
Добавил:
BIV65
Опубликованный материал нарушает ваши авторские права? Сообщите нам.
Вуз:
Предмет:
Файл:
Помехоустойчивое кодирование
Скачиваний:
0
Добавлен:
17.06.2023
Размер:
65.16 Кб
Скачать
![]()
1. ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
Помехоустойчивое кодирование (англ. Error Correcting Coding, ECC) — процесс преобразования информации, предоставляющий возможность обнаружить и исправить ошибки, возникающие при передаче информации по каналам передачи данных.
Под ошибкой при этом понимают ситуацию, когда в результате действия помех и искажений в канале передачи данных приемник принимает неверное решение, отождествляя принятый сигнал не с фактически переданным символом, а с каким-либо другим [1].
Процесс помехоустойчивого кодирования заключается во введении избыточности, т. е. для передачи информации используется код, у которого используются не все возможные комбинации, а только некоторые из них. Такие коды называют избыточными или корректирующими.
Соответственно, процесс введения избыточности (преобразование информационных символов в кодовое слово) называется кодированием, а обратный процесс восстановления информации из кодового слова, возможно содержащего ошибки, — декодированием.
В рамках цифровой системы передачи данных задачи кодирования и декодирования возложены на кодер и декодер соответственно. Структура цифровой системы передачи данных показана на рис. 1.1 [2].
|
Двоичные |
Дискретный канал |
||
|
Источник |
данные |
Модулятор |
|
|
данных |
Кодер |
||
|
S(T ) |
|||
|
Физический |
Помехи |
||
|
Информация |
канал |
N(T ) |
|
|
о надежности |
ˆ |
||
|
Двоичные |
S(T ) |
||
|
Получатель |
данные |
Демодулятор |
|
|
данных |
Декодер |
||
Рис. 1.1. Структура цифровой системы передачи данных
Часто декодеру доступна информация, указывающая на надежность решений, принимаемых о различных символах кодового слова. Такая информация может быть использована для упрощения процесса декодирования, либо для улучшения его характеристик [2].
В целом, способность помехоустойчивых кодов определять и исправлять ошибки — их корректирующие свойства — зависит от правил постро-
6
ения этих кодов и параметров кода (числа разрядов, избыточности и др.), а также от используемых алгоритмов декодирования.
1.1. Основные параметры помехоустойчивых кодов
Основными параметрами, характеризующими корректирующие свойства кодов являются:
1)избыточность кода;
2)кодовое расстояние;
3)кратность гарантированно обнаруживаемых ошибок;
4)кратность гарантированно исправляемых ошибок.
1.1.1.Избыточность корректирующего кода
Избыточность корректирующего кода может быть абсолютной и относительной. Под абсолютной избыточностью понимают число вводимых дополнительных разрядов
R = N − K,
где N — число кодовых символов на выходе кодера, соответствующих K информационным символам на его входе.
Относительной избыточностью корректирующего кода называют величину
Rотн = R = N − K = 1 − K . N N N
С ней связана так называемая относительная скорость передачи информации или скорость кода, которая показывает, какую часть общего числа символов кодовой комбинации составляют информационные символы.
K
N
= 1 − Rотн.
Если производительность источника равна H символов в секунду, то скорость передачи после кодирования этой информации будет равна
K
R = H · .
N
1.1.2. Кодовое расстояние
Кодовое расстояние D или расстояние Хемминга характеризует cтепень различия любых двух кодовых комбинаций. Оно выражается числом разрядов, в которых комбинации отличаются одна от другой.
Чтобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число единиц в поразрядной сумме этих
7

Dmin
комбинаций по модулю 2:
10011 11001 = 01010 D = 2.
Кодовое расстояние может быть различным. Так, в первичном натуральном безызбыточном коде это расстояние для различных комбинаций может различаться от единицы до N, где N — длина (значность) кода.
Для помехоустойчивого кода наиболее важным является минимальное кодовое расстояние — наименьшее кодовое расстояние из всех между всеми парами кодовых комбинаций.
В безызбыточном коде все комбинации являются разрешенными, Dmin = 1. Поэтому искажение хотя бы одного символа в комбинации будет приводить к получению ошибочного сообщения.
1.1.3. Кратности гарантированно обнаруживаемых и гарантированно исправляемых ошибок
Эти параметры напрямую зависят от минимального кодового расстояния. Под кратностью понимается количество поражённых ошибками символов кодовой комбинации.
В общем случае при необходимости обнаруживать ошибки кратности Tобн минимальное кодовое расстояние должно быть, по крайней мере, на единицу больше Tобн, т. е.
Dmin ≥ Tобн + 1.
Соответственно, кратность гарантированно обнаруживаемых кодом ошибок равна
Tобн ≤ Dmin − 1.
Кратность гарантированно исправляемых кодом ошибок вычисляется по формуле
T ≤ Dmin − 1 .
2
Таким образом, код, имеющий минимальное кодовое расстояние Dmin = 3, позволяет гарантированно обнаружить Tобн = 2 и менее ошибок и гарантированно исправить T = 1 ошибку.
1.2. Классификация помехоустойчивых кодов
Помехоустойчивые коды классифицируются по различным признакам. Одной из основных классификаций является деление кодов на блочные и непрерывные.
8
Блочный (блоковый) код является кодом без памяти. Кодер блочного кода отображает подающийся на вход блок информационных символов длиной K в кодовую последовательность из N выходных символов. Термин «без памяти» указывает, что каждый блок из N символов зависит только от соответствующего блока из K символов и не зависит от других блоков [2].
Основыми параметрами блочных кодов являются длина информационного блока K, длина кодового слова N, скорость кода NK и минимальное кодовое расстояние Dmin.
Непрерывные или древовидные коды — это помехоустойчивые коды использующие непрерывную, или последовательную, обработку информации короткими фрагментами (блоками). Кодер древовидного кода является устройством с памятью. На его вход поступают наборы из K входных информационных символов, а на выходе появляются наборы из N кодовых символов. Каждый набор N кодовых символов зависит от текущего входного набора и от V предыдущих входных символов. Следовательно кодер должен содержать устройство памяти на M = K + V входных символов. Параметр M часто называют длиной кодового ограничения кода [2].
Также непрерывные коды характеризуются скоростью кода NK и свободным расстоянием Dсв [2].
Чаще всего используются линейные древовидные коды, называемые
сверточными.
Особое место в классификации помехоустойчивых кодов занимают каскадные коды и турбо коды, представляющие из себя комбинации блочных и/или непрерывных кодов [3].
Другой подход к классификации делит коды на линейные и нелинейные. Линейные коды образуют векторное пространство, в котором два кодовых слова при сложении по определенному правилу дают в результате третье кодовое слово [2].
Практически все применяемые на практике схемы кодирования основаны на использовании линейных кодов. Двоичные линейные блоковые коды часто называют групповыми кодами, так как их кодовые слова образуют математическую структуру, называемую группа [2].
Нелинейные коды применяются гораздо реже линейных. К нелинейным кодам относится код с контрольным суммированием, в котором проверочные разряды являются записью суммы единиц в кодовой комбинации [1].
По способу кодирования коды делятся на систематические и несистематические. В первом случае информационные символы передаются на выход декодера без изменения и к ним добавляются проверочные символы. В
9
случае несистематического кодирования информационные символы в явном виде в кодовом слове отсутствуют.
Большинство помехоустойчивых кодов может быть использовано как для обнаружения, так и для исправления ошибок, хотя есть коды, которые позволяют лишь обнаруживать ошибки. Поскольку избыточность, требуемая для обнаружения ошибок, меньше избыточности для исправления ошибок, то коды с обнаружением ошибок часто используют в системах с обратной связью [1].
Ещё одним вариантом деления помехоустойчивых кодов является разделение их на коды, исправляющие случайные ошибки, и коды, исправляющие пакеты (пачки) ошибок. Хотя для исправления пачек ошибок было разработано большое количество кодов с хорошими характеристиками, часто оказывается выгодным использовать коды, исправляющие случайные ошибки, совместно с устройствами перемежения/деперемежения [2]. Также стоит отметить, что существуют алгоритмы декодирования, позволяющие использовать коды, рассчитанные на исправление случайных ошибок, для исправления пачек ошибок без использования перемежителей. К таким алгоритмам относится, например, мажоритарное декодирование на основе двойственного базиса [4].
Контрольные вопросы
1.Что такое помехоустойчивое кодирование?
2.Опишите структуру цифровой системы передачи данных.
3.Дайте понятие избыточности корректирующего кода. Что такое абсолютная и относительная избыточности? Как определяется скорость кода?
4.Что такое кодовое расстояние? Как оно определяется?
5.Как рассчитываются кратности гарантированно обнаруживаемых и гарантированно исправляемых ошибок?
6.Приведите классификацию помехоустойчивых кодов.
10
Соседние файлы в предмете Основы теории передачи данных
- #
17.06.20232.01 Кб06.txt
- #
- #
- #
- #
- #
- #
Все помехоустойчивые коды делятся на блоковые и непрерывные (их называют также цепные или рекуррентные). При блоковом кодировании данные передаются отдельными блоками (словами, кодовыми комбинациями). При этом поступающие в кодер символы, разбиваются на блоки по k информационных символов. В кодере этот блок информационных символов преобразуется в блок из ![]() кодовых символов, где п называется длиной кода. Добавленные при кодировании r = n – k символов являются проверочными. Такой блоковый код принято обозначать как (n, k) – код. Величину R = k / n называют скоростью кода, а величину, обратную скорости, Rи = n / k называют избыточностью кода.
кодовых символов, где п называется длиной кода. Добавленные при кодировании r = n – k символов являются проверочными. Такой блоковый код принято обозначать как (n, k) – код. Величину R = k / n называют скоростью кода, а величину, обратную скорости, Rи = n / k называют избыточностью кода.
Проверочные символы являются избыточными, они необходимы для обнаружения и (или) исправления ошибок, возникших при передаче. Существуют безызбыточные (примитивные) коды. У этих кодов проверочных символов нет (n = k), поэтому у них самая высокая скорость кода R = 1, но они не способны обнаруживать ошибки.
Ошибки при передаче кодового слова возникают потому, что некоторые из переданных символов могут быть приняты неверно. Принцип обнаружения ошибок заключается в следующем. Если блоковый (n, k) – код имеет основание (количество символов в используемом алфавите) q, то возможно Q = qn различных кодовых слов. Для передачи же используются только Qр = qk кодовых слов, которые называются разрешенными. Остальные Qз = Q – Qр слов априорно для передачи не используются и называются запрещенными.
В дальнейшем будут рассматриваться только двоичные коды, у которых алфавит состоит из двух символов 0 и 1, т. е. с основанием q = 2.
В памяти кодера и декодера хранится таблица разрешенных слов. Работа кодера заключается в выборе разрешенного кодового слова, соответствующего поступившему информационному слову. Приходящее в декодер кодовое слово сравнивается с таблицей разрешенных слов и, если происходит совпадение, то потребитель получает информационное слово, соответствующее данному разрешенному слову. Если же совпадение не наступает, то слово считается запрещенным, а потребитель получает сообщение об ошибке. Однако если совокупность ошибок превратит одно разрешенное слово в другое разрешенное, то возникшие ошибки не могут быть обнаружены.
Пример 1. Требуется передача сообщения о наступлении одного из четырех возможных событий A, B, C, D. Эти события представлены информационными словами 00, 01, 10, 11 соответственно. При передаче этих слов безызбыточным кодом все возможные комбинации являются разрешенными. Поэтому достаточно искажения хотя бы одного символа, чтобы сообщение было принято неверно. Так, если передавалось сообщение A в виде кодового слова 00, а принято было слово 01, то декодер, найдя в таблице такое разрешенное слово, вынесет решение о приеме сообщения B.
Если к вышеперечисленным информационным словам добавить по одному избыточному символу, поставив в соответствие разрешенные слова 000, 011, 101, 110, то искажение одного символа в переданном слове можно обнаружить. Так, если передавалось сообщение A в виде кодового слова 000, а принято было слово 001, то декодер, не найдя в таблице такого разрешенного слова, объявит принятое слово запрещенным и сообщит об обнаружении ошибки в слове. Однако если было принято слово 011, то декодер вынесет решение о приеме сообщения B.
Для сравнения слов необходимо задать метрику, т. е. способ измерения расстояний между кодовыми словами. Известно несколько способов выбора метрики, из которых наиболее распространенным является метрика Хэмминга. Расстоянием Хэмминга между двумя кодовыми словами называется количество несовпадающих символов в этих словах. Важнейшей характеристикой блочного кода является кодовое расстояние – d, оно равно наименьшему расстоянию из всех возможных для данного кода.
Пример 2. Для передачи используются три разрешенных слова 000, 100, 111. Расстояние между первым и вторым словами равно 1, между вторым и третьим словами – 2, а между первым и вторым – 3. Кодовое расстояние для данного кода d = 1.
Очевидно, что у безызбыточного кода d = 1, так как между любой парой его слов расстояние равно единице. Этот код не позволяет обнаруживать ошибки. Приведенный в примере 1 избыточный код (он называется кодом с проверкой на четность) имеет d = 2. Он позволяет гарантировано обнаружить однократную ошибку.
Кратностью ошибки называется количество неправильно принятых символов в кодовом слове. Если искажения символов возникают независимо друг от друга, то ошибки меньшей кратности более вероятны, чем ошибки большей кратности. Следовательно, прежде всего требуется вести борьбу с ошибками малой кратности.
Можно заметить, что максимальная кратность гарантировано обнаруживаемой ошибки tо = d – 1. Действительно, при возникновении необнаруженной ошибки одно разрешенное слово должно превратиться в другое разрешенное слово. А для этого надо, чтобы кратность возникшей ошибки была не менее d, поскольку все разрешенные слова по определению кодового расстояния различаются не менее, чем на d символов. Если же принятое кодовое слово хотя бы на один символ отличается от разрешенных кодовых слов, то будет зафиксировано появление ошибки.
При декодировании вместо обнаружения ошибок возможно их исправление. Так, если было принято запрещенное кодовое слово, то можно не отбрасывать его, а найти наиболее похожее разрешенное слово и объявить его принятым. Таким образом, возникшие при передаче ошибки считаются исправленными, и потребитель получает не сообщение об ошибке, а очередное информационное слово. При декодировании с исправлением ошибок решение принимается по минимуму расстояния Хэмминга, т. е. переданным считается то разрешенное кодовое слово, которое отличается от принятого слова наименьшим количеством несовпадающих символов.
Пример 3. Для передачи используется два разрешенных кодовых слова 000 и 111. Было принято слово 001, на беглый взгляд оно больше похоже на 000, чем на 111. Действительно, слово 001 от первого разрешенного слова отличается на один символ, а от второго на два. Так как однократная ошибка вероятнее двукратной, то скорее всего было передано первое слово и в нем исказился один символ. Декодер принимает решение по минимуму расстояния Хэмминга и объявляет принятым разрешенное слово 000.
В
рассмотренном примере код имеет d = 3, он позволяет гарантировано исправлять однократную ошибку. Можно заметить, что максимальная кратность гарантировано исправляемой ошибки :
где [x] –целая часть числа x.
Существует так называемый прием со стиранием. Это частный случай приема с мягким решением. Его особенность состоит в том, что решающее устройство имеет область неопределенности, в которую попадают все сигналы, не превысившие установленный порог. Решающее устройство выдает при этом специальный символ, заменяющий неуверенно принятый сигнал. Этот символ оказывается, таким образом, «стертым». Так, при передаче двоичным кодом на выходе решающего устройства появляется один из трех символов: 0, 1 и символ стирания Х.
Восстановить стертые знаки часто оказывается легче, чем исправить ошибочные. Это обусловлено тем, что местонахождение стертых знаков известно, так как оно обозначено символом стирания Х, тогда как местоположение ошибок неизвестно, и каждый из знаков 0 или 1 может быть как верным, так и неверным.
Для сохранения различимости кодовых комбинаций при стирании не более s знаков кодовое расстояние d должно удовлетворять условию:
![]()
Для того, чтобы код мог одновременно исправлять t ошибок и восстанавливать s стертых символов кодовое расстояние должно быть:
![]()
Преимущество кодов со стираниями очевидно: например, при d = 3 такой код может как и обычный исправить одиночную ошибку, но может восстановить два стертых символа.
Описанный выше метод кодирования и декодирования, основанный на запоминании таблицы разрешенных слов, называется универсальным, поскольку годится для всех блочных кодов. Однако этот метод практически не применяется из-за сложности реализации и низкого быстродействия. Если длина информационного слова достаточно велика, то требуется большой объем памяти для хранения всех разрешенных слов. Кроме того, сравнение принятого слова со всей таблицей может продолжаться очень долго, что недопустимо при работе в режиме реального времени. Поэтому созданы другие методы кодирования и декодирования блочных кодов, в которых используется не поиск разрешенных слов, а математические операции над информационными и проверочными символами.
Чаще всего применяются систематические коды. Систематическим называется такой блочный код, у которого информационные и проверочные символы расположены на одних и тех же позициях во всех кодовых словах
В примере 1 был рассмотрен избыточный код с проверкой на четность. При его кодировании к информационному слову добавляется один проверочный символ так, чтобы количество единиц в кодовом слове было четным. При декодировании проверяется выполнение этого условия. Если количество единиц в принятом слове нечетно, то слово является запрещенным. Таким образом, можно обойтись без запоминания таблицы разрешенных слов.
Если в кодере используются лишь линейные операции над поступающими информационными символами, то код называется линейным. Принцип кодирования и декодирования линейного кода заключается в системе линейных уравнений, в которую входят информационные и проверочные символы. Для каждого кода эта система своя. Рассмотрим её на примере кода (7, 4), имеющего d = 3.
a1 а2 а3 а5 = 0
а2 а3 а4 а6 = 0
а1 а2 а4 а7 = 0
где — знак сложения по модулю 2, символы а1, а2, а3, а4 являются информационными, а символы а5, а6, а7 – проверочными. При кодировании проверочные символы вычисляются из информационных так, чтобы они удовлетворяли системе уравнений. При декодировании символы принятого слова подставляются в систему уравнений и вычисляется её правая часть. Эта правая часть представляет собой вектор, который называется исправляющим вектором или синдромом. Анализ синдрома позволяет исправлять ошибки. Каждому возможному синдрому соответствует номер искаженного символа.
|
Синдром |
Номер искаженного символа |
|
000 |
Ошибок не обнаружено |
|
101 |
1 |
|
111 |
2 |
|
110 |
3 |
|
011 |
4 |
Проверочные символы вычисляются с помощью производящей (порождающей) матрицы. Производящая матрица G – это таблица, у которой k строк и n столбцов, в которой записаны k линейно независимых разрешенных комбинаций данного кода. По ней можно построить все остальные разрешенные кодовые комбинации, складывая поразрядно по модулю 2 строки производящей матрицы во всех возможных сочетаниях. В памяти кодера достаточно иметь производящую матрицу. С помощью набора сумматоров можно получить любую разрешенную кодовую комбинацию.
Производящую матрицу принято представлять в каноническом виде. Для рассматриваемого кода она будет:

Где левая часть матрицы — единичная матрица, соответствующая информационным символам, а правая часть матрицы соответствует проверочным символам. Схема кодирования строится на основе производящей матрицы. Кодер состоит из k-элементного регистра для информационного слова и n – k сумматоров по модулю 2. Элементы правой части производящей матрицы pij отвечают за вычисление проверочных символов. Они показывают связь i-ой ячейки регистра с j-м сумматором. Если pij = 1, то связь есть, если pij = 0 , то связи нет.
Д
ля декодирования требуется проверочная матрица H, содержащая n – k строк и n столбцов. В каждой строке этой матрицы единицы находятся в тех разрядах, которые входят в соответствующее проверочное уравнение. Для рассмотренного кода Хэмминга (7, 4) проверочная матрица будет иметь вид:
Существует особый класс блочных линейных кодов – циклические коды. Они отличаются тем, что всякая циклическая перестановка символов разрешенного кодового слова приводит также к разрешенному слову. Все кодовые комбинации можно получить циклическим сдвигом одного слова. Поэтому важным достоинством циклических кодов является то, что операции кодировании и декодирования легко реализуются на сдвигающих регистрах.
Назначение помехоустойчивого кодирования – защита информации от помех и ошибок при передаче и хранении информации. Помехоустойчивое кодирование необходимо для устранения ошибок, которые возникают в процессе передачи, хранения информации. При передачи информации по каналу связи возникают помехи, ошибки и небольшая часть информации теряется.

Без использования помехоустойчивого кодирования было бы невозможно передавать большие объемы информации (файлы), т.к. в любой системе передачи и хранении информации неизбежно возникают ошибки.
Рассмотрим пример CD диска. Там информация хранится прямо на поверхности диска, в углублениях, из-за того, что все дорожки на поверхности, часто диск хватаем пальцами, елозим по столу и из-за этого без помехоустойчивого кодирования, информацию извлечь не получится.

Использование кодирования позволяет извлекать информацию без потерь даже с поврежденного CD/DVD диска, когда какая либо область становится недоступной для считывания.
В зависимости от того, используется в системе обнаружение или исправление ошибок с помощью помехоустойчивого кода, различают следующие варианты:
- запрос повторной передачи (Automatic Repeat reQuest, ARQ): с помощью помехоустойчивого кода выполняется только обнаружение ошибок, при их наличии производится запрос на повторную передачу пакета данных;
- прямое исправление ошибок (Forward Error Correction, FEC): производится декодирование помехоустойчивого кода, т. е. исправление ошибок с его помощью.
Возможен также гибридный вариант, чтобы лишний раз не гонять информацию по каналу связи, например получили пакет информации, попробовали его исправить, и если не смогли исправить, тогда отправляется запрос на повторную передачу.
Исправление ошибок в помехоустойчивом кодировании
Любое помехоустойчивое кодирование добавляет избыточность, за счет чего и появляется возможность восстановить информацию при частичной потере данных в канале связи (носителе информации при хранении). В случае эффективного кодирования убирали избыточность, а в помехоустойчивом кодировании добавляется контролируемая избыточность.
Простейший пример – мажоритарный метод, он же многократная передача, в котором один символ передается многократно, а на приемной стороне принимается решение о том символе, количество которых больше.
Допустим есть 4 символа информации, А, B, С,D, и эту информацию повторяем несколько раз. В процессе передачи информации по каналу связи, где-то возникла ошибка. Есть три пакета (A1B1C1D1|A2B2C2D2|A3B3C3D3), которые должны нести одну и ту же информацию.

Но из картинки справа, видно, что второй символ (B1 и C1) они отличаются друг от друга, хотя должны были быть одинаковыми. То что они отличаются, говорит о том, что есть ошибка.
Необходимо найти ошибку с помощью голосования, каких символов больше, символов В или символов С? Явно символов В больше, чем символов С, соответственно принимаем решение, что передавался символ В, а символ С ошибочный.
Для исправления ошибок нужно, как минимум 3 пакета информации, для обнаружения, как минимум 2 пакета информации.
Параметры помехоустойчивого кодирования
Первый параметр, скорость кода R характеризует долю информационных («полезных») данных в сообщении и определяется выражением: R=k/n=k/m+k
- где n – количество символов закодированного сообщения (результата кодирования);
- m – количество проверочных символов, добавляемых при кодировании;
- k – количество информационных символов.
Параметры n и k часто приводят вместе с наименованием кода для его однозначной идентификации. Например, код Хэмминга (7,4) значит, что на вход кодера приходит 4 символа, на выходе 7 символов, Рида-Соломона (15, 11) и т.д.
Второй параметр, кратность обнаруживаемых ошибок – количество ошибочных символов, которые код может обнаружить.
Третий параметр, кратность исправляемых ошибок – количество ошибочных символов, которые код может исправить (обозначается буквой t).
Контроль чётности
Самый простой метод помехоустойчивого кодирования это добавление одного бита четности. Есть некое информационное сообщение, состоящее из 8 бит, добавим девятый бит.
Если нечетное количество единиц, добавляем 0.
1 0 1 0 0 1 0 0 | 0
Если четное количество единиц, добавляем 1.
1 1 0 1 0 1 0 0 | 1
Если принятый бит чётности не совпадает с рассчитанным битом чётности, то считается, что произошла ошибка.
1 1 0 0 0 1 0 0 | 1
Под кратностью понимается, всевозможные ошибки, которые можно обнаружить. В этом случае, кратность исправляемых ошибок 0, так как мы не можем исправить ошибки, а кратность обнаруживаемых 1.
Есть последовательность 0 и 1, и из этой последовательности составим прямоугольную матрицу размера 4 на 4. Затем для каждой строки и столбца посчитаем бит четности.
Прямоугольный код – код с контролем четности, позволяющий исправить одну ошибку:

И если в процессе передачи информации допустим ошибку (ошибка нолик вместо единицы, желтым цветом), начинаем делать проверку. Нашли ошибку во втором столбце, третьей строке по координатам. Чтобы исправить ошибку, просто инвертируем 1 в 0, тем самым ошибка исправляется.
Этот прямоугольный код исправляет все одно-битные ошибки, но не все двух-битные и трех-битные.
Рассчитаем скорость кода для:
- 1 1 0 0 0 1 0 0 | 1
Здесь R=8/9=0,88
- И для прямоугольного кода:
Здесь R=16/24=0,66 (картинка выше, двадцать пятую единичку (бит четности) не учитываем)
Более эффективный с точки зрения скорости является первый вариант, но зато мы не можем с помощью него исправлять ошибки, а с помощью прямоугольного кода можно. Сейчас на практике прямоугольный код не используется, но логика работы многих помехоустойчивых кодов основана именно на прямоугольном коде.
Классификация помехоустойчивых кодов
- Непрерывные — процесс кодирования и декодирования носит непрерывный характер. Сверточный код является частным случаем непрерывного кода. На вход кодера поступил один символ, соответственно, появилось несколько на выходе, т.е. на каждый входной символ формируется несколько выходных, так как добавляется избыточность.
- Блочные (Блоковые) — процесс кодирования и декодирования осуществляется по блокам. С точки зрения понимания работы, блочный код проще, разбиваем код на блоки и каждый блок кодируется в отдельности.
По используемому алфавиту:
- Двоичные. Оперируют битами.
- Не двоичные (код Рида-Соломона). Оперируют более размерными символами. Если изначально информация двоичная, нужно эти биты превратить в символы. Например, есть последовательность 110 110 010 100 и нужно их преобразовать из двоичных символов в не двоичные, берем группы по 3 бита — это будет один символ, 6, 6, 2, 4 — с этими не двоичными символами работают не двоичные помехоустойчивые коды.
Блочные коды делятся на
- Систематические — отдельно не измененные информационные символы, отдельно проверочные символы. Если на входе кодера присутствует блок из k символов, и в процессе кодирования сформировали еще какое-то количество проверочных символов и проверочные символы ставим рядом к информационным в конец или в начало. Выходной блок на выходе кодера будет состоять из информационных символов и проверочных.
- Несистематические — символы исходного сообщения в явном виде не присутствуют. На вход пришел блок k, на выходе получили блок размером n, блок на выходе кодера не будет содержать в себе исходных данных.
В случае систематических кодов, выходной блок в явном виде содержит в себе, то что пришло на вход, а в случае несистематического кода, глядя на выходной блок нельзя понять что было на входе.

Смотря на картинку выше, код 1 1 0 0 0 1 0 0 | 1 является систематическим, на вход поступило 8 бит, а на выходе кодера 9 бит, которые в явном виде содержат в себе 8 бит информационных и один проверочный.

Код Хэмминга
Код Хэмминга — наиболее известный из первых самоконтролирующихся и самокорректирующихся кодов. Позволяет устранить одну ошибку и находить двойную.

Код Хэмминга (7,4) — 4 бита на входе кодера и 7 на выходе, следовательно 3 проверочных бита. С 1 по 4 информационные биты, с 6 по 7 проверочные (см. табл. выше). Пятый проверочный бит y5, это сумма по модулю два 1-3 информационных бит. Сумма по модулю 2 это вычисление бита чётности.
Декодирование кода Хэмминга
Декодирование происходит через вычисление синдрома по выражениям:

Синдром это сложение бит по модулю два. Если синдром не нулевой, то исправление ошибки происходит по таблице декодирования:

Расстояние Хэмминга
Расстояние Хэмминга — число позиций, в которых соответствующие символы двух кодовых слов одинаковой длины различны. Если рассматривать два кодовых слова, (пример на картинке ниже, 1 0 1 1 0 0 1 и 1 0 0 1 1 0 1) видно что они отличаются друг от друга на два символа, соответственно расстояние Хэмминга равно 2.

Кратность исправляемых ошибок и обнаруживаемых, связано минимальным расстоянием Хэмминга. Любой помехоустойчивый код добавляет избыточность с целью увеличить минимальное расстояние Хэмминга. Именно минимальное расстояние Хэмминга определяет помехоустойчивость.
Помехоустойчивые коды
Современные коды более эффективны по сравнению с рассматриваемыми примерами. В таблице ниже приведены Коды Боуза-Чоудхури-Хоквингема (БЧХ)

Из таблицы видим, что там один класс кода БЧХ, но разные параметры n и k.
- n — количество символов на входе.
- k — количество символов на выходе.
- t — кратность исправляемых ошибок.
- Отношение k/n — скорость кода.
- G (энергетический выигрыш) — величина, показывающая на сколько можно уменьшить отношение сигнал/шум (Eb/No) для обеспечения заданной вероятности ошибки.
Несмотря на то, что скорость кода близка, количество исправляемых ошибок может быть разное. Количество исправляемых ошибок зависит от той избыточности, которую добавим и от размера блока. Чем больше блок, тем больше ошибок он исправляет, даже при той же самой избыточности.
Пример: помехоустойчивые коды и двоичная фазовая манипуляция (2-ФМн). На графике зависимость отношения сигнал шум (Eb/No) от вероятности ошибки. За счет применения помехоустойчивых кодов улучшается помехоустойчивость.

Из графика видим, код Хэмминга (7,4) на сколько увеличилась помехоустойчивость? Всего на пол Дб это мало, если применить код БЧХ (127, 64) выиграем порядка 4 дБ, это хороший показатель.
Компромиссы при использовании помехоустойчивых кодов
Чем расплачиваемся за помехоустойчивые коды? Добавили избыточность, соответственно эту избыточность тоже нужно передавать. Нужно: увеличивать пропускную способность канала связи, либо увеличивать длительность передачи.

Компромисс:
- Достоверность vs полоса пропускания.
- Мощность vs полоса пропускания.
- Скорость передачи данных vs полоса пропускания
Необходимость чередования (перемежения)
Все помехоустойчивые коды могут исправлять только ограниченное количество ошибок t. Однако в реальных системах связи часто возникают ситуации сгруппированных ошибок, когда в течение непродолжительного времени количество ошибок превышает t.
Например, в канале связи шумов мало, все передается хорошо, ошибки возникают редко, но вдруг возникла импульсная помеха или замирания, которые повредили на некоторое время процесс передачи, и потерялся большой кусок информации. В среднем на блок приходится одна, две ошибки, а в нашем примере потерялся целый блок, включая информационные и проверочные биты. Сможет ли помехоустойчивый код исправить такую ошибку? Эта проблема решаема за счет перемежения.
Пример блочного перемежения:

На картинке, всего 5 блоков (с 1 по 25). Код работает исправляя ошибки в рамках одного блока (если в одном блоке 1 ошибка, код его исправит, а если две то нет). В канал связи отдается информация не последовательно, а в перемешку. На выходе кодера сформировались 5 блоков и эти 5 блоков будем отдавать не по очереди а в перемешку. Записали всё по строкам, но считывать будем, чтобы отправлять в канал связи, по столбцам. Информация в блоках перемешалась. В канале связи возникла ошибка и мы потеряли большой кусок. В процессе приема, мы опять составляем таблицу, записываем по столбцам, но считываем по строкам. За счет того, что мы перемешали большое количество блоков между собой, групповая ошибка равномерно распределится по блокам.
Расчет и анализ основных характеристик простой дискретной системы связи
Введение
Базовой дисциплиной для бакалавров
по направлению 210700 «Инфокоммуникационные технологии и системы связи»
специальностей «Системы радиосвязи и радиодоступа» является «Общая теория
связи».
Содержание курсовой работы
охватывает значительную часть дисциплины и направлено на закрепление и более
глубокое усвоение теоретических знаний, полученных в течение семестра.
При выполнении работы идет расчет
основных характеристик простых дискретных систем связи и их анализ, углубленное
ознакомление с теорией передачи информации, и освоение основных принципов и
методов:
форматирования — преобразования
сообщения источника в цифровой сигнал;
кодирования источника (или
эффективного кодирования) — сжатия информации для экономии ресурсов систем
передачи информации;
кодирования канала (или
помехоустойчивого кодирования) — введения регулярной избыточности, для
устранения ошибок.
Работа состоит в виде четырех
индивидуальных заданий, которые в свою очередь содержат задачи по определенным
темам. Задачей первой работы является качественное освоение дисциплин
предыдущих курсов, так как нет смысла приступать, к изучению курса, не вспомнив
хотя бы основные понятия теории вероятностей.
Вторая работа направлена на изучение
методов сжатия данных, а также знакомству с информационными характеристиками
источников сообщений и каналов связи, в общем, на решение одной из больших
проблем теорий передачи информации — избыточности сообщений для достижения
максимальной скорости передачи.
Целью третьей работы является борьба
с ошибками при передаче информации. Освоение основных принципов кодирования
канала. Идеи эти легче всего рассматривать на примере линейно-блочных кодов,
что и приведены в данной работе.
И наконец, четвертая работа нацелена
на способы обработки импульса, который при заданных характеристиках сигналов и
помех обеспечивал минимум полной вероятности ошибки. Это и есть главный
критерий качества приема в цифровой системе передачи информации.
Самостоятельное и сознательное
решение всех поставленных задач обеспечивает подготовку к успешной защите
курсовой работы и сдаче экзамена.
цифровой сигнал кодирование
регенерация
1. Индивидуальное задание 1
.1 Задача 1. Вероятностное описание
символа
Для дискретной случайной
величины ![]()
![]() , принимающей одно из
, принимающей одно из
трех значений ![]()
![]() с вероятностями
с вероятностями ![]()
![]() , записать ряд
, записать ряд
распределения и функцию распределения, привести соответствующие графики и найти
следующие числовые характеристики: математическое ожидание и СКО,
математическое ожидание модуля ![]()
![]() ,
, ![]()
![]() ,
, ![]()
![]() ,
, ![]()
![]() ,
, ![]()
![]() .
.
Исходные данные:
Вариант 19. Исходные
данные представлены в таблице 1.1.
Таблица 1.1 — Исходные
данные
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Решение:
Ряд распределения заданной
дискретной случайной величины:
Многоугольник распределений данного
ряда показан на рисунке 1.1.
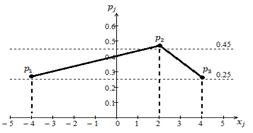
Рисунок 1.1 — Многоугольник
распределений
Функция распределения определяется
как
![]()
Для данного случая,
при ![]()
![]()
![]()
![]()
![]()
График функции
распределения изображен на рисунке 1.2.
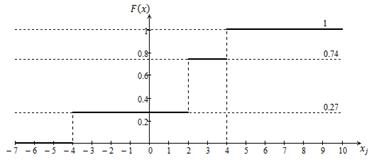
Рисунок 1.2 — График
функции распределения
Математическое ожидание
случайной величины ![]()
![]() :
:
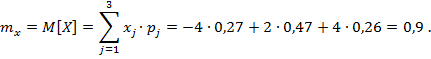
Математическое ожидание ![]()
![]() :
:
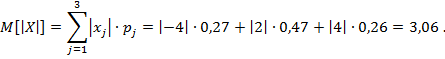
Математическое ожидание ![]()
![]() :
:
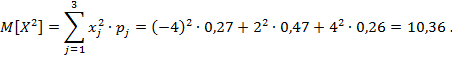
Математическое ожидание ![]()
![]() :
:
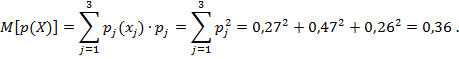
Математическое ожидание ![]()
![]() :
:

Математическое ожидание
минус ![]()
![]() :
:
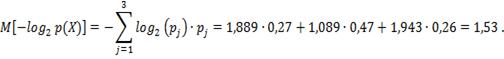
СКО:
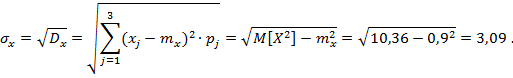
Ответы:
Полученные данные
занесены в таблицу 1.2.
Таблица 1.2 — Результаты
вычисления (![]()
![]() )
)
|
|
|
|
|
|
|
|
|
|
0,9 |
3,09 |
3,06 |
10,36 |
|
3 |
1,53 |
22,3 |
.2 Задача 2. Вероятностное описание
двух символов
Два символа ![]()
![]() и
и ![]()
![]() имеют возможные
имеют возможные
значения ![]()
![]() и
и ![]()
![]() соответственно. Задана
соответственно. Задана
матрица совместных вероятностей с элементами ![]()
![]() . Найти:
. Найти:
ряд распределения
случайной величины ![]()
![]() , а также
, а также ![]()
![]() . Повторить то же при
. Повторить то же при
каждом из условий ![]()
![]() и
и ![]()
![]() , то есть определить
, то есть определить
условные ряды распределения и числовые характеристики случайной величины ![]()
![]() .
.
Исходные данные:
Вариант 19. Исходные
данные представлены в таблице 1.3.
Таблица 1.3 — Исходные
данные
|
N |
|
|
|
|
|
|
|
19 |
3 |
9 |
0,16 |
0,04 |
0,47 |
0,33 |
Решение:
Закон распределения
вероятностей двумерной случайной величины ![]()
![]() :
:
Безусловный ряд
распределения случайной величины ![]()
![]() :
:
![]()
![]()
Условный ряд
распределения при ![]()
![]() :
:
![]()
![]()
![]()
Условный ряд
распределения при ![]()
![]() :
:
![]()
![]()
![]()
Математическое ожидание
случайной величины ![]()
![]() :
:
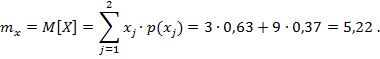
СКО:
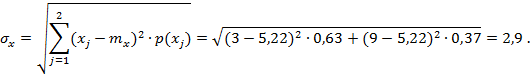
Математическое ожидание
минус ![]()
![]() :
:
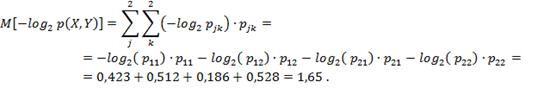
Ответы:
Полученные данные
занесены в таблицу 1.4.
Таблица 1.4 — Результаты
вычисления (![]()
![]() )
)
|
|
|
|
|
|
|
||||
|
0,63 |
0,37 |
0,8 |
0,2 |
0,59 |
0,41 |
||||
|
|
|
|
|
||||||
|
5,22 |
2,9 |
1,65 |
12,77 |
||||||
.3 Задача 3. АЦП непрерывных
сигналов
![]()
![]() -разрядный АЦП рассчитан
-разрядный АЦП рассчитан
на входные напряжения в интервале ![]()
![]() и проводит квантование
и проводит квантование
во времени с шагом ![]()
![]() . Записать
. Записать
последовательность, состоящую из 5 двоичных комбинаций на выходе АЦП, если на
вход поступает сигнал ![]()
![]() , для
, для ![]()
![]() . Найти
. Найти
среднеквадратическую величину ошибки квантования по уровню для данного сигнала ![]()
![]() , и затем ее теоретическое
, и затем ее теоретическое
значение ![]()
![]() , где
, где ![]()
![]() — шаг квантования по
— шаг квантования по
уровню.
Полученные двоичные
комбинации представить в форме целых неотрицательных десятичных чисел ![]()
![]() , например
, например![]()
![]() .
.
Построить графики
функции ![]()
![]() и погрешности
и погрешности
восстановления сигнала ![]()
![]() .
.
Теоретические сведения:
Цель аналого-цифрового
преобразования (АЦП) — заменить непрерывный сигнал последовательностью
символов. АЦП осуществляется в два этапа: дискретизация по времени и
квантование по уровню. Обратное преобразование (ЦАП) также проводится в два
этапа: формирование импульсов, соответствующих каждой цифре, и преобразование
серии импульсов-отсчетов в непрерывный сигнал при помощи ФНЧ с прямоугольной
частотной характеристикой. При этом восстановить исходный сигнал удается лишь с
некоторой погрешностью.
Исходные данные:
Вариант 19. Исходные
данные представлены в таблице 1.5.
Таблица 1.5 — Исходные
данные
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Решение:
Число интервалов по напряжению для
4-х разрядного АЦП:
![]()
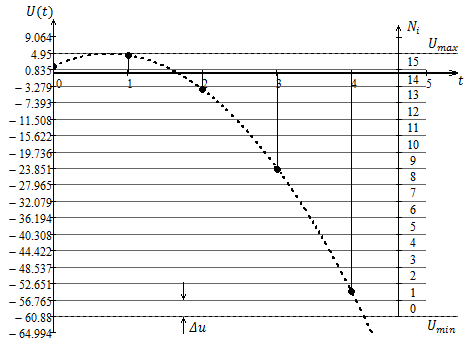
Рисунок 1.3 —
Дискретизация сигнала ![]()
![]()
Шаг квантования по
уровню:
![]()
Дискретизация по времени
входного сигнала с шагом ![]()
![]() :
:
![]()
![]()
![]()
![]()
![]()
Процесс дискретизации
показан на рисунке 1.3.
Номер интервала, который
в свою очередь переводится в двоичный код, находится по формуле:
![]()
в нашем случае, сигнал
на выходе АЦП:
![]()
![]()
![]()
![]()
![]()
Таким образом, приемник
получает лишь номер интервала и по нему восстанавливает исходный сигнал.
Сигнал восстанавливается
по формуле:
![]()
Восстановление
оцифрованного сигнала:
![]()
![]()
![]()
![]()
![]()
Погрешность
восстановления сигнала (ошибка квантования) определяется по формуле:
![]()
![]()
![]()
![]()
![]()
![]()
.4 Задача 4. Нормальные
случайные величины
Система случайных
величин ![]()
![]() имеет нормальное
имеет нормальное
распределение ![]()
![]() , которое
, которое
характеризуется вектором-строкой математических ожиданий ![]()
![]() и ковариационной
и ковариационной
матрицей ![]()
![]() . Найти:
. Найти: ![]()
![]() , коэффициент ковариации
, коэффициент ковариации
![]()
![]() ; значение условного СКО
; значение условного СКО
![]()
![]() и математического
и математического
ожидания ![]()
![]() ;
; ![]()
![]() — наиболее вероятное
— наиболее вероятное
значение ![]()
![]() при заданном
при заданном ![]()
![]() ; значение
; значение
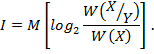
Теоретические сведения:
Из законов распределения
системы двух случайных величин имеет смысл рассмотреть нормальный закон (часто
называют законом Гаусса), как имеющий наибольшее распространение на практике.
Этот закон играет
исключительно важную роль в теории связи (и не только). Главная особенность,
выделяющая нормальный закон среди других законов, состоит в том, что он
является предельным законом, к которому приближаются другие законы
распределения при весьма часто встречающихся типичных условиях.
Исходные данные:
Начальные условия даны в
таблице 1.7.
Таблица 1.7 — Исходные
данные
|
N |
|
|
|
|
|
|
|
19 |
0,4 |
1,31 |
0,17 |
0,63 |
0,31 |
2,33 |
Решение:
СКО:
![]()
![]()
Коэффициент ковариации:
![]()
При ![]()
![]() , случайные величины
, случайные величины ![]()
![]() являются линейно
являются линейно
зависимыми.
Перед тем как найти
условное СКО, рассмотрим условный закон распределения:
![]()
В общем случае плотность
нормального распределения двух случайных величин выражается формулой:

А плотность
распределения случайной величины ![]()
![]() :
:
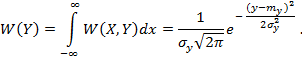
То есть величина ![]()
![]() подчинена нормальному
подчинена нормальному
закону с центром рассеивания ![]()
![]() и средним
и средним
квадратическим отклонением ![]()
![]() .
.
Тогда условный закон
распределения:

Нетрудно убедиться, что
![]()
Для нахождения условного
математического ожидания, преобразуем выражение условной плотности к виду:
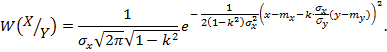
Очевидно, центр
рассеивания данного распределения:
![]()
2 Индивидуальное задание
2
.1 Задача 1.
Информационные характеристики источника и канала
Статистические свойства
совокупности сигналов на входе (![]()
![]() ) и выходе (
) и выходе (![]()
![]() ) канала с шумом
) канала с шумом
определяются матрицей совместных вероятностей, заданной в задаче 2
индивидуального задания 1. Определить информационные характеристики источника и
канала, а именно: производительность (мощность) источника, скорость передачи и
скорость потери информации в канале, скорость создания в канале ложной
информации, энтропию на выходе канала в расчете на один символ и в единицу
времени. Бодовая скорость в ![]()
![]() Бод определяется
Бод определяется
номером студента в объединенном списке.
Теоретические сведения:
Информационные
характеристики источников сообщений и каналов связи позволяют установить пути
повышения эффективности систем передачи информации, и, в частности, определить
условия, при которых можно достигнуть максимальной скорости передачи сообщений
по каналу связи.
Исходные данные:
Вариант 19.
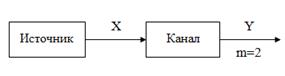
Рисунок 2.1 —
Структурная схема: — основание кода;
По условию задания
известна матрица совместных вероятностей (таблица 2.1).
Таблица 2.1 — Матрица
совместных вероятностей
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Согласно номеру варианта
бодовая скорость ![]()
![]() равна
равна ![]()
![]() .
.
Решение:
.1 Производительность
(мощность) источника или мощность создания информации (энтропия источника):
![]()
или
![]()
.2 Энтропия на выходе
канала:
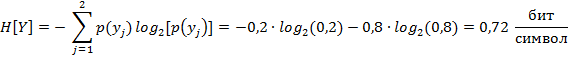
или
![]()
.3 Энтропия системы двух
случайных величин:
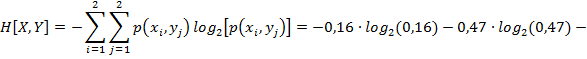
![]()
.4 Скорость передачи
информации по каналу (средняя взаимная информация):
![]()
или
![]()
.5 Скорость потери
информации в канале (ненадёжность канала):
![]()
или
![]()
.6 Скорость создания
ложной информации в канале:
![]()
или
![]()
Ответы:
Полученные результаты
занесены в таблицу 2.2.
Таблица 2.2 — Полученные
результаты (![]()
![]() )
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.2 Задача 2. Блоковое кодирование
источника
Статистические свойства троичного
источника без памяти определяются рядом распределения, заданного в задаче 1
индивидуальной работы 1.
Определить энтропию источника и его
избыточность.
Произвести блоковое кодирование
источника блоками по два символа двоичными кодами Хаффмана, Шеннона-Фано и
равномерным кодом.
Сравнить коды по эффективности.
Определить вероятности появления 0 и
1 в последовательностях символов на выходе кодеров.
Теоретические сведения:
Сообщение на выходе любого реального
источника информации (текст, речь, изображение и т.д.) обладает избыточностью.
Эффективное кодирование (кодирование источника) осуществляется с целью
повышения скорости передачи информации и приближения ее к пропускной
способности канала за счет уменьшения избыточности. Поэтому перед тем, как
проводить какие-то преобразования сообщения, лучше от этой избыточности
избавиться.
Избыточность при побуквенном
кодировании может оказаться слишком большой. Причины — неравномерное
распределение вероятностей и наличие статистической зависимости между буквами.
В этом случае осуществляется кодирование блоков, содержащие буквы, то есть
каждая буквенная комбинация рассматривается как символ нового алфавита источника
и производится эффективное кодирование известными методами.
Исходные данные:
Вариант 19.
Таблица 1.3 — Ряд
распределения
Известен ряд распределения (таблица
2.3).

Рисунок 1.2 —
Структурная схема
— основание алфавита; m
— основание кода;
Решение:
.2.1 Определение
энтропий источника и его избыточности
Максимальная энтропия
источника:
![]()
Энтропия источника:

Избыточность источника:
![]()
.2.2 Блоковое
кодирование источника по два символа
Длина блока ![]()
![]() равен 2.
равен 2.
Объем нового алфавита:
![]()
Всевозможные комбинации
в блоке и их вероятности даны в таблице 2.4.
Таблица 2.4 — Варианты
комбинации в блоке и их вероятности
|
Комбинация |
Вероятность |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Полная вероятность: ![]()
![]()
Энтропия кодера:

Минимальная возможная
длина кода:
![]()
.2.2.1 Код Шеннона-Фано
Алгоритм кода
Шеннона-Фано (рисунок 2.3, таблица 2.5):
Буквы алфавита сообщений
вписываются в таблицу в порядке убывания вероятностей — упорядочивание
алфавита;
Алфавит разделяется на
две приблизительно равновероятные группы — дробление алфавита;
Всем буквам верхней
половины в качестве первого символа приписывают 1, а всем нижним — 0;
Процесс повторяют до тех
пор, пока в каждой подгруппе останется по одной букве;
Записывают код.
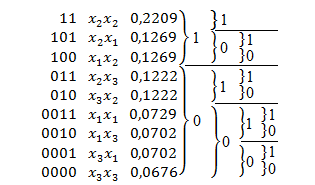
Рисунок 2.3 —
Кодирование алгоритмом Шеннона-Фано
Таблица 2.5 —
Кодирование алгоритмом Шеннона-Фано
|
|
|
I |
II |
III |
IV |
Код |
|
|
|
|
||||
|
|
|
|
||||
|
|
|
|
||||
|
|
|
|
||||
|
|
|
|
||||
|
|
|
|
||||
|
|
|
|
||||
|
|
|
|
||||
|
|
|
|
Код Хаффмана
Алгоритм кода Хаффмана:
Буквы алфавита сообщений также
вписываются в столбец в порядке убывания вероятностей;
Две последние буквы объединяются в
одну вспомогательную букву, которой приписывается суммарная вероятность —
укрупнение алфавита;
Буквам верхней группы присваивают
значение 1, а нижней — 0;
Процесс продолжают до тех пор, пока
не останется единственная вспомогательная буква с вероятностью, равной единице.
Процесс кодирования удобно
графически иллюстрировать при помощи горизонтально расположенного дерева (слева
— ветви, справа — корень, рисунок 2.4), у которого всегда две ветви объединяются
в одну, более крупную. Объединяемые ветви обозначаются двоичными цифрами:
верхняя — 1, нижняя — 0. Чтобы записать кодовое слово, соответствующее данной
букве, нужно двигаться к ней от корня дерева и считывать эти двоичные цифры.

Рисунок 2.4 — Кодовое дерево метода
Хаффмана
.2.2.3 Равномерный код
Средняя длина кодового слова:
![]()
то есть ![]()
![]()
Таблица 2.6 —
Равномерное кодирование
|
Комбинация |
Вероятность |
Код |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.2.3 Сравнение кодов по эффективности
.2.3.1 Анализ кода Шеннона-Фано
Средняя длина кода:

Эффективность:
![]()
Полученные данные занесены в таблицу
2.7.
.2.3.2 Анализ кода Хаффмана
Средняя длина кода:
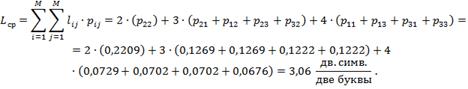
Эффективность:
![]()
Полученные данные занесены в таблицу
2.7.
.2.3.3 Анализ равномерного кода
Средняя длина кода:

Эффективность:
![]()
Полученные данные занесены в таблицу
2.7.
.2.4 Вероятности появления «0» и «1»
.2.4.1 Вероятности появления на
выходе «0» и «1» у кода Шеннона-Фано
Средняя длина единиц:
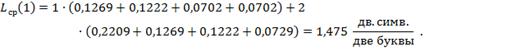
Вероятность появления «1»:
![]()
Вероятность появления «0»:
![]()
Полученные данные занесены в таблицу
2.7.
.2.4.2 Вероятности появления на
выходе «0» и «1» у кода Хаффмана
Средняя длина единиц:
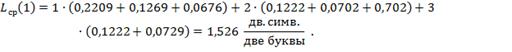
Вероятность появления «1»:
![]()
Вероятность появления «0»:
![]()
Полученные данные занесены в таблицу
2.7.
Искать вероятности появлении нуля
или единицы у равномерного кодирования нет смысла, так как осуществляется
произвольный выбор кода.
Таблица 2.7 — Сравнение кодов
|
Код Шеннона-Фано |
Код Хаффмана |
Равномерный код |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Эффективность источника:
![]()
Выводы:
Равномерное кодирование источника
понизило его эффективность. Когда в свою очередь у кодов Шеннона-Фано и
Хаффмана наблюдается существенное увеличение.
Коды Шеннона-Фано и Хаффмана имеют
явные преимущества перед равномерным кодом по средней длине кода (доходят почти
до минимальной длины).
Средняя длина кодового слова у
Шеннона-Фано и Хаффмана одинакова, но учитывая вероятности появления «0» и «1»,
то последний является более предпочтительным. То есть у кода Хаффмана
вероятности появления нуля и единицы (примерно) равновероятна, а это означает,
что он носит больше информации.
Алгоритмы Хаффмана и Шеннона-Фано
используют избыточность сообщения, заключенную в неоднородном распределении
частот символов его (первичного) алфавита, то есть, заменяют коды более частых
символов короткими двоичными последовательностями, а коды более редких символов
— более длинными двоичными последовательностями.
Главный недостаток кодов
Шеннона-Фано и Хаффмана заключаются в том, что для их применения нужно знать
вероятности появления букв (или их комбинации при кодировании блоками), а на
практике такая благоприятная ситуация возникает чрезвычайно редко.
При использовании обоих кодов любая,
даже одиночная ошибка в принятой последовательности лишает приемник возможности
правильно декодировать ее оставшуюся часть.
.3 Задача 3. Кодирование и
декодирование кодом Лемпела-Зива
Задан ряд из 4-х десятичных чисел.
Представить каждое число с помощью 6
символов равномерного двоичного кода
Закодировать полученную
последовательность двоичных символов кодом Лемпела — Зива.
Произвести декодирование.
Теоретические сведения:
В отличие от предыдущих кодов
(Шеннона-Фано и Хаффмана) в данном кодировании не нужно знать вероятность
появления букв. Здесь кодовая таблица, изначально почти пустая, заполняется
одновременно в пунктах передачи и приема в процессе кодирования
(декодирования), причем в эту таблицу вносятся лишь такие все более длинные
отрезки передаваемого сообщения, которые еще не встречались ранее. Каждому
отрезку в таблице присваивается свой номер.
Исходные данные:
Вариант 19.
Четыре десятичных числа, заданные
руководителем, представлены в таблице 2.8.
Таблица 2.8 — Заданные числа
|
Вариант |
Данные |
|||
|
19 |
17 |
42 |
27 |
29 |
Решение:
.3.1 Представление заданных чисел
равномерным двоичным кодом
В таблице 2.9 показаны двоичные коды
соответствующих чисел.
![]()
![]() .
.
Таблица 2.9 —
Представление в двоичном виде
|
Десятичное число |
17 |
42 |
27 |
29 |
|
Двоичный код |
010001 |
101010 |
011011 |
011101 |
.3.2 Кодирование кодом Лемпела-Зива
Входная последовательность кодера:
010001 101010 011011 011101
В таблице 2.10 показаны
последовательности двоичных символов на входе и выходе кодера, где подчеркнутые
символы находятся в словаре (входные комбинации) или взяты из нее (выходные
коды).
Таблица 2.10 — Последовательности двоичных
символов на входе и выходе кодера
|
Вх |
_0 |
_1 |
00 |
01 |
10 |
101 |
001 |
1011 |
011 |
101 |
|
Вых |
00000 |
00001 |
00010 |
00011 |
00100 |
01011 |
00111 |
01101 |
01001 |
0110 |
Таблица 2.11 представляет собой
словарь. В кодировании идет запись словаря.
Рассмотрим подробнее. На кодер первым
поступает «_0», так как до этого не было на входе сигнала, на выходе будет
«0000» из словаря и входной «0», который подается на выход (то есть «00000»),
при этом нуль записывается в словарь (код «0001»). Далее на входе «_1»,
которого нет в словаре. С ним кодер поступает также как и с нулем, но символ в
словарь уже записывается под другим кодом. На входе третий символ — «0». Так
как код данного символа присутствует в словаре, он переходит к следующему
символу последовательности (также «0»), то есть на входе уже «00». Последняя
комбинация записывается в словарь («0011»), а на выход подается «00010»: код
первого нуля из словаря и второй нуль. Остальные комбинации кодируются таким же
образом, при этом кодируемая комбинация увеличивается.
Таблица 2.11 — Словарь
|
Комбинация |
Код |
|
— |
0000 |
|
0 |
0001 |
|
1 |
0010 |
|
00 |
0011 |
|
01 |
0100 |
|
10 |
0101 |
|
101 |
0110 |
|
001 |
0111 |
|
1011 |
1000 |
|
011 |
1001 |
.3.3 Декодирование кодом
Лемпела-Зива
Входная последовательность декодера:
00001 00010 00011 00100 01011 00111
01101 01001 0110
В таблице 2.12 показаны
последовательности двоичных символов на входе и выходе декодера, где
подчеркнутые символы находятся в словаре (входные коды) или взяты из нее
(выходные комбинации).
Таблица 2.12 — Последовательности
двоичных символов на входе и выходе декодера
|
Вх |
00000 |
00001 |
00010 |
00011 |
00100 |
01011 |
00111 |
01101 |
01001 |
0110 |
|
Вых |
_0 |
_1 |
00 |
01 |
10 |
101 |
001 |
1011 |
011 |
101 |
Принцип декодирования в большом
счете не отличается от кодирования. Разница в том, что при декодировании идет
считывание из словаря. В данном случае входная последовательность будет
рассматриваться по пять символов: первые четыре комбинации сравниваются со
словарным кодом, и на выход подается соответствующая комбинация из него, а
последний, пятый, идет на выход декодера.
Выводы:
При кодировании коротких сообщений
код Лемпела-Зива увеличивает избыточность. Однако, асимптотически (при
увеличении длины сообщения) избыточность стремится к нулю.
Все рассмотренные выше методы — это
универсальные методы, позволяющие кодировать любое цифровое сообщение без потери
информации. Эти методы кодирования избегают неоднозначности кода, то есть
следуют условию, которое гласит: ни одно кодовое слово не должно быть началом
другого, более длинного.
3. Индивидуальное задание 3
.1 Задача 1. Корректирующие коды
Строки производящей
матрицы линейного блочного ![]()
![]() -кода — это три
-кода — это три ![]()
![]() -разрядные комбинаций
-разрядные комбинаций
(младший разряд — справа), которые в двоичной форме представляют десятичные
числа ![]()
![]() ,
, ![]()
![]() ,
, ![]()
![]() . Найти: кодовое
. Найти: кодовое
расстояние ![]()
![]() , максимальные кратности
, максимальные кратности
гарантированно обнаруживаемых ![]()
![]() и исправляемых
и исправляемых ![]()
![]() ошибок. Закодировать
ошибок. Закодировать
двоичную комбинацию, соответствующую десятичному числу ![]()
![]() , и двоичную комбинацию
, и двоичную комбинацию
на выходе кодера представить в форме десятичного числа ![]()
![]() .
.
Примечание: верхняя
строка производящей матрицы ![]()
![]() соответствует младшему
соответствует младшему
разряду комбинации на входе кодера.
Теоретические сведения:
Физическая среда, по
которой передаются данные, не может быть абсолютно надежной. Более того,
уровень шума бывает очень высоким, например, в беспроводных системах связи и
телефонных системах. В результате помех могут исчезать биты или наоборот —
появляться лишние. Целью помехоустойчивого кодирования является обнаружение
и/или исправление ошибок при приеме сигнала в канале с помехой. Если при
декодировании производится обнаружение ошибки, то обязательно нужен канал
переспроса (обратный канал). Если исправление ошибок — канал переспроса не
нужен.
Основная идея
помехоустойчивого кодирования — введение регулярной избыточности, при
использовании которых процент ошибочных комбинации на выходе декодера сводилось
бы к минимуму.
Корректирующим
называется такой код, использование которого дает возможность в процессе приема
цифрового сигнала обнаруживать в нем наличие ошибок и, возможно, даже
исправлять некоторые из ошибочных символов. Среди корректирующих кодов
наибольшее распространение получили блочные двоичные коды, то есть передача
двоичного сообщения производится блоками. Кодирование и декодирование каждого блока
производится независимо от других блоков.
Исходные данные:
Вариант ![]()
![]() . В таблице 3.1
. В таблице 3.1
представлены исходные данные.
Таблица 3.1 — Исходные
данные
|
N |
n |
in |
|
|
|
|
|
|
|
|
|
Решение:
В таблице 3.2 показаны
заданные десятичные числа ![]()
![]() в двоичной форме
в двоичной форме
записи.
Таблица 3.2 —
Соответствие десятеричного и двоичного представлений заданных чисел
|
Десятичная система счисления |
488 |
683 |
866 |
|
Двоичная система счисления |
01111 01000 |
10101 01011 |
11011 00010 |
Согласно варианту
производящая матрица ![]()
![]() выглядит следующим
выглядит следующим
образом:
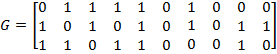
Производящая матрица
состоит из ![]()
![]() линейно независимых
линейно независимых
разрешенных векторов, которые образуют базис пространства разрешенных кодовых
комбинаций.
При использовании
линейно блочных кодов расстояние между кодами можно находить (как расстояние
между строками) из производящей матрицы, приписав к нему строку, состоящую из
нулей. Кодовое расстояние определяется по формуле:
![]()
где ![]()
![]() — кодовое расстояние
— кодовое расстояние
между i-ой и j-ой строками матрицы ![]()
![]() .
.
Это расстояние
определяется в пространстве Хэмминга. Оно равно количеству позиций с различными
символами. Для двоичного кода определяется весом суммарного вектора,
суммирование осуществляется по модулю два.
Для данной матрицы они
равны:
![]()
![]()
Отсюда, ![]()
![]()
Кратность гарантированно
обнаруживаемой ошибки:
![]()
Кратность гарантированно
исправляемой ошибки:
![]()
то есть ![]()
![]()
Проведя анализ
полученных значений можно убедиться в том, что ресурсы кода используются
полнее, если ![]()
![]() является нечетным
является нечетным
числом.
Кодирование заданной
двоичной комбинации. Кодируемое десятичное число ![]()
![]() в двоичной форме записи
в двоичной форме записи
с учетом количества информационных символов ![]()
![]() , который определен из
, который определен из
размерности производящей матрицы как число строк, выглядит следующим образом:
![]()
Кодирование
осуществляется по формуле:
![]()
Учитывая условие, что
верхняя строка производящей матрицы ![]()
![]() соответствует младшему
соответствует младшему
разряду комбинации на выходе, задания, при вычислении переставим строки матрицы
![]()
![]() соответственно разрядам
соответственно разрядам
кодируемого числа, иными словами:
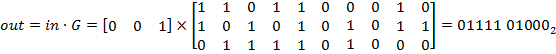
или ![]()
![]() в десятичной системе
в десятичной системе
счисления.
Ответы:
Все найденные значения
занесены в таблицу 3.3.
Таблица 3.3 — Полученные
результаты (![]()
![]() )
)
|
|
|
|
|
|
|
4 |
3 |
1 |
488 |
496 |
3.2 Задача 2. Линейные блочные коды
Двоичные комбинации,
соответствующие пяти десятичным числам ![]()
![]() из задачи
из задачи ![]()
![]() , считать строками
, считать строками
проверочной матрицы H кода ![]()
![]() .
.
Определить:
способен ли этот код
обнаружить любую однократную ошибку (![]()
![]() , если способен,
, если способен, ![]()
![]() в противном случае);
в противном случае);
способен ли этот код
исправить любую однократную ошибку (![]()
![]() , если способен,
, если способен, ![]()
![]() в противном случае).
в противном случае).
Теоретические сведения:
Код линейный, если
проверочные символы получены в результате линейных операций над
информационными. В двоичной арифметике линейной операцией является операция
суммирования по модулю 2. Следствием линейности является тот факт, что
суммирование по модулю 2 разрешенных комбинаций дает разрешенную кодовую
комбинацию.
Любой линейный блочный
код обозначается как ![]()
![]() , где:
, где: ![]()
![]() — количество символов в
— количество символов в
комбинации на выходе кодера; ![]()
![]() — количество информационных
— количество информационных
символов.
Для любого линейного
блочного кода существуют проверочная (![]()
![]() ) и производящая (
) и производящая (![]()
![]() ) матрицы.
) матрицы.
Исходные данные:
Вариант ![]()
![]() . В таблице 3.4
. В таблице 3.4
представлены исходные данные.
Таблица 3.4 — Исходные
данные
|
Система счисления |
|
|
|
|
|
|
десятичная |
10 |
1 |
|
|
|
|
двоичная |
0000001010 |
0000000001 |
0111101000 |
1010101011 |
1101100010 |
Код ![]()
![]() . Задан с помощью
. Задан с помощью
проверочной матрицы ![]()
![]() .
.
Решение:
Будем считать двоичные
комбинации исходных данных элементами соответствующих векторов ![]()
![]() . Тогда согласно условию
. Тогда согласно условию
задачи проверочная матрица ![]()
![]() будет выглядеть
будет выглядеть
следующим образом:

Транспонированная
проверочная матрица ![]()
![]() :
:
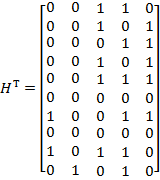
Чтобы проверить
обнаружение однократной ошибки воспользуемся фундаментальным свойством:
![]()
где ![]()
![]() — вектор синдрома;
— вектор синдрома;
![]()
![]() — передаваемый вектор;
— передаваемый вектор;
![]()
![]() — вектор ошибки.
— вектор ошибки.
Учитывая всевозможные
однократные ошибки, получим:
![]()
где ![]()
![]() — матрица синдромов;
— матрица синдромов;
![]()
![]() — единичная матрица
— единичная матрица
размера ![]()
![]() (единицы стоят на
(единицы стоят на
позициях ошибок).
Или ![]()
![]()
Данная матрица содержит
две нулевые строки и поэтому не может обнаружить гарантированно все однократные
ошибки. Следовательно, код и не способен исправить однократную ошибку.
Ответы:
Таблица 3.5 — Полученные
результаты (![]()
![]() )
)
.3 Задача 3. Неравенство Хэмминга
для линейного блочного кода
Требуется построить
линейный блочный ![]()
![]() -код. Определить
-код. Определить
теоретический предел для этого кода — найти максимальную кратность исправляемых
ошибок ![]()
![]() .
.
Определить вероятность
ошибочного декодирования кодовой комбинации ![]()
![]() , если ошибки в
, если ошибки в
отдельных символах в канале передачи происходят с вероятностью ![]()
![]() , а ошибки в разных
, а ошибки в разных
символах независимы. В ответе для величины ![]()
![]() оставить
оставить ![]()
![]() знаков после десятичной
знаков после десятичной
точки.
Теоретические сведения:
Идея неравенства
Хэмминга заключается в том, что количество вариантов гарантированно
исправляемых ошибок ![]()
![]() должно быть меньше или
должно быть меньше или
равно количества вариантов ненулевых синдромов ![]()
![]() :
:
![]()
Если неравенство
превращается в равенство, код обладает минимальной избыточностью и является
оптимальным. Такой код называется кодом Хэмминга.
Исходные данные:
Вариант ![]()
![]() . В таблице 3.6
. В таблице 3.6
представлены исходные данные.
Таблица 3.6 — Исходные
данные
![]()
![]() — количество
— количество
проверочных символов.
Код (23, 6).
Решение:
Максимальное количество
гарантированно исправляемых ошибок:
![]()
где ![]()
![]() определяется формулой:
определяется формулой:
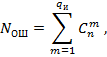
а ![]()
![]() как:
как:
![]()
В последнем выражении
вычитание единицы обусловлено из условия ненулевых синдромов, другими словами
отнимается нулевая комбинация.
Отсюда, ![]()
![]()
Максимальную кратность
гарантированно исправляемых ошибок найдем из неравенства Хэмминга:
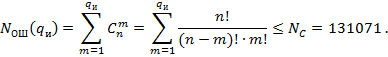
Полученные выражения при
![]()
![]() занесены в таблицу 3.7.
занесены в таблицу 3.7.
Таблица 3.7 — Количество
гарантированно исправляемых ошибок в зависимости от кратности исправляемых
ошибок
|
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|
23 |
276 |
2047 |
10902 |
44551 |
145498 |
Из данной таблицы видно, что данный
код уже не способен гарантированно исправлять шестикратные ошибки, просто не
хватит синдромов. А вот пятикратные ошибки исправит, но код будет чрезвычайно
избыточен, так как неиспользуемых синдромов будет:
![]()
Следуя, ![]()
![]() .
.
Вероятность ошибочного
декодирования, если код гарантированно исправляет пятикратные ошибки:
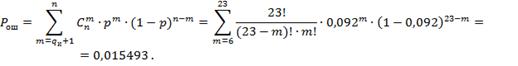
Ответы: Все полученные
значения занесены в таблицу 3.8.
Таблица 3.8 — Полученные
результаты (![]()
![]() )
)
4. Индивидуальное задание 4
.1 Задача 1. Битовая вероятность
ошибки при передаче цифрового потока
Источник информации
создает цифровой поток ![]()
![]() мегабит в секунду. На
мегабит в секунду. На
вход радиолинии с выхода передатчика подается последовательность двоичных
радиоимпульсов, модулированных по закону ![]()
![]() (
(![]()
![]() для АМ,
для АМ, ![]()
![]() для ЧМ с ортогональными
для ЧМ с ортогональными
сигналами, ![]()
![]() для ФМ). Средняя
для ФМ). Средняя
мощность передаваемых сигналов обоих видов (![]()
![]() ) равна
) равна ![]()
![]() . Задана величина
. Задана величина
ослабления в линии ![]()
![]() . На входе приемника
. На входе приемника
присутствует аддитивный белый гауссовский шум со спектральной плотностью ![]()
![]() . Определить битовую
. Определить битовую
вероятность ошибки на выходе идеальной когерентной системы связи без
использования корректирующего кода (![]()
![]() ) и при использовании
) и при использовании ![]()
![]() -кода Хэмминга в режиме
-кода Хэмминга в режиме
обнаружения ошибки (![]()
![]() ) и в режиме исправления
) и в режиме исправления
ошибки (![]()
![]() ).
).
При расчетах считать,
что вероятность ошибки в канале переспроса (режим обнаружения ошибки) пренебрежимо
мала по сравнению с вероятностью появления искаженной комбинации на выходе
декодера.
Теоретические сведения:
Значение каждого
импульса передается с помощью радиоимпульса прямоугольной формы, с
использованием одного из методов модуляции. В процессе передачи сигнала по
линии эти импульсы случайным образом искажаются (обычно это происходит из-за
наличия мультипликативной помехи) и появляется аддитивная помеха.
Демодулятор к моменту
окончания очередного принимаемого импульса должен указать (вернее угадать),
которое из возможных значений символа было передано с данным импульсом.
Очевидно, что иногда демодулятор будет выдавать ошибочные решения, поэтому
желательно применять такой способ обработки импульса, который обеспечивал
минимум полной вероятности ошибки.
Полная вероятность
ошибки (битовая вероятность ошибки) — объективная характеристика качества
приема, которая зависит от энергии разностного сигнала к спектральной плотности
шума и, разумеется, уменьшается при увеличении этого отношения.
Исходные данные:
Вариант ![]()
![]() . В таблице 4.1
. В таблице 4.1
представлены исходные данные.
Таблица 4.1 — Исходные
данные
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Код Хэмминга (63, 57). Частотная
модуляция.
Решение:
.1.1 Без использования
корректирующего кода
Ослабление в линии по мощности:
![]()
Длительность одного бита:
![]()
Средняя энергия сигнала на выходе
передатчика:
![]()
Средняя энергия сигнала на входе
приемника:
![]()
Отношение сигнал/шум по мощности, то
есть отношение средней энергии импульса на входе демодулятора к спектральной
плотности мощности белого шума:
![]()
Отношение сигнал/шум по мощности на
выходе корреляционного приемника, равный отношению энергии разностного сигнала
к спектральной плотности мощности шума:
![]()
или по энергии ![]()
![]()
Битовая вероятность
ошибки на выходе идеальной когерентной системы связи:
![]()
где ![]()
![]() — интеграл вероятностей
— интеграл вероятностей
Гаусса (при заданной ![]()
![]() значение определяется
значение определяется
по таблице или находится самостоятельно решением интеграла).
.1.2 При использовании
кода Хэмминга в режиме обнаружения
Скорость цифрового
потока при использовании ![]()
![]() -кода:
-кода:
![]()
Средняя энергия сигнала
на входе приемника:
![]()
Отношение сигнал/шум по
мощности на выходе корреляционного приемника:
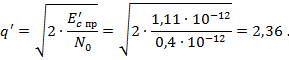
Битовая вероятность
ошибки на выходе системы:
![]()
При наличии однократной
(или двукратной, для кода Хэмминга ![]()
![]() ) ошибки по обратному
) ошибки по обратному
каналу сгенерируется сигнал подтверждения. Если же полученная на выходе кодовая
комбинация является запрещенной, то оно стирается, а по обратному каналу
посылается сигнал переспроса. Таким образом, на выходе системы будет ошибка,
только в том случае, если в цифровом потоке возникла трехкратная или более
ошибка.
В канале с независимыми
ошибками вероятность, того, что ровно ![]()
![]() бит в принятой
бит в принятой
комбинации являются ошибочными можно найти по биноминальной формуле Бернулли.
Найдем вероятность
появления ошибки более двух кратностей:
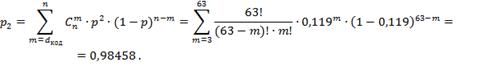
Тогда битовая
вероятность ошибки на выходе системы в режиме обнаружения:
![]()
.1.3 При использовании
кода Хэмминга в режиме исправления
Код Хэмминга в режиме
исправления отличается тем, что при нахождении ошибки (в данном случае только
однократной) автоматически исправляет ее. Очевидно, что на выходе системы будет
ошибка, если в цифровом потоке возникнет двукратная или более ошибка. Найдем
соответствующую вероятность:
А значит, битовая
вероятность ошибки на выходе системы в режиме исправления:
![]()
Численные расчеты
показывают, что при той же величине избыточности системы передачи информации с
обратным каналом обеспечивают большую помехоустойчивость, если ошибки в канале
переспроса пренебрежимо малы.
Ответы: Полученные
данные занесены в таблицу 4.2.
Таблица 4.2 — Полученные
данные
.2 Задача 2. Регенерация цифрового
сигнала при передаче на большие расстояния
На кабельной линии,
содержащей ![]()
![]() регенерационных
регенерационных
участков, регенерация двоичных импульсов в полном смысле этого слова проводится
лишь в обслуживаемых регенерационных пунктах (ОРП), размещенных на каждом m-м
участке. На остальных участках размещены необслуживаемые регенерационные пункты
(НРП), в которых входной сигнал лишь усиливается. Определить вероятность ошибки
при демодуляции сигнала на выходе некогерентной линии ![]()
![]() , если при
, если при ![]()
![]() эта величина равна:
эта величина равна:
![]()
где ![]()
![]() — отношение сигнал/шум
— отношение сигнал/шум
по мощности на входе первого НРП, а все участки и приемники идентичны.
Найти отношение
сигнал/шум ![]()
![]() , которое потребовалось
, которое потребовалось
бы для обеспечения той же вероятности ошибки ![]()
![]() на выходе линии для
на выходе линии для
двух случаев:
все регенераторы — это
НРП (![]()
![]() , дБ);
, дБ);
все регенераторы — это
ОРП (![]()
![]() , дБ).
, дБ).
Теоретические сведения:
При передаче на большие
расстояния сигнал может быть ослаблен настолько, что прием становится
невозможным. Чтобы избежать этого, на определенных расстояниях вдоль линий
связи устанавливают промежуточные пункты, в которых проводится восстановление
ослабленного сигнала: либо обычное усиление, либо усиление с регенерацией
сигнала.
Исходные данные:
Вариант 19. Начальные
условия даны в таблице 4.3.
Таблица 4.3 — Исходные
данные
Решение:
.2.1 Вероятность ошибки на выходе
некогерентной линии
Отношение сигнал/шум по мощности на
входе первого НРП:
![]()
При усилении сигнала без регенерации
импульсов происходит аддитивное накопление шума, то есть, отношение сигнал/шум
по мощности на входе первого ОРП:
![]()
Рисунок 4.1 — Линия связи с одной
регенерацией сигнала
Битовая вероятность ошибки на выходе
ОРП, то есть ошибка на выходе линий связи с одной регенерацией сигнала (рисунок
4.1):
![]()
Именно здесь, при восстановлении
сигнала, происходит накопление ошибок, возникающих при демодуляции.
Учитывая, что таких
участков ![]()
![]() , определим вероятность
, определим вероятность
ошибки на выходе линий связи:
![]()
.2.2 Все регенераторы —
НРП
Отношение сигнал/шум по
мощности на входе приемника ![]()
![]() , выразим из уравнения:
, выразим из уравнения:
![]()
![]()
Отношение сигнал/шум по
мощности на входе первого НРП:
![]()
или ![]()
![]() .
.
.2.3 Все регенераторы —
ОРП
Вероятность ошибки на
выходе первого ОРП ![]()
![]() выразим из соотношения:
выразим из соотношения:
![]()
![]()
Отношение сигнал/шум по
мощности на входе первого ОРП ![]()
![]() , выразим из уравнения:
, выразим из уравнения:
![]()
![]()
Ответы:
Найденные значения
занесены в таблицу 4.4.
Таблица 4.4 — Полученные
данные (![]()
![]() )
)
Заключение
Курсовая работа была посвящена
расчету и анализу основных характеристик простой дискретной системы связи для
передачи сообщений. Изучены принципы и методы передачи информации по каналам
связи. Рассмотрены вопросы математического описания сообщений, сигналов и
каналов связи, кодирования и декодирования, основы теории информации, анализ
помехоустойчивости каналов связи, методы помехоустойчивого кодирования,
оптимального приема дискретных сообщений, основы цифровой обработки сигналов,
вопросы оптимизации.
Основные результаты теории
информации имеют вид неравенств, то есть, они определяют предельные,
потенциальные характеристики систем передачи информации. Любая теория
информации оперирует лишь вероятностными характеристиками сигналов и является
математической теорией. Поэтому она универсальна, то есть может быть применена
к любым сигналам независимо от их физической формы.
В заключение следует отметить, что
никакое методическое руководство не может заменить посещения лекций и
систематической самостоятельной работы с учебником и дополнительной
литературой.
Список использованных источников
1 Бернгардт, А.С. ТЭС-14 Ч 5 (6, 7.1, 10): электронные презентации
PDF / А.С. Бернгардт. — Томск: Томский государственный университет систем
управления и радиоэлектроники.
Теория и техника передачи информации: учебное пособие /
Ю.П.Акулиничев, А.С.Бернгардт. — Томск: ЭльКонтент, 2012. — 210с.
Булгаков, Р.В. Индивидуальное задание №3 / Р.В. Булгаков. — Томск:
Томский государственный университет систем управления и радиоэлектроники, 2013.
— 4 с.
Дамдинжапов, Э.Ц. Тетрадь по лекционным занятиям / Э.Ц.
Дамдинжапов — Томск: Томский государственный университет систем управления и
радиоэлектроники, 2014. — 48 л.
Дамдинжапов, Э.Ц. Тетрадь по практическим занятиям / Э.Ц.
Дамдинжапов — Томск: Томский государственный университет систем управления и
радиоэлектроники, 2014. — 48 л.
Вентцель, Е.С. Теория вероятностей: учебник для студ. вузов / Е.С.
Вентцель. — 10-е изд., стер. — М.: Издательский центр — «Академия», 2005. — 576
с.