В статистике есть целый набор показателей, которые характеризуют центральную тенденцию. Выбор того или иного индикатора в основном зависит от характера данных, целей расчетов и его свойств.
Что подразумевается под характером данных? Прежде всего, мы говорим о количественных данных, которые выражены в числах. Но набор числовых данных может иметь разное распределение. Под распределением понимаются частоты отдельных значений. К примеру, в классе из 23 человек 2 школьника написали контрольную работу на двойку, 5 – на тройку, 10 – на четверку и 6 – на пятерку. Это и есть распределение оценок. Распределение очень наглядно можно представить с помощью специальной диаграммы – гистограммы. Для данного примера получится следующая гистограмма.

Во многих случаях количество уникальных значений намного больше, а распределение похоже на нормальное. Ниже приведена примерная иллюстрация нормального распределения случайных чисел.

Итак, центральная тенденция. Если частоты анализируемых значений распределены по нормальному закону, то есть симметрично вокруг некоторого центра, то центральная тенденция определяется вполне однозначно – это есть тот самый центр, и математически он соответствует средней арифметической.
Как нетрудно заметить, в этом же центре находится и максимальная частота значений. То есть при нормальном распределении центральная тенденция есть не только средняя арифметическая, но и максимальная частота, которая в статистике называется модой или модальным значением.

На диаграмме оба значения центральной тенденции совпадают и равны 10.
Но такое распределение встречается далеко не всегда, а при малом числе данных – совсем редко. Чаще бывает так, что частоты распределяются асимметрично. Тогда мода и среднее арифметическое не будут совпадать.

На рисунке выше среднее арифметическое по-прежнему составляет 10, а вот мода уже равна 9. Что в таком случае считать значением центральной тенденции? Ответ зависит от поставленных целей анализа. Если интересует уровень, сумма отклонений от которого равна нулю со всеми вытекающим отсюда свойствами и последствиями, то это средняя арифметическая. Если нужно максимально частое значение, то это мода.
Итак, зачем нужна мода? Приведу пару примеров. Экономист планово-экономического отдела обувной фабрики интересуется, какой размер обуви пользуется наибольшим спросом. Средний размер обуви, скорее всего, здесь не подойдет, тем более, что число может получится дробным. А вот мода – как раз нужный показатель.
Расчет моды
Теперь посмотрим, как рассчитать моду. Мода – это то значение в анализируемой совокупности данных, которое встречается чаще других, поэтому нужно посмотреть на частоты значений и отыскать максимальное из них. Например, в наборе данных 3, 4, 6, 7, 3, 5, 3, 4 модой будет значение 3 – повторяется чаще остальных. Это в дискретном ряду, и здесь все просто. Если данных много, то моду легче всего найти с помощью соответствующей гистограммы. Бывает так, что совокупность данных имеет бимодальное распределение.

Без диаграммы очень трудно понять, что в данных не один, а два центра. К примеру, на президентских выборах предпочтения сельских и городских жителей могут отличаться. Поэтому распределение доли отданных голосов за конкретного кандидата может быть «двугорбым». Первый «горб» – выбор городского населения, второй – сельского.
Немного сложнее с интервальными данными, когда вместо конкретных значений имеются интервалы. В этом случае говорят о модальном интервале (при анализе доходов населения, например), то есть интервале, частота которого максимальна относительно других интервалов. Однако и здесь можно отыскать конкретное модальное значение, хотя оно будет условным и примерным, так как нет точных исходных данных. Представим, что есть следующая таблица с распределением цен.

Для наглядности изобразим соответствующую диаграмму.

Требуется найти модальное значение цены.
Вначале нужно определить модальный интервал, который соответствует интервалу с наибольшей частотой. Найти его так же легко, как и моду в дискретном ряду. В нашем примере это третий интервал с ценой от 301 до 400 руб. На графике – самый высокий столбец. Теперь нужно определить конкретное значение цены, которое соответствует максимальному количеству. Точно и по факту сделать это невозможно, так как нет индивидуальных значений частот для каждой цены. Поэтому делается допущение о том, что интервалы выше и ниже модального в зависимости от своей частоты имеют разные вес и как бы перетягивают моду в свою сторону. Если частота интервала следующего за модальным больше, чем частота интервала перед модальным, то мода будет правее середины модального интервала и наоборот. Давайте еще раз посмотрим на рисунок, чтобы понять формулу, которую я напишу чуть ниже.

На рисунке отчетливо видно, что соотношение высоты столбцов, расположенных слева и справа от модального определяет близость моды к левому или правому краю модального интервала. Задача по расчету модального значения состоит в том, чтобы найти точку пересечения линий, соединяющих модальный столбец с соседними (как показано на рисунке пунктирными линиями) и нахождении соответствующего значения признака (в нашем примере цены). Зная основы геометрии (7-й класс), по данному рисунку нетрудно вывести формулу расчета моды в интервальном ряду.
Формула моды имеет следующий вид.
![]()
Где Мо – мода,
x0 – значение начала модального интервала,
h – размер модального интервала,
fМо – частота модального интервала,
fМо-1 – частота интервала, находящего перед модальным,
fМо1 – частота интервала, находящего после модального.
Второе слагаемое формулы моды соответствует длине красной линии на рисунке выше.
Рассчитаем моду для нашего примера.
![]()
Таким образом, мода интервального ряда представляет собой сумму, состоящую из значения начального уровня модального интервала и отрезка, который определяется соотношением частот ближайших интервалов от модального.
Расчет моды в Excel
В настоящее время большинство вычислений делается в MS Excel, где для расчета моды также предусмотрена специальная функция. В Excel 2013 я таких нашел ажно 3 штуки.
МОДА – пережиток старых изданий Excel. Функция оставлена для совмещения со старыми версиями.
МОДА.ОДН – рассчитывает моду по заданным значениям. Здесь все просто. Вставили функцию, указали диапазон данных и «Ок».
МОДА.НСК – позволяет рассчитать сразу несколько модальных значений (одинаковых максимальных частот) для одного ряда данных, если они есть. Функцию нужно вводить как формулу массива, перед этим выделив количество ячеек равное количеству требуемых модальных значений. Иногда действительно модальных значений может быть несколько. Однако для этих целей предварительно лучше посмотреть на диаграмму распределения.
Моду для интервальных данных одной функцией в Excel рассчитать нельзя. То есть такая функция в готовом виде не предусмотрена. Придется прописывать вручную.
Следующая статья посвящена медиане.
До встречи на statanaliz.info.
Поделиться в социальных сетях:
Оценка количества ошибок в программе. Модель Миллса
Время на прочтение
3 мин
Количество просмотров 16K
Сколько ошибок в программе? Это вопрос, который волнует каждого программиста. Особую актуальность придает ему принцип кучкования ошибок, согласно которому нахождение в некотором модуле ошибки увеличивает вероятность того, что в этом модуле есть и другие ошибки. Точного ответа на вопрос о количестве ошибок в программе очень часто дать невозможно, а вот построить некоторую оценку — можно. Для этого существуют несколько статических моделей. Рассмотрим одну из них: Модель Миллса.
В 1972 г. суперпрограммист фирмы IBM Харлан Миллс предложил следущий способ оценки количества ошибок в программе. Пусть у нас есть программа. Предположим, что в ней N ошибок. Назовем их естественными. Внесем в нее дополнительно M искусственных ошибок. Проведём тестирование программы. Пусть в ходе тестирования было обнаружено n естественных ошибок и m искусственных. Предположим, что вероятность обнаружения для естественных и искусственных ошибок одинакова. Тогда выполняется соотношение:

Мы нашли один и тот же процент естественных и искусственных ошибок. Отсюда количество ошибок в программе:

Количество необнаруженных ошибок равно (N-n).
Например, пусть в программу внесено 20 искусственных ошибок, в ходе тестирования было обнаружено 12 искусственных и 7 естественных ошибок. Получим следущую оценку количества ошибок в программе:

Количество необнаруженных ошибок равно (N-n) = 12 — 7 = 5.
Легко заметить, что в описанном выше способе Миллса есть один существенный недостаток. Если мы найдем 100% искусственных ошибок, это будут означать, что и естественных ошибок мы нашли 100%. Но чем меньше мы внесем искусственных ошибок, тем больше вероятность того, что мы найдём их все. Внесем единственную исскуственную ошибку, найдем ее, и на этом основании объявим, что нашли все естесственные ошибки! Для решение такой проблемы Миллс добавил вторую часть модели, предназначенную для проверки гипотезы о величине N:
Предположим, что в программе N естественных ошибок. Внесём в неё M искусственных ошибок. Будем тестировать программу до тех пор, пока не найдем все искусственные ошибки. Пусть к этому моменту найдено n естественных ошибок. На основании этих чисел вычислим величину C:

Величина C выражает меру доверия к модели. Это вероятность того, что модель будет правильно отклонять ложное предположение. Например, пусть мы считаем, что естественных ошибок в программе нет (N=0). Внесем в программу 4 искусственные ошибки. Будем тестировать программу, пока не обнаружим все искусственные ошибки. Пусть при это мы не обнаружим ни одной естественной ошибки. В этом случае мера доверия нашему предположению (об отсутствии ошибок в программе) будет равна 80% (4 / (4+0+1)). Для того чтобы довести ее до 90% количество искусственных ошибок придется поднять до 9. Следущие 5% уверенности в отсутствии естественных ошибок обойдутся нам в 10 дополнительных искусственных ошибок. M придется довести до 19.
Если мы предположим, что в программе не более 3-х естественных ошибок (N=3), внесем в нее 6 искусственных (M=6), найдем все искусственные и одну, две или три (но не больше!) естественных, то мера доверия к модели будет 60% (6 / (6+3+1)).
Значения функции С для различных значений N и M, в процентах:
Таблица 1 — с шагом 1;
Таблица 2 — с шагом 5;
Из формул для вычисления меры доверия легко получить формулу для вычисления количества искусственных ошибок, которые необходимо внести в программу для получения нужной уверенности в полученной оценке:

Количество исскуственных ошибок, которые необходимо внести в программу, для достижения нужной меры доверия, для различных значений N:
Таблица 3 — с шагом 1;
Таблица 4 — с шагом 5;
Модель Миллса достаточно проста. Ее слабое место — предположение о равновероятности нахождения ошибок. Чтобы это предположение оправдалось, процедура внесения искусственных ошибок должна обладать определенной степенью «интеллекта». Ещё одно слабое место — это требование второй части миллсовой модели отыскать непременно
все
искусственные ошибки. А этого может не произойти долго, может быть, и никогда.
План урока:
Понятие выборки и генеральной совокупности
Среднее арифметическое выборки
Упорядоченный ряд и таблица частот
Размах выборки
Мода выборки
Медиана выборки
Ошибки в статистике
Понятие выборки и генеральной совокупности
Слово статистика, образованное от латинского status(состояние дел), появилось только в 1746 году, когда его употребил немец Готфрид Ахенвалль. Однако ещё в Древнем Китае проводились переписи населения, в ходе которых правители собирали информацию о своих владениях и жителях, проживающих в них.
В основе любого статистического исследования лежит массив информации, который называют выборкой данных. Покажем это на примере. Пусть в классе, где учится 20 учеников, проводился тест по математике, содержавший 25 вопросов. В результате учащиеся показали следующие результаты:

Ряд чисел, приведенный во второй строке таблицы (12, 19, 19, 14, 17, 16, 18, 20, 15, 25, 13, 20, 25, 16, 17, 12, 24, 13, 21, 13), будет выборкой. Также ее могут называть рядом данных или выборочной совокупностью.

В примере с классом выборка состоит из 20 чисел. Эту величину (количество чисел в ряду) называют объемом выборки. Каждое отдельное число в ряду именуют вариантой выборки.
В примере со школьным классом в выборку попали все его ученики. Это позволяет точно определить, насколько хорошо учащиеся написали математический тест. Однако иногда необходимо проанализировать очень большие группы населения, состоящие из десятков и даже сотен миллионов человек. Например, необходимо узнать, какая часть населения страны курит. Опросить каждого жителя государства невозможно, поэтому в ходе исследования опрашивают лишь его малую часть. В этом случае статистики выделяют понятие генеральная совокупность.

Так, если с помощью опроса 10 тысяч человек ученые делают выводы о распространении курения в России, то все российское население будет составлять генеральную совокупность исследования, а опрошенные 10 тысяч людей вместе образуют выборку.
Среднее арифметическое выборки
Сбор информации о выборке является лишь первой стадией статистического исследования. Далее ее необходимо обобщить, то есть получить некоторые цифры, характеризующие выборку. Самой часто используемой статистической характеристикой является среднее арифметическое.

Другими словами, для подсчета среднего арифметического необходимо просто сложить все числа в ряде данных, а потом поделить получившееся значение на количество чисел в ряде. Так, в примере с тестом по математике (таблица 1) средний балл учащихся составит: (12+19+19+14+17+16+18+20+15+25+13+20+25+16+17+12+24+13+21+13):20=
= 349:20 = 17,45.
Среднее арифметическое позволяет одним числом характеризовать какое-либо качество всех объектов группы. Чем больше средний балл учащихся в классе, тем выше их успеваемость. Чем меньше среднее количество голов, пропускаемых футбольной командой за один матч, тем лучше она играет в обороне. Если средняя зарплата программистов в городе составляет 90 тысяч рублей, а дворников – 25 тысяч рублей, то это значит, что программисты значительно более востребованы на рынке труда, а потому при выборе будущей профессии лучше предпочесть именно эту специальность.
Упорядоченный ряд и таблица частот
В ряде данных в таблице 1 числа приведены в произвольном порядке. Перепишем ряд так, чтобы все числа шли в неубывающем порядке, то есть от самого маленького к самому большому:
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Такую запись называют упорядоченным рядом данных.

Его характеристики ничем не отличаются от изначальной выборки, однако с ним удобнее работать. С его помощью можно видеть, что ни одному ученику не удалось набрать 22 или 23 балла на тесте, но сразу двое учащихся дали 25 правильных ответов. На основе упорядоченного ряда данных несложно составить таблицу частот, в которой будет указано, как часто та или иная варианта выборки встречается в ряде. Выглядеть она будет так:

При составлении этой таблицы мы исключили из нее те варианты количества набранных баллов, частота которых равна нулю (от 0 до 12, 22 и 23).Заметим, что сумма чисел в нижней строке таблицы частот должна равняться объему выборки. Действительно,
2+3+1+1+2+2+1+2+2+1+1+2 = 20.
С помощью таблицы частот можно быстрее посчитать среднее арифметическое выборки. Для этого каждую варианту надо умножить на ее частоту, после чего сложить полученные результаты и поделить их на объем выборки:
(12•2+13•3+14•1+15•1+16•2+17•2+18•1+19•2+20•2+21•1+24•1+25•2):20 =
(24+39+14+15+32+34+18+38+40+42+24+50):20 = 349:20 = 17,45.
Размах выборки
Следующий важная характеристика ряда данных – это размах выборки.

Если выборка представлена в виде упорядоченного ряда данных, то достаточно вычесть из последнего числа ряда первое число. Так, размах выборки результатов теста в классе равен:
25 – 12 = 13,
так как самые лучшие ученики смогли решить все 25 заданий, а наихудший учащийся ответил правильно только на 13 вопросов.
Размах выборки характеризует стабильность, однородность исследуемых свойств. Например, пусть два спортсмена-стрелка в ходе соревнований производят по 5 выстрелов по круговой мишени, где за попадание начисляют от 0 до 10 очков. Первый стрелок показал результаты 8, 9, 9, 8, 9 очков. Второй же спортсмен в своих попытках показал результаты 7, 10, 10, 6, 10. Средние арифметические этих рядов равны:
(8+9+9+8+9):5 = 43:5 = 8,6;
(7+10+10+6+10):5 = 43:5 = 8,6.
Получается, что в среднем оба стрелка стреляют одинаково точно, однако первый спортсмен демонстрирует более стабильные результаты. У его выборки размах равен
9 – 8 = 1,
в то время как размах выборки второго спортсмена равен
10 – 6 = 4.
Размах выборки может быть очень важен в метеорологии. Например, в Алма-Ате и Амстердаме средняя температура в течение года почти одинакова и составляет 10°С. Однако в Алма-Ате в январе и феврале иногда фиксируются температуры ниже -30°С, в то время как в Амстердаме за всю историю наблюдений она никогда не падала ниже -20°С.
Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны. Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:
6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Медиана выборки
Иногда, например, при расчете средней зарплаты, среднее арифметическое не вполне адекватно отражает ситуацию. Это происходит из-за наличия в выборке чисел, очень сильно отличающихся от среднего. Так, из-за огромных зарплат некоторых начальников большинство рядовых сотрудников компаний обнаруживают, что их зарплата ниже средней. В таких случаях целесообразно использовать такую характеристику, как медиану ряда. Это такое значение, которое делит ряд данных пополам. В упорядоченном ряде 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25 медианой будет равна 12, так как именно она находится в середине ряда:

Однако таким образом можно найти только медиану ряда, в котором находится нечетное количество чисел. Если же их количество четное, то за медиану условно принимают среднее арифметическое двух средних чисел. Так, для ряда 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25, 30, содержащего 12 чисел, медиана будет равна среднему значению 12 и 15, которые занимают 6-ое и 7-ое место в ряду:


Вернемся к примеру с математическим тестом в школе. Так как его сдавали 20 учеников, а 20 – четное число, то для расчета медианы следует найти среднее арифметическое 10-ого и 11-ого числа в упорядоченном ряде
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Эти места занимают числа 17 и 17 (выделены жирным шрифтом). Медиана ряда будет равна
(17+17):2 = 34:2 = 17.
Три приведенные основные статистические характеристики выборки, а именно среднее арифметическое, мода и медиана, называются мерами центральной тенденции. Они позволяют одним числом указать значение, относительно которого группируются все числа ряда.
Рассмотрим для наглядности ещё один пример. Врач в ходе диспансеризации измерил вес мальчиков в классе. В результате он получил 10 значений (в кг):
39, 41, 67, 36, 60, 58, 46, 44, 39, 69.
Найдем среднее арифметическое, размах, моду и медиану для этого ряда.
Решение. Сначала перепишем ряд в упорядоченном виде:
36, 39, 39, 41, 44, 46, 58, 60, 67, 69.
Так как в ряде 10 чисел, то объем выборки равен 10. Найдем среднее арифметическое. Для этого сложим все числа в ряде и поделим их на объем выборки (то есть на 10):
(36+39+39+41+44+46+58+60+67+69):10 =
= 499:10 = 49,9 кг.
Размах выборки равен разнице между наибольшей и наименьшей вариантой в ней. Самый тяжелый мальчик весит 69 кг, а самый легкий – 36 кг, а потому размах ряда равен
69 – 36 = 33 кг.
В упорядоченном ряде только одно число, 39, встречается дважды, а все остальные числа встречаются по одному разу. Поэтому мода ряда будет равна 39 кг.
В выборке 10 чисел, а это четное число. Поэтому для нахождения медианы надо найти два средних по счету значение найти их среднее. На 5-ом и 6-ом месте в ряде находятся числа 44 и 46. Их среднее арифметическое равно
(44+46):2 = 90:2 = 45 кг.
Поэтому и медиана ряда будет равна 45 кг.
Ошибки в статистике
Статистика является очень мощным инструментом для исследований во всех областях человеческой деятельности. Однако иногда ее иронично называют самой точной из лженаук. Известно и ещё одно высказывание, приписываемое политику Дизраэли, согласно которому существует просто ложь, наглая ложь и статистика. С чем же связана такая репутация этой дисциплины?
Дело в том, что некоторые люди и организации часто манипулируют данными статистики, чтобы убедить других в своей правоте или преимуществах товара, которые они продают. Требуются определенные навыки, чтобы правильно пользоваться статистикой. Одна из самых распространенных ошибок – это неправильный выбор выборки.
В 1936 году перед президентскими выборами в США был проведен телефонный опрос, который показал, что с большим преимуществом победу должен одержать Альфред Лендон. Однако на выборах Франклин Рузвельт набрал почти вдвое больше голосов. Ошибка была связана с тем, что в те годы телефон могли позволить себе только богатые люди, которые в большинстве своем поддерживали Лендона. Однако бедные люди (а их, конечно же, больше, чем богатых) голосовали за Рузвельта.
Ещё один пример – это агитация в конце XIX века в США к службе на флоте. Пропагандисты в своей рекламе указывали, что, согласно статистике, смертность на флоте во время войны (испано-американской) составляет 0,09%, в то время как среди населения Нью-Йорка она равнялась 0,16%. Получалось, что служить на флоте в военное время безопаснее, чем жить мирной жизнью. Однако на самом деле причина таких цифр заключается в том, что во флот всегда отбирали молодых мужчин с хорошим здоровьем, которые не могли умереть от «старческих» болезней, в то время как в население Нью-Йорка входят больные и старые люди.
При указании среднего значения исследователь может использовать разные характеристики – среднее арифметическое, медиана, мода. При этом почти всегда среднее арифметическое несколько больше медианы. Именно поэтому большинство людей, узнающих о средней зарплате в стране, удивляются, так как они столько не зарабатывают. Правильнее ориентироваться на медианную зарплату.
Ну и наконец, нельзя забывать, что любая статистика может показать только корреляцию между двумя величинами, но это не всегда означает причинно-следственную связь. Так, известно, что чем больше в городе продается мороженого, тем больше в это же время людей тонет на пляжах. Означает ли это, что поедание мороженого увеличивает риск во время плавания? Нет. Дело в том, что оба этих показателя, продажи мороженого и количество утонувших, зависят от третьей величины – температуры в городе. Чем жарче на улице, тем большее количество людей ходят на пляж и тем больше мороженого продается в магазинах.
Привет, Вы узнаете про статистическая модель миллса -оценка количества ошибок в программном коде , Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
статистическая модель миллса -оценка количества ошибок в программном коде , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
Модель Миллса — способ оценки количества ошибок в программном коде, созданный в 1972 году программистом Харланом Миллсом. Он получил широкое распространение благодаря своей простоте и интуитивной привлекательности .
Методология
Допустим, имеется программный код, в котором присутствует заранее неизвестное количество ошибок (багов) , требующее максимально точной оценки. Для получения этой величины можно внести в программный код
, требующее максимально точной оценки. Для получения этой величины можно внести в программный код  дополнительных ошибок, о наличии которых ничего не известно специалистам по тестированию[3][1].
дополнительных ошибок, о наличии которых ничего не известно специалистам по тестированию[3][1].
Предположим, что после проведения тестирования было обнаружено n естественных ошибок (где n[1][4].
Из которого следует, что оценка полного количества естественных ошибок в коде равна , а количество все еще не выловленных багов кода равно разности
, а количество все еще не выловленных багов кода равно разности  [1][5]. Сам Миллс полагал, что процесс тестирования необходимо сопровождать постоянным обновлением графиков для оценки количества ошибок[6].
[1][5]. Сам Миллс полагал, что процесс тестирования необходимо сопровождать постоянным обновлением графиков для оценки количества ошибок[6].
Очевидно, что такой подход не лишен недостатков. Например, если найдено 100% искусственных ошибок, то значит и естественных ошибок было найдено около 100%. Причем, чем меньше было внесено искусственных ошибок, тем больше вероятность того, что все они будут обнаружены. Из чего следует заведомо абсурдное следствие: если была внесена всего одна ошибка, которая была обнаружена при тестировании, значит ошибок в коде больше нет[6].
В целях количественной оценки доверия модели был введен следующий эмпирический критерий:

Уровень значимости  оценивает вероятность, с которой модель будет правильно отклонять ложное предположение[7][6]. Выражение для было сконструировано Миллсом[7], но в силу своей эмпирической природы при необходимости оно допускает некоторую вариативность в разумных пределах[8].
оценивает вероятность, с которой модель будет правильно отклонять ложное предположение[7][6]. Выражение для было сконструировано Миллсом[7], но в силу своей эмпирической природы при необходимости оно допускает некоторую вариативность в разумных пределах[8].
Исходя из формулы для можно получить оценку количества искусственно вносимых багов для достижения нужной меры доверия . Это количество дается выражением вида  [8].
[8].
Слабостью подхода Миллса является необходимость вести тестирование продукта до обнаружения абсолютно всех искусственно введенных багов, однако существуют обобщения этой модели, где это ограничение снято[7] . Об этом говорит сайт https://intellect.icu . Например, если порог на допустимое количество из обнаруженных внесенных ошибок равен величине  ), то критерий перезаписывается следующим образом:
), то критерий перезаписывается следующим образом:

Статистическая модель Миллса позволяет оценить не только количество ошибок до начала тестирования, но и степень отлаженности программ. Для применения модели до начала тестирования в программу преднамеренно вносят ошибки . Далее считают, что обнаружение преднамеренно внесенных и так называемых собственных ошибок программы равновероятно.
Для оценки количества ошибок в программе до начала тестирования используется выражение
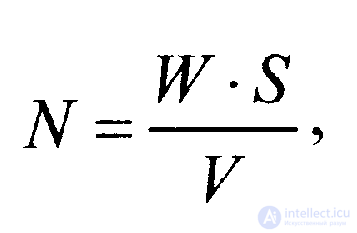 (2.2.1)
(2.2.1)
где W‘ — количество преднамеренно внесенных в программу ошибок до начала тестирования;V— количество обнаруженных в процессе тестирования ошибок из числа преднамеренно внесенных;S— количество «собственных» ошибок программы, обнаруженных в процессе тестирования.
Если продолжать тестирование до тех пор, пока все ошибки из числа преднамеренно внесенных не будут обнаружены, степень отлаженности программы С можно оценить с помощью выражения
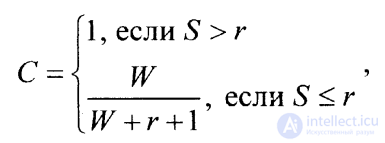 (2.2.2)
(2.2.2)
где SиW=V(равенство значенийWиVв данном случае имеет место, поскольку считается, что все преднамеренно внесенные ошибки обнаружены) имеют тот же смысл, что и в предыдущем выражении (2.2.1), аr означает верхний предел (максимум) предполагаемого количества «собственных» ошибок в программе.
Выражения (2.2.1) и (2.2.2) представляют собой статистическую модель Миллса. Необходимо заметить, что если тестирование будет закончено преждевременно (т. е. раньше, чем будут обнаружены все преднамеренно внесенные ошибки), то вместо выражения (2.2.2) следует использовать более сложное комбинаторное выражение (2.2.3). Если обнаружено только Vошибок изWпреднамеренно внесенных, используется выражение
 !!!(2.2.3)
!!!(2.2.3)
где в круглых скобках записаны обозначения для числа сочетаний из Sэлементов поV— 1 элементов в каждой комбинации и числа сочетаний изS+r+ 1 элементов поr+Vэлементов в каждой комбинации.
2.2.2. Задачи по применению модели Миллса
Задача 1
В программу преднамеренно внесли (посеяли) 10 ошибок. В результате тестирования обнаружено 12 ошибок, из которых 10 ошибок были внесены преднамеренно. Все обнаруженные ошибки исправлены. До начала тестирования предполагалось, что программа содержит не более 4 ошибок. Требуется оценить количество ошибок до начала тестирования и степень отлаженности программы.
Решение задачи
Для оценки количества ошибок до начала тестирования используем формулу (2.2.1).
Нам известно:
• количество внесенных в программу ошибок W= 10;
• количество обнаруженных ошибок из числа внесенных V= 10;
• количество «собственных» ошибок в программе S= 12 — 10 = 2.
Подставив указанные значения в формулу, получим оценку количества ошибок:
N = (W·S) /V= (10 ·2) / 10 = 2.
Таким образом, из результатов тестирования следует, что до начала тестирования в программе имелось 2 ошибки.
Для оценки отлаженности программы используем уравнение (2.2.2). Нам известно:
• количество обнаруженных «собственных» ошибок в программе S=2;
• количество предполагаемых ошибок в программе r= 4;
• количество преднамеренно внесенных и обнаруженных ошибок W= 10.
Очевидно, что обнаружено меньшее число «собственных» ошибок, чем количество предполагаемых ошибок в программе (S<r). Для оценки отлаженности программы используем уравнение
С =W/ (W +r + 1) = 10/ (10 + 4 + 1) = 0,67.
Степень отлаженности программы равна 0,67, что составляет 67%.
Задача 2
В программу было преднамеренно внесено (посеяно) 14 ошибок. Предположим, что в программе перед началом тестирования было 14 ошибок. В процессе четырех тестовых прогонов было выявлено следующее количество ошибок.
|
Номер прогона |
1 |
2 |
3 |
4 |
|
V |
6 |
4 |
2 |
2 |
|
S |
4 |
2 |
1 |
1 |
Необходимо оценить количество ошибок перед каждым тестовым прогоном. Оценить степень отлаженности программы после последнего прогона. Построить диаграмму зависимости возможного числа ошибок в данной программе от номера тестового прогона.
Решение задачи
Количество ошибок перед каждым прогоном будем оценивать в соответствии с выражением (2.2.1). Перед каждой последующей оценкой количества ошибок и степени отлаженности программы необходимо корректировать значения внесенных Wи предполагаемыхr ошибок с учетом выявленных и устраненных после каждого прогона тестов. Степень отлаженности программы на всех прогонах, кроме последнего (2.2.2), рассчитывается по комбинаторной формуле (2.2.3).
Определяя показатели программы по результатам первого прогона, необходимо учитывать, что W1= 14;S1= 4;V1= 6, тогда
N1= (W1 · S1) /V1= (14·4) / 6 = 9.
Перед вторым прогоном корректируем исходные данные для оценки параметров: r2= 14 — 4 = 10;W2= 14 — 6 = 8;S2= 2;V2= 4, тогда
N2= (W2 · S2) /V2= (8·2) / 4 = 4.
Корректировка исходных данных перед третьим прогоном дает следующие данные. r3 = 10 — 2 = 8,W3= 8 — 4 = 4;S3= 1;V3= 2, откуда количество ошибок определится следующим образом:
N3= (W3 · S3) /V3= (4 · 1) / 2 = 2.
Перед четвертым прогоном программы получим следующие исходные данные: r4 = 8 — 1 = 7,W4= 4 — 2 = 2;S4= 1;V4= 2, тогда
N4= (W4 · S4) /V4= (2 ·1) /2 = 1.
Поскольку после четвертого прогона все «посеянные» ошибки выявлены и устранены, то для оценки отлаженности программы можно воспользоваться упрощенной формулой
С=W/(W+r+ 1) =2/(2+ 7+ 1) =0,2.
Таким образом, в предположении, что до начала четвертого прогона в программе оставалось 7 ошибок, степень отлаженности программы составляет 20%.
Результат по количеству ошибок в программе до начала каждого прогона приведен ниже.
|
Номер прогона |
1 |
2 |
3 |
4 |
|
N |
9 |
4 |
2 |
1 |
Надеюсь, эта статья об статистическая модель миллса -оценка количества ошибок в программном коде , была вам интересна и не так слона для восприятия как могло показаться, удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое статистическая модель миллса -оценка количества ошибок в программном коде
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
1
Лабораторная работа Модели
надежности программного обеспечения
Цель работы : ознакомиться с динамическими
и статическими методами оценки
надежности ПО
Методические указания
1. Модель Шумана основана на следующих
допущениях:
-
общее число команд в программе на
машинном языке постоянно; -
в начале компоновочных испытаний число
ошибок равно некоторой постоянной
величине, и по мере исправления ошибок
их становится меньше. В ходе испытаний
программы новые ошибки не вносятся; -
ошибки изначально различимы, по
суммарному числу исправленных ошибок
можно судить об оставшихся; -
интенсивность отказов программы
пропорциональна числу остаточных
ошибок.
Предполагается, что до
начала тестирования (т.е. в момент =0)
имеется M
ошибок. В течение времени тестирования
τ обнаруживается ε1()
ошибок
в расчете на одну команду в машинном
языке.
Тогда удельное число ошибок
на одну машинную команду, оставшихся в
системе после времени тестирования τ,
равно:
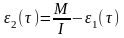
(1)
где I — общее число машинных
команд, которое предполагается постоянным
в рамках этапа тестирования.
Предполагается, что значение
функции количества ошибок Z(t) пропорционально
числу ошибок, оставшихся в программе
после израсходованного на тестирование
времени τ.
Z (t) = C * ε2
(τ),
где С — некоторая постоянная,
t — время работы программы без отказов.
Тогда, если время работы
программы без отказа t отсчитывается
от точки t = 0, а τ остается фиксированным,
функция надежности, или вероятность
безотказной работы на интервале от 0 до
t, равна
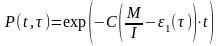
(2)

(3)
Необходимо найти начальное
значение ошибок M
и коэффициент пропорциональности С.
Эти неизвестные оцениваются путем
пропуска функционального теста в двух
точках переменной оси отладки a
и b,
выбранных так, что ε1(a)<ε1(b).
В процессе тестирования
собирается информация о времени и
количестве ошибок на каждом прогоне,
т.е. общее время тестирования τ складывается
из времени каждого прогона:
τ = τ1 +
τ2 +
τ3 +
… + τn.
Предполагая, что интенсивность
появления ошибок постоянна и равна λ,
можно вычислить ее как число ошибок в
единицу времени,
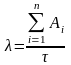
(4)
где Ai —
количество ошибок на i — ом прогоне.
Тогда
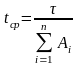
. (5)
Имея данные для двух различных
моментов тестирования a
и в,
можно сопоставить уравнения (3) при τa
и τb:
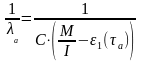
(6)
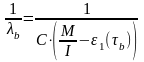
(7)
Из соотношений (6) и (7) найдем
неизвестный параметр С и М:
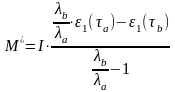
(8)
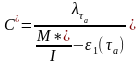
(9)
Получив неизвестные M*
и C*,
можно рассчитать надежность программы
по формуле (2).
Пример 1.
Программа содержит 2 000 командных
строк, из них, до начала эксплуатации
(после периода отладки), 15 командных
строк содержат ошибки. После
20 дней
работы обнаружена 1 ошибка. Найти среднее
время безошибочной работы программы и
интенсивность отказов программы при
коэффициенте пропорциональности, равном
0,7.
|
I |
2000 |
|
M |
15 |
|
t |
20 |
|
x |
1 |
|
C= |
0,7 |
|
Выполнение задания 1(t)=? |
|||
|
2(t)=? |
|||
|
P(t)=? |
|||
|
tср=? |
|||
|
λ=? |
На условиях примера 1 определить
вероятность безошибочной работы
программы P(t)
в течение 90 суток.
|
I= |
2000 |
||
|
M= |
15 |
||
|
t= |
90 |
||
|
x= |
1 |
||
|
C= |
0,7 |
||
|
Пример 3.
Определить первоначальное количество
возможных ошибок в программе, содержащей
2 000 командных строк, если в течение
первых 60 суток эксплуатации было
обнаружено 2 ошибки, а за последующие
40 суток была обнаружена одна ошибка.
Определить T0
– среднее время безошибочной работы,
соответствующее первому и второму
периоду эксплуатации программы и
коэффициент пропорциональности.
|
I= |
2000 |
||||
|
t1= |
60 |
суток |
|||
|
t2= |
100 |
суток |
|||
|
x1= |
2 |
ош. |
|||
|
x2= |
3 |
ош. |
|||
|
T0= |
? |
||||
|
Интенсивности |
отказов: |
||||
|
λ2= |
|||||
|
C= |
|||||
|
ε1 |
|||||
|
ε2 |
|||||
|
M= |
|||||
|
2/1= |
2. Модель Миллса. Пусть в процессе тестирования обнаружено n исходных ошибок и V из s рассеянных ошибок. Тогда оценка n — первоначальное число ошибок в программе — составит
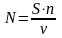
.
Вторая часть модели связана с проверкой
гипотезы выражения и тестирования N.
Рассмотрим случай, когда
программа содержит К
собственных ошибок и S рассеянных
ошибок. Будем тестировать программу до
тех пор, пока не обнаружим все рассеянные
ошибки. В то же время количество
обнаруженных исходных ошибок накапливается
и запоминается. Далее вычисляется оценка
надежности модели:
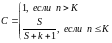
(11)
как вероятность того, что
в программе содержится K
ошибок.
Величина С является мерой
доверия к модели и показывает вероятность
того, насколько правильно найдено
значение N. Эти два связанных между собой
по смыслу соотношения образуют полезную
модель ошибок: первое предсказывает
возможное число первоначально имевшихся
в программе ошибок, а второе используется
для установления доверительного уровня
прогноза.
Формула для расчета С в
случае, когда обнаружены не все
искусственно рассеянные ошибки,
модифицирована таким образом, что оценка
может быть выполнена после обнаружения
v
(vS)
рассеянных ошибок:
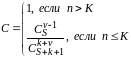
(12)
где числитель и знаменатель
формулы при n
К являются
биноминальными коэффициентами.
Пример 4.
Предположим, что в программе имеется 3
собственных ошибки. Внесём ещё 6 ошибок
случайным образом.
В процессе тестирования было найдено:
1) 6 ошибок из рассеянных и 2 собственных;
2) 5 ошибок из рассеянных и 2 собственных;
3) 5 ошибок из рассеянных и 4 собственных.
Найти надёжность по модели
Миллса
3. Простая интуитивная
модель. Использование этой модели
предполагает проведение тестирования
двумя группами программистов (или двумя
программистами в зависимости от величины
программы) независимо друг от друга,
использующими независимые тестовые
наборы. В процессе тестирования каждая
из групп фиксируют все найденные ею
ошибки.
Пусть первая группа обнаружила n1
ошибок, вторая n2 , n12 — это
число ошибок, обнаруженных как первой,
так и второй группой.
Обозначим через N неизвестное количество
ошибок, присутствующих в программе до
начала тестирования. Тогда можно
эффективность тестирования каждой из
групп определить как
.![]()
Эффективность тестирования можно
интерпретировать как вероятность того,
что ошибка будет обнаружена. Таким
образом, можно считать, что первая группа
обнаруживает ошибку в программе с
вероятностью
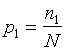
,
вторая — с вероятностью
![]()
.
Тогда вероятность p12 того, что
ошибка будет обнаружена обеими группами,
можно принять равной
![]()
.
С другой стороны, так как группы действуют
независимо друг от друга, то р12 =
р1р2. Получаем:
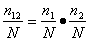
Отсюда получаем оценку первоначального
числа ошибок программы:
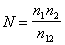
.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #