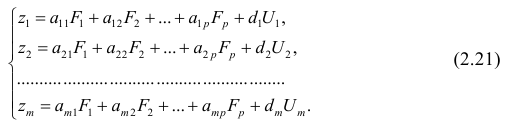
Коэффициенты системы (2,21) — факторные нагрузки — можно представить в виде матрицы, каждая строка которой соответствует параметру, а столбец — фактору.
Факторный анализ позволяет получить не только матрицу отображений, но и коэффициенты корреляции между параметрами и
факторами, что является важной характеристикой качества факторной модели. Таблица таких коэффициентов корреляции называется факторной структурой или просто структурой.
Коэффициенты отображения можно выразить через выборочные парные коэффициенты корреляции. На этом основаны методы вычисления факторного отображения.
Рассмотрим связь между элементами структуры и коэффициентами отображения. Для этого, учитывая выражение (2.19) и определение выборочного коэффициента корреляции, умножим уравнения системы (2.21) на соответствующие факторы, произведём суммирование по всем n наблюдениям и, разделив на n, получим следующую систему уравнений:
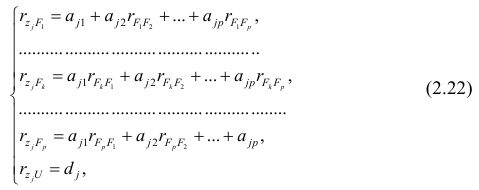
где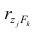 — выборочный коэффициент корреляции между j-м параметром и к-
— выборочный коэффициент корреляции между j-м параметром и к-
м фактором;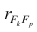 — коэффициент корреляции между к-м и р-м факторами.
— коэффициент корреляции между к-м и р-м факторами.
Если предположить, что общие факторы между собой, не коррелированы, то уравнения (2.22) можно записать в виде
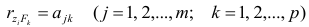 , т.е. коэффициенты отображения равны
, т.е. коэффициенты отображения равны
элементам структуры.
Введём понятие, остаточного коэффициента корреляции и остаточной корреляционной матрицы. Исходной информацией для построения факторной модели (2.19) служит матрица выборочных парных коэффициентов корреляции. Используя построенную факторную модель, можно снова вычислить коэффициенты корреляции между признаками и сравнись их с исходными Коэффициентами корреляции. Разница между ними и есть остаточный коэффициент корреляции.
В случае независимости факторов имеют место совсем простые выражения для вычисляемых коэффициентов корреляции между параметрами: для их вычисления достаточно взять сумму произведений коэффициентов отображения, соответствующих наблюдавшимся признакам: 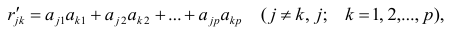
где 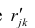 —вычисленный по отображению коэффициент корреляции между j-м
—вычисленный по отображению коэффициент корреляции между j-м
и к-м признаком. Остаточный коэффициент корреляции
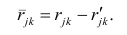
Матрица остаточных коэффициентов корреляции называется остаточной матрицей или матрицей остатков
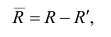
где 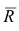 — матрица остатков; R — матрица выборочных парных коэффициентов корреляции, или полная матрица; R’— матрица вычисленных по отображению коэффициентов корреляции.
— матрица остатков; R — матрица выборочных парных коэффициентов корреляции, или полная матрица; R’— матрица вычисленных по отображению коэффициентов корреляции.
Результаты факторного анализа удобно представить в виде табл. 2.10.

Здесь суммы квадратов нагрузок по строкам — общности параметров, а суммы квадратов нагрузок по столбцам — вклады факторов в суммарную дисперсию параметров. Имеет место соотношение
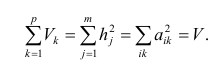
Определение факторных нагрузок
Матрицу факторных нагрузок можно получить различными способами. В настоящее время наибольшее распространение получил метод главных факторов. Этот метод основан на принципе последовательных приближений и позволяет достичь любой точности. Метод главных факторов предполагает использование ЭВМ. Существуют хорошие алгоритмы и программы, реализующие все вычислительные процедуры.
Введём понятие редуцированной корреляционной матрицы или просто редуцированной матрицы. Редуцированной называется матрица выборочных коэффициентов корреляции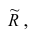 у которой на главной диагонали стоят значения общностей
у которой на главной диагонали стоят значения общностей 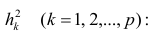 :
: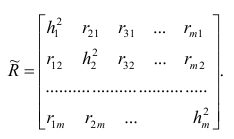
Редуцированная и полная матрицы связаны соотношением

где D — матрица характерностей.
Общности, как правило, неизвестны, и нахождение их в факторном анализе представляет серьезную проблему. Вначале определяют (хотя бы приближённо) число общих факторов, совокупность, которых может с достаточной точностью аппроксимировать все взаимосвязи выборочной корреляционной матрицы. Доказано, что число общих факторов (общностей) равно рангу редуцированной матрицы, а при известном ранге можно по выборочной корреляционной матрице найти оценки общностей. Числа общих факторов можно определить априори, исходя из физической природы эксперимента. Затем рассчитывают матрицу факторных нагрузок. Такая матрица, рассчитанная методом главных факторов, обладает одним интересным свойством: сумма произведений каждой пары её столбцов равна нулю, т.е. факторы попарно ортогональны.
Сама процедура нахождения факторных нагрузок, т.е. матрицы А, состоит из нескольких шагов и заключается в следующем: на первом шаге ищут коэффициенты факторных нагрузок при первом факторе так, чтобы сумма вкладов данного фактора в суммарную общность была максимальной:
Максимум  должен быть найден при условии
должен быть найден при условии
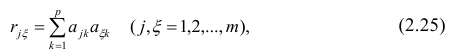
где 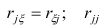 —общность
—общность параметра
параметра
Затем рассчитывают матрицу коэффициентов корреляции с учётом только первого фактора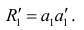 Имея эту матрицу, получают первую матрицу остатков:
Имея эту матрицу, получают первую матрицу остатков: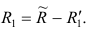
На втором шаге определяют коэффициенты нагрузок при втором факторе так, чтобы сумма вкладов второго фактора в остаточную общность (т.е. полную общность без учёта той части, которая приходится на долю первого фактора) была максимальной. Сумма квадратов нагрузок при втором факторе
Максимум  находят из условия
находят из условия
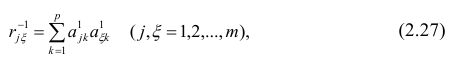
где 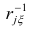 — коэффициент корреляции из первой матрицы остатков;
— коэффициент корреляции из первой матрицы остатков; 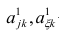 — факторные нагрузки с учётом второго фактора. Затем рассчитыва коэффициентов корреляций с учётом второго фактора и вычисляют вторую матрицу остатков:
— факторные нагрузки с учётом второго фактора. Затем рассчитыва коэффициентов корреляций с учётом второго фактора и вычисляют вторую матрицу остатков: 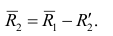
Факторный анализ учитывает суммарную общность. Исходная суммарная общность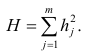 Итерационный процесс выделения факторов заканчивают, когда учтённая выделенными факторами суммарная общность отличается от исходной суммарной общности меньше чем на
Итерационный процесс выделения факторов заканчивают, когда учтённая выделенными факторами суммарная общность отличается от исходной суммарной общности меньше чем на 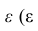 — наперёд заданное малое число).
— наперёд заданное малое число).
Адекватность факторной модели оценивается по матрице остатков (если величины её коэффициентов малы, то модель считают адекватной).
Такова последовательность шагов для нахождения факторных нагрузок. Для нахождения максимума функции (2.24) при условии (2.25) используют метод множителей Лагранжа, который приводит к системе т уравнений относительно m неизвестных 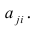
Метод главных компонент
Разновидностью метода главных факторов является метод главных компонент или компонентный анализ, который реализует модель вида
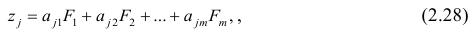
где m — количество параметров (признаков).
Каждый из наблюдаемых, параметров линейно зависит от m не коррелированных между собой новых компонент (факторов) 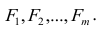 По сравнению с моделью факторного анализа (2.19) в модели (2.28) отсутствует характерный фактор, т.е. считается, что вся вариация параметра может быть объяснена только действием общих или главных факторов. В случае компонентного анализа исходной является матрица коэффициентов корреляции, где на главной диагонали стоят единицы. Результатом компонентного анализа, так же как и факторного, является матрица факторных нагрузок. Поиск факторного решения — это ортогональное преобразование матрицы исходных переменных, в результате которого каждый параметр может быть представлен линейной комбинацией найденных m факторов, которые называют главными компонентами. Главные компоненты легко выражаются через наблюдённые параметры.
По сравнению с моделью факторного анализа (2.19) в модели (2.28) отсутствует характерный фактор, т.е. считается, что вся вариация параметра может быть объяснена только действием общих или главных факторов. В случае компонентного анализа исходной является матрица коэффициентов корреляции, где на главной диагонали стоят единицы. Результатом компонентного анализа, так же как и факторного, является матрица факторных нагрузок. Поиск факторного решения — это ортогональное преобразование матрицы исходных переменных, в результате которого каждый параметр может быть представлен линейной комбинацией найденных m факторов, которые называют главными компонентами. Главные компоненты легко выражаются через наблюдённые параметры.
Если для дальнейшего анализа оставить все найденные т компонент, то тем самым будет использована вся информация, заложенная в корреляционной матрице. Однако это неудобно и нецелесообразно. На практике обычно оставляют небольшое число компонент, причём количество их определяется долей суммарной дисперсии, учитываемой этими компонентами. Существуют различные критерии для оценки числа оставляемых компонент; чаще всего используют следующий простой критерий: оставляют столько компонент, чтобы суммарная дисперсия, учитываемая ими, составляла заранее установленное число процентов. Первая из компонент должна учитывать максимум суммарной дисперсии параметров; вторая — не коррелировать с первой и учитывать максимум оставшейся дисперсии и так до тех пор, пока вся дисперсия не будет учтена. Сумма учтённых всеми компонентами дисперсий равна сумме дисперсий исходных параметров. Математический аппарат компонентного анализа полностью совпадает с аппаратом метода главных факторов. Отличие только в исходной матрице корреляций.
Компонента (или фактор) через исходные переменные выражается следующим образом:
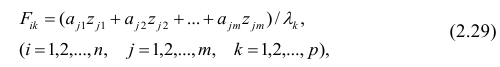
где 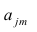 — элементы факторного решения:
— элементы факторного решения: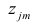 — исходные переменные;
— исходные переменные; 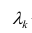 .— k-е собственное значение; р — количество оставленных главных
.— k-е собственное значение; р — количество оставленных главных
компонент.
Для иллюстрации возможностей факторного анализа покажем, как, используя метод главных компонент, можно сократить размерность пространства независимых переменных, перейдя от взаимно коррелированных параметров к независимым факторам, число которых р
Следует особо остановиться на интерпретации результатов, т.е. на смысловой стороне факторного анализа. Собственно факторный анализ состоит из двух важных этапов; аппроксимации корреляционной матрицы и интерпретации результатов. Аппроксимировать корреляционную матрицу, т.е. объяснить корреляцию между параметрами действием каких-либо общих для них факторов, и выделить сильно коррелирующие группы параметров достаточно просто: из корреляционной матрицы одним из методов
факторного анализа непосредственно получают матрицу нагрузок — факторное решение, которое называют прямым факторным решением. Однако часто это решение не удовлетворяет исследователей. Они хотят интерпретировать фактор как скрытый, но существенный параметр, поведение которого определяет поведение некоторой своей группы наблюдаемых параметров, в то время как, поведение других параметров определяется поведением других факторов. Для этого у каждого параметра должна быть наибольшая по модулю факторная нагрузка с одним общим фактором. Прямое решение следует преобразовать, что равносильно повороту осей общих факторов. Такие преобразования называют вращениями, в итоге получают косвенное факторное решение, которое и является результатом факторного анализа.
Приложения
Значение t — распределения Стьюдента 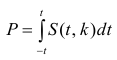
Понятие о регрессионном анализе. Линейная выборочная регрессия. Метод наименьших квадратов (МНК)
Основные задачи регрессионного анализа:
- Вычисление выборочных коэффициентов регрессии
- Проверка значимости коэффициентов регрессии
- Проверка адекватности модели
- Выбор лучшей регрессии
- Вычисление стандартных ошибок, анализ остатков
Построение простой регрессии по экспериментальным данным.
Предположим, что случайные величины  связаны линейной корреляционной зависимостью
связаны линейной корреляционной зависимостью 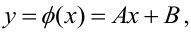 для отыскания которой проведено
для отыскания которой проведено 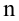 независимых измерений
независимых измерений 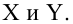
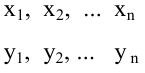
Диаграмма рассеяния (разброса, рассеивания)
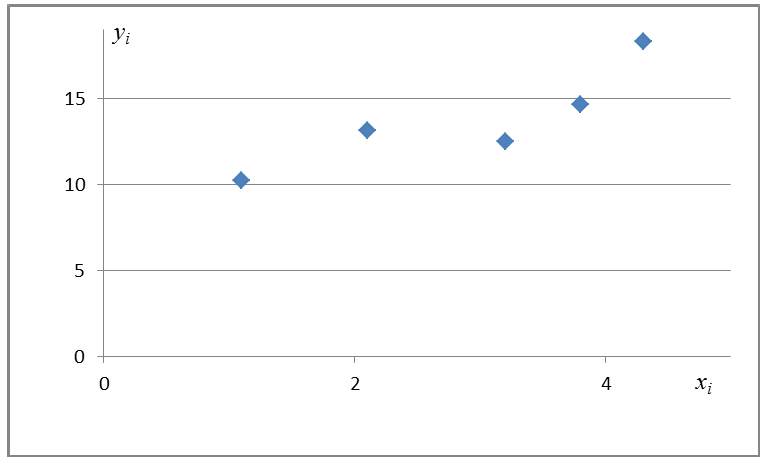
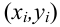 — координаты экспериментальных точек.
— координаты экспериментальных точек.
Выборочное уравнение прямой линии регрессии 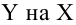 имеет вид
имеет вид
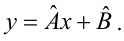
Задача: подобрать 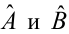 таким образом, чтобы экспериментальные точки как можно ближе лежали к прямой
таким образом, чтобы экспериментальные точки как можно ближе лежали к прямой 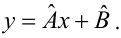
Для того, что бы провести прямую 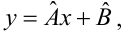 воспользуемся МНК. Потребуем,
воспользуемся МНК. Потребуем,
чтобы 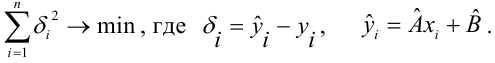
Постулаты регрессионного анализа, которые должны выполняться при использовании МНК.
 подчинены нормальному закону распределения.
подчинены нормальному закону распределения.- Дисперсия
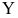 постоянна и не зависит от номера измерения.
постоянна и не зависит от номера измерения. - Результаты наблюдений
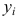 в разных точках независимы.
в разных точках независимы. - Входные переменные
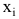 независимы, неслучайны и измеряются без ошибок.
независимы, неслучайны и измеряются без ошибок.
Введем функцию ошибок 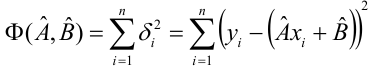 и найдём её минимальное значение
и найдём её минимальное значение
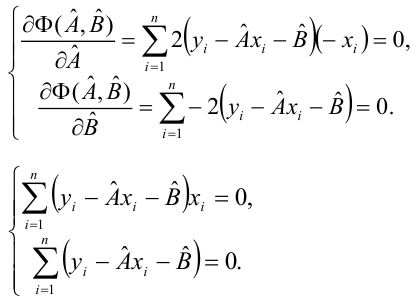
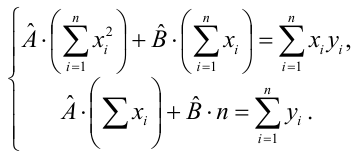
Решив систему, получим искомые значения 
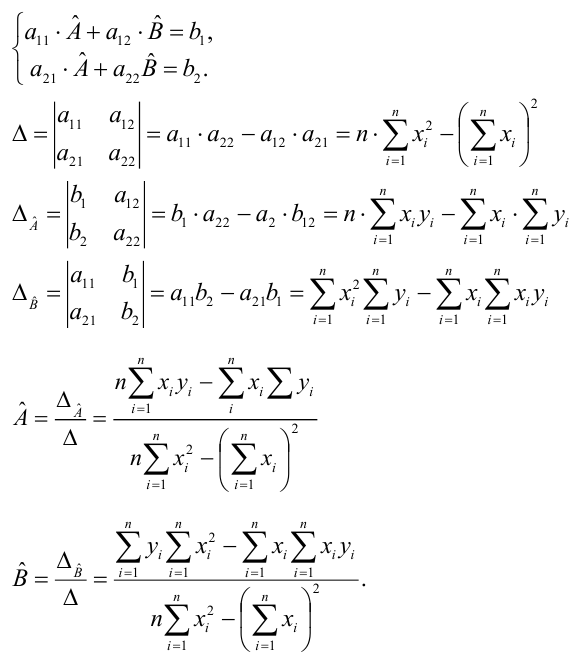
 является несмещенными оценками истинных значений коэффициентов
является несмещенными оценками истинных значений коэффициентов 
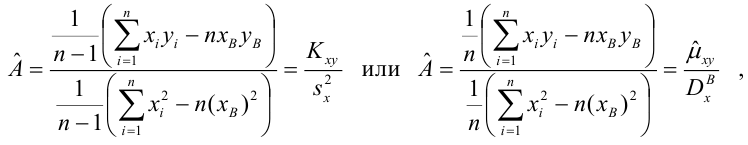 где
где
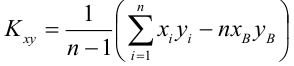 несмещенная оценка корреляционного момента (ковариации),
несмещенная оценка корреляционного момента (ковариации),
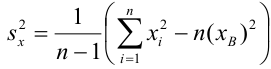 несмещенная оценка дисперсии
несмещенная оценка дисперсии 
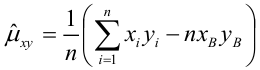 выборочная ковариация,
выборочная ковариация,
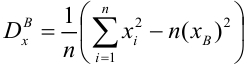 выборочная дисперсия
выборочная дисперсия 
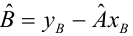
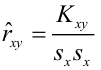 — выборочный коэффициент корреляции
— выборочный коэффициент корреляции
Коэффициент детерминации
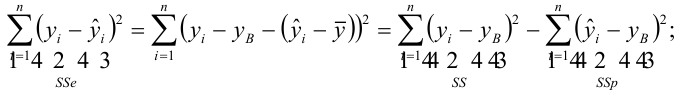
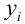 — наблюдаемое экспериментальное значение
— наблюдаемое экспериментальное значение  при
при 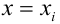
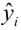 — предсказанное значение
— предсказанное значение 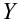 удовлетворяющее уравнению регрессии
удовлетворяющее уравнению регрессии
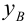 — средневыборочное значение
— средневыборочное значение 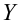
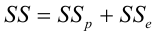
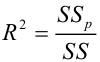 — коэффициент детерминации, доля изменчивости
— коэффициент детерминации, доля изменчивости 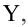 объясняемая рассматриваемой регрессионной моделью. Для парной линейной регрессии
объясняемая рассматриваемой регрессионной моделью. Для парной линейной регрессии 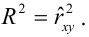
Коэффициент детерминации принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это используется для доказательства адекватности модели (качества регрессии). Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 0,5 (в этом случае коэффициент множественной корреляции превышает по модулю 0,7). Модели с коэффициентом детерминации выше 0,8 можно признать достаточно хорошими (коэффициент корреляции превышает 0,9). Подтверждение адекватности модели проводится на основе дисперсионного анализа путем проверки гипотезы о значимости коэффициента детерминации.
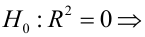 регрессия незначима
регрессия незначима
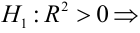 регрессия значима
регрессия значима
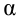 — уровень значимости
— уровень значимости
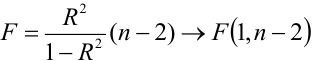 — статистический критерий
— статистический критерий
Критическая область — правосторонняя; 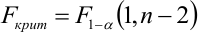
Если 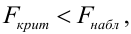 то нулевая гипотеза отвергается на заданном уровне значимости, следовательно, коэффициент детерминации значим, следовательно, регрессия адекватна.
то нулевая гипотеза отвергается на заданном уровне значимости, следовательно, коэффициент детерминации значим, следовательно, регрессия адекватна.
Мощность статистического критерия. Функция мощности
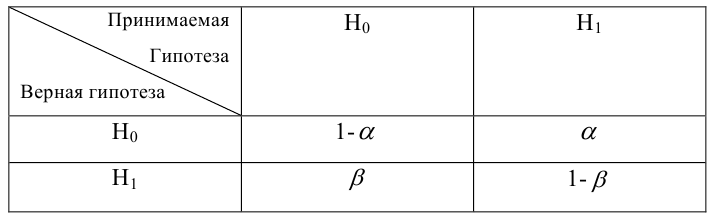
Определение. Мощностью критерия 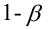 называют вероятность попадания критерия в критическую область при условии, что справедлива конкурирующая гипотеза.
называют вероятность попадания критерия в критическую область при условии, что справедлива конкурирующая гипотеза.
Задача: построить критическую область таким образом, чтобы мощность критерия была максимальной.
Определение. Наилучшей критической областью (НКО) называют критическую область, которая обеспечивает минимальную ошибку второго рода 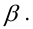
Пример:
По паспортным данным автомобиля расход топлива на 100 километров составляет 10 литров. В результате измерения конструкции двигателя ожидается, что расход топлива уменьшится. Для проверки были проведены испытания 25 автомобилей с модернизированным двигателем; выборочная средняя расхода топлива по результатам испытаний составила 9,3 литра. Предполагая, что выборка получена из нормально распределенной генеральной совокупности с математическим ожиданием 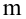 и дисперсией
и дисперсией 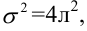 проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
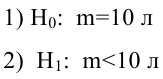
3) Уровень значимости 
4) Статистический критерий
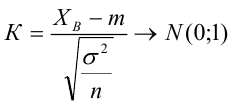
5) Критическая область — левосторонняя
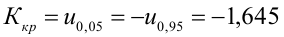
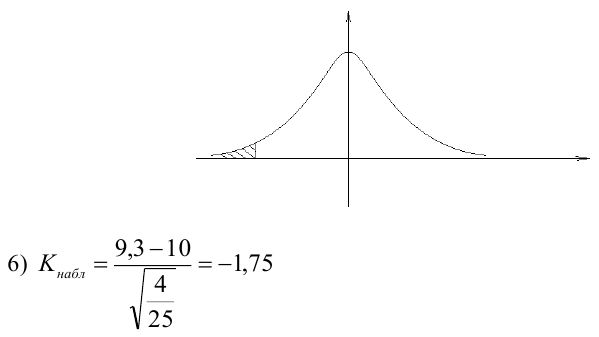
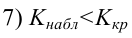 следовательно
следовательно 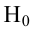 отвергается на уровне значимости
отвергается на уровне значимости 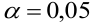
Пример:
В условиях примера 1 предположим, что наряду с 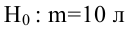 рассматривается конкурирующая гипотеза
рассматривается конкурирующая гипотеза 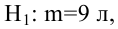 а критическая область задана неравенством
а критическая область задана неравенством 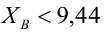 Найти вероятность ошибок I рода и II рода.
Найти вероятность ошибок I рода и II рода.
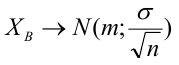
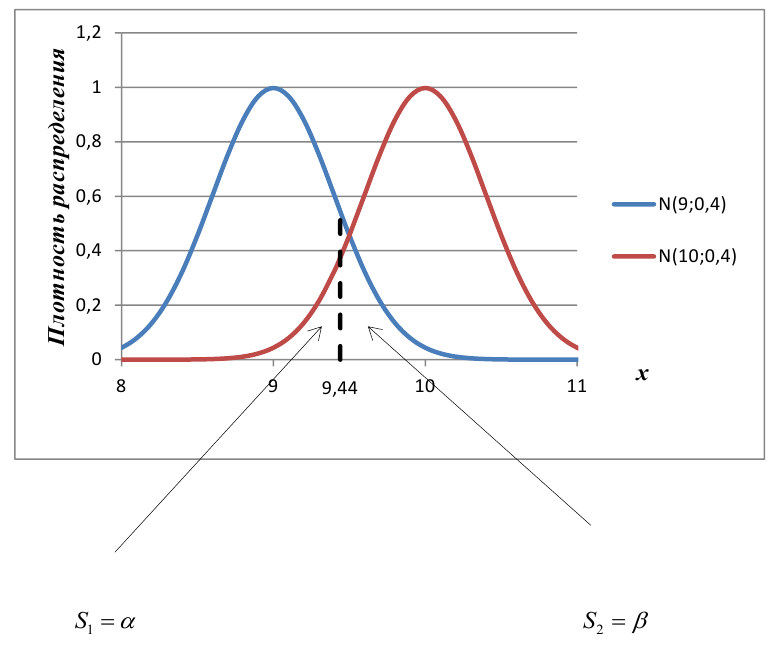
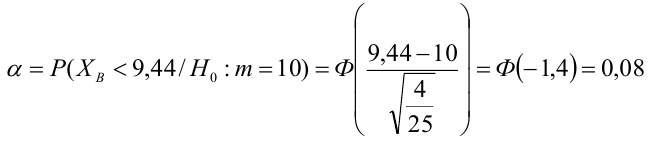
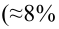 автомобилей имеют меньший расход топлива)
автомобилей имеют меньший расход топлива)
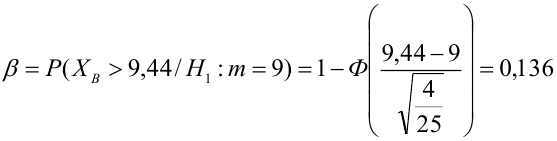
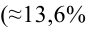 автомобилей, имеющих расход топлива 9л на 100 км, классифицируются как автомобили, имеющие расход 10 литров).
автомобилей, имеющих расход топлива 9л на 100 км, классифицируются как автомобили, имеющие расход 10 литров).
Определение. Пусть проверяется  — критическая область критерия с заданным уровнем значимости
— критическая область критерия с заданным уровнем значимости 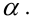 Функцией мощности критерия
Функцией мощности критерия 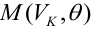 называется вероятность отклонения
называется вероятность отклонения  как функция параметра
как функция параметра  т.е.
т.е.
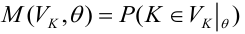
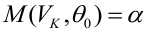 — ошибка 1-ого рода
— ошибка 1-ого рода
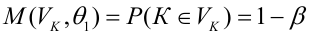 — мощность критерия
— мощность критерия
Пример:
Построить график функции мощности из примера 2 для 
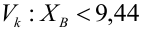 попадает в критическую область.
попадает в критическую область.
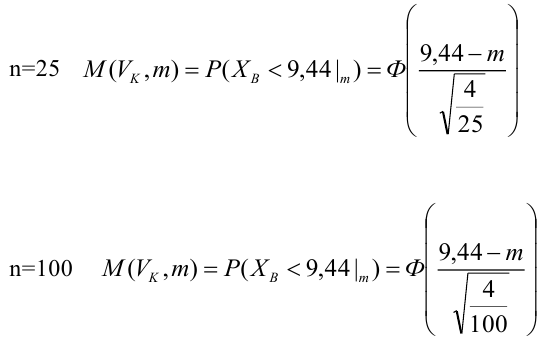
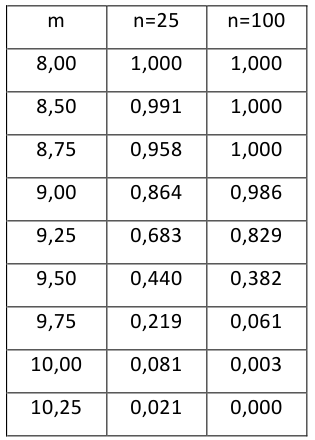
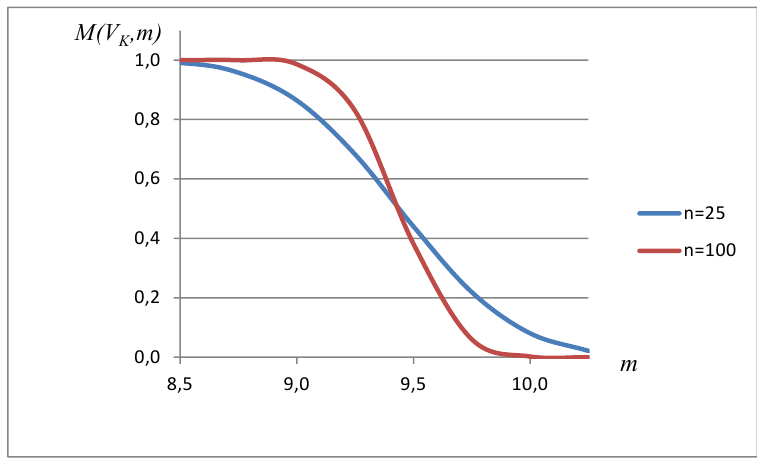
Пример:
Какой минимальный объем выборки следует взять в условии примера 2 для того, чтобы обеспечить 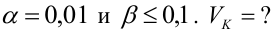
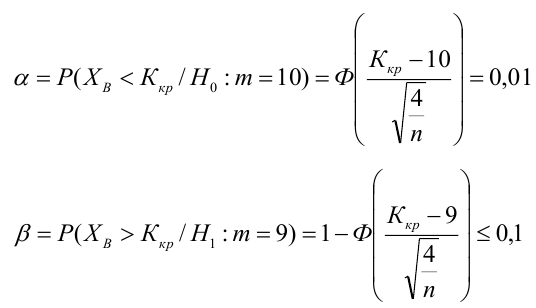
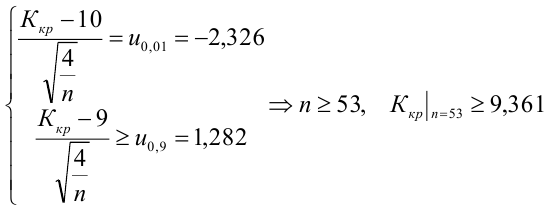
Лемма Неймана-Пирсона.
При проверке простой гипотезы 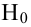 против простой альтернативной гипотезы
против простой альтернативной гипотезы 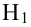 наилучшая критическая область (НКО) критерия заданного уровня значимости
наилучшая критическая область (НКО) критерия заданного уровня значимости 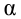 состоит из точек выборочного пространства (выборок объема
состоит из точек выборочного пространства (выборок объема  для которых справедливо неравенство:
для которых справедливо неравенство:
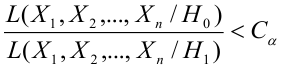
 — константа, зависящая от
— константа, зависящая от 
 — элементы выборки;
— элементы выборки;
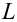 — функция правдоподобия при условии, что соответствующая гипотеза верна.
— функция правдоподобия при условии, что соответствующая гипотеза верна.
Пример:
Случайная величина 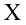 имеет нормальное распределение с параметрами
имеет нормальное распределение с параметрами 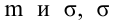 известно. Найти НКО для проверки
известно. Найти НКО для проверки 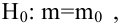 против
против 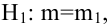 причем
причем 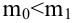
Решение:
Ошибка первого рода: 
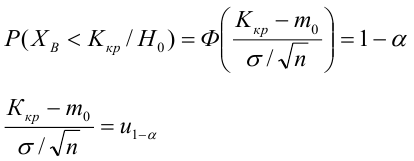
НКО: 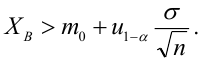
Пример:
Для зависимости заданной корреляционной табл. 13, найти оценки параметров
заданной корреляционной табл. 13, найти оценки параметров  уравнения линейной регрессии
уравнения линейной регрессии 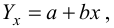 остаточную дисперсию; выяснить значимость уравнения регрессии при
остаточную дисперсию; выяснить значимость уравнения регрессии при 
Решение. Воспользуемся предыдущими результатами
Согласно формуле (24), уравнение регрессии будет иметь вид 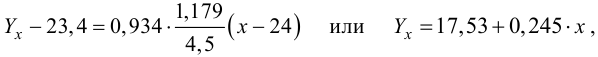 тогда
тогда 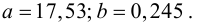
Для выяснения значимости уравнения регрессии вычислим суммы  Составим расчетную таблицу:
Составим расчетную таблицу:
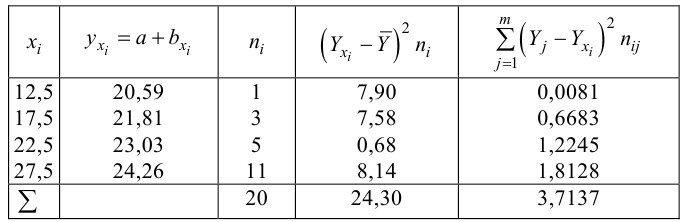
Из (27) и (28) по данным таблицы получим 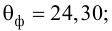
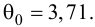
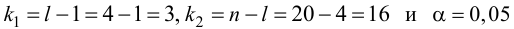 по табл. П7 находим
по табл. П7 находим 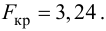
Вычислим статистику
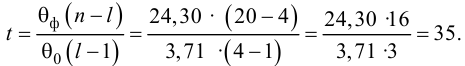
Так как 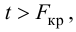 то уравнение регрессии значимо. Остаточная дисперсия равна
то уравнение регрессии значимо. Остаточная дисперсия равна 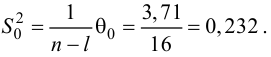
- Корреляционный анализ
- Статистические решающие функции
- Случайные процессы
- Выборочный метод
- Проверка гипотезы о равенстве вероятностей
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Проверка статистических гипотез
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартная ошибка оценки служит для того, чтобы выяснить, как линия регрессии соответствует набору данных. Если у вас есть набор данных, полученных в результате измерения, эксперимента, опроса или из другого источника, создайте линию регрессии, чтобы оценить дополнительные данные. Стандартная ошибка оценки характеризует, насколько верна линия регрессии.
-

1
Создайте таблицу с данными. Таблица должна состоять из пяти столбцов, и призвана облегчить вашу работу с данными. Чтобы вычислить стандартную ошибку оценки, понадобятся пять величин. Поэтому разделите таблицу на пять столбцов. Обозначьте эти столбцы так:[1]
-

2
Введите данные в таблицу. Когда вы проведете эксперимент или опрос, вы получите пары данных — независимую переменную обозначим как
, а зависимую или конечную переменную как
. Введите эти значения в первые два столбца таблицы.
- Не перепутайте данные. Помните, что определенному значению независимой переменной должно соответствовать конкретное значение зависимой переменной.
- Например, рассмотрим следующий набор пар данных:
- (1,2)
- (2,4)
- (3,5)
- (4,4)
- (5,5)
-

3
Вычислите линию регрессии. Сделайте это на основе представленных данных. Эта линия также называется линией наилучшего соответствия или линией наименьших квадратов. Расчет можно сделать вручную, но это довольно утомительно. Поэтому рекомендуем воспользоваться графическим калькулятором или онлайн-сервисом, которые быстро вычислят линию регрессии по вашим данным.[2]
- В этой статье предполагается, что уравнение линии регрессии дано (известно).
- В нашем примере линия регрессии описывается уравнением
.
-

4
Вычислите прогнозируемые значения по линии регрессии. С помощью уравнения линии регрессии можно вычислить прогнозируемые значения «y» для значений «x», которые есть и которых нет в наборе данных.
Реклама
-

1
Вычислите ошибку каждого прогнозируемого значения. В четвертом столбце таблицы запишите ошибку каждого прогнозируемого значения. В частности, вычтите прогнозируемое значение (
) из фактического (наблюдаемого) значения (
- В нашем примере вычисления будут выглядеть так:
-

2
Вычислите квадраты ошибок. Возведите в квадрат каждое значение четвертого столбца, а результаты запишите в последнем (пятом) столбце таблицы.
- В нашем примере вычисления будут выглядеть так:
-

3
Найдите сумму квадратов ошибок. Она пригодится для вычисления стандартного отклонения, дисперсии и других величин. Чтобы найти сумму квадратов ошибок, сложите все значения пятого столбца. [4]
- В нашем примере вычисления будут выглядеть так:
- В нашем примере вычисления будут выглядеть так:
-

4
Завершите расчеты. Стандартная ошибка оценки — это квадратный корень из среднего значения суммы квадратов ошибок. Обычно ошибка оценки обозначается греческой буквой
. Поэтому сначала разделите сумму квадратов ошибок на число пар данных. А потом из полученного значения извлеките квадратный корень.[5]
- Если рассматриваемые данные представляют всю совокупность, среднее значение находится так: сумму нужно разделить на N (количество пар данных). Если же рассматриваемые данные представляют некоторую выборку, вместо N подставьте N-2.
- В нашем примере, скорее всего, имеет место выборка, потому что мы рассматриваем всего 5 пар данных. Поэтому стандартную ошибку оценки вычислите следующим образом:
-

5
Интерпретируйте полученный результат. Стандартная ошибка оценки — это статистический показатель, которые оценивает, насколько близко измеренные данные лежат к линии регрессии. Ошибка оценка «0» означает, что каждая точка лежит непосредственно на линии. Чем выше ошибка оценки, тем дальше от линии регрессии лежат точки.[6]
- В нашем примере выборка достаточно маленькая, поэтому стандартная оценка ошибки 0,894 является довольно низкой и характеризует близко расположенные данные.
Реклама

Об этой статье
Эту страницу просматривали 4834 раза.
Была ли эта статья полезной?
Так как значения
![]() известны без ошибок, а значения
известны без ошибок, а значения![]() независимы и равноточны, то оценка
независимы и равноточны, то оценка
дисперсии вычисляется по формуле:
![]() ,
,
где
![]() ,
,
(23)
![]() –фактические
–фактические
значения результативного признака,
полученного по данным наблюдений,
![]() – значения результативного признака,
– значения результативного признака,
рассчитанного по уравнению регрессии
и полученного подстановкой значений
факторного признака в уравнение
регрессии:![]() .
.
В нашем примере![]() .
.
Средняя квадратическая
ошибка уравнения регрессии:
![]() .
.
Для нахождения
оценки дисперсии
![]() величины
величины![]() составим таблицу:
составим таблицу:
|
№ |
|
|
|
|
|
|
|
1 2 3 4 5 6 7 8 9 10 |
4,055 4,525 4,995 5,465 5,935 6,405 6,875 7,345 7,815 8,285 |
3 7 13 14 15 18 12 11 2 5 |
35,11 39,3329 52,1638 64,67 78,4647 94,23 111,4733 127,8209 153,35 165,174 |
30,8811 40,9186 52,2328 64,8238 78,6916 93,8362 110,2547 127,9559 146,9309 167,1827 |
17,8832 2,5143 0,0048 0,0236 0,05149 0,1551 1,4778 0,01822 41,2047 4,0350 |
53,6497 17,6001 0,0618 0,3311 0,7723 2,7918 17,7335 0,2004 82,4094 20,1752 |
![]()
![]() .
.
Средняя квадратическая
ошибка уравнения регрессии
![]() .
.
Сравним полученную
величину со средним квадратическим
отклонением результативного признака
![]() ,
,
получим![]() ,
,
т.е.![]() ,
,
следовательно, использование уравнения
регрессии является целесообразным.
2.10. Интервальные оценки параметров квадратичной линии регрессии генеральной совокупности
Доверительные
интервалы для коэффициентов ![]()
при заданной доверительной вероятности
![]() имеют вид:
имеют вид:![]() ,
,
где![]() определяется из таблицы для закона
определяется из таблицы для закона
распределения Стьюдента по выходным
величинам![]() и числу степеней свободы
и числу степеней свободы![]() .
.
В данном случае
![]() ,
,![]() ,
,
отсюда![]() .
.
Оценки
![]() коэффициентов
коэффициентов
![]()
определяются формулами
![]() ,
,
где
![]() ,
,![]() – определитель системы (22),
– определитель системы (22),![]() – алгебраическое дополнение элемента
– алгебраическое дополнение элемента![]() в определителе
в определителе![]() .
.
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
2.11. Нахождение коэффициента детерминации
Коэффициент
детерминации, интегрально характеризующий
точностные свойства уравнения регрессии,
определяем по формуле (21).
 ,
,
![]() ,
,![]() ,
,
![]() .
.
Сравним
![]() с
с![]() .
.![]() – следовательно, полученная регрессионная
– следовательно, полученная регрессионная
модель работоспособна.
2.12. Проверка адекватности регрессионной модели
Проверка адекватности
модели возможна только при
![]() ,
,
где![]() – число опытов (
– число опытов (![]() ),
),![]() – число оцениваемых коэффициентов
– число оцениваемых коэффициентов
регрессии математической модели (![]() ).
).
В нашем случае![]() ,
,
следовательно, можно проводить проверку
адекватности.
Найдем дисперсию
адекватности
![]() ,
,
где
![]() ;
;
![]() .
.
Получим
![]() .
.
Найдем
 ,где
,где
![]() ;
;![]() .
.
Найдем
![]() ,
,
где![]() – уровень значимости,
– уровень значимости,![]() – число степеней свободы дисперсии
– число степеней свободы дисперсии
адекватности,![]() – число степеней свободы дисперсии
– число степеней свободы дисперсии
воспроизводимости.
Сравним
![]() и
и![]() ,
,![]() .
.
Построенная модель
предсказывает значения выходной величины
с той же точностью, что и результаты
эксперимента.
Список литературы:
-
Гмурман
В.Е. Теория вероятностей и математическая
статистика: учеб. пособие для вузов.
М.: Высш. шк., 2003. – 479 с. -
Гмурман
В.Е. Руководство к решению задач по
теории вероятностей и математической
статистике: учеб. пособие для вузов.
М.: Высш. шк., 2003. – 405 с. -
Виленкин
Н.Я., Потапов В.Г. Задачник-практикум по
теории вероятностей с элементами
комбинаторики и математической
статистики. М.: Просвещение, 1979. – 112 с. -
Кремер
Н.Ш. Теория вероятностей и математическая
статистика. М.: ЮНИТИ-ДАНА, 2004. – 573 с.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Когда мы подгоняем регрессионную модель к набору данных, нас часто интересует, насколько хорошо регрессионная модель «подходит» к набору данных. Две метрики, обычно используемые для измерения согласия, включают R -квадрат (R2) и стандартную ошибку регрессии , часто обозначаемую как S.
В этом руководстве объясняется, как интерпретировать стандартную ошибку регрессии (S), а также почему она может предоставить более полезную информацию, чем R 2 .
Стандартная ошибка по сравнению с R-квадратом в регрессии
Предположим, у нас есть простой набор данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их баллы за экзамен:

Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

R-квадрат — это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной. При этом 65,76% дисперсии экзаменационных баллов можно объяснить количеством часов, потраченных на учебу.
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом случае наблюдаемые значения отклоняются от линии регрессии в среднем на 4,89 единицы.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание, что некоторые наблюдения попадают очень близко к линии регрессии, в то время как другие не так близки. Но в среднем наблюдаемые значения отклоняются от линии регрессии на 4,19 единицы .
Стандартная ошибка регрессии особенно полезна, поскольку ее можно использовать для оценки точности прогнозов. Примерно 95% наблюдений должны находиться в пределах +/- двух стандартных ошибок регрессии, что является быстрым приближением к 95% интервалу прогнозирования.
Если мы заинтересованы в прогнозировании с использованием модели регрессии, стандартная ошибка регрессии может быть более полезной метрикой, чем R-квадрат, потому что она дает нам представление о том, насколько точными будут наши прогнозы в единицах измерения.
Чтобы проиллюстрировать, почему стандартная ошибка регрессии может быть более полезной метрикой для оценки «соответствия» модели, рассмотрим другой пример набора данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их экзаменационная оценка:

Обратите внимание, что это точно такой же набор данных, как и раньше, за исключением того, что все значения s сокращены вдвое.Таким образом, студенты из этого набора данных учились ровно в два раза дольше, чем студенты из предыдущего набора данных, и получили ровно половину экзаменационного балла.
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

Обратите внимание, что R-квадрат 65,76% точно такой же, как и в предыдущем примере.
Однако стандартная ошибка регрессии составляет 2,095 , что ровно вдвое меньше стандартной ошибки регрессии в предыдущем примере.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание на то, что наблюдения располагаются гораздо плотнее вокруг линии регрессии. В среднем наблюдаемые значения отклоняются от линии регрессии на 2,095 единицы .
Таким образом, несмотря на то, что обе модели регрессии имеют R-квадрат 65,76% , мы знаем, что вторая модель будет давать более точные прогнозы, поскольку она имеет более низкую стандартную ошибку регрессии.
Преимущества использования стандартной ошибки
Стандартную ошибку регрессии (S) часто бывает полезнее знать, чем R-квадрат модели, потому что она дает нам фактические единицы измерения. Если мы заинтересованы в использовании регрессионной модели для получения прогнозов, S может очень легко сказать нам, достаточно ли точна модель для прогнозирования.
Например, предположим, что мы хотим создать 95-процентный интервал прогнозирования, в котором мы можем прогнозировать результаты экзаменов с точностью до 6 баллов от фактической оценки.
Наша первая модель имеет R-квадрат 65,76%, но это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. К счастью, мы также знаем, что у первой модели показатель S равен 4,19. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*4,19 = +/- 8,38 единиц, что слишком велико для нашего интервала прогнозирования.
Наша вторая модель также имеет R-квадрат 65,76%, но опять же это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. Однако мы знаем, что вторая модель имеет S 2,095. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*2,095= +/- 4,19 единиц, что меньше 6 и, следовательно, будет достаточно точным для использования для создания интервалов прогнозирования.
Дальнейшее чтение
Введение в простую линейную регрессию
Что такое хорошее значение R-квадрата?
Whenever we fit a linear regression model, the model takes on the following form:
Y = β0 + β1X + … + βiX +ϵ
where ϵ is an error term that is independent of X.
No matter how well X can be used to predict the values of Y, there will always be some random error in the model.
One way to measure the dispersion of this random error is by using the standard error of the regression model, which is a way to measure the standard deviation of the residuals ϵ.
This tutorial provides a step-by-step example of how to calculate the standard error of a regression model in Excel.
Step 1: Create the Data
For this example, we’ll create a dataset that contains the following variables for 12 different students:
- Exam Score
- Hours Spent Studying
- Current Grade

Step 2: Fit the Regression Model
Next, we’ll fit a multiple linear regression model using Exam Score as the response variable and Study Hours and Current Grade as the predictor variables.
To do so, click the Data tab along the top ribbon and then click Data Analysis:

If you don’t see this option available, you need to first load the Data Analysis ToolPak.
In the window that pops up, select Regression. In the new window that appears, fill in the following information:

Once you click OK, the output of the regression model will appear:

Step 3: Interpret the Standard Error of Regression
The standard error of the regression model is the number next to Standard Error:

The standard error of this particular regression model turns out to be 2.790029.
This number represents the average distance between the actual exam scores and the exam scores predicted by the model.
Note that some of the exam scores will be further than 2.79 units away from the predicted score while some will be closer. But, on average, the distance between the actual exam scores and the predicted scores is 2.790029.
Also note that a smaller standard error of regression indicates that a regression model fits a dataset more closely.
Thus, if we fit a new regression model to the dataset and ended up with a standard error of, say, 4.53, this new model would be worse at predicting exam scores than the previous model.
Additional Resources
Another common way to measure the precision of a regression model is to use R-squared. Check out this article for a nice explanation of the benefits of using the standard error of the regression to measure precision compared to R-squared.