10 Sep 2020 |
SPSS
Источники:
- Наследов. SPSS Профессиональный статистический анализ данных.
- Дубина. Логика проверки статистических гипотез
0. Логика проверки гипотез
0.1 Базовые идеи
Связь может характеризоваться не только величиной (степенью связи) и направлением, но также и надежностью или статистической достоверности (statistical confidence).
Надежность определяется тем, насколько вероятно, что обнаруженная в выборке связь подтвердится (будет вновь обнаружена) на другой выборке той же генеральной совокупности.
0.2 Статистическая значимость и обоснованность
Пример: Проверяется гипотеза о том, что женщины тратят больше времени на разговоры по телефону, чем мужчины. Предположим, что в исследовании принимали участие 52 мужчины и 43 женщины. Среднее время разговора составило 37 мин. в день у мужчин и 41 мин. в день у женщин. На первый взгляд, различия обнаружены, и эти результаты подтверждают гипотезу.
Однако такой результат может быть получен случайно, даже если в генеральной совокупности различий нет, как и наоборот, когда различия на самом деле существуют.
Поэтому закономерен вопрос: достаточно ли полученного различия в средних значениях для того, чтобы утверждать, что вообще все женщины в среднем говорят по телефону дольше, чем все мужчины? Какова вероятность, что это не так? Является ли это различие статистически значимым?
Необходимо определить, достаточно ли велика разность между средними двух распределений для того, чтобы можно было объяснить ее действием независимой переменной, а не случайностью, связанной с малым объемом выборки
Методы статистики позволяют оценить вероятность случайного получения такого различия при условии, что на самом деле различий в генеральной совокупности нет
0.3 Статистические гипотезы
- Нулевая гипотеза (null hypothesis) – гипотеза об отсутствии различий (утверждение об отсутствии различий в значениях или об отсутствии связи в генеральной совокупности)
- Согласно нулевой гипотезе ((H_{0})), различие между значениями недостаточно значительно, а независимая переменная не оказывает никакого влияния.
- Альтернативная гипотеза (alternative hypothesis) – гипотеза о значимости различий (утверждает наличие различий или существование связи).
- Альтернативная гипотеза ((H_{A})) является «рабочей» гипотезой исследования. В соответствии с этой гипотезой, различия достаточно значимы и обусловлены влиянием независимой переменной.
- Нулевая и альтернативная гипотезы представляют полную группу несовместных событий: отклонение одной влечет принятие другой.
- Основной принцип метода проверки гипотез состоит в том, что выдвигается нулевая гипотеза (H_{0}), с тем чтобы попытаться опровергнуть ее и тем самым подтвердить альтернативную гипотезу (H_{A}). Если результаты статистического теста, используемого для анализа разницы между средними, окажутся таковы, что позволят отклонить (H_{0}), это будет означать, что верна (H_{1}), т.е. выдвинутая рабочая гипотеза подтверждается.
- Не можем отклонить нулевую гипотезу — не значит «принять» альтернативную (нулевая гипотеза никогда не может быть абсолютно подтверждена!)
0.4 Статистические ошибки при принятии решений Ошибки первого и второго рода
Статистическая ошибка первого рода (Type I Error) – ошибка обнаружить различия или связи, которые на самом деле не существуют «Истинная нулевая гипотеза отклоняется».
Статистическая ошибка второго рода (Type II Error) — не обнаружить различия или связи, которые на самом деле существуют «Ложная нулевая гипотеза не может быть отклонена».
Более «критичной» ошибкой считается статистическая ошибка первого рода.
Пример: «Судебная» аналогия: Вердикт «Не виновен» или «Виновен» Ошибка первого рода — невинный обвинен
Ошибка второго рода — виновный освобожден.
0.5 Уровни статистической значимости
Уровень значимости (level of significance) (уровень достоверности, уровень надежности, доверительный уровень, вероятностный порог) — это пороговая (критическая) вероятность ошибки, заключающейся в отклонении (не принятии) нулевой гипотезы, когда она верна. Другими словами, это допустимая (с точки зрения исследователя) вероятность совершения статистической ошибки первого рода – ошибки того, что различия сочтены существенными, а они на самом деле случайны.
Обычно используют уровни значимости (обозначаемые (alpha)), равные 0.05, 0.01 и 0.001.
Например, уровень значимости, равный 0,05, означает, что допускается не более чем 5%-ая вероятность ошибки. Т.е. нулевую гипотезу можно отвергнуть в пользу альтернативной гипотезы, если по результатам статистического теста вероятность ошибки, т.е. вероятность случайного возникновения обнаруженного различия (p-уровень) не превышает 5 из 100, т.е. имеется лишь 5 шансов из 100 ошибиться. Если же этот уровень значимости не достигается (вероятность ошибки выше 5%), считают, что разница вполне может быть случайной и поэтому нельзя отклонить нулевую гипотезу.
Таким образом, p-уровень значимости (p-value) соответствует риску совершения ошибки первого рода (отклонения истинной нулевой гипотезы). Если (p < alpha), (H_{0}) отклоняется.
| Уровень значимости | Решение | Возможный статистический вывод |
|---|---|---|
| p>0.1 | Но не может быть отклонена | «Статистически достоверные различия не обнаружены» |
| p <= 0.1 | сомнения в истинности Но, неопределенность | «Различия обнаружены на уровне ста- тистической тенденции» |
| p<=0.05 | значимость, отклонение Но | «Обнаружены статистически достоверные (значимые) различия» |
| p<=0.01 | высокая значимость, отклонение Но | «Различия обнаружены на высоком уровне статистической значимости» |
Для принятия решений о том, какую из гипотез (нулевую или альтернативную) следует принять, используют статистические критерии, которые включают в себя методы расчета определенного показателя, на основании которого принимается решение об отклонении или принятии гипотезы, а также правила (условия) принятия решения.
Этот показатель называется эмпирическим значением критерия. Это число сравнивается с известным (например, заданным таблично) эталонным числом, называемым критическим значением критерия.
Критические значения приводятся, как правило, для нескольких уровней значимости: 5% (0.05), 1% (0.01) или еще более высоких. Если полученное исследователем эмпирическое значение критерия оказывается меньше или равно критическому, то нулевая гипотеза не может быть отклонена – считается, что на заданном уровне значимости (то есть при том значении (a), для которого рассчитано критическое значение критерия) характеристики распределений совпадают.
Если эмпирическое значение критерия оказывается строго больше критического, то нулевая гипотеза отвергается и принимается альтернативная гипотеза – характеристики распределений считаются различными с достоверностью различий (1 – alpha). Например, если (alpha = 0.05) и принята альтернативная гипотеза, то достоверность различий равна 0.95 или 95%.
- Если эмпирическое значение критерия для данного числа степеней свободы ((df=n-1)) оказывается ниже критического уровня, соответствующего выбранному значению (alpha) (порогу вероятности), то нулевая гипотеза не может считаться опровергнутой, и это означает, что выявленная разница (или связь) недостоверна.
- Чем эмпирическое значение меньше критического значения критерия, тем больше степень совпадения характеристик сравниваемых объектов.
- Чем эмпирическое значение критерия больше критического значения, тем сильнее различаются характеристики сравниваемых объектов. Если эмпирическое значение критерия оказывается меньше или равно критическому, то можно сделать вывод, что характеристики экспериментальной и контрольной групп совпадают на уровне значимости (alpha).
- Если эмпирическое значение критерия оказывается строго больше критического, то можно сделать вывод, что достоверность различий характеристик экспериментальной и контрольной групп равна (alpha)
0.6 Процедура проверки статистической гипотезы
- Сформулировать нулевую и альтернативной гипотезы;
- Выбрать соответствующий статистический тест;
- Выбрать требуемый уровень значимости ((alpha = 0.05, 0.01, 0.025, …))
- Вычислить эмпирическое значение критерия по тесту;
- Сравнить с критическим значением критерия по тесту;
- Принять решение (для большинства тестов приемлемо правило: если вычисленное значение больше, чем критическое, нулевая гипотеза (H_{0}) отклоняется).
! Примечание: Выбор статистического метода также зависит от того, являются ли выборки, средние которых сравниваются, независимыми (т. е., например, взятыми из двух разных групп испытуемых) или зависимыми (т. е. отражающими результаты одной и той же группы испытуемых до и после воздействия или после двух различных воздействий).
1. Описательные статистики
Таблицы сопряженности и критерий (chi^{2})
Таблицы сопряженности служат для описания связи двух или более номинальных (категориальных) переменных. Примерами номинальных переменных являются: пол (женский, мужской), класс (А, Б, В), местность (город, пригород, село), ответ (да, нет) и т. д. Таблицы сопряженности неприменимы к непрерывным переменным, однако последние можно разбить на интервалы. Так, возраст человека, который следует считать непрерывным из-за большого числа его возможных значений, можно разделить на интервалы от 0 до 19 лет, от 20 до 39 лет, от 40 до 59 лет и т. д.
Критерий независимости (chi^{2})
Помимо частот (или наблюдаемых величин) SPSS может вычислять ожидаемые значения для каждой ячейки таблицы. Ожидаемое значение вычисляется в пред- положении, что две номинальные переменные независимы друг от друга. Рассмо- трим простой пример. Пусть в комнате находится 100 человек, из которых 30 являются мужчинами, а 70 — женщинами. Если известно, что из этих 100 человек 10 увлекаются искусством, в случае если увлечение не зависит от пола, следует ожидать, что из 10 увлекающихся искусством 3 являются мужчинами, а 7 — женщинами. Сопоставляя эти ожидаемые частоты с наблюдаемыми частотами, мы можем судить о том, действительно ли два номинальных признака независимы. Чем больше расхождение наблюдаемых и ожидаемых частот, тем сильнее эти два признака связаны друг с другом. Целью применения критерия независимости (chi^{2}) и является установление степени соответствия между наблюдаемыми и ожидаемыми значениями ячеек.
Вместе с (chi^{2}) вычисляется р-уровень значимости. При p > 0,05 считается, что различия между наблюдаемыми и ожидаемыми значениями незначительны. В противном случае предположение о независимости двух номинальных переменных отклоняется и делается вывод о том, что две классификации (переменные) зависят друг от друга. Т.е. если p < 0,05 различия значимы и две переменные зависят друг от друга.
О величине связи переменных можно судить по симметричным мерам — значени- ям показателей (phi) и (V) Крамера, которые аналогичны коэффициенту корреляции. Например, величина 0,392 свидетельствует об умеренной связи между переменными.
- Значение — для критерия (chi^{2}) значение тем больше, чем больше зависимость между переменными (как в нашем примере 15.02 для 2х df). Значения близкие к 0 свидетель- ствуют о независимости переменных.
- Асимпт. значимость — асимптотическая значимость, вероятность случайности связи или р-уровень значимости, то есть вероятность того, что связь является случайной. Чем меньше эта величина, тем выше статистическая значимость (достоверность) связи. Величина
p ≤ 0,05свидетельствует о статистически значимом результате, который достоин содержательной интерпретации. Асимптотическая значимость определяется по традиционному критерию (chi^{2}). - (phi) — коэффициент, являющийся мерой связи двух переменных, аналог корреляции Пирсона. Значение (φ) = 0,392 показывает умеренную связь между двумя переменными.
- (V) Крамера — как и коэффициент (phi), этот коэффициент является мерой связи между двумя переменными, однако отличается тем, что всегда принимает значения от 0 до 1 и более приемлем для таблиц с df > 2.
2. Корреляции
Корреляция представляет собой величину, заключенную в пределах от –1 до +1, и обозначается буквой r. Понятия корреляция и двумерная корреляция часто употребляются как синонимы; последнее означает «корреляция между двумя переменными» и подчеркивает, что рассматривается именно двумерное соотношение. Основной коэффициент корреляции r Пирсона предназначен для оценки связи между двумя переменными, измеренными в метрической шкале, распределение которых соответствует нормальному. Несмотря на то что величина r рассчитывается в предположении, что значения обеих переменных распределены по нормальному закону, формула для ее вычисления дает достаточно точные результаты и в случаях анормальных распределений, а также в случаях, когда одна из переменных является дискретной. Для распределений, не являющихся нормальными, предпочтительнее пользоваться ранговыми коэффициентами корреляции Спирмена или Кендалла. Команды подменю Корреляции позволяют вычислить как коэффициент Пирсона, так и коэффициенты Спирмена и Кендалла.
Понятие корреляции
Корреляция, или коэффициент корреляции, — это статистический показатель вероятностной связи между двумя переменными, измеренными в количественной шкале.
Величина коэффициента корреляции меняется от –1 до 1. Крайние значения соответствуют линейной функциональной связи между двумя переменными, 0 — отсутствию связи.
Линейная и криволинейная корреляции
Основной коэффициент корреляции r Пирсона является мерой прямолинейной связи между переменными: его значения достигают максимума, когда точки на графике двумерного рассеяния лежат на одной прямой линии. Если связь нелинейная, но монотонная, вместо r Пирсона следует использовать ранговые корреляции Спирмена или Кендалла.
Прежде чем оценивать корреляцию двух переменных, рекомендуется построить график зависимости между ними — график двумерного рассеяния. Если график демонстрирует монотонность связи, для вычисления корреляции можно использовать команды подменю Корреляции.
Ранговые корреляции
Необходимость в применении ранговых корреляций возникает в двух случаях:
- когда распределение хотя бы одной из двух переменных не соответствует нормальному
- когда связь между переменными является нелинейной (но монотонной).
В этих случаях вместо корреляции r Пирсона можно выбрать ранговые корреляции: r Спирмена либо τ (читается «тау») Кендалла. Ранговыми они являются потому, что программа предварительно ранжирует переменные, между которыми они вычисляются.
Значимость
При проверке статистической гипотезы результат имеет статистическую значимость, когда маловероятно, что он произошел с учетом нулевой гипотезы.
Напомним, что уровень значимости является мерой статистической достоверности результата вычислений, в данном случае — корреляции, и служит основанием для интерпретации. Если исследование показало, что уровень значимости корреляции не превышает 0,05 (р ≤ 0,05), то это означает, что корреляция является случайной с вероятностью не более 5 %. Обычно это является основанием для вывода о статистической достоверности корреляции. В противном случае (p > 0,05) связь признается статистически недостоверной и не подлежит содержательной интерпретации.
Частная корреляция
Понятие частной корреляции связано с ковариацией. Здесь мы упоминаем частную корреляцию лишь как одну из команд подменю Корреляции. Суть частной корреляции заключается в следующем. Если две переменные коррелируют, всегда можно предположить, что эта корреляция обусловлена влиянием третьей переменной, как общей причины совместной изменчивости первых двух переменных. Для проверки этого предположения достаточно исключить влияние этой третьей переменной и вычислить корреляцию двух переменных без учета влияния третьей переменой (при фиксированных ее значениях). Корреляция, вычисленная таким образом, и называется частной.
При вычисление парной корреляции в SPSS есть пунктик “Метить значимые корреляции (Falg significant correlations)”, корреляции, вычисленные с уровнем значимости от 0,01 до 0,05, будут помечены одной звездочкой (*), а от 0 до 0,01 — двумя звездочками(**)
Пример:

Значимая положительная корреляция в этой таблице наблюдается, в частности, между переменными кратковременная память (тест5) и отметка2 (r = 0.294, p = = 0.003). Это означает, что чем лучше кратковременная память, тем выше средняя отметка за выпускной класс.
3. Средние значения
Команда Средние предназначена для сравнения подгрупп наблюдений по таким показателям количественных переменных, как средние, медианы и пр.
Так, при помощи этой команды можно сравнить средние значения успеваемости (отметка1, отметка2) юношей и девушек (пол), учащихся разных классов (класс) и т. д.
Analyze -> Compare Means -> Means
Список независимых переменных служит для задания неколичественных (номи- нальных) переменных, градации которых определяют сравниваемые подгруппы объектов (пол, класс, вуз и т. п.)
Пример:

Сравнение средних отметок (непрерывная — dependent) для классов (номинальная — independent).
Анализ сравнения средних позволяет проводить однофакторный дисперсионный анализ

Для примера, сравним средние в группах Класс (Layer 1) и Пол (Layer 2).

Вычисленные средние значения (4,096, 4,167 и 4,408) различаются на уровне зна- чимости p < 0,001. Это свидетельствует о статистически достоверной зависимости успеваемости учащихся от класса.
Коэффициент Эта подобен корреляции и оценивает связь между двумя переменными: количе- ственной и номинативной. Коэффициент Эта в квадрате — мера влияния независи- мой переменной на дисперсию зависимой переменной. Величина 0,231 свидетельствует о том, что 23,1 % дисперсии зависимой переменной объясняются влиянием независимой переменной.
Попарно сравнить средние значения можно при помощи t-критерия Стьюдента.
4. Сравнение двух средних и t-критерий
Различные варианты обработки данных с применением t-критерия позволяют сделать вывод о различии двух средних значений. Например, в случае применения t-критерия для независимых выборок проверяется достоверность различия двух выборок по количественной переменной, измеренной у представителей этих двух выборок. Для этих выборок вычисляются средние значения количественной переменной, затем по t-критерию определяется статистическая значимость различия средних. Применение t-критерия позволяет ответить на простой вопрос: насколько существенны различия между двумя выборками по данной количественной переменной. Основное требование к данным для применения этого критерия — представление переменных, по которым сравниваются выборки, в метрической шкале измерения.
! SPSS позволяет применять 3 варианта t-критерия: t-критерий для независимых выборок, t-критерий для парных выборок, одновыборочный t-критерий.
- Первый из вариантов t-критерия, t-критерий для независимых выборок, предназначен для сравнения средних значений двух выборок. Для сравниваемых выборок должны быть определены значения одной и той же переменной. С помощью t-критерия для независимых выборок можно сравнить успеваемость студентов и студенток, степень удовлетворенности жизнью холостяков и женатых, средний рост футболистов двух команд и пр. Обязательным условием для проведения этого t-критерия является независимость выборок.
- Второй из t-критериев, t-критерий для парных или зависимых выборок, позволяет сравнить средние значения двух измерений одного признака для одной и той же выборки, например результаты первого и последнего экзаменов группы студентов или значения показателя до и после воздействия на группу. Обязательным условием применения t-критерия для зависимых выборок является наличие повторного измерения для одной выборки.
- Последний из t-критериев, одновыборочный t-критерий, позволяет сравнить среднее значение этой выборки с некоторой эталонной величиной. Например, отличается ли среднее значение некоторого теста для данной выборки от нормативной величины, отличается ли время, показанное бегунами во время соревнования, от 17 минут и т. д.
Уровень значимости
Результат сравнения средних значений с применением t-критерия оценивается по уровню значимости.
Напомним, что уровень значимости (р-уровень) является мерой статистической достоверности результата вычислений, в данном случае — различий средних, и служит основанием для интерпретации. Если исследование показало, что p-уровень значимости различий не превышает 0,05, это означает, что с вероятностью не более 5 % различия являются случайными. Обычно это яв- ляется основанием для вывода о статистической достоверности различий. В про- тивном случае (p > 0,05) различие признается статистически недостоверным и не подлежит содержательной интерпретации.
Применение t-критерия для независимых выборок
Сравнение средних -> T-критерий для независимых выборок
! Проверяемые переменные: Cами переменные должны быть метрического типа (переменные отметка1, отметка2, тест1 и т. п.)
! Группировать по: указывается имя переменной, значениям (градациям) которой соответствует две независимые выборки для t-критерия. Как правило, группирующая переменная дискретна и имеет две градации.

Output

Вывод: Из результатов следует, что выборка из 39 юношей имеет средний балл 4,13, выборка из 61 девушки — средний балл 4,28. Различия статистически достоверны на высоком уровне значимости (p = 0,009). Критерий равенства дисперсий Ливиня указывает на то, что дисперсии двух распределений статистически значимо не различаются (p = 0,807), следовательно, применение t-критерия корректно.
Применение t-критерия для парных выборок
Cравним отметки учащихся в 10 и 11 классах (отметка1 и отметка2).

Output

Вывод: Как видно из результатов, для выборки объемом N = 100 среднее значение пере- менной отметка2 (4,22) оказалось статистически значимо выше среднего значения переменной отметка1 (3,96) с уровнем значимости p < 0,001. Кроме того, между переменными отметка1 и отметка2 существует значительная корреляция (r = 0,434, p < 0,001), свидетельствующая о том, что данные переменные действительно мож- но считать зависимыми выборками.
Применение t-критерия для одной выборки
Сравнение средних -> Одновыборочный T-критерий
Иногда бывает необходимо сравнить среднее значение распределения с какой-либо фиксированной величиной. Представим себе следующую ситуацию. Исследователь решил проверить, отличаются ли данные его выборки от нормативных показателей. Предположим, нормативный показатель по выбранной переменной равен 10. Для того чтобы проверить результат выборки на соответствие норме, нужно вычислить среднее значение для выборки и сравнить его с числом 10.

Output

Вывод: Из таблиц видно, что среднее значение переменной тест2 (числовые ряды) составляет 10,35 и статистически достоверно не отличается от 10 ( p > 0,1). Среднее значение переменной тест3 (словарь) равно 11,96 и статистически достоверно отличается от 10 (p < 0,001).
Термины, используемые в выводе
- Стандартная ошибка — отношение стандартного отклонения к квадратному корню из размера выборки N. Является мерой стабильности среднего значения.
- F-критерий — величина, характеризующая соотношение дисперсий двух распределений.
- Значимость — значимость, или
р-уровень значимости. При сравнении дисперсии двух распределений, в зависимости от того, равны они или не равны, применяются различные виды статистических приближений. Величинаp > 0,05указывает на то, что дисперсии можно считать не различающимися. - t (t-критерий) — t-критерий определяется как отношение разности средних значений к стандартному отклонению.
- ст. св. — число степеней свободы, для t-критерия с независимыми выборками при равенстве дисперсий число степеней свободы равно разности числа объ- ектов и числа групп (100 – 2 = 98), а при различии дисперсий применяется более сложная формула, приводящая к дробному значению, равному 81,65. Для зависимых выборок и для одной выборки число степеней свободы для t-критерия определяется как 100 – 1 = 99.
- Значимость (2-сторонняя) — по отношению к t-критерию двусторонняя значимость означает вероятность того, что разность между средними значениями является случайной, а по отношению к коэффициенту корреляции — вероятность того, что связь между двумя переменными является случайной.
- Стд. отклонение — стандартное отклонение. Для t-критерия с зависимыми выборками это стандартное отклонение разности между значениями повторных измерений.
- Корреляция — мера связи двух переменных, а для зависимых выборок — мера связи парных переменных. Численно определяется коэффициентом корреля- ции; в данном примере использовался коэффициент Пирсона.
- 95% доверительный интервал — в случае t-критерия термин «доверительный интервал» относится к разности между средними значениями выборок.
5. Непараметрические критерии
Параметрический критерий — это метод статистического вывода, который применяется в отношении параметров генеральной совокупности. Самым главным условием для параметрических методов является нормальность распределения переменных и, как следствие, правомерность применения таких статистик, как среднее значение и стандартное отклонение.
Непараметрические методы методы предназначены для номинативных и ранговых переменных.
Восемь непараметрических методов перечислены ниже
- Сравнение двух независимых выборок (критерий Манна–Уитни) позволяет установить различия между двумя независимыми выборками по уровню выраженности порядковой переменной.
- Критерий знаков. Сравнение двух связанных (зависимых) выборок может проводиться по двум критериям. Критерий знаков основан на подсчете числа отрицательных и положительных разностей между повторными измерениями; критерий Уилкоксона в дополнение к знакам разностей учитывает их величину.
- Критерий серий определяет, является ли последовательность бинарных величин (событий) случайной или упорядоченной.
- Биномиальный критерий определяет, отличается ли распределение дихотомической величины от заданного соотношения.
- Критерий Колмогорова—Смирнова для одной выборки определяет отличие распределения переменной от нормального (равномерного, Пуассона и т. д.).
- Критерий хи-квадрат для одной выборки определяет степень отличия наблюдаемого распределения частот по градациям переменной от ожидаемого распределения.
- Сравнение К независимых выборок (критерий Н Крускала—Уоллеса) позволяет установить степень различия между тремя и более независимыми выборками по уровню выраженности порядковой переменной.
- Сравнение К связанных (зависимых) выборок (критерий Фридмана) позволяет установить степень различия между тремя и более зависимыми выборками по уровню выраженности порядковой переменной.
Примеры
5.1 Сравнение двух независимых выборок
Критерий Манна—Уитни (Mann-Whitney), или U-критерий, по назначению аналогичен t-критерию для независимых выборок. Разница заключается в том, что t-критерии ориентированы на нормальные и близкие к ним распределения, а критерий Манна–Уитни — на распределения, отличные от нормальных. В частном случае критерий Манна–Уитни можно применять и для нормально распределенных данных, однако он менее чувствителен к различиям (является менее мощным).
Пример: Выясним, различаются ли юноши и девушки по успеваемости в выпускном классе.

Output

Вывод: Средний ранг для девушек равен 56,21, а для юношей — 41,56. Это значит, что у девушек успеваемость выше, чем у юношей. Статистика U Манна-Уитни равна 841. Значение Z является нормализованным, связанным с уровнем значимости p = 0,014. Поскольку величина уровня значимости (Асимпт. знч (двухсторонняя)) меньше 0,05, мы можем быть уверены в статистической достоверности вывода о том, что успе- ваемость девушек действительно выше успеваемости юношей.
5.2 Сравнение двух связанных (зависимых) выборок
Основные методы, которые используются для сравнения двух зависимых выборок, — это критерий знаков и критерий Уилкоксона (Wilcoxon test).
5.2.a Критерий знаков
Критерий знаков позволяет сравнить два измерения переменной на одной выборке (например, «до» и «после») по уровню ее выраженности путем сопоставления количества положительных и отрицательных разностей (сдвигов) значений.
Пример: сравним результаты учащихся по второму (тест2) и четвертому (тест4) тестам

Output

Вывод: в 39 случаях значения переменной тест2 оказались меньшими, чем значения переменной тест4, в 57 случаях значе- ния переменной тест2 превысили значения переменной тест4, и 4 раза было уста- новлено равенство значений обеих переменных. Стандартизованное значение (Z) составляет –1,735, а уровень значимости p = 0,083. Это означает, что различия между результатами тестов тест4 и тест2 статистически недостоверны. Обратите внимание: поскольку переменные тест4 и тест2 являются метрическими, к ним предпочтительней применить t-критерий для парных выборок. Он показал бы, что средние значения тест4 и тест2 различаются с уровнем значимости p = 0,01. Таким образом, можно на практике убедиться в том, что статистические возможности t-критерия в отношении переменных значительно выше, чем возможности критерия знаков.
5.2.b Критерий Уилкоксона
Корректность применения этого критерия сомнительна, если переменная имеет небольшое число возможных значений, например, 3-балльная шкала.
Output

Вывод: Результаты применения критерия Уилкоксона и критерия знаков очень похожи. Частота каждого из трех исходов N осталась неизменной. Информация о каждом из исходов (кроме равенства) теперь включает также среднее и суммарное значе- ния для соответствующих рангов. Визуальный анализ исходных данных говорит о том, что значения теста 4 (осведомленность) в целом несколько превышают зна- чения теста 2 (числовые ряды). Это демонстрирует и величина Z = –2,493, которая значительно превосходит по модулю соответствующее значение, полученное ранее для критерия знаков. Уровень значимости p = 0,013, что говорит о статистической достоверности различий. Таким образом, мы убеждаемся в том, что критерий Уилкоксона является более чувствительным к различиям (более мощным), чем крите- рий знаков. Тем не менее он оказывается несколько хуже t-критерия, обеспечивающего уровень значимости 0,01, что подтверждает предпочтительность последнего для анализа метрических данных.
5.3 Критерий серий
Критерий серий применяется для анализа последовательности объектов (явлений, событий), упорядоченных во времени или в порядке возрастания (убывания) значений измеренного признака. Кроме того, критерий требует представления последовательности в виде бинарной переменной, то есть как чередования событий 0 и 1. Гипотеза о случайном распределении событий 1 среди событий 0 может быть отклонена, если количество серий либо слишком мало (однотипные события имеют тенденцию к группированию), либо слишком велико (события 0 и 1 имеют тенденцию к чередованию).
Пример: проверим гипотезу о неслучайном чередовании юношей и девушек (переменная пол).

Output

Вывод: Количество серий равно 49. В результаты включено значение точки деления, вве- денное в поле Задаваемое. Величина Z и соответствующая значимость зависят от числа серий. Число серий преобразуется к z-значению, для которого и определяется p-уровень. Большое значение p-уровня (0,929) свидетельствует о том, что чередование юношей и девушек в файле является случайным. Статистически значимый результат свидетельствовал бы о том, что чередование юношей и девушек в файле является неслучайным. Если при этом число серий было бы слишком велико, это свидетельствовало бы о том, что после юноши с высокой долей вероятности следует девушка (и наоборот). При малом значении числа серий можно было бы сделать вывод о том, что более вероятно группирование испытуемых в списке по половому признаку (после юноши чаще следует юноша, а после девушки — девушка).
5.4 Биномиальный критерий
Назначение биномиального критерия — определение вероятности того, что наблю- даемое распределение не отличается от ожидаемого (заданного) биномиального распределения. Свойством биномиального распределения является заранее задан- ное соотношение вероятностей двух взаимоисключающих событий (обычно — равновероятное). Например, при многократном подбрасывании «правильной» монеты вероятности выпадения «орлов» и «решек» подчиняется биномиальному распределению.
Пример: исследуем распределение юношей и девушек. Проверим, отличается ли статистически достоверно это распределение (наблюдаемое) от ожидаемого (теоретического) равновероятного соотношения.

Output

Вывод: Ожидаемая пропорция для биномиального теста равна 0,5 для обеих групп. На- блюдаемая пропорция для каждой из групп определяется как отношение размера группы (N ) к размеру выборки (100). Как можно видеть, наблюдаемые пропорции значительно отличаются от 0,5 и составляют 0,39 для мужчин и 0,61 для женщин. Уровень значимости, равный 0,035, свидетельствует о статистически достоверном отличии исследуемого распределения от биномиального (равновероятного).
5.5 Критерий Колмогорова–Смирнова для одной выборки
Критерий Колмогорова–Смирнова для одной выборки позволяет определить, отличается ли заданное распределение от нормального (эксцесс и асимметрия распределения равны 0), равномерного (значения распределены с одинаковой плотностью, например, как у целых чисел от 1 до 1000), Пуассона (среднее значение и дисперсия равны (lambda); при больших значениях (lambda) распределение Пуассона приближается к нормальному) или экспоненциального.
Пример: исследуем распределение значений переменной отметка1 на соответствие нормальному распределению.

Output

Вывод: В строке Разности экстремумов приведены Модуль, а также Положительные и Отрицательные отклонения исследуемого распределения от теоретического (в данном случае, нормального). Строка Статистика Z Колмогорова-Смирнова содержит z-значение, уровень значимости которого равен 0,685 (последняя строка). Это означает, что распределение значений переменной отметка1 статистически не отличается от нормального (p > 0,05).
5.6 Критерий хи-квадрат (chi^{2}) для одной выборки
В данном случае в качестве ожидаемого (теоретического) распределения обычно выступает равномерное распределение объектов по градациям перемен- ной, в отношении которой применяется критерий. Далее будет приведен пример применения критерия (chi^{2}) к переменной вуз. Поскольку число объектов (N) равно 100, а переменная вуз имеет 4 градации, ожидаемые частоты для каждой градации равны 100/4 = 25. Применение рассматриваемого критерия допускает задание не только равномерного ожидаемого распределения, но и любого другого. Например, можно проверить гипотезу о том, что соотношение учащихся, предпочитающих 4 категории специализаций, соотносятся как 20:20:30:30. Для этого в группе Ожидаемые значения следует установить переключатель Значения, а затем при помощи поля и кнопки Добавить последовательно ввести в список значения 20, 20, 30, 30. После этих действий ожидаемые частоты изменятся в соответствии с заданными пропорциями.

Output

Вывод: Первая из таблиц демонстрирует заметные различия наблюдаемых и ожидаемых частот. Остаток — это разность между наблюдаемыми и ожидаемыми частотами. Число степеней свободы (ст.св.) определяется как число значений (градаций) переменной, уменьшенное на 1. Уровень значимости ( p = 0,002) свидетельствует о статистически достоверном отличии наблюдаемого распределения предпочтений от равномерного распределения.
5.7 Сравнение К независимых выборок и критерий Крускала–Уоллеса
Для сравнения более двух независимых выборок по уровню выраженности переменной применяется несколько критериев: H-критерий Крускала—Уоллеса, критерий медианы, критерий Джонкира—Терпстра. Из них наибольшей чувствительностью к различиям обладает H-критерий Крускала—Уоллеса. Этот критерий является непараметрическим аналогом однофакторного дисперсионного анализа, отличаясь от него в двух отношениях. Во-первых, критерий Крускала—Уоллеса основан не на сравнении средних значений и дисперсий переменных, а на сравнении средних рангов. Во-вторых, вместо вычисления F-критерия на основе сравнения средних рангов с ожидаемыми значениями вычисляется критерий хи-квадрат. Для нормальных распределений однофакторный дисперсионный анализ обеспечивает более точные результаты, чем критерий Крускала—Уоллеса, однако применение последнего рекомендуется для распределений, отличающихся от нормального.
H-критерий Крускала—Уоллеса «по идее» сходен с U-критерием Манна—Уитни. Как и последний, он оценивает степень пересечения (совпадения) нескольких рядов значений измеренного признака. Чем меньше совпадений, тем больше различаются ряды, соответствующие сравниваемым выборкам. Основная идея H-критерия Крускала—Уоллеса основана на представлении всех значений сравниваемых выборок в виде одной общей последовательности упорядоченных (ранжированных) значений с последующим вычислением среднего ранга для каждой из выборок. Если выполняется статистическая гипотеза об отсутствии различий, можно ожидать, что все средние ранги примерно равны и близки к общему среднему рангу.
Пример: проведем сравнение трех групп учащихся, отличающихся внешкольными увлечениями (переменная хобби) и успеваемостью в выпускном классе (переменная отметка2).

Output

Вывод: В первой таблице для каждой группы представлена ее численность и средний ранг. Во второй таблице указано значение критерия (chi^{2}), число степеней свободы и уровень статистической значимости. Результаты обработки показывают статистически достоверную связь внешкольных увлечений учащихся с успеваемостью в выпускном классе.
5.8 Сравнение нескольких зависимых выборок и критерий Фридмана
Критерий Фридмана является непараметрическим аналогом однофакторного дис- персионного анализа для повторных измерений. Он позволяет проверять гипотезы о различии более двух зависимых выборок (повторных измерений) по уровню выраженности изучаемой переменной. Критерий Фридмана может быть более эффективен, чем его метрический аналог однофакторный дисперсионный анализ в случаях повторных измерений изучаемого признака на небольших выборках и при отличии распределения от нормального. Если выполняется статистическая гипотеза об отсутствии различий между повторными измерениями, можно ожидать примерного равенства сумм рангов для этих условий. Чем больше различаются зависимые выборки по изучаемому признаку, тем больше эмпирическое значение вычисляемого значения критерия (chi^{2}), по которому определяется p-уровень значимости.
Пример: сравним результаты тестов тест1, тест2, тест3, тест4 и тест5 для всех учащихся.

Output

Вывод: Средние ранги определяются следующим образом: сначала для каждого наблюдения значения сравниваемых переменных ранжируются (по строке). Затем для каждой из сравниваемых переменных вычисляется средний ранг по всем объектам. Определяемый по критерию (chi^{2}) уровень значимости Асимпт. знч. < 0.001. Он свидетельствует о статистически значимой разнице между пятью результатами тестирования. Различаться может любая пара переменных, и без попарного сравнения невозможно выяснить, какие именно пары вносят значимый вклад в факт статистической достоверности результата.
6. Однофакторный дисперсионный анализ
Дисперсионный анализ (Analysis Of Variances, ANOVA — общепринятое обозначение метода) — это процедура сравнения средних значений выборок, на основании которой можно сделать вывод о соотношении средних значений генеральных совокупностей. Ближайшим и более простым аналогом ANOVA является t-критерий. В отличие от t-критерия дисперсионный анализ предназначен для сравнения не двух, а нескольких выборок. Слово «дисперсионный» в названии указывает на то, что в процессе анализа сопоставляются компоненты дисперсии изучаемой переменной. Общая изменчивость переменной раскладывается на две составляющие: межгрупповую (факторную), обусловленную различием групп (средних значений), и внутригрупповую (ошибки), обусловленную случайными (неучтенными) причинами. Чем больше частное от деления межгрупповой и внутригрупповой изменчивости (F-отношение), тем больше различаются средние значения сравниваемых выборок и тем выше статистическая значимость этого различия.
В ANOVA можно задать единственную зависимую переменную (при этом она обязательно должна быть количественного, а точнее метрического типа) и единственную независимую переменную (всегда номинальную, имеющую несколько градаций).
При однофакторном дисперсионном анализе сравниваются между собой средние значения каждой выборки и вычисляется общий уровень значимости различий. Вывод по результатам ANOVA касается общего различия всех сравниваемых средних без конкретизации того, какие именно выборки различаются, а какие нет. Для идентификации пар выборок, отличающихся друг от друга средними значениями, используются апостериорные критерии парных сравнений (Post Hoc), а для более сложных сопоставлений — метод контрастов (Contrasts).
Зависимые переменные должны быть метрического типа.
Фактор, в котором нужно указать единственную независимую переменную, имеющую несколько градаций (в нашем случае — хобби).
Пример: в роли зависимой переменной выступит переменная тест1, а независимая переменная класс разделит объекты на три выборки, средние значения которых мы будем сравнивать.
Однофакторный дисперсионный анализ
Мы будем сравнивать между собой средние значения переменной тест1 для каждой из выборок по уровням переменной хобби.
Флажок Описательные статистики приведет к включению в выводимые данные всех средних значений, стандартных отклонений, стандартных ошибок, границ доверительных интервалов в 95 %, а также минимумов и максимумов выборок. Флажок Проверка однородности дисперсии позволяет вывести информацию о степени пригодности данных к дисперсионному анализу, а с помощью флажка График средних можно построить диаграмму, на которой будут изображены средние значения для каждой выборки.

Output

Вывод: Самым важным в этой таблице является уровень значимости (p = 0.002). Он указывает на то, что разность между средними значениями переменной тест1 для трех групп статистически достоверна. Знаком звездочки помечены те пары выборок, для которых разность средних значений статистически достоверна, то есть со значением уровня значимости 0,05 и меньше. Из полученных данных можно сделать вывод, что результаты теста 1 для тех, кто увлекается компьютером, статистически выше значимы, чем для тех, кто увлекается спортом и искусством. Те же, кто увлекаются спортом и искусством, по результатам теста 1 статистически достоверно не различаются.
Критерий однородности дисперсии Ливиня со значимостью 0,161 показал, что дисперсии для каждой из групп статистически достоверно не различаются. Следовательно, результаты ANOVA могут быть признаны корректными. Если бы результат применения критерия Ливиня оказался статистически достоверным, то это послужило бы основанием для сомнения в корректности применения ANOVA.
7. Многофакторный дисперсионный анализ
ANOVA с двумя и более факторами.
- Единственная зависимая переменная должна быть метрической.
- Несколько независимых переменных, каждая из которых должна быть номинальна, то есть иметь несколько градаций, или уровней.
В многофакторном дисперсионном анализе появляется проблема взаимодействия факторов. Выполним двух- и трехфакторный дисперсионный анализ с учетом влияния ковариаты.
Дисперсионный анализ (ANOVA) определяет статистическую достоверность различия между выборками путем сравнения их средних значений.
7.1 Дисперсионный анализ с двумя факторами
Попытаемся определить степень влияния переменных Интонация (Инт), Часть ряда (Ч_ряда) и их взаимодействия Инт × Ч_ряда на распределение значений переменной Слова. Такая схема анализа может быть лаконично обозначена как ANOVA 2 × 3 (Интонация × Часть ряда). Исследование позволит получить ответы на перечисленные ниже вопросы.
- Существует ли главный эффект фактора Инт, то есть существует ли значимое различие в продуктивности воспроизведения всего ряда из 24 слов в зависимости от интонационного выделения середины ряда и какова степень этого различия?
- Существует ли главный эффект фактора Ч_ряда, то есть существует ли зна- чимое различие в продуктивности воспроизведения трех частей ряда (начала, середины и конца) и какова степень этого различия?
- Существует ли взаимодействие переменных Инт и Ч_ряда, то есть зависит ли влияние одной из этих переменных от уровней (значений, градаций) другой?
7.2 Дисперсионный анализ с тремя и более факторами
Предположим, изучается влияние на переменную Слова трех факторов: Инт, Ч_ряда и Отсрочка.
- Существует ли главный эффект фактора Инт, то есть существует ли значимое различие в продуктивности воспроизведения всего ряда из 24 слов в зависимости от интонационного выделения середины ряда и какова степень этого различия?
- Существует ли главный эффект фактора Ч_ряда, то есть существует ли зна- чимое различие в продуктивности воспроизведения трех частей ряда (начала, середины и конца) и какова степень этого различия?
- Существует ли главный эффект фактора Отсрочка, то есть существует ли зна- чимое различие в продуктивности воспроизведения всего ряда в зависимости от отсрочки?
- Существует ли взаимодействие переменных Инт и Ч_ряда, то есть зависит ли влияние одной из этих переменных от уровней (значений, градаций) другой?
- Существует ли взаимодействие переменных Инт и Отсрочка, то есть зависит ли влияние одной из этих переменных от градаций другой?
- Существует ли взаимодействие переменных Ч_ряда и Отсрочка, то есть зависит ли влияние одной из этих переменных от градаций другой?
- Существует ли взаимодействие переменных Инт, Ч_ряда и Отсрочка, то есть за- висит ли взаимодействие двух из этих переменных от градаций третьей?
Трехфакторный дисперсионный анализ предполагает проверку уже семи гипотез.
7.3. Влияние ковариат
Ковариаты используются для исключения влияния количественной переменной на зависимую переменную. Ковариату проще всего представить как переменную, значительно коррелирующую с зависимой переменной и позволяющую умень- шить ее дисперсию. За счет включения в анализ ковариаты дисперсия зависимой переменной уменьшается, что позволяет сделать более очевидным влияние анали- зируемых факторов. В нашем исследовании в качестве ковариаты будет использоваться переменная Знач. Эта переменная (эмоциональная значимость предъявляемого ряда слов) в существенной степени коррелирует с продуктивностью воспроизведения этого ряда (Слова).

Output

Вывод: Таблица Оценка эффеков межгрупповых факторов содержит результаты проверки трех основных гипотез двухфакторного дисперсионного анализа:
- Переменная Ч_ряда не оказывает статистически достоверное влияние на распре- деление зависимой переменной Слова (средние значения для начала, середины и конца ряда составили соответственно 3,08, 3,70 и 3,28, F = 2,364, p = 0,099).
- Переменная Инт не оказывает статистически значимого влияния на распределе- ние зависимой переменной Слова (средние значения для групп «нет» и «есть» составили соответственно 3,45 и 3,25, F = 0,696, p = 0,406).
- Обнаружено статистически достоверное взаимодействие на высоком уровне статистической значимости между независимыми переменными Ч_ряда и Инт (F = 8,543, p < 0,001).
Влияние ковариаты. Таблицы Оценка эффектов межгрупповых факторов
Ковариата ЗНАЧ оказывает значительное влияние на разброс зависимой переменной Слова: значение (eta^{2}) составляет 0,265, то есть 26,5 % дисперсии переменной Слова обусловлено влиянием ковариаты. Дисперсия скорректированной модели представляет собой сумму всех сумм квадратов дисперсий, обусловленных влияниями независимых переменных и их взаимодействий.
Двухфакторный дисперсионный анализ с зависимой переменной Слова, независимыми переменными Инт и Ч_ряда и ковариатой «`ЗНАЧ« дал следующие результаты:
- Ковариата
ЗНАЧоказывает статистически достоверное влияние на зависимую переменнуюСлова(F = 40,73, p < 0,001). - Переменная
Интоказывает статистическое влияние на распределение зависимой переменнойСлова(F = 4,429, p =0,038). - Переменная
Ч_рядаоказывает статистически значимое влияние на распределение зависимой переменнойСлова(F = 3,188, p = 0,045). - Обнаружено статистически достоверное взаимодействие между независимыми переменными
Ч_рядаиИнт(F = 11,52, p < 0,001).
8. Простая линейная регрессия (стр239)
Рассмотрим такие понятия, как прогнозируемые значения зависимой переменной и уравнение регрессии, покажем связь между простой регрессией и корреляцией двух переменных, рассмотрим влияние одной переменной на дисперсию другой, а также ознакомимся с оценкой криволинейности связи двух переменных.
Пример: есть датасет с переменными трев и тест. Гипотеза о линейности отношения этих двух переменных говорит о том, что чем выше нервная возбудимость студента, тем выше его результативность (например, потому, что спокойных студентов меньше волнуют их знания, а тревожные студенты проводят больше времени за подготовкой к зачету).
- Зависимая переменная (критерий) — переменная
тест, - Независимая переменная (предиктор) — переменная
трев.
Уравнение регрессии: ({тест}_{истина} = константа + коэфициент*трев + остаток)
В результате применения линейного регрессионного анализа константа оказалась равной 9.3114, а коэффициент регрессии 0.6751. Соответственно, уравнение для прогноза результата зачетного тестирования выглядит следующим образом:
[{тест}_{прогноз} = 9.3114 + 0.6751*трев]
[{тест}_{истина} = тест_{прогноз} + остаток]
Прогнозируемое значение будет отличаться от истинного значения. Чтобы получить истинный результат, необходимо ввести в уравнение член, равный разности прогнозируемого и реального значений. Этот член и называют остатком.
[РеальноеЗначение = ПрогнозируемоеЗначение + остаток]
Величины, которые вычисляются при проведении регрессионного анализа:
- (R) — Коэффициент корреляции. Коэфициент, характеризующий связь между значениями зависимой и независимой переменных.
- (p-ур.знач.) — (p < 0.05) свидетельствует о значимой корреляции переменных. При (p > 0.05) вероятность случайности результата считается слишком высокой, и в этом случае говорят, что связь между переменными слабая или не обнаружена.
- (R^{2}) — характеризует долю дисперсии одной переменной, обусловленной воздействием другой переменной. Так, для переменных
тревитестзначение (R = 0.546), а (R^{2}) = 0.298. Это означает, что 29.8 % дисперсии переменнойтестобъясняется влиянием независимой переменнойтрев.
Оценка криволинейности
В приведенном ранее примере мы видим значительную корреляцию между переменными трев и тест ((R = 0.546), (p < 0.001)), однако возможная ошибка прогноза велика (только 29.8 % дисперсии переменной тест объясняется влиянием переменной трев). Можно предположить, что если изменить вид общего уравнения (например, включить в него квадрат переменной трев), прогнозируемые значения будут ближе к реальным.
Построим график рассеяния переменных тест и трев

Чтобы статистически оценить криволинейность, в подменю Регрессия есть Подгонка кривых. Там необходимо задать зависимую переменную (тест), независимую переменную (трев) и установить флажки Линейная и Квадратичная.

Output

В результаты включены значения коэффициентов B регрессии (Константа b0, b1, b2), поэтому не сложно составить линейное и квадратичное уравнения регрессии для прогнозируемых значений.
Для линейной уравнение имеет вид: ({тест}_{прогноз} = 9.3114 + 0.6751 times трев)
Для квадратичной уравнение имеет вид: ({тест}_{прогноз} = 0.1615 + 4.4896 times трев — 0.3381 times (трев)^{2})

В случае линейной регрессии величина (R^{2}) (столбец R квадрат в таблице выводимых результатов) равна 0.298, то есть 29.8 % дисперсии переменной тест обусловлено воздействием со стороны переменной трев. В то же время для квадратичной регрессии, которая учитывает и линейную, и криволинейную связи, (R^{2} = 0.675), то есть она обусловливает 67.5 % дисперсии переменной тест. Малый p-уровень для обоих уравнений свидетельствует об очень высокой статистической достоверности полученных результатов. Очевидно, что квадратичная регрессия описывает отношения между переменными тест и трев более адекватно, чем линейная. Значения F-критерия и соответствующие значимости (для F и t) говорят о сильном воздействии на зависимую переменную как обеих независимых переменных, так и каждой переменной в отдельности.
9. Множественный регрессионный анализ
Множественная регрессия исследует влияние двух и более предикторов на критерий.
Переменные

Простая регрессия. Переменная помощь представляет время (в секундах), потраченное человеком на оказание помощи своему партнеру, и ее значения имеют нормальное распределение (среднее равно 30, стандартное отклонение — 10). Переменная симпатия отражает оценку симпатии к партнеру в баллах от 1 до 20. На примере этих двух переменных мы продемонстрируем простую регрессию. В качестве зависимой выступит переменная помощь, а в качестве независимой — переменная симпатия (предполагается, что симпатия и сочувствие заставляют человека оказывать помощь, а не наоборот). Как показал анализ, коэффициент корреляции между переменными помощь и симпатия составляет 0.416 при значимости p = 0.004, что говорит о значительной связи между этими переменными. Константа и коэффициент регрессии составили соответственно 14.739 и 1.547. Таким образом, уравнение регрессии имеет следующий вид:
[{помощь}_{прогноз} = 14.739 + 1.547 times (симпатия)]
Множественная регрессия. Множественный регрессионный анализ показал следующие коэффициенты при каждой из переменных: (B(симпатия) = 1.0328), (B(агрессия) = 1.1676), (B(польза) = 1.2569) , (константа = –5.3147). Уравнение регрессии для множественного анализа имеет следующий вид:
[{помощь}_{прогноз} = –5.3147 + 1.0328 times (симпатия) + 1.1676 times (агрессия) + 1,2569 times (польза)]
Возьмем объект с номером 7 и рассчитаем для него прогнозируемое значение переменной помощь:
[{помощь}_{прогноз} = –5.3147 + 1.0328 times 2 + 1.1676 times 10 + 1.2569 times 9 = 19.74]
Таким образом, человек, имеющий низкий показатель симпатии и средние показатели агрессивности и самооценки полезности, должен, согласно прогнозу, оказывать незначительную помощь. Фактическое значение переменной помощь для объекта 7 составило 21, что свидетельствует о высокой точности нашего прогноза.
9.1. Коэффициент детерминации и пошаговые методы
Коэффициент (R) является мерой связи всей совокупности независимых переменных и зависимой переменной. Часто его называют коэффициентом множественной корреляции. Величина(R^{2}) равна доле дисперсии зависимой переменной, обусловленной влиянием со стороны независимых переменных, и называется коэффициентом детерминации. Для регрессионного анализа с тремя независимыми переменными, речь о котором шла выше, значение (R = 0.571), а (R^{2} = 0.326). Это означает, что 32.6 % дисперсии переменной помощь определяется совокупным воздействием переменных агрессия, симпатия и польза.
Множественный регрессионный анализ позволяет использовать любое количество предикторов, но присутствие большого числа независимых переменных не всегда удобно. Было бы предпочтительно иметь в качестве предикторов как можно больше переменных, оказывающих значимое влияние на критерий, и как можно меньше переменных, не оказывающих такого влияния. В процедуру множественной регрессии SPSS включены методы, позволяющие производить пошаговый отбор в регрессионное уравнение только значимых независимых переменных. Одним из них является метод Включение, суть которого заключается в следующем. Сначала процедура вычисляет, какая из независимых переменных имеет наибольший коэффициент корреляции с зависимой переменной, а затем составляет уравнение регрессии с участием этой переменной. Далее из числа оставшихся предикторов выбирается тот, который имеет наибольший коэффициент (beta), при условии, что (beta) является значимым. Выбранный предиктор также включается в уравнение регрессии. Процесс продолжается до тех пор, пока не будут выбраны все предикторы, оказывающие значимое воздействие на зависимую переменную (имеющие статистически достоверные коэффициенты (beta)). По умолчанию SPSS продолжает выбирать независимые переменные до тех пор, пока уровень значимости ((p)) коэффициентов (beta) не превысит значения 0.05. Разумеется, при желании вы можете изменить величину порогового уровня значимости.
Рассмотрим основные условия, выполнение которых способствует получению действительно ценных результатов анализа:
-
Распределение значений предикторов должно быть близким к нормальному. Желательно, чтобы значения асимметрий и эксцессов по модулю не превосходили 1. Тем не менее можно получить весьма точные результаты, если это требование не выполняется строго для каждого из предикторов, и даже в случае, если в анализ входит дискретная переменная с небольшим числом значений. Нормальность распределения зависимой переменной также желательна, однако допустимы как отклонения от нормальности, так и использование дискретных переменных с малым числом значений.
-
Наиболее жестким требованием является запрет на использование зависимых переменных, корреляции между которыми близки к 1 (–1). Для проверки это- го требования можно использовать статистики коллинеарности.
Выполнение

! Важно. Раскрывающийся список Метод. Пункты этого списка определяют алгоритмы включения независимых переменных в уравнение регрессии.
- Принудительное включение — метод, применяющийся по умолчанию. Все независимые переменные включаются в уравнение независимо от степени их корреляции с переменной-критерием.
- Включение — пошаговое включение переменных с проверкой на значимость их частной корреляции с критерием. В результате в уравнение включаются все переменные, имеющие значимую частную корреляцию с переменной-критерием. Включение производится в порядке возрастания p-уровня.
- Исключение — пошаговый метод, сначала включающий в уравнение регрессии все независимые переменные, а затем поочередно удаляющий все переменные, чья корреляция с критерием имеет уровень значимости выше заданного порогового значения. Как правило, пороговым значением является p = 0,1.
- Шаговый отбор — комбинация пошаговых методов включения и исключения. Основной идеей является изменение доли влияния независимой переменной на критерий при появлении в уравнении других независимых переменных. Если влияние какой-либо из включенных переменных становится слишком слабым, она исключается из уравнения. Подобный метод используется при регрессионном анализе наиболее часто.
- Блочное исключение — это метод принудительного удаления переменных. Он требует предварительного задания метода Включение в качестве предыдущего блока, например Блок 1 из 1. При задании следующего блока, в данном случае Блок 2 из 2, в список Независимые переменные вы сможете ввести те независимые переменные, которые хотите исключить из уравнения регрессии. При выполнении команды вы получите результат со всеми заданными переменными, а затем — результат с удаленными переменными. Если в анализе участвуют несколько блоков, то можно задавать операцию удаления после каждого из них.
Кнопка Переменная отбора наблюдений — возможность выбрать группирующую переменную для задания подгруппы наблюдений.
! Окно Линейная регрессия: Статистики. Наиболее важные флажки.
- Доверительные интервалы — включает в вывод для коэффициентов (B) доверительный интервал в 95 %.
- Матрица ковариаций — генерирует таблицу, под главной диагональю которой расположены ковариации, на главной диагонали — дисперсии, а над главной диагональю — корреляции.
- Изменение (R-квадрата) — для методов
ВключениеиШаговый отборуказывает изменения коэффициента (R^{2}) при введении новых переменных в уравнение регрессии. - Описательные статистики — включает средние значения переменных, стандартные отклонения, а также корреляционную матрицу.
- Диагностика коллинеарности — устанавливает наличие коллинеарностей (корреляций, близких к 1) между переменными.
! Окно Линейная регрессия: Сохраниение. Наиболее важные флажки.
Данное окно позволяет создать в файле данных новые переменные, содержащие значения, соответствующие установленным флажкам.
- В группе Предсказанные значения имеются 4 флажка. Флажок Нестандартизованные генерирует прогнозируемые значения, которые бывает полезно сравнить с фактическими значениями для оценки адекватности уравнения регрессии. Флажок Стандартизованные позволяет рассчитывать стандартизированные прогнозируемые значения (в z-значениях).
- Флажки в группе Статистики влияния позволяют исключать из выборки те или иные объекты. Так, если в команде спортсменов-бегунов один пробегает дистанцию гораздо хуже или гораздо лучше других, его результаты значительно искажают статистические показатели всей команды. Иногда подобные значения («выбросы») желательно исключать из анализа. К сожалению, подробное изложение этой процедуры выходит за пределы темы данной книги.
Пример 1: МРА с участием зависимой переменной помощь и пяти предикторов: симпатия, проблема, эмпатия, польза и агрессия. C методом Принудительное включение.

Output

Вывод: В уравнение регрессии включены все пять предикторов. Коэффициент множественной корреляции (R) отражает связь зависимой переменной помощь с совокупностью независимых переменных и равен 0.598. Значение (R^{2}) составляет 0.358 и показывает, что 35.8 % дисперсии переменной помощь обусловлено влиянием предикторов. Стандартные коэффициенты регрессии (beta) отражают относительную степень влияния каждого из предикторов, но ни один из них не достигает статистической значимости ( (p > 0.05)). Следовательно, вклад предикторов в оценку зависимой переменной не может быть проинтерпретирован, и результат имеет сомнительную ценность.
Пример 2: МРА с участием зависимой переменной помощь и пяти предикторов: симпатия, проблема, эмпатия, польза и агрессия. C методом Шаговый отбор.
Будем использовать метод Шаговый отбор, включим в результат статистики для коэффициентов (B), описательные статистики и характеристики модели.


Сгенерированы данные, позволяющие судить о том, какая из независимых переменных оказывает наибольшее влияние на критерий. При составлении уравнения регрессии сначала в него включаются переменные, чья частная корреляция ((β)) с зависимой переменной имеет уровень значимости не выше 0.05. Если затем обнаружится, что из включенных переменных какие-либо обнаруживают новый уровень значимости, превышающий значение 0.1, они исключаются из уравнения. Кроме того, в результате выполнения процедуры будет создана переменная для хранения прогнозируемых значений переменной помощь, рассчитанных по составленному уравнению регрессии. В окне вывода можно найти корреляционную матрицу для всех переменных и описательные статистики.
Output

Вывод: в результате применения пошагового метода из пяти предикторов в уравнение регрессии включены лишь три (модель 3): симпатия, агрессия и польза. Коэффициент множественной корреляции R отражает связь зависимой переменной помощь с совокупностью независимых переменных и равен 0.571. Значение (R^{2}) составляет 0.326 и показывает, что 32.6 % дисперсии переменной помощь обусловлено влиянием предикторов. Стандартные коэффициенты регрессии (beta) являются статистически достоверными, что позволяет интерпретировать относительную степень влияния каждого из предикторов; для переменной симпатия (beta = 0.278), а для переменных агрессия и польза соответственно (beta = 0.276) и (beta = 0.269). Каждая из независимых переменных вносит примерно одинаковый вклад в оценку зависимой переменной и коррелирует с ней положительно.
Терминология вывода:
- Вероятность F-включения — максимальный уровень значимости переменных, вводимых в уравнение регрессии, в данном случае равный (p = 0.050).
- R — коэффициент множественной корреляции, отражающий связь совокупности предикторов
симпатия,агрессияипользас критериемпомощь. - R-квадрат — коэффициент детерминации ((R^{2})), равный доле дисперсии зависимой переменной
помощь, обусловленной влиянием независимых переменныхсимпатия,агрессияипольза. - Скорректированный R-квадрат — исправленная величина (R^{2}). Величина (R^{2}), используемая в расчетах, на практике оказывается несколько завышенной. Исправленная величина (R^{2}) ближе к реальным результатам.
- Стд. ошибка оценки — в таблице Сводка для модели стандартное отклонение ожидаемого значения переменной
помощь. Как видно из приводимых данных, с добавлением каждой новой независимой переменной в уравнение регрессии эта величина уменьшается. - Регрессия — статистика, отражающая влияние предикторов на зависимую переменную.
- Остаток — статистика, отражающая внешнее (не обусловленное предикторами) влияние на независимую переменную.
- B — нестандартизированные коэффициенты и константа уравнения регрессии, связывающего критерий и предикторы:
[{помощь}_{прогноз} = –5.3147 + 1.0328 times (симпатия) + 1.1676 times (агрессия) + 1.2569 times (польза)]
- Стд. ошибка — в таблице Коэффициенты является мерой стабильности коэффициентов (B) и равна стандартному отклонению их значений, рассчитанных для большого числа выборок.
- Бета — стандартизованный коэффициент регрессии ((beta)), представляющий собой коэффициенты (B) для независимых переменных, представленных в z-шкале. Для линейных взаимодействий (beta) по абсолютному значению не превосходит 1; для криволинейных взаимодействий это условие не является обязательным.
- t — отношение коэффициента (B) к своей стандартной ошибке.
- Бета включения — значения коэффициента (beta) для переменных, не включенных в уравнение регрессии в предположении, что они в него включены.
- Частная корреляция — коэффициенты частной корреляции для переменных, входящих в уравнение регрессии. Наличие в этом уравнении нескольких коррелирующих переменных взаимно снижает их частную корреляцию.
10. Факторный анализ
Факторный анализ дает возможность количественно определить нечто, непосредственно неизмеряемое, исходя из нескольких доступных измерению переменных. Например, характеристики «посещает развлекательные мероприятия», «много разговаривает».
Факторный анализ позволяет установить для большого числа исходных признаков сравнительно узкий набор «свойств», характеризующих связь между группами этих признаков и называемых факторами.
Этапы факторного анализа
- Вычисление корреляционной матрицы для всех переменных, участвующих в анализе.
- Извлечение факторов.
- Вращение факторов для создания упрощенной структуры.
- Интерпретация факторов.
10.1 Вычисление корреляционной матрицы
Без комментариев
10.2. Извлечение факторов
С математической точки зрения извлечение факторов имеет определенную аналогию с множественным регрессионным анализом. Первым шагом множественного регрессионного анализа является выбор той независимой переменной, которая обусловливает наибольшую долю дисперсии зависимой переменной. Затем операция повторяется для оставшихся независимых переменных до тех пор, пока добавляемая доля дисперсии не перестанет быть значимой. В факторном анализе существует аналогичная процедура.
Извлечение фактора начинается с подсчета суммарного разброса значений всех участвующих в анализе переменных (данная величина чем-то похожа на общую сумму квадратов). Для этого «суммарного разброса» непросто подобрать логическую интерпретацию, однако он является вполне строго определенной математической величиной. Первой задачей факторного анализа является выбор взаимодействующих переменных, чья взаимная корреляция обусловливает наибольшую долю общей дисперсии. Эти переменные образуют первый фактор. Затем первый фактор исключается и из оставшегося множества переменных снова выбираются те, чье взаимодействие определяет наибольшую долю оставшейся общей дисперсии. Эти переменные образуют второй фактор. Процедура извлечения факторов продолжается до тех пор, пока не будет исчерпана вся общая дисперсия переменных.
10.3. Выбор и вращение факторов
Целью факторного анализа является сокращение исходного набора переменных. Итак, нужно принять решение, какие из факторов следует оставить для дальнейшего анализа. Здесь, в первую очередь, рекомендуется руководствоваться здравым смыслом и оставлять те факторы, которые имеют понятную теоретическую или логическую интерпретацию. Однако не всегда представляется возможным заранее установить назначение каждого фактора, и поэтому исследователи на первом этапе обычно используют формальные критерии. При выполнении факторного анализа с установками по умолчанию все факторы, чьи собственные значения превышают единицу, сохраняются для дальнейшего анализа. Поскольку число факторов равно числу переменных, лишь для небольшого количества факторов собственные значения оказываются больше единицы, а значит, выполнение команды с параметрами по умолчанию позволяет радикально сократить числофакторов. Существуют и другие критерии выделения факторов (например, критерий «каменистой осыпи» Р. Кеттелла); кроме того, вы можете выбирать факторы, основываясь на известных вам особенностях конкретного файла данных. В любом случае, окончательное решение о числе факторов обычно принимается после интерпретации факторов, следовательно, факторный анализ предполагает неоднократное выделение различного числа факторов. В разделе пошаговых процедур рассмотрены несколько вариантов выполнения факторного анализа, отличные от принятого по умолчанию.
Следующим шагом после выделения факторов является их вращение. Вращение требуется потому, что изначально структура факторов, будучи математически корректной, как правило, трудна для интерпретации. Целью вращения является получение простой структуры, которой соответствует большое значение нагрузки каждой переменной только по одному фактору и малое по всем остальным факторам. Нагрузка отражает связь между переменной и фактором, являясь подобием коэффициента корреляции. Значение нагрузки лежит в пределах от –1 до 1. Идеальная простая структура предполагает, что каждая переменная имеет нулевые значения нагрузок для всех факторов, кроме одного, для которого нагрузка этой переменной близка к 1 (–1). До вращения (слева) точки, соответствующие переменным, расположены на удалении от осей факторов. После поворота осей (справа) переменные оказываются вблизи осей, что соответствует максимальной нагрузке каждой переменной только по одному фактору. На практике строгая ориентация переменных вдоль осей факторов обычно не достигается, однако операция поворота позволяет приблизиться к желательному результату.

10.4. Интерпретация факторов
Итак, пусть в некоторой ситуации (близкой к идеальной) путем вращения мы добились того, что значение нагрузки для рассматриваемого фактора является большим (более 0,5), а для остальных факторов — малым (менее 0,2); кроме того, мы четко представляем смысл нашего фактора, то есть то, что он измеряет. Разумеется, в большинстве исследований переменные могут взаимодействовать с «ненужным» фактором, а нередко таких факторов может быть несколько. Как правило, исследователь не ограничивается только числовыми результатами факторного анализа; необходимым условием успеха факторного анализа является понимание содержательной специфики конкретных данных и взаимосвязей между ними.
Для факторного анализа мы будем использовать данные реального тестирования интеллекта 46 школьников. Тест включал в себя 11 субтестов (переменные и1, и2, …, и11). Предпо лагалось, что эти 11 субтестов позволят измерить 3 и более обобщенные интеллектуальные характеристики: математические, вербальные и невербальные (образные). Факторный анализ должен был установить соотношение субтестов и факторов.
Число объектов (N) равно 46.
Простейший вариант факторного анализа, в котором используются значения по умолчанию для всех параметров:

Output


Что произошло:
- Вычисление корреляционной матрицы для 11 заданных переменных.
- Извлечение 11 факторов методом главных компонентов.
- Выбор для вращения всех факторов, чьи собственные значения не меньше 1.
- Вращение факторов по методу Варимакс.
- Вывод матрицы факторных нагрузок после вращения и других результатов.
Вывод: фвыывфыв
Второй вариант, напротив, включает многие из действий, упомянутых ранее в этой главе:
Теперь зададим некоторые дополнительные параметры. Включим в вывод одномерные описательные статистики всех переменных, коэффициенты корреляции, а также применим критерии многомерной нормальности и адекватности выборки. Для извлечения факторов будет использоваться метод главных компонентов, а для отображения — график собственных значений. Вращение факторов будет производиться методом Варимакс. Наконец, отсортируем переменные по величине их нагрузок по факторам и отобразим те нагрузки, абсолютная величина которых не менее 0.3.




Output

Величина КМО демонстрирует приемлемую адекватность выборки для факторного анализа. Критерий сферичности Бартлетта показывает статистически достоверный результат ( p < 0,05): данные вполне приемлемы для факторного анализа.

В первой из двух таблиц перечислены имена переменных и общности. Столбцы второй таблицы содержат характеристики выделенных факторов: их порядковые номера (с 1 по 3), суммы квадратов нагрузок, процент общей дисперсии, обусловленной фактором, и соответствующий кумулятивный (накопленный) процент (до и после вращения).
Чем больше процент дисперсии, обусловленной фактором, тем больший вес имеет данный фактор. А чем больше кумулятивный процент, накопленный к последнему фактору, тем более состоятельным является факторное решение. Если этот накопленный процент менее 50 %, следует либо сократить количество переменных, либо увеличить количество факторов. В данном случае накопленный процент дисперсии вполне приемлем.
Диаграмма называется графиком собственных значений, или диаграммой каменистой осыпи.

Точками показаны соответствующие собственные значения в пространстве двух координат. Этот тип диаграммы обычно используется при определении достаточного числа факторов перед вращением. При этом руководствуются следующим правилом: оставлять нужно лишь те факторы, которым соответствуют первые точки на графике до того, как кривая станет более пологой. В данном примере число таких факторов равно 3, а в соответствие с упомянутым правилом нужно было бы взять не три, а четыре фактора.

Преобразованная матрица факторных нагрузок после вращения. Именно эта матрица является главным итогом факторного анализа и подлежит содержательной интерпретации.
Первый из факторов соответствует предполагаемым математическим способностям, так как объединяет субтесты «счет в уме», «аналогии», «числовые ряды» и «умозаключения». Во второй фактор попали три субтеста, относящиеся к вербальным способностям: «заучивание слов», «осведомленность», «пропущенные слова», а в третий фактор — три субтеста, относящиеся к невербальным способностям: «скрытые фигуры», «геометрическое сложение», «исключение изображений». К «странностям» результатов можно отнести разве что распределение переменной «исключение изображений» между вторым и третьим фактором и попадание переменной «понятливость» в третий фактор. Подобные отклонения обычно требуют отдельного изучения. В частности, можно увеличить число факторов или исключить «неопределенные» переменные и повторить анализ. Целью приведенного примера было показать, каким образом факторный анализ группирует переменные, объединяя их по факторам. Каждый фактор интерпретируется как причина совместной изменчивости (корреляции) группы переменных. После получения приемлемого решения можно вычислить факторные оценки для объектов как новые переменные для дальнейшего анализа.
Критериям KMO и Барлетта: КМО (мера выборочной адекватности Кайзера–Мейера–Олкина) — величина, характеризующая степень применимости факторного анализа к данной выборке:
- более 0.9 — безусловная адекватность;
- более 0.8 — высокая адекватность;
- более 0.7 — приемлемая адекватность;
- более 0.6 — удовлетворительная адекватность;
- более 0.5 — низкая адекватность;
- менее 0.5 — факторный анализ неприменим к выборке.
- Критерий сферичности Барлетта — критерий многомерной нормальности для распределения переменных. С его помощью проверяют, отличаются ли корреляции от 0. Значение p-уровня, меньшее 0.05, указывает на то, что данные вполне приемлемы для проведения факторного анализа.
Матрица повернутых компонент — матрица факторных нагрузок после вращения, основной результат факторного анализа для содержательной интерпретации.
11. Кластерный анализ
Программа SPSS реализует три метода кластерного анализа: Двухэтапный кластерный анализ (TwoStep), Кластеризация К-средними (K-means) и Иерархическая кластеризация (Hierarchical).
- Двухэтапный кластерный анализ позволяет выявить группы (кластеры) объектов по заданным переменным, если эти группы действительно существуют. При этом программа автоматически определяет количество существующих кластеров.
- Кластеризация К-средними разбивает по заданным переменным все множество объектов на заданное пользователем число кластеров так, чтобы средние значения для кластеров по каждой из переменных максимально различались.
- Иерархическая кластеризация, как наиболее гибкий из рассматриваемых методов, позволяет детально исследовать структуру различий между объектами и выбрать наиболее оптимальное число кластеров.
11.1. Сравнение кластерного и факторного анализов
Главное сходство между кластерным и факторным анализами заключается в том, что тот и другой предназначены для перехода от исходной совокупности множества переменных (или объектов) к существенно меньшему числу факторов (кластеров).
-
Целью факторного анализа является замена большого числа исходных переменных меньшим числом факторов. Кластерный анализ, как правило, применяется для того, чтобы уменьшить число объектов путем их группировки.
-
В факторном анализе на каждом этапе извлечения фактора для каждой переменной подсчитывается доля дисперсии, которая обусловлена влиянием данного фактора. При кластерном анализе вычисляется расстояние между текущим объектом и всеми остальными объектами, и кластер образует та пара, для которой расстояние оказалось наименьшим. Подобным образом каждый объект группируется либо с другим объектом, либо включается в состав существующего кластера. Процесс кластеризации конечен и продолжается до тех пор, пока все объекты не будут объединены в один кластер.
11.2. Этапы кластерного анализа
Для демонстрации кластерного анализа будем кластеризовать данные о 15 подержанных автомобилях
Этапы:
-
Выбор переменных-критериев для кластеризации. В данном случае, это будут:
цена,т_сост(экспертная оценка технического состояния по 10-балльной шкале),возраст(количество лет эксплуатации),пробег(пройденный километраж с начала эксплуатации). -
Выбор способа измерения расстояния между объектами, или кластерами (изначально считается, что каждый объект соответствует одному кластеру). По умолчанию используется квадрат Евклидова расстояния. Предположим, что марка автомобиля A имеет показатели технического состояния и возраста 5 и 6, а марка B — соответственно 7 и 4. Тогда по этим двум переменным (координатам) расстояние между марками А и В вычисляется следующим образом: ({(5 – 7)}^{2} + {(6 – 4)}^{2} = 8). Помимо Евклидова существуют и другие виды расстояний, вычисляемые по другим формулам. Относительно вычисления расстояния может возникнуть следующий вопрос: будет ли адекватным результат кластерного анализа в том случае, если переменные имеют различные шкалы измерения? Так, все переменные файла cars. sav имеют самые разные шкалы. Для решения проблемы шкалирования в SPSS используется стандартизация, в частности ее простой метод — нормализация переменных, приводящая все переменные к стандартной z-шкале (среднее равно 0, стандартное отклонение — 1). При нормализации всех переменных при проведении кластерного их веса становятся одинаковыми. В случае если все исходные данные имеют одну и ту же шкалу измерения либо веса переменных по смыслу должны быть разными, стандартизацию переменных проводить не нужно.
-
Формирование кластеров. Существует два основных метода формирования кластеров: метод слияния и метод дробления. В первом случае исходные кластеры увеличиваются путем объединения до тех пор, пока не будет сформирован единственный кластер, содержащий все данные. Метод дробления основан на обратной операции: сначала все данные объединяются в один кластер, который затем делится на части до тех пор, пока не будет достигнут желаемый результат.
-
Интерпретация результатов. Как и в случае факторного анализа, желаемое число кластеров и оценка результатов анализа зависят от целей исследователя. Для рассматриваемого примера нам представляется наиболее предпочтительным число кластеров, равное 3. Как показывает анализ, все марки можно разделить на 3 группы: первая группа имеет высокую стоимость (среднее значение — 15 230), небольшой срок эксплуатации (4 года) и средний пробег (85 400 км). Вторая группа имеет среднюю стоимость, небольшой пробег, наибольший воз- раст, но хорошее техническое состояние. Третья группа содержит недорогие модели с большим пробегом и невысоким рейтингом технического состояния.
Анализ выберите команду Классификация -> Иерархическая кластеризация.
Если вместо переключателя Наблюдения в группе Кластеризовать установить переключатель Переменные, в списке Переменные потребуется указать кластеризуемые переменные, а поле Метить значениями останется пустым.
Процедура стандартизации выбирается в раскрывающемся списке Стандартизация. По умолчанию выбран пункт Нет, однако в случаях, когда переменные представлены в разных шкалах (единицах измерения) стандартизация необходима, и чаще всего выбирают пункт z-значения.
Последняя из четырех функциональных кнопок окна Иерархический кластерный анализ — кнопка Сохранить. С помощью этого окна можно создавать новые переменные, значения которых будут указывать принадлежность наблюдений кластерам.
Пример 1: Класетризуем авто. В кластеризации участвуют объекты.


Output


Вывод:
В таблице Шаги агломерации вторая колонка Кластер объединен с содержит первый (Кластер 1) и второй (Кластер 2) столбцы, которые соответствуют номерам кластеров, объединяемых на данном шаге. После объединения кластеру присваивается номер, соответствующий номеру в колонке Кластер 1. Так, на первом шаге объединяются объекты 5 и 14, и кластеру присваивается номер 5, далее этот кластер на шаге 3 объединяется с элементом 4, и новому кластеру присваивается номер 4 и т. д. Следующая колонка Коэффициент содержит значение расстояния между кластерами, которые объединяются на данном шаге. Колонка Этап первого появления кластера показывает, на каком шаге до этого появлялся первый и второй из объединяемых кластеров. Последняя колонка Следующий этап показывает, на каком шаге снова появится кластер, образованный на этом шаге.
Выбор числа кластеров. По таблице шагов агломерации можно предварительно оценить число кластеров. Для этого необходимо проследить динамику увеличения расстояний по шагам кластеризации и определить шаг, на котором отмечается резкое возрастание расстояний. Оптимальному числу классов соответствует разность между числом объектов и порядковым номером шага, на котором было обнаружено резкое возрастание расстояний. Так, в нашем примере это обнаруживается при переходе от шага 12 к шагу 13. Следовательно, наиболее оптимальное количество кластеров должно быть получено на шаге 12 или 13. Оно равно численности объектов минус номер шага, то есть (15 – 12 = 3) или (15 – 13 = 2), то есть 3 или 2 кластера.
Дендрограмма показывает, что в результате кластеризации переменные группируются в три кластера, состав которых идентичен факторам, полученным в отношении тех же данных при факторном анализе.
Пример 2: testIQ, содержащий 11 переменных. В кластеризации участвуют переменные.
Нас интересуют взаимосвязи между переменными, и мы хотим сравнить результаты с факторным анализом, в качестве меры близости целесообразно выбрать корреляцию.

Output

12. Дискриминантный анализ
Дискриминантный анализ позволяет предсказать принадлежность объектов к двум или более непересекающимся группам. Исходными данными для дискриминантного анализа является множество объектов, разделенных на группы так, что каждый объект может быть отнесен только к одной группе. Допускается при этом, что некоторые объекты не относятся ни к какой группе (являются «неизвестными»).
Для каждого из объектов имеются данные по ряду количественных переменных. Такие переменные называются дискриминантными переменными, или предикторами.
Задачами дискриминантного анализа является определение:
- решающих правил, позволяющих по значениям дискриминантных переменных (предикторов) отнести каждый объект (в том числе и «неизвестный») к одной из известных групп;
- «веса» каждой дискриминантной переменной для разделения объектов на группы.
Существует множество ситуаций, в которых было бы весьма желательно вычислить вероятность того или иного исхода в зависимости от совокупности измеряемых переменных: например, подходит ли соискатель работы на ту или иную должность, страдает психически больной человек шизофренией или психозом, вернется заключенный в тюрьму или к нормальной жизни после выхода на свободу, ка- кие факторы влияют на увеличение риска пациента получить сердечный приступ и т. п. Во всех перечисленных ситуациях есть две общие черты: во-первых, для некоторых субъектов (не для всех) есть информация об их принадлежности к той или иной группе; во-вторых, о каждом субъекте имеется дополнительная информация для создания формулы, которая позволит спрогнозировать принадлежность субъекта к той или иной группе.
Дискриминантный анализ имеет определенное сходство с кластерным анализом; сходство заключается в том, что исследователь в обоих случаях ставит перед собой цель разделить совокупность объектов (а не переменных) на несколько более мелких (значимых) групп. Тем не менее процесс классификации в двух видах анализа принципиально различен. В кластерном анализе объекты классифицируются на основе их различий без какой-либо предварительной информации о количестве и составе классов. В дискриминантном анализе изначально заданы количество и состав классов, и основная задача заключается в определении того, насколько точно можно предсказать принадлежность объектов к классам при помощи данного набора дискриминантных переменных (предикторов).
Дискриминантный анализ представляет собой альтернативу множественного регрессионного анализа для случая, когда зависимая переменная представляет собой не количественную, а номинальную переменную. При этом дискриминантный анализ решает, по сути, те же задачи, что и множественный регрессионный анализ: предсказание значений «зависимой» перемененной (в данном случае — категорий номинального признака) и определение того, какие «независимые» переменные лучше всего подходят для такого предсказания. Дискриминантный анализ основан на составлении уравнения регрессии, использующего номинальную зависимую переменную (обратите внимание на то, что она не является количественной, как в случае регрессионного анализа). Уравнение регрессии составляется на основе тех объектов, о которых известна групповая принадлежность, что позволяет максимально точно подобрать его коэффициенты. После того как уравнение регрессии получено, его можно использовать для группировки интересующих нас объектов в целях прогнозирования их принадлежности к какому-либо классу.
Как и для большинства сложных статистических операций, параметры дискриминантного анализа в основном определяются особенностями данных, а также задачами исследователя. Как всегда, мы рассмотрим пример (на этот раз единственный) проведения дискриминантного анализа в разделе пошаговых процедур, а раздел «Представление результатов» посвятим интерпретации выводимых данных.
Для демонстрации дискриминантного анализа мы рассмотрим пример прогнозирования успешности обучения на основе предварительного тестирования. Файл class.sav содержит данные о 46 учащихся (объекты с 1 по 46), юношей и девушек (переменная пол), закончивших курс обучения, в отношении которых известны оценки успешности обучения — для этого используется переменная оценка (1 — низкая, 2 — высокая). Кроме того, в файл включены данные предварительного тестирования этих учащихся до начала обучения (13 переменных):
и1, ..., и11— 11 показателей теста интеллекта;э_и— показатель экстраверсии по тесту Г. Айзенка (H. Eysenck);н— показатель нейротизма по тесту Г. Айзенка.
Еще для 10 претендентов на курс обучения (объекты с 47 по 56) известны лишь результаты их предварительного тестирования (13 перечисленных переменных). Значения переменной оценка для них, разумеется, неизвестны, и в файле данных им соответствуют пустые ячейки. В процессе дискриминантного анализа мы, в частности, попытаемся спрогнозировать успешность обучения этих 10 претендентов в предположении, что выборки закончивших обучение и претендентов идентичны.
Этапы дискриминантного анализа
-
Выбор переменных-предикторов. Необходимо составить список переменных, которые могут повлиять на результат группировки (переменную-критерий). В рассматриваемом файле помимо переменной-критерия (оценка) содержится 13 переменных, характеризующих каждого учащегося; это позволяет нам сделать все 13 переменных предикторами и включить их в уравнение регрессии. Если бы число переменных было велико (например, несколько сотен), было бы невозможно применить дискриминантный анализ ко всем переменным одновременно. Обычно на начальном этапе дискриминантного анализа для предикторов формируется корреляционная матрица. В данном контексте она имеет особый смысл, называется общей внутригрупповой корреляционной матрицей и содержит средние коэффициенты корреляции для двух или более корреляционных матриц (каждая для одной группы). Помимо общей внутригрупповой корреляционной матрицы можно также вычислить ковариационные матрицы для отдельных групп, для всей выборки либо общую внутригрупповую ковариационную матрицу. Нередко исследователи применяют серию t-критериев между двумя группами для каждой переменной либо однофакторный дисперсионный анализ, если число групп оказывается больше двух. Поскольку целью дискриминантного анализа является составление наилучшего уравнения регрессии, дополнительный анализ исходных данных никогда не является лишним. Так, в результате применения t-критериев для данных нашего примера были найдены значимые различия между двумя уровнями переменной оценка для 8 из 13 предикторов. Мы рассмотрим один из наиболее распространенных вариантов дискриминантного анализа, при проведении которого программа автоматически исключает несущественные для предсказания предикторы, но по критериям, которые устанавливает сам исследователь.
-
Выбор параметров. По умолчанию программа реализует метод, который основан на принудительном включении в регрессионное уравнение всех предикторов, указанных исследователем. В другом варианте используется метод Уилкса (Wilks), относящийся к категории пошаговых методов и основанный на минимизации коэффициента Уилкса ((lambda)) после включения в уравнение регрессии каждого нового предиктора. Так же как и в случае множественного регрессионного анализа, существует критерий для включения предикторов в уравнение регрессии (по умолчанию таким критерием является (F > 3.84)) и критерий для исключения предикторов из уравнения регрессии (по умолчанию (F < 2.71)). Коэффициент (lambda) представляет собой отношение внутригрупповой суммы квадратов к общей сумме квадратов и характеризует долю влияния предиктора на дисперсию критерия. Со значением (lambda) связаны величины (F) и (p), характеризующие его значимость. Более полное описание вы можете найти в разделе «Представление результатов».
-
Интерпретация результатов. Целью дискриминантного анализа является составление уравнения регрессии с использованием выборки, для которой известны значения и предикторов, и критерия. Это уравнение позволяет по известным значениям предикторов определить неизвестные значения критерия для другой выборки. Разумеется, точность рассчитываемых значений критерия для второй выборки в общем случае не выше, чем для исходной. Так, в нашем примере регрессионное уравнение обеспечило около 90 % корректных результатов для той выборки, с помощью которой оно было создано. Соответственно, точность предсказания успешности обучения для 10 претендентов может достигать 90 % лишь в том случае, если выборка претендентов совершенно идентична тем 46 учащимся, данные для которых послужили основой для прогноза.
Пример: дискриминантный анализ для зависимой переменной оценка, имеющей два уровня, и 13 предикторов. Предикторы добавляются в дискриминантное уравнение пошаговым методом (Уилкса) с установками, отличающимися от предлагаемых по умолчанию: для включения предикторов в уравнение (F = 1.125), а для исключения — значение (F = 1). Для анализа зависимости между предикторами вычисляются все описательные статистики. Кроме того, мы включаем в окно вывода нестандартные коэффициенты дискриминантного уравнения, результаты для каждого объекта и итоговую таблицу.
Кнопка Сохранить позволяет сохранять в качестве новых переменных следующие величины для каждого объекта (в том числе, «неизвестного»):
- прогнозируемый номер группы;
- оценки дискриминантных функций;
- вероятность принадлежности к каждой группе.
Поскольку переменная оценка, используемая в нашем примере как зависимая, имеет лишь два уровня (1 и 2), их следует указать в полях Минимум и Максимум. Если число уровней группирующей переменной больше двух, описанная операция позволит задать любой диапазон уровней.




Output
Таблица Критерии равенства групповых средних. Наиболее важная для исследователя информация относится к величинам F-критерия и уровням значимости, поскольку именно по ним можно судить, для каких переменных различие двух групп является значимым.

Таблица Введенные/исключенные переменные иллюстрирует пошаговый процесс составления дискриминантного уравнения. В него поочередно вводятся предикторы на основе заданного критерия включения (по умолчанию критерием является F ≥ 3,84, в нашем случае — F ≥ 1,25), а также исключаются из уравнения те предикторы, которые удовлетворяют критерию исключения (по умолчанию таким критерием является F ≤ 2,71, в нашем случае — F ≤ 1).

В таблицах Собственные значения и Лямбда Уилкса в графе Функция значение 1 говорит о том, что в процессе дискриминантного анализа была получена одна дискриминантная функция. Если бы зависимая переменная имела не 2, а 3 уровня, то было бы составлено две дискриминантные функции. Чем больше значение Хи-квадрат (chi^{2}), тем сильнее дискриминантная функция различает группы и тем лучше она соответствует своему назначению. О ее состоятельности свидетельствует статистическая значимость Знч., заметно меньшая 0.05.

Таблица Коэффициенты канонической дискриминантной функции — список нестандартизованных коэффициентов и константа дискриминантного уравнения. Это уравнение подобно линейному уравнению множественной регрессии и применяется для предсказания. Значение функции для каждого объекта подсчитывается по этому уравнению.

Таблица Нормированных коэффициентов канонической дискриминантной функции. Эти коэффициенты служат для определения относительного вклада каждой переменной в значение дискриминантной функции, с учетом влияния остальных переменных. Чем больше абсолютное значение коэффициента, тем больше относительный вклад данной переменной в значение дискриминантной фунциии, разделяющей классы.

Таблица Поточечные статистики содержит информацию о фактической и прогнозируемой группах для каждого объекта, вероятности его принадлежности к группе, а также значения (баллы) дискриминантной функции. Для объектов, отмеченных двумя звездочками (**), фактическая и прогнозируемая группы не совпали. Всего таких объектов 5 из 46. В отношении последних 10 объектов, для которых принадлежность к группе не была известна, в таблице представлены результаты предсказания, полученные при помощи уравнения дискриминантной функции.


Таблица Результаты классификации показывает, при данном наборе дискриминантных переменных точность классификации составляет 89,13% (41 из 46 правильных предсказаний в отношении «известных» объектов).

13. Многомерное шкалирование (332)
Основное достоинство многомерного шкалирования — представление больших массивов данных о различии объектов в наглядном, доступном для интерпретации графическом виде. При многомерном шкалировании матрица различий между объектами (вычисленными, например, по их экспертным оценкам) представляется в виде одно-, двух- или трехмерного графического изображения взаимного расположения этих объектов.
Основным преимуществом многомерного шкалирования является возможность очень наглядного визуального сравнения объектов анализа. Если две точки на изображении удалены друг от друга, то между соответствующими объектами имеется значительное расхождение; и наоборот, близость точек говорит о сходстве объектов.
Рассмотрим наиболее известную процедуру многомерного шкалирования ALSCAL.
Представим себе, что преподаватель решил создать идеальную психологическую обстановку в группе во время занятия, рассадив учащихся так, чтобы ни один из них не оказался рядом с тем, кто ему не нравится. Для этого каждому из 12 студентов было предложено оценить степень своей симпатии к своим однокурсникам по пятибалльной шкале (от 1 до 5, где 1 — максимум симпатии, а 5 — максимум антипатии). Результаты этого вымышленного опроса мы поместили в файл данных mds1.sav. Чтобы добиться желаемого результата, преподавателю необходимо максимально далеко рассадить негативно настроенных в отношении друг друга учащихся. Здесь весьма полезной окажется диаграмма, на которой удаленность точек будет соответствовать отношениям между учащимися. Для построения диаграммы мы воспользуемся средствами многомерного шкалирования.
Первое, что необходимо сделать для решения задачи, — создать квадратную (12 × 12) матрицу различий. Позже на основе этой матрицы будет построено двумерное изображение, иллюстрирующее взаимоотношения студентов. В ходе многомерного шкалирования исходная матрица 12 × 12 преобразуется в гораздо более простую матрицу 12 × 2 (где 2 — количество измерений или шкал), содержащую координаты точек для изображения. Исходную матрицу называют квадратной асимметричной матрицей различий. Поясним, что означают составляющие это определение термины.
- Квадратная матрица — это матрица, строки и столбцы которой представляют один и тот же набор объектов. В данном случае этим набором объектов является группа учащихся.
- Асимметричная матрица — это матрица, для которой отношение двух объектов друг к другу может быть разным. Так, например, симпатия Петра к Ирине не означает, что Ирине Петр тоже симпатичен. Визуально асимметричность матрицы выражается в том, что как минимум для одной пары ячеек, симметрично расположенных относительно главной диагонали матрицы, значения различны.
- Матрица различий — матрица, данные которой представляют меру различия. В данном случае значения матрицы отражают степень отличия отношения одного студента к другому от идеального; чем больше значение, тем больше различие.
Пример 1: Обработаем гипотетическую социограмму для группы учащихся, при этом количественные оценки их взаимоотношений будут преобразованы в соответствующее графическое изображение.
Данные имеют вид




Output

Значения, записанные в столбце S-stress, характеризуют отклонение результата от идеального (точно соответствующего матрице отличий) на различных итерациях применения модели. SPSS применяет заданную модель столько раз, сколько необходимо для получения достаточно низкого значения в столбце S-stress. Если число итераций оказывается больше 30, то это, как правило, указывает на проблемы в исходных данных.
Стрессы и квадраты коэффициентов корреляции
Для каждой строки асимметричной матрицы различий, для каждой матрицы мо- дели индивидуальных различий, а также для всей модели при многомерном шка- лировании вычисляются стресс и коэффициент (R^{2}). Стресс по своему смыслу схож со стрессом предыдущей модели, однако для его расчета используется другое уравнение, позволяющее упростить вычислительный процесс сравнения различий. Коэффициент (R^{2}) (столбец RSQ) характеризует долю дисперсии в матрице различий, обусловленную данной моделью. Чем лучше модель, тем выше значение коэффициента (R^{2}).

Координаты стимулов
Для каждого шкалируемого объекта указываются его координаты по каждой шкале. Это сделано для того, чтобы вы могли на основе этих координат построить собственное графическое изображение или использовать координаты для дальнейшего анализа. В данном случае столбец 1 соответствует координате x, а столбец 2 — координате y.


Диаграмма представляет собой итог применения модели многомерного шкалирования. Она отображает взаимоотношения 12-ти студентов таким образом, что чем больше различия между учащимися в исходной матрице, тем дальше они находятся друг от друга на диаграмме. На ней видно, что в исследуемой группе выделяются три относительно компактные подгруппы, самая крупная из которых состоит из пяти человек и располагается в правом верхнем углу диаграммы. Отношения внутри каждой из группировок характеризуются симпатией (точки расположены близко), чего не скажешь об отношениях между группами. В данном случае смысл каждой из шкал не имеет значения; главным является взаимное расположение точек.
Пример 2: Рассмотрим результаты тестирования учащихся по пяти показателям и покажем различия между ними графически на плоском изображении.
Данные имеют вид



Output
Пример 3: Небольшое исследование восприятия и понимания студентами пяти многомерных методов статистического анализа. Рассмотрим пример двумерного шкалирования с использованием нескольких квадратных симметричных матриц и модели индивидуальных различий.
Данные имеют вид



14. Логистическая регрессия
Логистическая регрессия представляет собой расширение множественной регрессии и отличается от последней тем, что в качестве зависимой переменной используется дихотомическая переменная, имеющая лишь два возможных значения. Как правило, эти два значения символизируют принадлежность или не принадлежность объекта какой-либо группе, ответ типа «да» или «нет» и т. п.
Логистическая регрессия прогнозирует вероятность некоторого события, находящуюся в пределах от 0 до 1. Кроме того, при помощи индикаторной схемы кодирования допускается использование в качестве предикторов категориальных (номинативных) переменных. Категориальный предиктор может быть представлен серией бинарных переменных — по одной на каждую категорию предиктора. Этим бинарным переменным присваиваются значения 1 или 0 в зависимости от того, к какой категории относится объект.
Будем прогнозировать мнение партнера о том, полезна или нет оказанная ему помощь.
Уравнение логистической регресии (имеет две формы)
[{P}_{help}=frac{1}{1+e^{-B_{0}} times e^{-B_{1} x_{1}} times e^{-B_{2} x_{2} }times e^{-B_{3} x_{3} }}]
[lnleft [ frac{P_{help}}{1-P_{help}} right ]=B_{0}+B_1x_1+B_2x_2+B_3x_3]

Регрессия -> Логистическая
Метод Включение: ОП (ОП — отношение правдоподобия) предполагает пошаговое включение в уравнение предикторов, оказывающих наибольшее воздействие на за- висимую переменную, до последнего предиктора, чье воздействие окажется значимым.
Если в вашем анализе используется категориальные предикторы, то после задания всех предикторов в списке Ковариаты следует воспользоваться кнопкой Категориальные.


Классификационная таблица
В классификационной таблице сравниваются прогнозируемые значения зависимой переменной, рассчитанные по уравнению регрессии, и фактические наблюдаемые значения. Как показывают данные крайнего правого столбца таблицы, для 78.3 % объектов результаты прогноза оказались верными.

Переменные в уравнении
Таблица демонстрирует эффекты включения переменных в уравнение на каждом шаге его построения. Строка Константа для каждого шага соответствует константе (B0) регрессионного уравнения.

Фактическая группировка и прогнозируемые вероятности
В диаграмме используются первые буквы градаций зависимой переменной: е (есть — помощь оказана) и н (нет — помощь не оказана). По горизонтальной оси отложены значения прогнозируемой вероятности, вычисляемые по уравнению регрессии, а по вертикальной оси — частоты. Таким образом, каждый столбик на диаграмме соответствует определенной предсказанной вероятности, а его высота — количеству объектов, для которых предсказана данная вероятность. В случае идеальной логистической регрессии все буквы н окажутся левее букв е, а разделять их будет вероятность 0,5. Как видно из диаграммы, некоторые столбики включают в себя обе буквы, что свидетельствует об ошибках предсказания (высота в два символа соответствует одному объекту). Символам н в правой части диаграммы и символам е в левой части диаграммы соответствуют неправильные предсказания относительно оказания помощи. О количестве правильных и неправильных предсказаний позволяет судить классификационная таблица.

Другие термины при выводе:
- (B) — коэффициенты регрессионного уравнения, отражающие влияние соответ- ствующих предикторов на зависимую переменную. Так, переменная агрессия оказывает положительное влияние на вероятность оказания помощи.
- (Вальд) — критерий значимости Вальда коэффициента (B) для соответствующего предиктора. Чем выше его значение (вместе с числом степеней свободы), тем выше значимость.
- (Exp(B)) — величина ((eB)), которая может использоваться для интерпретации результатов анализа наравне с коэффициентом (B) (вспомните о двух формах регрессионного уравнения, в одной из которых используются коэффициенты (B), а в другой — (eB)).
Тест на равенство двух дисперсий. (Критерий Ливиня)
Дисперсионный
анализ — достаточно большой раздел
статистики. Здесь мы не будем останавливаться
на нем подробно, а лишь в общих чертах
опишем F-критерий, который используется
для проверки гипотезы о равенстве
дисперсий. Он вычисляется по следующей
формуле:

где ![]() —
—
большая выборочная дисперсия, а![]() —
—
меньшая, а![]() рассчитывается
рассчитывается
так:![]() .
.
Проверяемая
(нулевая) гипотеза: сравниваемые
выборочные дисперсии характеризуют
вариацию признака в совокупностях,
взятых из нормально распределенных
генеральных совокупностей с одинаковыми
дисперсиями (![]() ).
).
Для
того чтобы отвергнуть или принять
проверяемую нами гипотезу, мы пользуемся
F-распределением Фишера и соответствующими
таблицами. В этих таблицах указываются
предельные значения F-критерия для
различных комбинаций числа степеней
свободы числителя и знаменателя, которые
могут быть превзойдены с вероятностью
0,05 или 0,01. Число степеней свободы ![]() ,
,
соответствующее большей дисперсии (![]() ),
),
определяет столбец таблицы, число
степеней свободы![]() (
(![]() ),
),
соответствующее дисперсии![]() ,
,
строку таблицы (см. приложение: таблица
№1).
Рассчитанная
по фактическим данным величина
дисперсионного отношения сопоставляется
с соответствующей данному сочетанию
числа степеней свободы числителя и
знаменателя и принятому уровню значимости
табличной величиной дисперсионного
отношения.
Если
фактическое дисперсионное отношение
будет больше табличного, то лишь с
вероятностью 0,05 или 0,01 можно утверждать,
что различие между дисперсиями
определяется случайными факторами.
Иными словами, при фактическом F-критерии
превышающем табличный мы отвергаем
нулевую гипотезу и считаем, что выборочные
дисперсии взяты из генеральных
совокупностей с различными дисперсиями.
Допустим, ![]() а
а![]()
![]() .
.
Тогда![]() ,
,
а![]() при
при
уровне значимости![]() .
.
Значит, мы принимаем нулевую гипотезу
и считаем дисперсии равными, так как![]() .
.
То есть, несмотря на видимое различие
между![]() и
и![]() ,
,
статистически это различие не значимо.
Выбор критерия
На
основе сказанного в пунктах 2 и 3, мы
выбираем критерий для проверки выдвинутой
нами гипотезы. Вернемся опять к нашим
примерам (см. таблицу №1). Для проверки
гипотезы из первого примера мы
воспользуемся t-критерием (каким именно
t-критерием, мы здесь считать не будем),
для проверки гипотезы из третьего
примера мы воспользуемся z-критерием
для независимых выборок, для проверки
гипотезы из второго примера мы
воспользуемся z-критерием для парных
выборок.
Уровень значимости и определение области допустимых значений
Уровень
значимости — вероятность ошибочно
отвергнуть основную проверяемую
гипотезу, когда она верна. В социологии
обычно используется уровень
значимости ![]() ,
,![]() ,
,![]() .
.
Критическую область для любого уровня
значимости можно найти в таблице: если
мы пользуемся z-критерием, то это будет
таблица для стандартизированного
нормального распределения (см. приложение:
таблица №2), если мы пользуемся t-критерием,
то это будет таблица для распределения
Стьюдента (см. приложение: таблица №3).
Приведем более конкретный пример — для
начала поговорим о нормальном
распределении, а потом о распределении
Стьюдента.
Нормальное
распределение.Возьмем
уровень значимости ![]() .
.
На графике критическая область будет
выглядеть следующим образом.

Рисунок
2
Из
рис.2 мы видим, что область допустимых
значений для уровня значимости 0,05 будет
находиться от -1,96 до +1,96. То есть если
значение, полученное по формуле
z-критерия, попадет в промежуток от -1,96
до +1,96, мы принимаем нулевую гипотезу,
если нет — отвергаем. Также мы видим, что
область <ошибочного принятия верной
гипотезы> (хвосты распределения больше
+1,96 и меньше -1,96) разделена на две части.
Это говорит о том, что критерий
двусторонний. Такой критерий обычно
используется, когда мы проверяем
двустороннюю гипотезу. Если же мы имеем
дело с односторонней гипотезой, (![]() )
)
то следует использовать односторонний
критерий. Графически это выглядит
следующим образом:

Рисунок
3
Чтобы
найти значение критической точки для
рис.3 в таблице стандартизированного
нормального распределения, надо
пользоваться уровнем значимости ![]() .
.
Соответственно, если, например, мы хотим
узнать критическую точку для одностороннего
критерия при уровне значимости 0,01, мы
должны искать в таблице критическую
точку для уровня значимости 0,02 (она
будет равна 2,33) и т.д.
Распределение
Стьюдента.
Итак, когда мы применяем t-критерий, то
пользуемся распределением Стьюдента.
Значение критической точки распределения
Стьюдента зависит не только от выбранного
нами уровня значимости, но также, как
было уже отмечено выше, от числа степеней
свободы, обычно обозначаемого df.
Формула, по которой можно определить
число степеней свободы для конкретных
двух независимых выборок выглядит
следующим образом: ![]() где
где![]() и
и![]() объем
объем
первой и второй выборок соответственно.
Допустим
число степеней свободы у нас равно 9.
Тогда для уровня значимости 0,05 графически
критическая область будет выглядеть,
как показано ниже:

Рисунок
4
Из
рис.4 мы видим, что область допустимых
значений для уровня значимости 0,05 в
данном случае будет находиться от -2,26
до +2,26. То есть если значение, полученное
по формуле t-критерия, попадет в промежуток
от -2,26 до +2,26, мы принимаем нулевую
гипотезу, если нет — отвергаем.
Если
мы хотим построить график для одностороннего
уровня значимости, следует действовать
по той же схеме, что и для нормального
распределения.
Итак,
для того, чтобы определить критическую
точку нам надо, прежде всего, задать
уровень значимости или вероятность
отвергнуть нулевую гипотезу, когда она
верна. Если мы отвергаем верную гипотезу,
то совершаем ошибку. Но мы также можем
совершить и другую ошибку: принять
неверную гипотезу. Такого рода ошибки
называются ошибками первого и второго
рода соответственно.
Проверка
любой гипотезы может иметь четыре
исхода, которые обычно представляют в
виде следующей таблицы:
Таблица
№3.
|
Нулевая |
Нулевая |
|
|
Нулевая |
Правильное |
Ошибка |
|
Нулевая |
Ошибка |
Правильное |
Таким
образом, нельзя сказать, что чем меньше
мы возьмем уровень значимости ![]() ,
,
тем более вероятно правильное решение
и тем меньше возможность ошибиться.
Если мы зададим максимально маленький
уровень значимости![]() ,
,
то практически исключим вероятность
ошибки первого рода, но не ошибки второго
рода.
Достаточно
сложно определить вероятность совершения
ошибки второго рода, обозначаемой
греческой буквой ![]() .
.
Вероятность не отвергнуть ложную
гипотезу зависит от многих факторов,
включая следующие:
1.
истинного значения изучаемого параметра,
то есть того, которое мы получили бы,
опросив всю генеральную совокупность;
2.
величины уровня значимости ![]() ;
;
3.
от того, односторонний или двусторонний
у нас критерий;
4.
от дисперсии генеральной совокупности;
5.
от объема нашей выборки.![]()
Очевидно,
что истинного значения изучаемого
параметра мы никогда не знаем (иначе
зачем бы мы проводили исследование) да
и знание дисперсии генеральной
совокупности случай не такой уж частый.
Поэтому ![]() мы
мы
посчитать не можем. Но зато можем
постараться снизить вероятность ошибки
второго рода, зная некоторые ее свойства.
Вероятность
совершить ошибку второго рода будет
уменьшаться:
1.
с увеличением разницы между истинным
и гипотетическим (тем, которое мы
получили) параметрами;
2.
с увеличением уровня значимости ![]() ;
;
3.
с увеличением размера выборки;
4.
с уменьшением стандартного отклонения
от среднего генеральной совокупности.
Соседние файлы в папке 4 курс АФК
- #
- #
- #
- #
- #
- #
- #
- #
- #
В ходе выполнения аналитической обработки маркетинговых данных проведение анализа различий является достаточно часто встречающимся видом анализа. Сюда подходят, например, ситуации, когда проверяется гипотеза разделении всей выборочной совокупности на определенные группы на основании одного или нескольких признаков.
Интересно
Обобщая, можно определить, что целью анализа различий является выявление групп респондентов, статистически значимо различающихся между собой. Респондентов сравнивают на основании средних значений переменных. Проводится сравнение на основании двух или более числовых переменных.
Получаемые первоначальные линейные распределения могут показывать, что исследуемые группы респондентов различаются. Самый простой пример, это наличие в выборке мужчин и женщин, количество которых всегда можно определить. При этом утверждать о наличии статистически значимого различия между группами нельзя. Для его выявления применяется такой вид анализа маркетинговых данных, как «Анализ различий».
Анализ различий между группами выполняется двумя методами. К первому относятся t-тесты, которые достаточно просты, поэтому часто используются, но имеют ограничение на количество тестируемых групп, что ограничивает их применение для решения всех задач при проведении маркетингового анализа.
Ко второму относится дисперсионный анализ, который преодолевает данное ограничение и является универсальной методикой для определения статистически значимых различий между любым числом групп респондентов. Таким образом, если требуется проанализировать три и более категории респондентов, то, следует прибегнуть к использованию дисперсионного анализа, который позволяет одновременно анализировать любое число групп.
Различают одномерный и многомерный дисперсионный анализ. Этот анализ может быть с повторными измерениями и без них. Для одномерного дисперсионного анализа существует только одна зависимая переменная, для многомерного — несколько. В таблице 7 приведены основные характеристики переменных, участвующих в различных видах дисперсионного анализа.
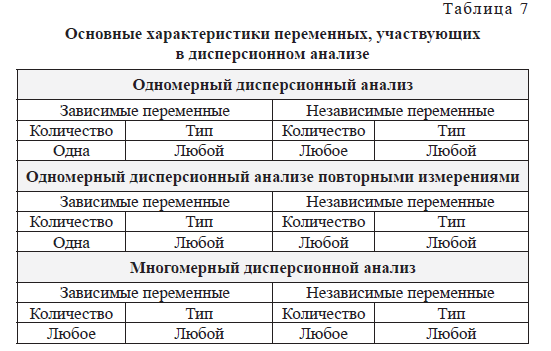
Как было сказано выше, одномерный дисперсионный анализ исследует влияние одной или нескольких независимых переменных на одну зависимую. Одномерный дисперсионный анализ может быть однофакторным или многофакторным. В первом случае есть только одна независимая переменная, во втором — несколько.
Однофакторный одномерный дисперсионный анализ можно проводить двумя способами: при помощи специальной процедуры «Однофакторный дисперсионный анализ»: меню «Анализ» → → «Сравнение средних» → «Однофакторный дисперсионный анализ» или посредством обобщенной линейной модели: меню «Анализ» → «Общая линейная модель» → «ОЛМ-одномерная».
Второй прием является более универсальным и обладает полным объемом функциональности первого, поэтому далее мы рассмотрим только ОЛМ. Необходимо отметить, что для проведения одномерного дисперсионного анализа на практике в маркетинговых исследованиях существует одно весьма существенное ограничение.
При увеличении количества факторов (то есть независимых переменных) в модели сложность интерпретации результатов расчета возра-стает многократно. Так, однофакторный анализ является наиболее простым. Его результаты понятны сразу при взгляде на итоговую таблицу.
Двухфакторный анализ намного сложнее в интерпретации — чтобы понять его результаты, приходится потратить много времени, разбираясь в таблицах и графиках. Для интерпретации результатов трехфакторного анализа необходимо обладать некоторым опытом в его проведении. Четырех- и мультифакторные модели в большинстве своем могут успешно интерпретироваться только квалифицированными специалистами.
Таким образом, для практических целей лучше воздержаться от исследования большого числа взаимодействий между факторами и ограничиться несколькими наиболее важными. Для примера последовательно рассмотрим одно-, двух- и трехфакторные модели одномерного дисперсионного анализа.
При этом будут использоваться следующие исходные данные:
- исследуется покупательское поведение потребителей сметаны;
- респонденты разделяются на целевые группы в зависимости
от предпочтений упаковки сметаны (q3) и жирности сметаны (q7); - дним из вопросов анкеты является вопрос «Какую сметану Вы предпочитаете покупать?» (q3) с вариантами ответа:
- упакованную производителем;
- расфасованную в магазине;
- затрудняюсь ответить.
Требуется выяснить, различается ли кратность покупки сметаны различными целевыми группами респондентов (по предпочтениям упаковки и объема сметаны).
Прежде всего проведем однофакторный одномерный дисперсионный анализ и установим, насколько значимо различается кратность покупок сметаны в зависимости от предпочтений респондентов (выбор по трем вариантам:
- упакованную производителем;
- расфасованную в магазине;
- затрудняюсь ответить).
Диалоговое окно одномерного дисперсионного анализа запускается при помощи меню «Анализ» →«Общая линейная модель»→ → «ОЛМ-одномерная» (рис. 49). Из левого списка всех доступных переменных переместим в поле для зависимой переменной «Зависимая переменная» переменную q3 («Какую сметану Вы предпочитаете покупать?»).
Как видим, в качестве зависимой переменной в дисперсионном анализе выступает основание сегментирования респондентов по группам, то есть та переменная, которая и определяет различия между категориями независимой переменной.
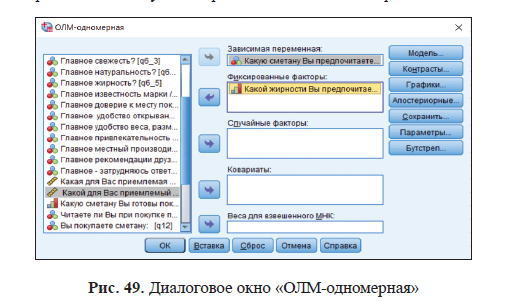
В область для независимых переменных «Фиксированные фак-торы» поместим «Жирность» (q7). Следует обратить внимание на разницу между областями «Фиксированные факторы» (факторы с фиксированными эффектами) и «Случайные факторы» (факторы со случайными эффектами).
Фиксированными факторами называют переменные, уровни которых охватывают все возможные состояния этой переменной. Например, среди предпочтений могут быть опции: упакованную производителем; расфасованную в магазине; затрудняюсь ответить.
Для жирности сметаны соответственно позиции:
- до 10 %;
- от 11 до 15 %;
- от 16 до 20 %;
- от 21 до 25 %;
- от 26 до 30 %;
- более 30 %.
Случайные факторы представляют переменные, уровни которых охватывают лишь часть из всего многообразия возможных состояний. Так как в нашем случае переменная q7 («Жирность») содержит все возможные группы жирности сметаны, то поместим ее в область фиксированных факторов.
Если после этого щелкнем на кнопке «ОК», то получим только одну таблицу, из которой можно узнать лишь о наличии / отсутствии значимых различий между возрастными группами. Однако останется неизвестным, какие именно группы отличаются от других. Для того чтобы определить это, существуют дополнительные статистические тесты, задаваемые при помощи кнопки «Апостериорные». Соответствующее диалоговое окно представлено на рисунке 50.
Перенесем из области «Факторы» в область «Апостериорные» критерии для тех независимых переменных (факторы), которые необходимо подвергнуть тестированию на предмет установления различий между их группами.
В нашем случае есть всего одна факторная переменная q7, которую и следует перенести в область тестирования. Далее укажем релевантные дополнительные тесты для указанной переменной. SPSS выводит различные тесты для равных и неравных дисперсий («Предполагается равенство дисперсий» и «Равенство дисперсий не предполагается» соответственно).
Установить равенство/неравенство дисперсий позволяет тест Ливиня, вывод которого на экран мы покажем ниже. В общем случае мы не знаем, равны ли дисперсии и, соответственно, какую группу статистических тестов следует использовать.
Поэтому рекомендуется сразу вывести тесты для равных и неравных дисперсий, чтобы сократить количество итераций при проведении дисперсионного анализа. SPSS предлагает много различных дополнительных тестов, помогающих определить различия между группами исследуемых переменных.
Однако использовать их все нецелесообразно. Можно ограничиться наиболее популярным и универсальным тестом Шеффе для равных дисперсий и тестом Тамхейна T2 — для неравных дисперсий. Двигаемся далее и закрываем описываемое диалоговое окно щелчком на кнопке «Продолжить».
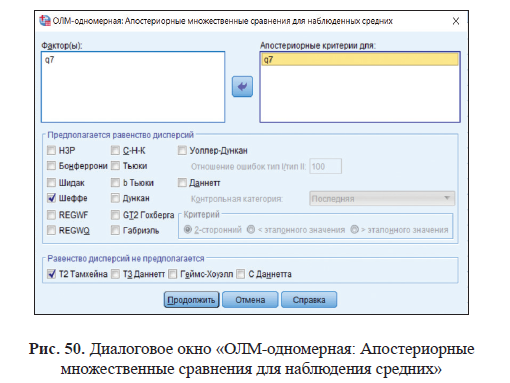
На необходимость проведения теста, позволяющем установить равенство / неравенство дисперсий (так же, как и многих других), можно указать в диалоговом окне «Параметры», вызываемом одно-именной кнопкой в главном диалоговом окне «ОЛМ-одномерная» (см. рис. 51). Для однофакторного дисперсионного анализа можно ограничиться только одним тестом Ливиня на равенство дисперсий (параметр «Критерии однородности»).
Следует отметить, что, если исследуемая независимая переменная имеет всего две категории (дихотомия), апостериорные тесты для нее не проводятся. Установить направление различия между категориями позволяет вывод средних значений зависимой переменной в каждой из двух категорий.
Для этого перенесем исследуемую независимую дихотомическую переменную из области «Факторы и их взаимодействия» в область «Вывести средние для». В данном случае единственная независимая переменная «Жирность» имеет больше двух категорий (6), и поэтому специально выводить для нее средние значения нет смысла (они будут выведены в таблице «Однородные Подмножества»).
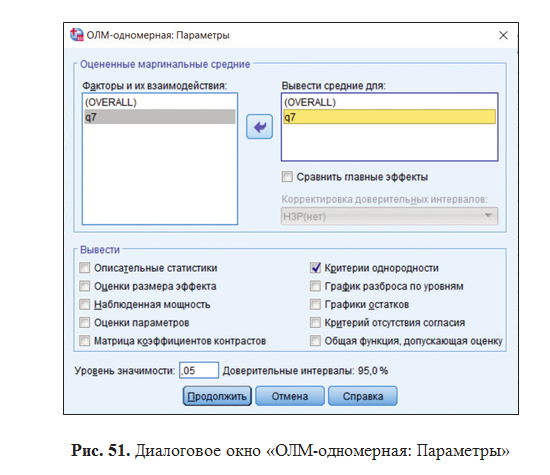
Остальные кнопки главного диалогового окна «ОЛМ-одно-мерная» предназначены для многофакторного анализа, рассматриваемого ниже. Щелкнем на кнопке «ОК», чтобы запустить процедуру дисперсионного анализа. В окне SPSS «Вывод» будут выведены результаты расчетов.
Первой практически значимой таблицей является результат теста на равенство дисперсий зависимой и независимых переменных «Критерий равенства дисперсионных ошибок Ливиня» (рис. 52).
В столбце «Значимость» данной таблицы содержится единственное интересующее нас значение — это статистическая значимость тестовой статистики F. Если значение в данном столбце показывает незначимость F, значит, дисперсии равны, и в дальнейшем следует анализировать результаты расчета теста Шеффе, предполагающего равенство дисперсий.
В противном случае, если F-статистика значима, дисперсии не равны, и при анализе различий между группами следует использовать тест Тамхейна T2, предполагающий неравенство дисперсий.

Как видно по подсчитанному критерию равенства дисперсий ошибок Ливиня (см. рис. 52), статистика F незначима («Значимость» стоит 0,000) и, следовательно, можно сделать вывод о равенстве дисперсий.
Следующее представление — это «Критерии межгрупповых эффектов» (см. рис. 53). Данная таблица является центральной во выводимых результатах дисперсионного анализа и показывает наличие/отсутствие значимых различий между категориями исследуемых переменных.
Первое, на что следует обратить внимание при анализе описываемой таблицы, это величина R2, отражающая долю совокупной дисперсии в зависимой переменной, описываемой статистической моделью. Другими словами, это та часть вариации зависимой переменной, которую можно объяснить на основании независимой переменной. Естественно, что чем меньше независимых переменных, тем меньше величина R2, и наоборот.
Так, в данном случае есть только одна независимая перемен-ная q7 («Жирность»), и при этом R2 составляет 0,064. Для дисперсионного анализа значения R2 можно просто проигнорировать, так как они не важны для практического использования получен-ной модели.
Второе, на что следует обращать внимание исследователю при интерпретации таблицы «Критерии межгрупповых эффектов», это собственно значимость различий между группами независимой переменной. Этот вывод следует из значения на пересечении строки, содержащей соответствующую независимую переменную, и столбца «Значимость».
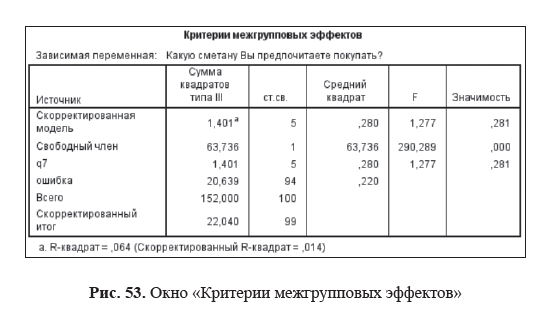
Как видно из рисунка 53, имеет место статистически высоко значимые различие между раз-личными группами в зависимости от предпочтений покупателей и жирностью сметаны (значимость F-статистики у переменной q7 < 0,001).
Обратите внимание, что, если тест Ливиня выявил факт неравенства дисперсий независимых и зависимых переменных, то следует поднять порог значимости со стандартного значения 0,05 до 0,01.
После того как установили наличие статистически значимого различия между группами респондентов в зависимости от их предпочтений и жирности сметаны, необходимо определить, какие из 6 имеющихся групп жирности сметаны отличаются от остальных и каким образом (в большую или в меньшую сторону).
В рассматриваемой ситуации на основании данного теста дисперсии оказались равными, и поэтому в таблице будем рассматривать только ту ее часть, в которой приведены расчеты по методу Шеффе (тест Тамхейна мы бы применили, если бы дисперсии были неравны).
6. Однофакторный дисперсионный анализ
Однофакторный дисперсионный анализ проводится для выявления влияния одной переменной на другую. При этом одна из переменных является независимой и должна быть порядковой или номинальной. А другая —
зависимой и метрической. Данный вид анализа проверяет верность гипотезы, согласно которой средние величины более чем в двух группах равны [1].
С помощью однофакторного дисперсионного анализа можно найти ответы, например, на следующие вопросы:
- Действительно ли различаются предпочтения потребителей к торговой марке в зависимости от их уровня дохода;
- Действительно ли различаются предпочтения потребителей к торговой марке в зависимости от вида рекламного ролика, который они посмотрели;
- Различаются ли группы потребителей по предпочтениям мест приобретения товара;
- Влияет ли уровень образования респондентов на выбор мета отдыха;
- Различаются ли географические сегменты по товарным предпочтениям потребителей.
При однофакторном дисперсионном анализе сравниваются между собой средние значения нескольких групп (выборок), на которые делятся все анализируемые данные. Независимая переменная, при
помощи которой все данные разделяются на группы (категории) называется категориальным фактором (Рисунок 6.1).

Рисунок 6.1 — Диалоговое окно Однофакторного дисперсионного анализа
Последовательность проведения однофакторного дисперсионного анализа:
- Формулировка вопроса в соответствии с требованиями, предъявляемыми к переменным, выбор зависимой и независимой переменных.
- Формулирование исходной (нулевой гипотезы), согласно которой нет связи между выбранными переменными. В результате анализа нулевая гипотеза должна быть подтверждена или опровергнута.
- В ходе проведения анализа проверяются условия равенства дисперсий зависимой переменной в нескольких выбранных группах (категориях).
- Проведение проверки неравенства средних значений зависимой переменной в сравниваемых группах для выявления взаимосвязи между переменными.
- Определение особенностей выявленной взаимосвязи, выявление категорий ее обуславливающих.
Пример. Используя базу данных опроса отдыхающих базы отдыха “Солнечная” проверим, существует ли взаимосвязь между доходом отдыхающих и суммой, которую они готовы
потратить на 1 человека за 1 сутки отдыха за городом.
Предварительно перед проведением однофакторного дисперсионного анализа проведем преобразование данных о среднем доходе респондентов и создадим категориальную переменную “группы по
доходу” с тремя значениями “низкий доход”, “средний доход”, “высокий доход”.
Нулевая гипотеза — туристы с разным уровнем дохода готовы потратить в среднем одинаковую сумму на 1 человека за 1 сутки отдыха за городом. (Не существует связи между доходом
отдыхающих и размером суммы, которую они готовы потратить на отдых за городом)
Пошаговая инструкция
Шаг 1. Анализ — Сравнение средних — Однофакторный дисперсионный анализ
Шаг 2. “Общие расходы на отдых_сумма” в поле “Список зависимых переменных”
Шаг 3. “Группы по доходу” в поле “Фактор”
Шаг 4. Кнопка “Параметры— в открывшемся окне выбрать: Описательные, Проверка однородности дисперсии и График средних (Рисунок 6.2)

Рисунок 6.2 — Диалоговое окно “Описательные статистики”
Шаг 5. Кнопка “Продолжить”
Шаг 6. Кнопка “Апостериорные”: выбрать Шефе и Т2 Тамхейна (Рисунок 6.3)
Шаг 7. Кнопка “Продолжить” и ОК.

Рисунок 6.3 — Апостериорные множественные сравнения
Вверх
Интерпретация результатов
Проверка практической значимости результатов исследования.
На экран компьютера выводится таблица “Описательные статистики”, которая содержит статистические показатели, описывающие распределение зависимой переменной в разных группах. В данном примере
таблица 6.1 содержит зависимую переменную “расходы на отдых” в группах отдыхающих с разным уровнем дохода.

Таблица 6.1 — Описательные статистики: расходы сумма
На данном этапе проверяется практическая значимость сформированных групп. Все группы имеют практическую значимость для исследования, так как количество объектов исследования в каждой
группе больше 2. В случае, если сформируется группа с одним ответом респондента, эта группа должна быть исключена из исследования, так как является практически незначимой.
- Проверка равенства дисперсий по тесту Ливиня.
Проверяется гипотеза “Дисперсии в сравниваемых группах равны”. Значимость 0,333 означает, что гипотеза может быть отклонена с вероятностью ошибки 33%. Следовательно, гипотеза не
отклоняется, и это значит, что дисперсии равны. Если значимость будет меньше 0,05, гипотеза может быть отклонена, то есть дисперсии не равны.Статистика Ливиня Ст. св. 1 Ст. св. 2 Знч. 1,129 2 42 ,333 Таблица 6.2 — Критерий однородности дисперсий: расходы сумма
Критерий однородности дисперсий Ливиня со значимостью 0,333 показал, что дисперсии для каждой из групп статистически достоверно не различаются. Следовательно, результаты анализа
корректны, в качестве апостериорных сравнений (множественных) будем использовать тест Шеффе. - Проверка верности нулевой гипотезы
После проверки равенства дисперсий на экран выводятся результаты однофакторного дисперсионного анализа.Сумма квадратов Ст. св. Средний квадрат F Знч. Между группами 6214056,16 2 3107028,08 27,38 ,000 Внутри групп 4765054,94 42 113453,68 Итого 1,098E7 44 Таблица 6.3 — Однофакторный дисперсионный анализ: расходы сумма
Проверяем верность исходной нулевой гипотезы: туристы с разным уровнем дохода готовы потратить в среднем одинаковую сумму на 1 человека за 1 сутки отдыха за городом. (Не существует
связи между доходом отдыхающих и размером суммы, которую они готовы потратить на отдых за городом).Она может быть отклонена с вероятностью ошибки 0% (значимость 0,000), то есть гипотеза не верна и должна быть отклонена.
Следовательно, можно сделать вывод, что туристы с разным уровнем дохода готовы потратить разные суммы на 1 человека за 1 сутки отдыха за городом (существует зависимость между доходом
отдыхающих и размером суммы, которую они готовы потратить на отдых за городом). - Для того, чтобы получить более точные результаты определим группы, в которых отличия наиболее значительны.
Проводим последующие многовариантные (множественные сравнения). В нашем случае дисперсии равны, поэтому анализируем данные теста Шеффе. В случае неравенства дисперсий значимыми являются
данные теста Т2 Тамхейна.
Пары, характеризующиеся значительной разностью средних, обозначаются звездочкой.
Как видно из таблицы 6.4 разность сумм, которую готовы потратить на отдых туристы, значительна для каждой из групп.
Значимость в каждой группе меньше 0,05, что говорит о достоверности результатов анализа.
Таблица 6.4 — Множественные сравнения. Зависимая переменная: расходы сумма
*. Разность средних значима на уровне 0.05.
Значимость разности сумм, которую туристы с разным уровнем дохода готовы потратить на отдых за городом можно также увидеть на графике (рисунок 6.1).

Рисунок 6.4 — Зависимость средних расходов на отдых и уровнем дохода респондента
В целом можно сделать вывод, что как низкий, так и средний и высокий уровень дохода туриста влияет на размер суммы, которую он готов потратить на 1 человека за 1 день отдыха за городом.
Следовательно, менеджменту базы отдыха “Солнечная” необходимо продумать грамотную политику ценообразования с учетом сегментирования рынка по доходу отдыхающих.