Наибольший
интерес представляет модель надежности
ПО, предложенная М.Х.Холстедом. На
сегодня, из множества разработанных
моделей, это единственная, с помощью
которой можно оценить число ожидаемых
ошибок в ПО еще на этапе обсуждения
технического задания на разработку
этого ПО.
МЕТРИКИ
ХОЛСТЕДА
Суть
метода Холстеда состоит в следующем.
Для любой программы можно определить:
Число
различных операций
![]()
(таких, как IF, =, DO,
PRINT и т.д.);
Число
различных операндов
![]()
(таких, как переменные и константы);
Общее
число всех операций
![]()
;
Общее
число всех операндов
![]()
;
Словарь
программы
![]()
;
Длину
реализации
![]()
.
Тогда
теоретическая длина программы составит
![]()
соответственно
объем программы (в битах)
![]()
далее
рассматривается такая метрика, как
потенциальный объем программы (в битах),
![]()
где
![]()
— минимальное число различных операндов,
в роли которого обычно выступает число
независимых входных и выходных параметров.
Величина
может быть выявлена еще на стадии
согласования технического задания на
разработку ПО. Технология этого процесса
будет подробно рассмотрена далее.
Таким
образом,
![]()
— потенциально минимально возможный
объем ПО с заданным интерфейсом, который
может быть реализован программистом
высокой квалификации на языке высокого
уровня.
Следующей
важной метрикой является уровень
программы определяемый как отношение
потенциального объема к объему:
![]()
Далее
вводится работа по программированию
E, как суммарное число
элементарных мысленных различений,
необходимых для генерации программы
ее создателем:
![]()
Следующая
метрика – уровень языка
![]()
— позволяет количественно оценивать
преимущества языка программирования
более высокого уровня по сравнению со
своими предшественниками и определяется
как
![]()
Следовательно:
![]()
; ![]()
В табл.
5 приведены численные значения
для языков разных уровней.
Таблица 5
|
Язык |
|
|
Ассемблер |
0.88 |
|
Фортран |
1,14 |
|
Паскаль |
2,16 |
Еще
одна из метрик, предложенных Холстедом,
позволяет оценивать время затрачиваемое
на разработку ПО:
![]()
где S
– параметр Страуда.
Параметр
Страуда – психофизиологическая
константа, характеризующая время,
необходимое человеческому мозгу для
выполнения элементарной мыслительной
операции («различия» по Холстеду).
Считается, что S лежит в
пределах от 5 до 20 различений в секунду.
Холстед использует значение S=18,
характеризующее процесс программирования
как довольно напряженную умственную
работу.
Можно
оценить относительное уменьшение
времени программирования при переходе
от языка низкого уровня
![]()
к языку высокого уровня
![]()
,
т.е. оценить выигрыш во времени за счет
выбора языка:
![]()
ОЦЕНКА
ЧИСЛА ОСТАВШИХСЯ В ПО ОШИБОК
Согласно
основной гипотезе Холстеда общее число
ожидаемых (переданных пользователю)
Ошибок B в программе
определяется сложностью ее создания,
которую можно характеризовать работой
по программированию E или
объемом программы V:
![]()
С
определением коэффициента пропорциональности
C модель надежности ПО
приобретает законченный вид. Приведем
ход рассуждений М.Холстеда по определению
этой константы.
Холстед
предлагает, что C должна
определяться (быть обратно пропорциональной)
некоторой минимальной работе по
программированию
![]()
,
производимой при создании программы,
содержащей максимум одну ошибку. Другими
словами, C выступает в
роли нормировочного коэффициента.
Теперь необходимо определить тот
минимальный объем работы
,
превышение которого приведет к появлению
ошибки. Для этой цели привлечем на помощь
гипотезу утверждающую, что мозг человека
может обрабатывать в своей памяти
одновременно и безошибочно лишь 5-9
объектов. Взяв нижнюю границу в пять
объектов и добавив результирующий
объект, мы получим минимальное число
![]()
различных входных и выходных параметров
для потенциально безошибочной программы.
Соответствующий потенциальный объем
составит:
![]()
(логических бит)
Итак,
гипотеза ошибок Холстеда утверждает,
что в среднем после обработки 24 битов
абстрактной информации на языке высокого
уровня человек совершает ошибку. Холстед
использует выражение
=2,16 и получает:
=3000.
Следовательно
В=V/300
Это
означает, что на каждые 3000 бит объема V
возможна одна потенциальная ошибка.
Здесь необходимо иметь в виду, что речь
идет не о «физических» битах памяти,
отведенной для размещения ПО в машине,
а о «логических» битах. Следует отметить,
что значение константы C
дает достаточно правдоподобные оценки
только в том случае, если ПО разрабатывалось
с использованием языков высокого уровня.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
10.2. Модели оценки надежности
Из всех областей программной инженерии надежность ПС является самой исследованной областью. Ей предшествовала разработка теории надежности технических средств, оказавшая влияние на развитие надежности ПС. Вопросами надежности ПС занимались разработчики ПС, пытаясь разными системными средствами обеспечить надежность, удовлетворяющую заказчика, а также теоретики, которые, изучая природу функционирования ПС, создали математические модели надежности, учитывающие разные аспекты работы ПС (возникновение ошибок, сбоев, отказов и др.) и позволяющие оценить реальную надежность. В результате надежность ПС сформировалась как самостоятельная теоретическая и прикладная наука [10.5-10.10, 10.16-10.24].
Надежность сложных ПС существенным образом отличается от надежности аппаратуры. Носители данных (файлы, сервер и т.п.) обладают высокой надежностью, записи на них могут храниться длительное время без разрушения, поскольку физическому разрушению они не подвергаются.
С точки зрения прикладной науки надежность — это способность ПС сохранять свои свойства (безотказность, устойчивость и др.), преобразовывать исходные данные в результаты в течение определенного промежутка времени при определенных условиях эксплуатации. Снижение надежности ПС происходит из-за ошибок в требованиях, проектировании и выполнении. Отказы и ошибки зависят от способа производства продукта и появляются в программах при их исполнении на некотором промежутке времени.
Для многих систем (программ и данных) надежность — главная целевая функция реализации. К некоторым типам систем (реального времени, радарные системы, системы безопасности, медицинскоеоборудование со встроенными программами и др.) предъявляются высокие требования к надежности, такие, как отсутствие ошибок, достоверность, безопасность и др.
Таким образом, оценка надежности ПС зависит от числа оставшихся и не устраненных ошибок в программах. В ходе эксплуатации ПС ошибки обнаруживаются и устраняются. Если при исправлении ошибок не вносятся новые или, по крайней мере, новых ошибок вносится меньше, чем устраняется, то в ходе эксплуатации надежность ПС непрерывно возрастает. Чем интенсивнее проводится эксплуатация, тем интенсивнее выявляются ошибки и быстрее растет надежность системы и соответственно ее качество.
Надежность является функцией от ошибок, оставшихся в ПС после ввода его в эксплуатацию. ПС без ошибок является абсолютно надежным. Но для больших программ абсолютная надежность практически недостижима. Оставшиеся необнаруженные ошибки проявляют себя время от времени при определенных условиях (например, при некоторой совокупности исходных данных) сопровождения и эксплуатации системы.
Для оценки надежности ПС используются такие статистические показатели, как вероятность и время безотказной работы, возможность отказа и частота (интенсивность) отказов. Поскольку в качестве причин отказов рассматриваются только ошибки в программе, которые не могут самоустраниться, то ПС следует относить к классу невосстанавливаемых систем.
При каждом проявлении новой ошибки, как правило, проводится ее локализация и исправление. Строго говоря, набранная до этого статистика об отказах теряет свое значение, так как после внесения изменений программа, по существу, является новой программой в отличие от той, которая до этого испытывалась.
В связи с исправлением ошибок в ПС надежность, т.е. ее отдельные атрибуты, будут все время изменяться, как правило, в сторону улучшения. Следовательно, их оценка будет носить временный и приближенный характер. Поэтому возникает необходимость в использовании новых свойств, адекватных реальному процессу измерения надежности, таких, как зависимость интенсивности обнаруженных ошибок от числа прогонов программы и зависимость отказов от времени функционирования ПС и т.п.
К факторам гарантии надежности относятся:
- риск как совокупность угроз, приводящих к неблагоприятным последствиям и ущербу системы или среды;
- угроза как проявление неустойчивости, нарушающей безопасность системы;
- анализ риска — изучение угрозы или риска, их частота и последствия;
- целостность — способность системы сохранять устойчивость работы и не иметь риска;
Риск преобразует и уменьшает свойства надежности, так как обнаруженные ошибки могут привести к угрозе, если отказы носят частотный характер.
10.2.1. Основные понятия в проблематике надежности ПС
Формально модели оценки надежности ПС базируются на теории надежности и математическом аппарате с допущением некоторых ограничений, влияющих на эту оценку. Главным источником информации, используемой в моделях надежности, является процесс тестирования, эксплуатации ПС и разного вида ситуации, возникающие в них. Ситуации порождаются возникновением ошибок в ПС, требуют их устранения для продолжения тестирования.
Базовыми понятиями, которые используются в моделях надежности ПС, являются [10.5-10.10].
Отказ ПC (failure) — это переход ПС из работающего состояния в нерабочее или когда получаются результаты, которые не соответствуют заданным допустимым значениям. Отказ может быть вызван внешними факторами (изменениями элементов среды эксплуатации) и внутренними — дефектами в самой ПС.
Дефект (fault) в ПС — это последствие использования элемента программы, который может привести к некоторому событию, например, в результате неверной интерпретации этого элемента компьютером (как ошибка (fault) в программе) или человеком (ошибка (error) исполнителя). Дефект является следствием ошибок разработчика на любом из процессов разработки — в описании спецификаций требований, начальных или проектных спецификациях, эксплуатационной документации и т.п. Дефекты в программе, не выявленные в результате проверок, являются источником потенциальных ошибок и отказов ПС. Проявление дефекта в виде отказа зависит от того, какой путь будет выполнять специалист, чтобы найти ошибку в коде или во входных данных. Однако не каждый дефект ПС может вызвать отказ или может быть связан с дефектом в ПС или среды. Любой отказ может вызвать аномалию от проявления внешних ошибок и дефектов.
Ошибка (error) может быть следствием недостатка в одном из процессов разработки ПС, который приводит к неправильной интерпретации промежуточной информации, заданной разработчиком или при принятии им неверных решений.
Интенсивность отказов — это частота появления отказов или дефектов в ПС при ее тестировании или эксплуатации.
При выявлении отклонения результатов выполнения от ожидаемых во время тестирования или сопровождения осуществляется поиск, выяснение причин отклонений и исправление связанных с этим ошибок.
Модели оценки надежности ПС в качестве входных параметров используют сведения об ошибках, отказах, их интенсивности, собранных в процессе тестирования и эксплуатации.
10.2.2. Классификация моделей надежности
Как известно, на данный момент времени разработано большое количество моделей надежности ПС и их модификаций. Каждая из этих моделей определяет функцию надежности, которую можно вычислить при задании ей соответствующих данных, собранных во время функционирования ПС. Основными данными являются отказы и время. Другие дополнительные параметры связаны с типом ПС, условиями среды и данных.
Ввиду большого разнообразия моделей надежности разработано несколько подходов к классификации этих моделей. Такие подходы в целом основываются на истории ошибок в проверяемой и тестируемой ПС на этапах ЖЦ. Одной из классификаций моделей надежности ПО является классификация Хетча [10.10]. В ней предлагается разделение моделей на прогнозирующие, измерительные и оценочные (рис. 10.4).
Прогнозирующие модели надежности основаны на измерении технических характеристик создаваемой программы: длина, сложность, число циклов и степень их вложенности, количество ошибок на страницу операторов программы и др.
Например, модель Мотли-Брукса основывается на длине и сложности структуры программы (количество ветвей, циклов, вложенность циклов), количестве и типах переменных, а также интерфейсов. В этих моделях длина программы служит для прогнозирования количества ошибок, например, для 100 операторов программы можно смоделировать интенсивность отказов.

Рис.
10.4.
Классификация моделей надежности
Модель Холстеда прогнозирует количество ошибок в программе в зависимости от ее объема и таких данных, как число операций
( 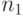 ) и операндов (
) и операндов ( 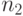 ), а также их общее число (
), а также их общее число ( 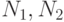 ).
).
Время программирования программы предлагается вычислять по следующей формуле:
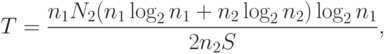
где  — число Страуда (Холстед принял равным 18 — число умственных операций в единицу времени).
— число Страуда (Холстед принял равным 18 — число умственных операций в единицу времени).
Объем вычисляется по формуле:

где 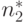 — максимальное число различных операций.
— максимальное число различных операций.
Измерительные модели предназначены для измерения надежности программного обеспечения,
работающего с заданной внешней средой. Они имеют следующие ограничения:
- программное обеспечение не модифицируется во время периода измерений свойств надежности;
- обнаруженные ошибки не исправляются;
- измерение надежности проводится для зафиксированной конфигурации программного обеспечения.
Типичным примером таких моделей являются модели Нельсона и РамамуртиБастани и др.Модель оценки надежности Нельсона основывается на выполнении k-прогонов программы при тестировании и позволяет определить надежность
![R(k) = exp [-sum{nabla t_{j}lambda(t)}],](https://intuit.ru/sites/default/files/tex_cache/b49eac2e774618b741148f322ba28c63.png)
где 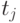 — время выполнения
— время выполнения  -прогона,
-прогона, ![lambda(t) = - [ln{(1-q_{i})nablaj]](https://intuit.ru/sites/default/files/tex_cache/bf1a911424671831af64a03762a55933.png) и при
и при  она интерпретируется как интенсивность отказов.
она интерпретируется как интенсивность отказов.
В процессе испытаний программы на тестовых  прогонах оценка надежности вычисляется по формуле
прогонах оценка надежности вычисляется по формуле
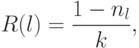
где  — число прогонов программы.
— число прогонов программы.
Таким образом, данная модель рассматривает полученные количественные данные о проведенных прогонах.
Оценочные модели основываются на серии тестовых прогонов и проводятся на этапах тестирования ПC. В тестовой среде определяется вероятность отказа программы при ее выполнении или тестировании.
Эти типы моделей могут применяться на этапах ЖЦ. Кроме того, результаты прогнозирующих моделей могут использоваться как входные данные для оценочной модели. Имеются модели (например, модель Муссы), которые можно рассматривать как оценочную и в то же время как измерительную модель [10.16, 10.17].
Другой вид классификации моделей предложил Гоэл [10.18, 10.19], согласно которой модели надежности базируются на отказах и разбиваются на четыре класса моделей:
- без подсчета ошибок;
- с подсчетом отказов;
- с подсевом ошибок;
- модели с выбором областей входных значений.
Модели без подсчета ошибок основаны на измерении интервала времени между отказами и позволяют спрогнозировать количество ошибок, оставшихся в программе. После каждого отказа оценивается надежность и определяется среднее время до следующего отказа. К таким моделям относятся модели Джелински и Моранды, Шика Вулвертона и Литвуда-Вералла [10.20, 10.21].
Модели с подсчетом отказов базируются на количестве ошибок, обнаруженных на заданных интервалах времени. Возникновение отказов в зависимости от времени является стохастическим процессом с непрерывной интенсивностью, а количество отказов является случайной величиной. Обнаруженные ошибки, как правило, устраняются и поэтому количество ошибок в единицу времени уменьшается. К этому классу моделей относятся модели Шумана, Шика- Вулвертона, Пуассоновская модель и др. [10.21-10.24].
Модели с подсевом ошибок основаны на количестве устраненных ошибок и подсеве, внесенном в программу искусственных ошибок, тип и количество которых заранее известны. Затем определяется соотношение числа оставшихся прогнозируемых ошибок к числу искусственных ошибок, которое сравнивается с соотношением числа обнаруженных действительных ошибок к числу обнаруженных искусственных ошибок. Результат сравнения используется для оценки надежности и качества программы. При внесении изменений в программу проводится повторное тестирование и оценка надежности. Этот подход к организации тестирования отличается громоздкостью и редко используется из-за дополнительного объема работ, связанных с подбором, выполнением и устранением искусственных ошибок.
Модели с выбором области входных значений основываются на генерации множества тестовых выборок из входного распределения, и оценка надежности проводится по полученным отказам на основе тестовых выборок из входной области. К этому типу моделей относится модель Нельсона и др.
Таким образом, классификация моделей роста надежности относительно процесса выявления отказов, фактически разделена на две группы:
- модели, которые рассматривают количество отказов как марковский процесс;
- модели, которые рассматривают интенсивность отказов как пуассоновский процесс.
Фактор распределения интенсивности отказов разделяет модели на экспоненциальные, логарифмические, геометрические, байесовские и др.
Компьютерная программа — это реализация алгоритма, который считается набором токенов, которые можно классифицировать как операторы или операнды. Метрики Холстеда включены в ряд текущих коммерческих инструментов, которые подсчитывают программные строки кода. Подсчитывая токены и определяя, какие из них являются операторами, а какие — операндами, можно собрать следующие базовые показатели:
n1 = количество различных операторов.
n2 = количество различных операндов.
N1 = Общее количество вхождений операторов.
N2 = Общее количество вхождений операндов.
В дополнение к вышесказанному, Холстед определяет следующее:
n1 * = Количество потенциальных операторов.
n2 * = Количество потенциальных операндов.
Холстед ссылается на n1 * и n2 * как на минимально возможное количество операторов и операндов для модуля и программы соответственно. Это минимальное количество будет воплощено в самом языке программирования, в котором требуемая операция уже существует (например, на языке C любая программа должна содержать по крайней мере определение функции main ()), возможно, как функция или как процедура: n1 * = 2, так как по крайней мере 2 оператора должны присутствовать для любой функции или процедуры: 1 для имени функции и 1, чтобы служить в качестве символа назначения или группировки, а n2 * представляет количество параметров без повторения , который необходимо передать функции или процедуре.
Метрики Холстеда —
Метрики Холстеда:
- Длина программы Холстеда — общее количество вхождений оператора и общее количество вхождений операнда.
N = N1 + N2Предполагаемая длина программы: N ^ = n1log 2 n1 + n2log 2 n2
Для оценки длины программы были опубликованы следующие альтернативные выражения:
- N J = журнал 2 (n1!) + Журнал 2 (n2!)
- N B = n1 * журнал 2 n2 + n2 * журнал 2 n1
- N C = n1 * sqrt (n1) + n2 * sqrt (n2)
- N S = (n * журнал 2 n) / 2
- Словарь Холстеда — общее количество уникальных вхождений оператора и уникальных операндов.
п = п1 + п2 - Объем программы — пропорционален размеру программы, представляет размер в битах пространства, необходимого для хранения программы. Этот параметр зависит от конкретной реализации алгоритма. Показано, что свойства V, N и количество строк в коде линейно связаны и одинаково пригодны для измерения относительного размера программы.
V = Размер * ( словарь log 2 ) = N * log 2 (n)
Единица измерения объема — это общепринятая единица измерения размера «бит». Это фактический размер программы, если используется единая двоичная кодировка словаря. И погрешность = Объем / 3000
- Потенциальный минимальный объем — Потенциальный минимальный объем V * определяется как объем самой сжатой программы, в которой может быть закодирована проблема.
V * = (2 + n2 *) * журнал 2 (2 + n2 *)
Здесь n2 * — количество уникальных входных и выходных параметров.
- Уровень программы — для ранжирования языков программирования учитывается уровень абстракции, обеспечиваемый языком программирования, уровень программы (L). Чем выше уровень языка, тем меньше усилий требуется для разработки программы, использующей этот язык.
L = V * / V
Значение L находится в диапазоне от нуля до единицы, где L = 1 представляет программу, написанную на максимально возможном уровне (т. Е. С минимальным размером).
Предполагаемый уровень программы L ^ = 2 * (n2) / (n1) (N2) - Сложность программы — этот параметр показывает, насколько сложно работать с программой.
D = (n1 / 2) * (N2 / n2)
D = 1 / л
По мере увеличения объема реализации программы уровень программы уменьшается, а сложность увеличивается. Таким образом, такие практики программирования, как избыточное использование операндов или отказ от использования управляющих конструкций более высокого уровня, будут иметь тенденцию увеличивать объем, а также сложность. - Усилия программирования — измеряет объем умственной деятельности, необходимой для преобразования существующего алгоритма в реализацию на указанном языке программы.
E = V / L = D * V = Сложность * Объем - Уровень языка — показывает уровень языка программы реализации алгоритма. Тот же алгоритм требует дополнительных усилий, если он написан на языке программ низкого уровня. Например, программировать на Паскале проще, чем на Ассемблере.
L ‘= V / D / D
лямбда = L * V * = L 2 * V - Содержимое интеллекта — определяет объем интеллекта, представленного (заявленного) в программе. Этот параметр обеспечивает измерение сложности программы независимо от языка программы, на котором она была реализована.
I = V / D - Время программирования — показывает время (в минутах), необходимое для преобразования существующего алгоритма в реализацию на указанном языке программы.
Т = E / (f * S)Также используется концепция скорости обработки данных человеческого мозга, разработанная психологом Джоном Страудом. Стоуд определил момент как время, необходимое человеческому мозгу для принятия самого элементарного решения. Таким образом, число Студа S представляет собой моменты Стауда в секунду с:
5 <= S <= 20. Холстед использует 18. Значение S было получено эмпирическим путем из психологических соображений, и его рекомендуемое значение для программирования приложений составляет 18.Число страда S = 18 моментов в секунду
коэффициент от секунд к минутам f = 60
Правила подсчета для языка C —
- Комментарии не рассматриваются.
- Объявления идентификатора и функции не рассматриваются.
- Все переменные и константы считаются операндами.
- Глобальные переменные, используемые в разных модулях одной и той же программы, считаются несколькими экземплярами одной и той же переменной.
- Локальные переменные с одинаковыми именами в разных функциях считаются уникальными операндами.
- Вызовы функций рассматриваются как операторы.
- Все операторы цикла, например, do {…} while (), while () {…}, for () {…}, все управляющие операторы, например, if () {…}, if () {…} else {…}, и т.д. считаются операторами.
- В управляющей конструкции switch () {case:…} switch, а также все операторы case рассматриваются как операторы.
- Зарезервированные слова, такие как return, default, continue, break, sizeof и т. Д., Считаются операторами.
- Все скобки, запятые и терминаторы считаются операторами.
- GOTO считается оператором, а метка считается операндом.
- Унарные и двоичные символы «+» и «-» рассматриваются отдельно. Аналогично «*» (оператор умножения) рассматриваются отдельно.
- В массиве такие переменные, как «имя-массива [индекс]», «имя-массива» и «индекс» рассматриваются как операнды, а [] рассматривается как оператор.
- В переменных структуры, таких как «имя-структуры, имя-члена» или «имя-структуры -> имя-члена», имя-структуры, имя-члена принимаются как операнды, а ‘.’, ‘->’ — как операторы. Некоторые имена элементов-членов в различных структурных переменных считаются уникальными операндами.
- Все хеш-директивы игнорируются.
Пример. Перечислите операторы и операнды, а также вычислите значения таких научных показателей программного обеспечения, как
int sort (int x [], int n)
{
int i, j, сохранить, im1;
/ * Эта функция сортирует массив x в порядке возрастания * /
Если (n <2) вернуть 1;
для (i = 2; i <= n; i ++)
{
im1 = i-1;
для (j = 1; j <= im1; j ++)
если (x [i] <x [j])
{
Сохранить = x [i];
х [я] = х [j];
x [j] = сохранить;
}
}
возврат 0;
}
Объяснение —
| операторы | происшествия | операнды | происшествия |
| int | 4 | Сортировать | 1 |
| () | 5 | Икс | 7 |
| , | 4 | п | 3 |
| [] | 7 | я | 8 |
| если | 2 | j | 7 |
| < | 2 | спасти | 3 |
| ; | 11 | im1 | 3 |
| для | 2 | 2 | 2 |
| знак равно | 6 | 1 | 3 |
| — | 1 | 0 | 1 |
| <= | 2 | — | — |
| ++ | 2 | — | — |
| возвращение | 2 | — | — |
| {} | 3 | — | — |
| n1 = 14 | N1 = 53 | n2 = 10 | N2 = 38 |
Следовательно, N = 91 n = 24 V = 417,23 бит N ^ = 86,51 n2 * = 3 (x: массив, содержащий целое число быть отсортированным. Это используется как как ввод и вывод) V * = 11,6 L = 0,027 D = 37,03 L ^ = 0,038 T = 610 секунд
Преимущества метрик Холстеда:
- Подсчитать несложно.
- Он измеряет общее качество программ.
- Он предсказывает уровень ошибки.
- Он прогнозирует усилия по техническому обслуживанию.
- Не требует полного анализа структуры программирования.
- Это полезно при планировании и составлении отчетов по проектам.
- Его можно использовать для любого языка программирования.
Недостатки метрик Холстеда:
- Это зависит от полного кода.
- Она не используется в качестве модели прогнозной оценки.
Ссылка —
Меры сложности Холстеда — Википедия
Ristancase
Эта статья предоставлена Шивани Вирмани. Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на deposit@geeksforgeeks.org. Посмотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по теме, обсужденной выше.
From Wikipedia, the free encyclopedia
Halstead complexity measures are software metrics introduced by Maurice Howard Halstead in 1977[1] as part of his treatise on establishing an empirical science of software development.
Halstead made the observation that metrics of the software should reflect the implementation or expression of algorithms in different languages, but be independent of their execution on a specific platform.
These metrics are therefore computed statically from the code.
Halstead’s goal was to identify measurable properties of software, and the relations between them.
This is similar to the identification of measurable properties of matter (like the volume, mass, and pressure of a gas) and the relationships between them (analogous to the gas equation).
Thus his metrics are actually not just complexity metrics.
Calculation[edit]
For a given problem, let:
From these numbers, several measures can be calculated:
The difficulty measure is related to the difficulty of the program to write or understand, e.g. when doing code review.
The effort measure translates into actual coding time using the following relation,
- Time required to program:
seconds
Halstead’s delivered bugs (B) is an estimate for the number of errors in the implementation.
Example[edit]
Consider the following C program:
main() { int a, b, c, avg; scanf("%d %d %d", &a, &b, &c); avg = (a+b+c)/3; printf("avg = %d", avg); }
The distinct operators (
main, (), {}, int, scanf,
&, =, +, /, printf, ,, ;
The distinct operands (
a, b, c, avg, "%d %d %d", 3, "avg = %d"
See also[edit]
- Function point
- Cyclomatic complexity
References[edit]
- ^ Halstead, Maurice H. (1977). Elements of Software Science. Amsterdam: Elsevier North-Holland, Inc. ISBN 0-444-00205-7.
External links[edit]
- The Halstead metrics — Extensive discussion on the calculation and use of Halstead Metrics in an object-oriented environment (with specific reference to Java).
- Calculation of Halstead metrics — Measurement of Halstead Metrics.
- Explanation with a Sample Program — Example (on Page 6 of the PDF)
- Script computing Halstead Metrics and using them for commented code detection
- IBM
- Calculator for computing Halstead metrics
From Wikipedia, the free encyclopedia
Halstead complexity measures are software metrics introduced by Maurice Howard Halstead in 1977[1] as part of his treatise on establishing an empirical science of software development.
Halstead made the observation that metrics of the software should reflect the implementation or expression of algorithms in different languages, but be independent of their execution on a specific platform.
These metrics are therefore computed statically from the code.
Halstead’s goal was to identify measurable properties of software, and the relations between them.
This is similar to the identification of measurable properties of matter (like the volume, mass, and pressure of a gas) and the relationships between them (analogous to the gas equation).
Thus his metrics are actually not just complexity metrics.
Calculation[edit]
For a given problem, let:
From these numbers, several measures can be calculated:
The difficulty measure is related to the difficulty of the program to write or understand, e.g. when doing code review.
The effort measure translates into actual coding time using the following relation,
- Time required to program:
Halstead’s delivered bugs (B) is an estimate for the number of errors in the implementation.
Example[edit]
Consider the following C program:
main() { int a, b, c, avg; scanf("%d %d %d", &a, &b, &c); avg = (a+b+c)/3; printf("avg = %d", avg); }
The distinct operators (
main, (), {}, int, scanf,
&, =, +, /, printf, ,, ;
The distinct operands (
a, b, c, avg, "%d %d %d", 3, "avg = %d"
See also[edit]
- Function point
- Cyclomatic complexity
References[edit]
- ^ Halstead, Maurice H. (1977). Elements of Software Science. Amsterdam: Elsevier North-Holland, Inc. ISBN 0-444-00205-7.
External links[edit]
- The Halstead metrics — Extensive discussion on the calculation and use of Halstead Metrics in an object-oriented environment (with specific reference to Java).
- Calculation of Halstead metrics — Measurement of Halstead Metrics.
- Explanation with a Sample Program — Example (on Page 6 of the PDF)
- Script computing Halstead Metrics and using them for commented code detection
- IBM
- Calculator for computing Halstead metrics
Наибольший
интерес представляет модель надежности
ПО, предложенная М.Х.Холстедом. На
сегодня, из множества разработанных
моделей, это единственная, с помощью
которой можно оценить число ожидаемых
ошибок в ПО еще на этапе обсуждения
технического задания на разработку
этого ПО.
МЕТРИКИ
ХОЛСТЕДА
Суть
метода Холстеда состоит в следующем.
Для любой программы можно определить:
Число
различных операций
![]()
(таких, как IF, =, DO,
PRINT и т.д.);
Число
различных операндов
![]()
(таких, как переменные и константы);
Общее
число всех операций
![]()
;
Общее
число всех операндов
![]()
;
Словарь
программы
![]()
;
Длину
реализации
![]()
.
Тогда
теоретическая длина программы составит
![]()
соответственно
объем программы (в битах)
![]()
далее
рассматривается такая метрика, как
потенциальный объем программы (в битах),
![]()
где
![]()
— минимальное число различных операндов,
в роли которого обычно выступает число
независимых входных и выходных параметров.
Величина
может быть выявлена еще на стадии
согласования технического задания на
разработку ПО. Технология этого процесса
будет подробно рассмотрена далее.
Таким
образом,
![]()
— потенциально минимально возможный
объем ПО с заданным интерфейсом, который
может быть реализован программистом
высокой квалификации на языке высокого
уровня.
Следующей
важной метрикой является уровень
программы определяемый как отношение
потенциального объема к объему:
![]()
Далее
вводится работа по программированию
E, как суммарное число
элементарных мысленных различений,
необходимых для генерации программы
ее создателем:
![]()
Следующая
метрика – уровень языка
![]()
— позволяет количественно оценивать
преимущества языка программирования
более высокого уровня по сравнению со
своими предшественниками и определяется
как
![]()
Следовательно:
![]()
; ![]()
В табл.
5 приведены численные значения
для языков разных уровней.
Таблица 5
|
Язык |
|
|
Ассемблер |
0.88 |
|
Фортран |
1,14 |
|
Паскаль |
2,16 |
Еще
одна из метрик, предложенных Холстедом,
позволяет оценивать время затрачиваемое
на разработку ПО:
![]()
где S
– параметр Страуда.
Параметр
Страуда – психофизиологическая
константа, характеризующая время,
необходимое человеческому мозгу для
выполнения элементарной мыслительной
операции («различия» по Холстеду).
Считается, что S лежит в
пределах от 5 до 20 различений в секунду.
Холстед использует значение S=18,
характеризующее процесс программирования
как довольно напряженную умственную
работу.
Можно
оценить относительное уменьшение
времени программирования при переходе
от языка низкого уровня
![]()
к языку высокого уровня
![]()
,
т.е. оценить выигрыш во времени за счет
выбора языка:
![]()
ОЦЕНКА
ЧИСЛА ОСТАВШИХСЯ В ПО ОШИБОК
Согласно
основной гипотезе Холстеда общее число
ожидаемых (переданных пользователю)
Ошибок B в программе
определяется сложностью ее создания,
которую можно характеризовать работой
по программированию E или
объемом программы V:
![]()
С
определением коэффициента пропорциональности
C модель надежности ПО
приобретает законченный вид. Приведем
ход рассуждений М.Холстеда по определению
этой константы.
Холстед
предлагает, что C должна
определяться (быть обратно пропорциональной)
некоторой минимальной работе по
программированию
![]()
,
производимой при создании программы,
содержащей максимум одну ошибку. Другими
словами, C выступает в
роли нормировочного коэффициента.
Теперь необходимо определить тот
минимальный объем работы
,
превышение которого приведет к появлению
ошибки. Для этой цели привлечем на помощь
гипотезу утверждающую, что мозг человека
может обрабатывать в своей памяти
одновременно и безошибочно лишь 5-9
объектов. Взяв нижнюю границу в пять
объектов и добавив результирующий
объект, мы получим минимальное число
![]()
различных входных и выходных параметров
для потенциально безошибочной программы.
Соответствующий потенциальный объем
составит:
![]()
(логических бит)
Итак,
гипотеза ошибок Холстеда утверждает,
что в среднем после обработки 24 битов
абстрактной информации на языке высокого
уровня человек совершает ошибку. Холстед
использует выражение
=2,16 и получает:
=3000.
Следовательно
В=V/300
Это
означает, что на каждые 3000 бит объема V
возможна одна потенциальная ошибка.
Здесь необходимо иметь в виду, что речь
идет не о «физических» битах памяти,
отведенной для размещения ПО в машине,
а о «логических» битах. Следует отметить,
что значение константы C
дает достаточно правдоподобные оценки
только в том случае, если ПО разрабатывалось
с использованием языков высокого уровня.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
10.2. Модели оценки надежности
Из всех областей программной инженерии надежность ПС является самой исследованной областью. Ей предшествовала разработка теории надежности технических средств, оказавшая влияние на развитие надежности ПС. Вопросами надежности ПС занимались разработчики ПС, пытаясь разными системными средствами обеспечить надежность, удовлетворяющую заказчика, а также теоретики, которые, изучая природу функционирования ПС, создали математические модели надежности, учитывающие разные аспекты работы ПС (возникновение ошибок, сбоев, отказов и др.) и позволяющие оценить реальную надежность. В результате надежность ПС сформировалась как самостоятельная теоретическая и прикладная наука [10.5-10.10, 10.16-10.24].
Надежность сложных ПС существенным образом отличается от надежности аппаратуры. Носители данных (файлы, сервер и т.п.) обладают высокой надежностью, записи на них могут храниться длительное время без разрушения, поскольку физическому разрушению они не подвергаются.
С точки зрения прикладной науки надежность — это способность ПС сохранять свои свойства (безотказность, устойчивость и др.), преобразовывать исходные данные в результаты в течение определенного промежутка времени при определенных условиях эксплуатации. Снижение надежности ПС происходит из-за ошибок в требованиях, проектировании и выполнении. Отказы и ошибки зависят от способа производства продукта и появляются в программах при их исполнении на некотором промежутке времени.
Для многих систем (программ и данных) надежность — главная целевая функция реализации. К некоторым типам систем (реального времени, радарные системы, системы безопасности, медицинскоеоборудование со встроенными программами и др.) предъявляются высокие требования к надежности, такие, как отсутствие ошибок, достоверность, безопасность и др.
Таким образом, оценка надежности ПС зависит от числа оставшихся и не устраненных ошибок в программах. В ходе эксплуатации ПС ошибки обнаруживаются и устраняются. Если при исправлении ошибок не вносятся новые или, по крайней мере, новых ошибок вносится меньше, чем устраняется, то в ходе эксплуатации надежность ПС непрерывно возрастает. Чем интенсивнее проводится эксплуатация, тем интенсивнее выявляются ошибки и быстрее растет надежность системы и соответственно ее качество.
Надежность является функцией от ошибок, оставшихся в ПС после ввода его в эксплуатацию. ПС без ошибок является абсолютно надежным. Но для больших программ абсолютная надежность практически недостижима. Оставшиеся необнаруженные ошибки проявляют себя время от времени при определенных условиях (например, при некоторой совокупности исходных данных) сопровождения и эксплуатации системы.
Для оценки надежности ПС используются такие статистические показатели, как вероятность и время безотказной работы, возможность отказа и частота (интенсивность) отказов. Поскольку в качестве причин отказов рассматриваются только ошибки в программе, которые не могут самоустраниться, то ПС следует относить к классу невосстанавливаемых систем.
При каждом проявлении новой ошибки, как правило, проводится ее локализация и исправление. Строго говоря, набранная до этого статистика об отказах теряет свое значение, так как после внесения изменений программа, по существу, является новой программой в отличие от той, которая до этого испытывалась.
В связи с исправлением ошибок в ПС надежность, т.е. ее отдельные атрибуты, будут все время изменяться, как правило, в сторону улучшения. Следовательно, их оценка будет носить временный и приближенный характер. Поэтому возникает необходимость в использовании новых свойств, адекватных реальному процессу измерения надежности, таких, как зависимость интенсивности обнаруженных ошибок от числа прогонов программы и зависимость отказов от времени функционирования ПС и т.п.
К факторам гарантии надежности относятся:
- риск как совокупность угроз, приводящих к неблагоприятным последствиям и ущербу системы или среды;
- угроза как проявление неустойчивости, нарушающей безопасность системы;
- анализ риска — изучение угрозы или риска, их частота и последствия;
- целостность — способность системы сохранять устойчивость работы и не иметь риска;
Риск преобразует и уменьшает свойства надежности, так как обнаруженные ошибки могут привести к угрозе, если отказы носят частотный характер.
10.2.1. Основные понятия в проблематике надежности ПС
Формально модели оценки надежности ПС базируются на теории надежности и математическом аппарате с допущением некоторых ограничений, влияющих на эту оценку. Главным источником информации, используемой в моделях надежности, является процесс тестирования, эксплуатации ПС и разного вида ситуации, возникающие в них. Ситуации порождаются возникновением ошибок в ПС, требуют их устранения для продолжения тестирования.
Базовыми понятиями, которые используются в моделях надежности ПС, являются [10.5-10.10].
Отказ ПC (failure) — это переход ПС из работающего состояния в нерабочее или когда получаются результаты, которые не соответствуют заданным допустимым значениям. Отказ может быть вызван внешними факторами (изменениями элементов среды эксплуатации) и внутренними — дефектами в самой ПС.
Дефект (fault) в ПС — это последствие использования элемента программы, который может привести к некоторому событию, например, в результате неверной интерпретации этого элемента компьютером (как ошибка (fault) в программе) или человеком (ошибка (error) исполнителя). Дефект является следствием ошибок разработчика на любом из процессов разработки — в описании спецификаций требований, начальных или проектных спецификациях, эксплуатационной документации и т.п. Дефекты в программе, не выявленные в результате проверок, являются источником потенциальных ошибок и отказов ПС. Проявление дефекта в виде отказа зависит от того, какой путь будет выполнять специалист, чтобы найти ошибку в коде или во входных данных. Однако не каждый дефект ПС может вызвать отказ или может быть связан с дефектом в ПС или среды. Любой отказ может вызвать аномалию от проявления внешних ошибок и дефектов.
Ошибка (error) может быть следствием недостатка в одном из процессов разработки ПС, который приводит к неправильной интерпретации промежуточной информации, заданной разработчиком или при принятии им неверных решений.
Интенсивность отказов — это частота появления отказов или дефектов в ПС при ее тестировании или эксплуатации.
При выявлении отклонения результатов выполнения от ожидаемых во время тестирования или сопровождения осуществляется поиск, выяснение причин отклонений и исправление связанных с этим ошибок.
Модели оценки надежности ПС в качестве входных параметров используют сведения об ошибках, отказах, их интенсивности, собранных в процессе тестирования и эксплуатации.
10.2.2. Классификация моделей надежности
Как известно, на данный момент времени разработано большое количество моделей надежности ПС и их модификаций. Каждая из этих моделей определяет функцию надежности, которую можно вычислить при задании ей соответствующих данных, собранных во время функционирования ПС. Основными данными являются отказы и время. Другие дополнительные параметры связаны с типом ПС, условиями среды и данных.
Ввиду большого разнообразия моделей надежности разработано несколько подходов к классификации этих моделей. Такие подходы в целом основываются на истории ошибок в проверяемой и тестируемой ПС на этапах ЖЦ. Одной из классификаций моделей надежности ПО является классификация Хетча [10.10]. В ней предлагается разделение моделей на прогнозирующие, измерительные и оценочные (рис. 10.4).
Прогнозирующие модели надежности основаны на измерении технических характеристик создаваемой программы: длина, сложность, число циклов и степень их вложенности, количество ошибок на страницу операторов программы и др.
Например, модель Мотли-Брукса основывается на длине и сложности структуры программы (количество ветвей, циклов, вложенность циклов), количестве и типах переменных, а также интерфейсов. В этих моделях длина программы служит для прогнозирования количества ошибок, например, для 100 операторов программы можно смоделировать интенсивность отказов.
Рис.
10.4.
Классификация моделей надежности
Модель Холстеда прогнозирует количество ошибок в программе в зависимости от ее объема и таких данных, как число операций
( ) и операндов ( ), а также их общее число ( ).
Время программирования программы предлагается вычислять по следующей формуле:
где — число Страуда (Холстед принял равным 18 — число умственных операций в единицу времени).
Объем вычисляется по формуле:
где — максимальное число различных операций.
Измерительные модели предназначены для измерения надежности программного обеспечения,
работающего с заданной внешней средой. Они имеют следующие ограничения:
- программное обеспечение не модифицируется во время периода измерений свойств надежности;
- обнаруженные ошибки не исправляются;
- измерение надежности проводится для зафиксированной конфигурации программного обеспечения.
Типичным примером таких моделей являются модели Нельсона и РамамуртиБастани и др.Модель оценки надежности Нельсона основывается на выполнении k-прогонов программы при тестировании и позволяет определить надежность
где — время выполнения -прогона, и при она интерпретируется как интенсивность отказов.
В процессе испытаний программы на тестовых прогонах оценка надежности вычисляется по формуле
где — число прогонов программы.
Таким образом, данная модель рассматривает полученные количественные данные о проведенных прогонах.
Оценочные модели основываются на серии тестовых прогонов и проводятся на этапах тестирования ПC. В тестовой среде определяется вероятность отказа программы при ее выполнении или тестировании.
Эти типы моделей могут применяться на этапах ЖЦ. Кроме того, результаты прогнозирующих моделей могут использоваться как входные данные для оценочной модели. Имеются модели (например, модель Муссы), которые можно рассматривать как оценочную и в то же время как измерительную модель [10.16, 10.17].
Другой вид классификации моделей предложил Гоэл [10.18, 10.19], согласно которой модели надежности базируются на отказах и разбиваются на четыре класса моделей:
- без подсчета ошибок;
- с подсчетом отказов;
- с подсевом ошибок;
- модели с выбором областей входных значений.
Модели без подсчета ошибок основаны на измерении интервала времени между отказами и позволяют спрогнозировать количество ошибок, оставшихся в программе. После каждого отказа оценивается надежность и определяется среднее время до следующего отказа. К таким моделям относятся модели Джелински и Моранды, Шика Вулвертона и Литвуда-Вералла [10.20, 10.21].
Модели с подсчетом отказов базируются на количестве ошибок, обнаруженных на заданных интервалах времени. Возникновение отказов в зависимости от времени является стохастическим процессом с непрерывной интенсивностью, а количество отказов является случайной величиной. Обнаруженные ошибки, как правило, устраняются и поэтому количество ошибок в единицу времени уменьшается. К этому классу моделей относятся модели Шумана, Шика- Вулвертона, Пуассоновская модель и др. [10.21-10.24].
Модели с подсевом ошибок основаны на количестве устраненных ошибок и подсеве, внесенном в программу искусственных ошибок, тип и количество которых заранее известны. Затем определяется соотношение числа оставшихся прогнозируемых ошибок к числу искусственных ошибок, которое сравнивается с соотношением числа обнаруженных действительных ошибок к числу обнаруженных искусственных ошибок. Результат сравнения используется для оценки надежности и качества программы. При внесении изменений в программу проводится повторное тестирование и оценка надежности. Этот подход к организации тестирования отличается громоздкостью и редко используется из-за дополнительного объема работ, связанных с подбором, выполнением и устранением искусственных ошибок.
Модели с выбором области входных значений основываются на генерации множества тестовых выборок из входного распределения, и оценка надежности проводится по полученным отказам на основе тестовых выборок из входной области. К этому типу моделей относится модель Нельсона и др.
Таким образом, классификация моделей роста надежности относительно процесса выявления отказов, фактически разделена на две группы:
- модели, которые рассматривают количество отказов как марковский процесс;
- модели, которые рассматривают интенсивность отказов как пуассоновский процесс.
Фактор распределения интенсивности отказов разделяет модели на экспоненциальные, логарифмические, геометрические, байесовские и др.
Таблица 1.
|
Название модели |
Формула, обозначение |
|
МЕТРИКИ СЛОЖНОСТИ |
|
|
Метрики Холстеда |
N = n1 log1 n1 + n2 |
|
Метрики Джилба |
L1oop |
|
Метрики Мак-Кейба- цикломатическое число; |
l(G) = m — n + p |
|
Метрика Чепена |
H = 0.5T+P+2M+3C |
|
Метрика Шнадевида |
S = S Pi Ci |
|
Метрика Майерса |
[n 1 ¸ |
|
Метрика Хансена |
{n , N} |
|
Метрика Чена |
M(G) = (n (G), N, Q0) |
|
Метрика Вудворда |
Y x |
|
Метрика Кулика |
Norm (P) |
|
Метрика Хура |
l(G*р) |
|
Метрики Витворфа, Зулевского |
g(Р) |
|
Метрика Петерсона |
Nm 1 0 0 p |
|
Метрики Харрисона, Мэйджела |
f1 = S c 1 |
|
Метрика Пивоварского |
N(G) = n*(G) + S Pi |
|
Метрика Пратта |
Test (Pr) |
|
Метрика Кантоне |
PCN* |
|
Метрика Мак-Клура |
C(V) = D(V) ´ J(V) / N |
|
Метрика Кафура |
I(G) |
|
Метрика Схуттса, Моханти |
e (G) |
|
Метрика Коллофело |
h (G) |
|
Метрика Зольновского, Симмонса, Тейера |
å (a å (c |
|
Метрика Берлингера |
I(R) = m (F* (R) ´ F—(R))2 |
|
Метрика Шумана |
X (Y) |
|
Метрика Янгера |
L (w |
|
ПРОГНОЗ МОДЕЛИ |
|
|
Модели Холстеда |
P=3/8 (Ra — 1) ´ |
|
ОЦЕНОЧНЫЕ МОДЕЛИ |
|
|
Джелински — Моранды |
R(t) = e — (Т — 1 + 1) Ft |
|
Вейса-Байеса |
R1 (t) = ò |
|
Шика-Волвертона |
R1 (t) = e — F( N — 1 + 1) ti2 / 2 |
|
Литтлвуда |
R1 (t) = (b+t/b+t +t)— F(N — i + 1) a |
|
Нельсона |
Rj (t) = exp { åln (1 — Pj)} |
|
Халецкого |
Rj (t) = Pµ— a(1- g nj ) / nj |
|
Модель отлаженности |
Rj (t) =Pµ— r fj (t,l ,p) |
|
Мозаичная модель |
Rj (t) = 1 — b( a — wj — 1) |