From Wikipedia, the free encyclopedia
An error correction model (ECM) belongs to a category of multiple time series models most commonly used for data where the underlying variables have a long-run common stochastic trend, also known as cointegration. ECMs are a theoretically-driven approach useful for estimating both short-term and long-term effects of one time series on another. The term error-correction relates to the fact that last-period’s deviation from a long-run equilibrium, the error, influences its short-run dynamics. Thus ECMs directly estimate the speed at which a dependent variable returns to equilibrium after a change in other variables.
History[edit]
Yule (1926) and Granger and Newbold (1974) were the first to draw attention to the problem of spurious correlation and find solutions on how to address it in time series analysis.[1][2] Given two completely unrelated but integrated (non-stationary) time series, the regression analysis of one on the other will tend to produce an apparently statistically significant relationship and thus a researcher might falsely believe to have found evidence of a true relationship between these variables. Ordinary least squares will no longer be consistent and commonly used test-statistics will be non-valid. In particular, Monte Carlo simulations show that one will get a very high R squared, very high individual t-statistic and a low Durbin–Watson statistic. Technically speaking, Phillips (1986) proved that parameter estimates will not converge in probability, the intercept will diverge and the slope will have a non-degenerate distribution as the sample size increases.[3] However, there might be a common stochastic trend to both series that a researcher is genuinely interested in because it reflects a long-run relationship between these variables.
Because of the stochastic nature of the trend it is not possible to break up integrated series into a deterministic (predictable) trend and a stationary series containing deviations from trend. Even in deterministically detrended random walks spurious correlations will eventually emerge. Thus detrending does not solve the estimation problem.
In order to still use the Box–Jenkins approach, one could difference the series and then estimate models such as ARIMA, given that many commonly used time series (e.g. in economics) appear to be stationary in first differences. Forecasts from such a model will still reflect cycles and seasonality that are present in the data. However, any information about long-run adjustments that the data in levels may contain is omitted and longer term forecasts will be unreliable.
This led Sargan (1964) to develop the ECM methodology, which retains the level information.[4][5]
Estimation[edit]
Several methods are known in the literature for estimating a refined dynamic model as described above. Among these are the Engle and Granger 2-step approach, estimating their ECM in one step and the vector-based VECM using Johansen’s method.[6]
Engle and Granger 2-step approach[edit]
The first step of this method is to pretest the individual time series one uses in order to confirm that they are non-stationary in the first place. This can be done by standard unit root DF testing and ADF test (to resolve the problem of serially correlated errors).
Take the case of two different series 

If they are both integrated to the same order (commonly I(1)), we can estimate an ECM model of the form

If both variables are integrated and this ECM exists, they are cointegrated by the Engle–Granger representation theorem.
The second step is then to estimate the model using ordinary least squares:
If the regression is not spurious as determined by test criteria described above, Ordinary least squares will not only be valid, but in fact super consistent (Stock, 1987).
Then the predicted residuals 

One can then test for cointegration using a standard t-statistic on 
While this approach is easy to apply, there are, however numerous problems:
VECM[edit]
The Engle–Granger approach as described above suffers from a number of weaknesses. Namely it is restricted to only a single equation with one variable designated as the dependent variable, explained by another variable that is assumed to be weakly exogeneous for the parameters of interest. It also relies on pretesting the time series to find out whether variables are I(0) or I(1). These weaknesses can be addressed through the use of Johansen’s procedure. Its advantages include that pretesting is not necessary, there can be numerous cointegrating relationships, all variables are treated as endogenous and tests relating to the long-run parameters are possible. The resulting model is known as a vector error correction model (VECM), as it adds error correction features to a multi-factor model known as vector autoregression (VAR). The procedure is done as follows:
- Step 1: estimate an unrestricted VAR involving potentially non-stationary variables
- Step 2: Test for cointegration using Johansen test
- Step 3: Form and analyse the VECM.
An example of ECM[edit]
The idea of cointegration may be demonstrated in a simple macroeconomic setting. Suppose, consumption 





In this setting a change 




This structure is common to all ECM models. In practice, econometricians often first estimate the cointegration relationship (equation in levels), and then insert it into the main model (equation in differences).
References[edit]
- ^ Yule, Georges Udny (1926). «Why do we sometimes get nonsense correlations between time series? – A study in sampling and the nature of time-series». Journal of the Royal Statistical Society. 89 (1): 1–63. JSTOR 2341482.
- ^ Granger, C.W.J.; Newbold, P. (1978). «Spurious regressions in Econometrics». Journal of Econometrics. 2 (2): 111–120. JSTOR 2231972.
- ^ Phillips, Peter C.B. (1985). «Understanding Spurious Regressions in Econometrics» (PDF). Cowles Foundation Discussion Papers 757. Cowles Foundation for Research in Economics, Yale University.
- ^ Sargan, J. D. (1964). «Wages and Prices in the United Kingdom: A Study in Econometric Methodology», 16, 25–54. in Econometric Analysis for National Economic Planning, ed. by P. E. Hart, G. Mills, and J. N. Whittaker. London: Butterworths
- ^ Davidson, J. E. H.; Hendry, D. F.; Srba, F.; Yeo, J. S. (1978). «Econometric modelling of the aggregate time-series relationship between consumers’ expenditure and income in the United Kingdom». Economic Journal. 88 (352): 661–692. JSTOR 2231972.
- ^ Engle, Robert F.; Granger, Clive W. J. (1987). «Co-integration and error correction: Representation, estimation and testing». Econometrica. 55 (2): 251–276. JSTOR 1913236.
Further reading[edit]
- Dolado, Juan J.; Gonzalo, Jesús; Marmol, Francesc (2001). «Cointegration». In Baltagi, Badi H. (ed.). A Companion to Theoretical Econometrics. Oxford: Blackwell. pp. 634–654. doi:10.1002/9780470996249.ch31. ISBN 0-631-21254-X.
- Enders, Walter (2010). Applied Econometric Time Series (Third ed.). New York: John Wiley & Sons. pp. 272–355. ISBN 978-0-470-50539-7.
- Lütkepohl, Helmut (2006). New Introduction to Multiple Time Series Analysis. Berlin: Springer. pp. 237–352. ISBN 978-3-540-26239-8.
- Martin, Vance; Hurn, Stan; Harris, David (2013). Econometric Modelling with Time Series. New York: Cambridge University Press. pp. 662–711. ISBN 978-0-521-13981-6.
тип модели временного ряда
Модель коррекции ошибок (ECM) принадлежит к Категория нескольких моделей временных рядов , наиболее часто используемых для данных, в которых базовые переменные имеют долгосрочный стохастический тренд, также известный как коинтеграция. ECM — это теоретически обоснованный подход, полезный для оценки как краткосрочного, так и долгосрочного воздействия одного временного ряда на другой. Термин «исправление ошибок» относится к тому факту, что отклонение последнего периода от долгосрочного равновесия, ошибка, влияет на его краткосрочную динамику. Таким образом, ECM напрямую оценивают скорость, с которой зависимая переменная возвращается в состояние равновесия после изменения других переменных.
Содержание
- 1 История ECM
- 2 Оценка
- 2.1 Двухэтапный подход Энгла и Грейнджера
- 2.2 VECM
- 2.3 Пример ECM
- 3 Ссылки
- 4 Далее чтение
История ECM
Юл (1926) и Грейнджер и Ньюболд (1974) первыми привлекли внимание к проблеме ложной корреляции и нашли решения, как ее решить. в анализе временных рядов. Учитывая два совершенно несвязанных, но интегрированных (нестационарных) временных ряда, регрессионный анализ одного из другого будет иметь тенденцию давать явно статистически значимую взаимосвязь, и, таким образом, исследователь может ошибочно полагать, что нашел доказательства существования истинная взаимосвязь между этими переменными. Обычный метод наименьших квадратов больше не будет согласованным, а часто используемая тестовая статистика будет недействительной. В частности, моделирования Монте-Карло показывают, что можно получить очень высокий R в квадрате, очень высокий индивидуальный t-статистический и низкий Дарбина – Ватсона. статистика. С технической точки зрения Филлипс (1986) доказал, что оценки параметров не будут сходиться по вероятности, точка пересечения будет расходиться, а наклон будет иметь невырожденное распределение по мере увеличения размера выборки. Однако может существовать общий стохастический тренд для обоих рядов, который искренне интересует исследователя, поскольку он отражает долгосрочную взаимосвязь между этими переменными.
Из-за стохастического характера тренда невозможно разбить интегрированный ряд на детерминированный (предсказуемый) тренд и стационарный ряд, содержащий отклонения от тренда. Даже при детерминированном удалении тренда случайных блужданий в конечном итоге возникнут ложные корреляции. Таким образом, детрендирование не решает проблему оценки.
Чтобы по-прежнему использовать подход Бокса – Дженкинса, можно было бы различать ряды, а затем оценивать такие модели, как ARIMA, учитывая, что многие часто используемые временные ряды ( например, в экономике) кажутся стационарными в первых разностях. Прогнозы на основе такой модели по-прежнему будут отражать циклы и сезонность, которые присутствуют в данных. Однако любая информация о долгосрочных корректировках, которую могут содержать данные в уровнях, опускается, и долгосрочные прогнозы будут ненадежными.
Это привело Саргана (1964) к разработке методологии ECM, которая сохраняет информацию об уровне.
Оценка
В литературе известно несколько методов. для оценки уточненной динамической модели, как описано выше. Среди них двухэтапный подход Энгла и Грейнджера, оценивающий их ECM за один этап, и векторный VECM с использованием метода Йохансена.
двухэтапного подхода Энгла и Грейнджера
Первый этап этот метод заключается в предварительном тестировании отдельных временных рядов, которые используются, чтобы подтвердить, что они нестационарны в первую очередь. Это можно сделать с помощью стандартного модульного корневого тестирования DF и теста ADF (для решения проблемы серийно коррелированных ошибок). Возьмем случай двух разных серий x t { displaystyle x_ {t}}
Если они оба интегрированы в одном порядке (обычно I (1)), мы можем оценить модель ECM в виде
- A (L) Δ yt = γ + B (L) Δ xt + α (yt — 1 — β 0 — β 1 xt — 1) + ν t. { Displaystyle A (L) , Delta y_ {t} = gamma + B (L) , Delta x_ {t} + alpha (y_ {t-1} — beta _ {0} — beta _ {1} x_ {t-1}) + nu _ {t}.}
Если обе переменные интегрированы и этот ECM существует, они коинтегрируются теоремой Энгла – Грейнджера о представлении.
Затем на втором этапе оценивается модель с помощью обычных наименьших квадратов : yt = β 0 + β 1 xt + ε t { displaystyle y_ {t} = beta _ {0} + beta _ {1} x_ {t} + varepsilon _ {t}}
- A (L) Δ yt = γ + B (L) Δ xt + α ε ^ t — 1 + ν t. { Displaystyle A (L) , Delta y_ {t} = gamma + B (L) , Delta x_ {t} + alpha { hat { varepsilon}} _ {t-1} + nu _ {t}.}
Затем можно протестировать коинтеграцию, используя стандартную t-статистику на α { displaystyle alpha}
VECM
Энгл-Грейнджер описанный выше подход имеет ряд недостатков. А именно, он ограничен только одним уравнением с одной переменной, обозначенной как зависимая переменная, объясненной другой переменной, которая, как предполагается, является слабо экзогенной для интересующих параметров. Он также основан на предварительном тестировании временных рядов, чтобы выяснить, являются ли переменные I (0) или I (1). Эти недостатки могут быть устранены с помощью процедуры Йохансена. Его преимущества заключаются в том, что в предварительном тестировании нет необходимости, может быть множество коинтегрирующих взаимосвязей, все переменные рассматриваются как эндогенные, и возможны тесты, относящиеся к долгосрочным параметрам. Полученная модель известна как модель векторной коррекции ошибок (VECM), поскольку она добавляет функции коррекции ошибок в многофакторную модель, известную как векторная авторегрессия (VAR). Процедура выполняется следующим образом:
- Шаг 1: оценка неограниченной VAR, включающей потенциально нестационарные переменные
- Шаг 2: Тест на коинтеграцию с использованием теста Йохансена
- Шаг 3: Сформировать и проанализировать VECM.
Пример ECM
Идея коинтеграции может быть продемонстрирована в простых макроэкономических условиях. Предположим, потребление C t { displaystyle C_ {t}}
В этой настройке изменение Δ C t = C t — C t — 1 { displaystyle Delta C_ {t} = C_ {t} -C_ {t-1}}
Эта структура является общей для всех моделей ECM. На практике эконометристы часто сначала оценивают взаимосвязь коинтеграции (уравнение в уровнях), а затем вставляют его в основную модель (уравнение в разностях).
Ссылки
Дополнительная литература
- Dolado, Juan J.; Гонсало, Хесус; Мармол, Франсеск (2001). «Коинтеграция». В Балтаги, Бади Х. (ред.). Компаньон теоретической эконометрики. Оксфорд: Блэквелл. Стр. 634 –654. doi : 10.1002 / 9780470996249.ch31. ISBN 0-631-21254-X.
- Эндерс, Уолтер (2010). Прикладные эконометрические временные ряды (Третье изд.). Нью-Йорк: Джон Вили и сыновья. С. 272–355. ISBN 978-0-470-50539-7.
- Lütkepohl, Helmut (2006). Новое введение в анализ множественных временных рядов. Берлин: Springer. Стр. 237 –352. ISBN 978-3-540-26239-8.
- Мартин, Вэнс; Херн, Стэн; Харрис, Дэвид (2013). Эконометрическое моделирование с использованием временных рядов. Нью-Йорк: Издательство Кембриджского университета. С. 662–711. ISBN 978-0-521-13981-6.
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
15 |
||||||||||||||||
|
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||||||||
|
C(2) |
1.014411 |
0.020750 |
48.88608 |
0.0000 |
|||||||||||||
|
C(3) |
0.702102 |
0.078268 |
8.970448 |
0.0000 |
|||||||||||||
|
т.е. yt |
= 1.014 yt – 1 + 0.702 (xt – 1.014 xt – 1) + e t , или |
||||||||||||||||
|
yt |
= 1.014 yt – 1 + 0.702 xt |
– 0.712 xt – 1 + e t |
Отметим близость результатов, полученных тремя методами:
|
yt = |
1.005 yt – 1 + 0.695 xt |
– 0.707 xt – 1 + et |
(метод 1), |
|
yt = |
yt – 1 + 0.710 xt |
– 0.710 xt – 1 + et |
(метод 2), |
|
yt = |
1.014 yt – 1 + 0.702 xt |
– 0.712 xt – 1 + e t |
(метод 3). |
Фактически, во всех трех случаях воспроизводится одна и та же линейная модель связи между рядами разностей:
∆yt = 0.7 ∆xt + et .
Эта регрессионная связь между продифференцированными рядами не является ложной (в отличие от регрессионной связи между рядами уровней): статистика Дарбина – Уотсона принимает значение 1.985; P-значение критерия Jarque – Bera равно 0.344.
Замечание
В связи с результатами, полученными при рассмотрении последних примеров, естественно возникает следующий вопрос, который поднимался в свое время различными исследователями. Не будет ли разумным, имея дело с рядами, траектории которых обнаруживают выраженный тренд, сразу приступать к оцениванию связей между рядами разностей (между продифференцированными рядами) ?
Против некритичного использования такого подхода говорят два обстоятельства:
(a)Если ряды в действительности стационарны относительно детерминированного тренда, то тогда дифференцирование приводит к
передифференцированным рядам, имеющим необратимую MA
составляющую.
(b)Если ряды являются интегрированными порядка 1 и при этом коинтегрированы, то при переходе к продифференцированным рядам теряется информация о долговременной связи между уровнями этих рядов.
Дифференцирование рядов оправданно и полезно, если ряды являются интегрированными, но при этом между ними отсутствует коинтеграционная связь.
Пусть yt ~ I(1), xt ~ I(0). Строить регрессию yt на xt в этом случае бессмысленно, т.к. для любых a и b в такой ситуации
yt – a – b xt ~ I(1).
Пусть, наоборот, yt ~ I(0), xt ~ I(1). Для любых a и b ≠ 0 здесь опять yt – a – b xt ~ I(1),
и только при b = 0 получаем yt – a – b xt ~ I(0),
так что и в таком сочетании строить регрессию одного ряда на другой не имеет смысла.
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
16 |
|
|
Пусть теперь yt ~ I(1), |
xt ~ I(1) – два интегрированных ряда. |
|
|
Если для любого b |
||
|
yt – b xt ~ I(1), |
||
|
то регрессия yt на |
xt является фиктивной, и мы уже выяснили, как следует |
действовать в такой ситуации.
Обратимся теперь к случаю, когда при некотором b ≠ 0 yt – b xt ~ I(0) – стационарный ряд.
Если это так, то ряды yt и xt называют коинтегрированными рядами, а вектор (1, – b)T – коинтегрирующим вектором.
Вообще, ряды yt ~ I(1), xt ~ I(1) называют коинтегрированными (в узком смысле – детерминистская коинтеграция), если существует ненулевой (коинтегрирующий)
вектор β = (β1, β2)T ≠ 0 , для которого
β1 xt + β2 yt ~ I(0) – стационарный ряд.
Заметим, что если вектор β = (β1, β2)T является коинтегрирующим вектором для рядов xt и yt , то тогда коинтегрирующим для этих рядов будет и любой вектор вида сβ = (сβ1, сβ2)T , где с ≠ 0 – постоянная величина. Чтобы выделить какой-то определенный вектор, приходится вводить условие нормировки, например, рассматривать только векторы вида (1, – b)T (или только векторы (– a, 1)T ).
Поскольку мы предполагаем сейчас, что xt , yt ~ I(1), то ряды разностей ∆xt , ∆yt стационарны. Будем предполагать в дополнение, что стационарен векторный ряд (∆xt , ∆yt)T , так что для него существует разложение Вольда в виде скользящего среднего
(∆xt , ∆yt)T = µ + B(L) εt ,
где
µ = (µ 1, µ 2 )T , µ 1 = E(∆xt ) , µ 2 = E(∆yt) ;
εt = (ε1t , ε2t )T – векторный белый шум,
т.е.
|
ε 1, ε 2 , … |
– последовательность не коррелированных между собой, одинаково |
||||||||
|
распределенных случайных векторов, для которых |
|||||||||
|
E(εt) = (0, 0)T , |
D(ε1t) = σ12 , D(ε2t) = σ22 , Cov(ε1t , ε2t ) = σ12 – постоянные величины; |
||||||||
|
1 |
0 |
∞ b |
(k ) |
b |
(k ) |
k |
|||
|
11 |
12 |
L |
. |
||||||
|
B(L) = |
0 |
1 |
+∑ |
b |
(k ) |
b |
(k ) |
||
|
k =1 |
|||||||||
|
21 |
22 |
Знаменитый результат Гренджера ([Granger (1983)], см. также [Engle, Granger (1987)])
состоит в том, что в случае коинтегрированности I(1) рядов xt и yt (в узком смысле)
|
(I) |
В разложении Вольда (∆xt , ∆yt)T = µ + B(L) εt матрица B(1) имеет ранг 1. |
|
(II)Система рядов xt и yt допускает векторное ARMA представление |
A(L) (xt, yt )T = c + d(L)εt ,
в котором
εt – тот же векторный белый шум, что и в (I), c = (c1, c2)T , c1 и c2 – постоянные,
A(L) – матричный полином от оператора запаздывания, d(L) – скалярный полином от оператора запаздывания, причем
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
17 |
A(0) = I2 (единичная матрица размера 2×2), rank A(1) = 1 (ранг 2×2-матрицы A(1) равен 1),
значение d(1) конечно.
Всвязи с тем, что в последнем представлении ранг (2×2)-матрицы A(1) меньше двух, об этом представлении часто говорят как о векторной авторегрессии пониженного ранга (reduced rank VAR).
Вразвернутой форме представление (II) имеет вид
|
p |
q |
|||||||||||||||
|
xt =c1 + |
∑(a1j xt − j +b1j yt − j )+ |
∑θkε1,t − k , |
||||||||||||||
|
j =1 |
k = 0 |
|||||||||||||||
|
p |
(a |
)+ |
q θ |
|||||||||||||
|
y |
t |
=c |
2 |
+ |
2 j |
x |
t − j |
+b |
y |
t − j |
ε |
2,t − k |
||||
|
∑ |
2 j |
∑ k |
||||||||||||||
|
j =1 |
k = 0 |
При этом верхние пределы p и q у сумм в правых частях могут быть бесконечными.
Если возможно векторное AR представление, то в нем d(L) ≡ 1 , p < ∞ .
|
(III) |
Система рядов xt и yt допускает представление в форме модели |
||
|
коррекции ошибок (error correction model – ECM) |
|||
|
∆xt =µ1 +α1zt −1 +∑∞ (γ 1j ∆xt − j +δ1j ∆yt − j )+ ∑∞ θkε1,t − k , |
|||
|
j =1 |
k = 0 |
||
|
∆yt = µ2 +α2 zt −1 +∑∞ (γ 2 j ∆xt − j +δ 2 j ∆yt − j )+ ∑∞ θkε2,t − k , |
|||
|
j =1 |
k = 0 |
||
|
где |
|||
|
zt = yt – β xt – E(yt – β xt) |
– стационарный ряд с нулевым |
математическим |
|
|
ожиданием, |
zt ~ I(0),
и
α12 + α22 > 0.
Если в (II) возможно векторное AR(p) представление (p < ∞), то тогда ECM принимает вид
∆xt =µ1 +α1zt −1 +∑p −1(γ 1j ∆xt − j +δ1j ∆yt − j ) +ε1,t , j =1
∆yt = µ2 +α2 zt −1 +∑p −1(γ 2 j ∆xt − j +δ 2 j ∆yt − j )+ε2,t , j =1
Здесь важно отметить следующее:
•Если ряды xt , yt ~ I(1) коинтегрированы, то все составляющие в ECM стационарны.
•Если векторный ряд (xt , yt)T ~ I(1) (так что векторный ряд (∆xt , ∆yt)T стационарен) и порождается ECM моделью, то ряды xt и yt коинтегрированы. (Действительно, в этом случае все составляющие ECM, отличные от zt–1, стационарны; но тогда стационарна и zt – 1.)
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
18 |
• Если ряды xt , yt ~ I(1) коинтегрированы, то тогда VAR в разностях не может иметь конечный порядок. (В отличие от случая, когда ряды xt и yt не коинтегрированы.)
|
Абсолютную величину zt = yt – α – β xt , где α = E(yt – β xt), |
можно рассматривать как |
|
|
расстояние, отделяющее систему в |
момент t от |
равновесия, задаваемого |
|
соотношением yt – α – β xt = 0. |
Величины и направления изменений xt и yt |
принимают во внимание величину и знак предыдущего отклонения от равновесия zt – 1 . Ряд zt , конечно, вовсе не обязательно убывает по абсолютной величине при переходе от одного периода времени к другому, но он является стационарным рядом, и поэтому расположен к движению по направлению к своему среднему.
Замечание 1
Переменная xt не является причиной по Гренджеру для переменной yt , если неучет прошлых значений переменной xt не приводит к ухудшению качества прогноза значения yt по совокупности прошлых значений этих двух переменных. Переменная yt не является причиной по Гренджеру для переменной xt , если неучет прошлых значений переменной yt не приводит к ухудшению качества прогноза значения xt по совокупности прошлых значений этих двух переменных. (Качество прогноза измеряется среднеквадратичной ошибкой прогноза.)
Если xt , yt ~ I(1) и коинтегрированы, то должна иметь место причинность по Гренджеру , по крайней мере, в одном направлении. Этот факт вытекает из представления такой системы рядов в форме ECM, в которой α12 + α22 > 0. Значение xt
– 1 через посредство zt– 1 помогает в прогнозировании значения yt (т.е. переменная xt является причиной по Гренджеру для переменной yt), если α2 ≠ 0. Значение yt – 1 через посредство zt– 1 помогает в прогнозировании значения xt (т.е. переменная yt является причиной по Гренджеру для переменной xt), если α1 ≠ 0.
Замечание 2
Пусть xt , yt ~ I(1) коинтегрированы и wt ~ I(0). Тогда для любого k коинтегрированы ряды xt и γ yt – k + wt , γ ≠ 0. Формально, если xt ~ I(1), то коинтегрированы ряды xt
и xt – k . (Действительно, тогда xt – xt – k = ∆xt + ∆xt – 1 + … + ∆xt – k – сумма I(0)- переменных, которая также является I(0)-переменной.)
Итак, при коинтегрированности рядов xt , yt ~ I(1) мы имеем
|
• |
модель долговременной (равновесной) связи yt = α + β xt ; |
•модель краткосрочной динамики в форме ECM,
иэти модели согласуются друг с другом.
Проблема, однако, состоит в том, что для построения ECM по реальным статистическим данным нам надо знать коинтегрирующий вектор (в данном случае, знать значение β). Хорошо, если этот вектор определяется экономической теорией. К сожалению, чаще его приходится оценивать по имеющимся данным.
Энгл и Гренджер [Engle, Granger (1987)] рассмотрели двухшаговую процедуру, в которой на первом шаге значения α и β оцениваются в рамках модели регрессии yt на xt
yt = α + β xt + ut .
Получив методом наименьших квадратов оценки αˆ и βˆ (НK-оценки), мы тем самым находим оцененные значения отклонений от положения равновесия
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
19 |
zˆt = yt – αˆ – βˆ xt
– это просто остатки от оцененной регрессии.
После этого, на втором шаге, методом наименьших квадратов раздельно (не как система!) оцениваются уравнения
∆xt =µ1 +α1zˆt −1 +∑p −1(γ 1j ∆xt − j +δ1j ∆yt − j ) +ν t , j =1
∆yt = µ2 +α2 zˆt −1 + ∑p −1(γ 2 j ∆xt − j +δ 2 j ∆yt − j ) +wt , j =1
(т.е. предполагается модель VAR(p) для xt , yt).
Определяющим в этой процедуре является то обстоятельство, что получаемая на первом шаге оценка βˆ быстрее обычного приближается (по вероятности) к истинному
значению β – второй компоненте коинтегрирующего вектора (1, β)T . ( βˆ является суперсостоятельной оценкой для β .) Это, в конечном счете, приводит к тому, что оценки в отдельном уравнении ECM, использующие оцененные значения zt−1 , имеют то же самое асимптотическое распределение, что и оценка максимального правдоподобия, использующая истинные значения zt−1 . (Обычно это асимптотически
нормальное распределение.) При этом НК-оценки стандартных ошибок всех коэффициентов являются состоятельными оценками истинных стандартных ошибок.
Заметим, что последние результаты справедливы несмотря на то, что ряд оцененных значений zˆt формально не является стационарным, поскольку βˆ ≠ β.
Отметим также, что если мы хотим использовать другую нормировку коинтегрирующего вектора в виде (β, 1)T , то нам придется оценивать регрессию xt на константу и yt , и это приведет к вектору, не пропорциональному вектору, оцененному в первом случае.
Замечание
|
ˆ |
|
|
Тот факт, что β |
быстрее обычного сходится (по вероятности) к β , вовсе не |
означает,что мы можем пользоваться на первом шаге процедуры Энгла – Гренджера обычными регрессионными критериями. Дело в том, что получаемые на первом шаге оценки и статистики, вообще говоря, имеют нестандартные асимптотические распределения.
Однако первый шаг является в данном контексте вспомогательным, и на этом шаге нет необходимости обращать внимание на сообщаемые в протоколах соответствующих пакетов программ значения статистик.
Напротив, на втором шаге мы можем использовать обычные статистические процедуры (разумеется, если количество наблюдений не мало и если коинтеграция имеется).
Пример Расмотрим реализацию процесса порождения данных
DGP: xt = xt – 1 + εt , yt = 2 xt + νt ,
где x1 = 0, а εt и νt – порождаемые независимо друг от друга последовательности независимых, одинаково распределенных случайных величин, имеющих стандартное
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
20 |
|||||||||||
|
нормальное распределение |
N(0, |
1). Графики полученных реализаций рядов |
xt |
и |
yt |
|||||||
|
имеют следующий вид |
||||||||||||
|
10 |
||||||||||||
|
0 |
||||||||||||
|
-10 |
||||||||||||
|
-20 |
||||||||||||
|
-30 |
||||||||||||
|
-40 |
||||||||||||
|
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
100 |
|||
|
Y |
X |
Пара (xt , yt) образует векторный процесс авторегрессии
xt = xt – 1 + εt , yt = 2 xt – 1 + ηt ,
где ηt = νt + 2εt ~ i.i.d. N(0, 5).
В форме ECM пара уравнений принимает вид
∆xt = εt ,
∆yt = – (yt – 1 – 2 xt – 1) + ηt = – zt + где zt = yt – 2 xt ,
или
∆xt = α1 zt – 1 + εt ,
∆yt = α2 zt – 1 + ηt ,
где α1 = 0, α2 = – 1, так что α12
На практике, приступая к анализу статистических данных, исследователь не знает точно, какой порядок имеет VAR в DGP. Имея это в виду, выберем для оценивания в качестве статистической модели ECM в виде
∆xt = α1 zt – 1 + γ11∆xt – 1 + δ11∆yt – 1 + vt ,
∆yt = α2 zt – 1 + γ21∆xt – 1 + δ21∆yt – 1 + wt ,
допуская, что данные порождаются моделью векторной авторегрессии второго порядка (p = 2). Для анализа используем 100 наблюдений.
(I шаг) Исходим из модели yt = α + β xt + ut . Оцененная модель:
|
Dependent Variable: Y |
||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
C |
-0.006764 |
0.165007 |
-0.040992 |
0.9674 |
|
X |
1.983373 |
0.020852 |
95.11654 |
0.0000 |
|
R-squared |
0.989284 |
Durbin-Watson stat |
2.217786 |
т.е.
yt = – 0.006764 + 1.983373 xt + uˆt ,
так что
zˆt = uˆt = yt + 0.006764 – 1.983373 xt .
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
21 |
Допустив, что VAR имеет порядок 2, при использовании критерия Дики – Фуллера для проверки рядов yt и xt на коинтегрированность в правую часть уравнения включаем одну запаздывающую разность:
∆zˆt = φ zˆt−1 + θ1∆zˆt−1 + ζt . ,
Оценивая последнее уравнение получаем:
Augmented Dickey-Fuller Test Equation Dependent Variable: D(Z) Sample(adjusted): 3 100
Included observations: 98 after adjusting endpoints
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-1.153515 |
0.151497 |
-7.614088 |
0.0000 |
||||||||
|
D(Z(-1)) |
0.038156 |
0.100190 |
0.380837 |
0.7042 |
||||||||
Полученное значение тестовой статистики tφ = – 7.614 намного ниже 5% критического уровня –3.396 (см. [Patterson (2000), таблица 8.7]). Гипотеза некоинтегрированности рассматриваемых рядов уверенно отвергается. (Ввиду статистической незначимости коэффициента при запаздывающей разности, можно было бы переоценить модель, не включая запаздывающую разность в правую часть уравнения. Это дало бы значение tφ = – 11.423, при котором гипотеза некоинтегрированности отвергается еще более уверенно.)
Таким образом, мы принимаем решение о коинтегрированности рядов yt и xt , и переходим к построению модели коррекции ошибок.
(Шаг II) Сначала отдельно оцениваем уравнение для ∆xt :
|
Dependent Variable: D(X) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
C |
-0.028016 |
0.100847 |
-0.277810 |
0.7818 |
||||||||
|
Z(-1) |
0.250942 |
0.176613 |
1.420858 |
0.1587 |
||||||||
|
D(X(-1)) |
0.639967 |
0.257823 |
2.482201 |
0.0148 |
||||||||
|
D(Y(-1)) |
-0.258740 |
0.116654 |
-2.218019 |
0.0290 |
||||||||
Поочередное исключение из правой части уравнения переменных со статистически незначимыми коэффициентами и наибольшим P-значением приводит к оцененной модели
|
Dependent Variable: D(X) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
D(X(-1)) |
0.115141 |
0.100249 |
1.148554 |
0.2536 |
||||||||
и, в конечном счете, к модели
∆xt = νt ,
которая и была использована при порождении ряда xt . Оценивая теперь уравнение для ∆yt , получаем
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
C |
-0.060101 |
0.211899 |
-0.283630 |
0.7773 |
||||||||
|
Z(-1) |
-0.641060 |
0.371097 |
-1.727472 |
0.0874 |
||||||||
|
D(X(-1)) |
1.313872 |
0.541733 |
2.425311 |
0.0172 |
||||||||
|
D(Y(-1)) |
-0.482981 |
0.245111 |
-1.970459 |
0.0517 |
||||||||
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
22 |
Исключая из правой части оцениваемого уравнения константу, получаем:
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-0.638888 |
0.369218 |
-1.730381 |
0.0868 |
||||||||
|
D(X(-1)) |
1.317763 |
0.538932 |
2.445138 |
0.0163 |
||||||||
|
D(Y(-1)) |
-0.483722 |
0.243908 |
-1.983217 |
0.0502 |
||||||||
Хотя формально здесь следовало бы начать исключение статистически незначимых переменных с zˆt −1 , мы должны принять во внимание уже принятое решение о
коинтегрированности рядов yt и xt . Но если эти ряды действительно коинтегрированы, то в ECM должно выполняться соотношение α12 + α22 > 0. Поскольку же переменная zt – 1 не вошла в правую часть уравнения для ∆xt , она должна оставаться в правой части уравнения для ∆yt . Если начать исключение с переменной ∆yt – 1 , то в оцененном редуцированном уравнении
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-1.186411 |
0.248876 |
-4.767072 |
0.0000 |
||||||||
|
D(X(-1)) |
0.331411 |
0.210732 |
1.572671 |
0.1191 |
||||||||
статистически незначим коэффициент при ∆xt – 1 , что приводит нас к уравнению ∆yt = α2 zˆt−1 + wt , оценивая которое, получаем
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-1.273584 |
0.247887 |
-5.137760 |
0.0000 |
||||||||
Проверка гипотезы H0: α2 = – 1 дает:
|
Null Hypothesis: |
C(1)= -1 |
|||||||||
|
F-statistic |
1.218077 |
Probability |
0.272441 |
|||||||
|
Chi-square |
1.218077 |
Probability |
0.269738 |
|||||||
Поскольку эта гипотеза не отвергается, мы можем остановиться на модели ECM
∆xt = εt , ∆yt = – zˆt−1 + wt ,
где
zˆt−1 = yt – 1 + 0.006764 – 1.983373 xt – 1 .
Подстановка последнего выражения для zˆt−1 в уравнение для ∆yt приводит к соотношению
yt = – 0.0068 + 1.983 xt – 1 + wt ,
которое близко к соотношению yt = 2 xt – 1 + ηt ,
соответствующему использованному DGP.
Заметим, наконец, что последовательность wt = ∆yt + zˆt−1 идентифицируется по
наблюдаемой ее реализации как гауссовский белый шум с оцененной дисперсией 4.62 (использованному DGP соответствует значение 5.00), а последовательность εt = ∆xt идентифицируется как гауссовский белый шум с оцененной дисперсией 1.04 (использованному DGP соответствует значение 1.00).
Оценив ECM и остановившись на модели
∆xt = εt , ∆yt = – zˆt−1 + wt ,
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
23 |
мы тем самым обнаруживаем, что коррекция производится только в отношении ряда yt : при положительных zˆt−1 , т.е. при
yt– 1 – (– 0.0068 + 1.983 xt – 1) > 0,
в правой части уравнения для ∆yt корректирующая составляющая – zˆt−1 отрицательна и действует в сторону уменьшения приращения переменной yt . Напротив, при отрицательных zˆt−1 корректирующая составляющая действует в сторону увеличения приращения переменной yt .
Прошлые значения переменной xt через посредство zˆt−1 помогают в прогнозировании
значения yt , т.е. переменная xt является причиной по Гренджеру для переменной yt . В то же время, прошлые значения переменной yt никак не помогают прогнозированию значения xt , так что yt не является причиной по Гренджеру для xt .
Заметим далее, что даже если в ECM Cov(vt, wt) ≠ 0, оценивание пары уравнений ЕСМ как системы не повышает эффективности оценок, поскольку в правые части обоих уравнений входят одни и те же переменные.
Расмотренный в нашем примере процесс порождения данных
DGP: xt = xt – 1 + εt , yt = 2 xt + νt ,
является частным случаем модели, известной как треугольная система Филлипса. В общем случае (для двух рядов) эта система имеет вид
yt = β xt + νt , xt = xt – 1 + εt ,
где (εt , νt)T ~ i.i.d. N2(0, Σ) – последовательность независимых, одинаково распределенных случайных векторов, имеющих двумерное нормальное распределение с нулевым математическим ожиданием и ковариационной матрицей Σ . (Такая последовательность называется двумерным гауссовским белым шумом.)
Если матрица Σ диагональная, так что Cov(εt , νt) = 0, то тогда xt является экзогенной переменной в первом уравнении, и никаких проблем с оцениванием коэффициента β в этом случае не возникает.
Если же Cov(εt , νt) ≠ 0, то тогда xt уже не является экзогенной переменной в первом уравнении, т.к. при этом Cov(xt , νt) = Cov(xt – 1 + εt , νt) ≠ 0. Поэтому получаемая в первом уравнении оценка наименьших квадратов для β не имеет даже асимптотически нормального распределения.
В дальнейшем мы еще вернемся к проблеме оценивания коинтегрирующего вектора, а сейчас обратимся к вопросу о коинтеграции нескольких временных рядов.
Пусть мы имеем N временных рядов y1t , … , yN t , каждый из которых является интегрированным порядка 1. Если существует такой вектор β = (β1, … , βN)T , отличный от нулевого, для которого
β1 y1t + … + βN yN t ~ I(0) – стационарный ряд,
то говорят, что эти ряды коинтегрированы (в узком смысле); такой вектор β называется коинтегрирующим вектором. Если при этом
c = E(β1 y1t + … + βN yN t),
то тогда можно говорить о долговременном положении равновесия системы в виде
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
24 |
β1 y1t + … + βN yN t = c .
В каждый конкретный момент времени t существует некоторое отклонение системы от этого положения равновесия, характеризующееся величиной
zt = β1 y1t + … + βN yN t – c .
Ряд zt , в силу сделанных предположений, является стационарным рядом, имеющим нулевое математическое ожидание, так что он достаточно часто пересекает нулевой уровень, т.е. система колеблется вокруг указанного выше положения равновесия.
Естественной процедурой для проверки коинтегрированности рядов y1t , … , yN t является построение регрессии одного из этих рядов на остальные N – 1 рядов и проверка гипотезы наличия единичного корня у ряда zt на основании исследования ряда остатков от оцененной регрессии. Иначе говоря, мы оцениваем, например, модель
y1t = θ1 + θ2 y2 t + … + θN yN t + ut ,
и проверяем гипотезу единичного корня на основании исследования ряда остатков uˆt = y1t – (θˆ1+ θˆ2 y2 t + … + θˆN yN t),
опираясь на статистику Дики – Фуллера. Критические значения можно найти, следуя
[MacKinnon (1991)] (см. также [Patterson (2000), таблица A8.1]).
Если гипотеза единичного корня отвергается, то вектор
βˆ = (1, – θˆ2 , … , – θˆN )
берется в качестве оцененного коинтегрирующего вектора. При этом отклонение системы от положения равновесия оценивается величиной
zˆt = uˆt .
Поясним теперь, что мы имели в виду, оговаривая, что приведенные выше определения коинтеграции соответствуют коинтеграции в узком смысле.
В приведенных определениях ненулевой вектор β = (β1, … , βN)T определялся как коинтегрирующий вектор, если β1 y1t + … + βN yN t – стационарный ряд. Это означает, что если ряды y1t , … , yN t (по крайней мере, некоторые из них) содержат, наряду со стохастическим, еще и детерминированные тренды, то тогда коинтегрирующий вектор должен аннулировать оба вида трендов одновременно. И в связи с этим, коинтеграцию в узком смысле называют еще детерминистской коинтеграцией.
7.3. Проверка нескольких рядов на коинтегрированность. Критерии Дики – Фуллера
Здесь надо различать несколько случаев.
(1) Коинтегрирующий вектор определяется экономической теорией.
Тогда надо просто проверить на наличие единичного корня соответствующую линейную комбинацию
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
25 |
β1 y1t + … + βN yN t .
При этом используются те же критические значения, которые рассчитаны на применение к отдельно взятому ряду; эти значения не зависят от количества задействованных рядов N .
Пусть возможный коинтегрирующий вектор не определен заранее.
Тогда отдельно рассматриваются следующие ситуации.
(2) Ряды y1t , … , yN t не имеют детерминированного тренда (точнее, E(∆yk t) = 0).
(2a) В коинтеграционное соотношение (SM) константа не включается.
В этом случае мы оцениваем
SM: y1t = γ2 y2t + … + γN yN t + ut ,
получаем ряд остатков
uˆt = y1t − (γˆ2 y2 t +K+ γˆN yN t ),
оцениваем модель регрессии
∆uˆt = ϕ uˆt −1 +ζ1∆uˆt −1 +K+ζ K ∆uˆt − K + εt
с достаточным количеством запаздывающих разностей и проверяем гипотезу H0: φ
= 0 против альтернативы H0: φ < 0 .
На этот раз критические значения для t-статистики tφ зависят от количества задействованных рядов N . При большом количестве наблюдений можно использовать
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
26 |
критические значения, приведенные в [Hamilton (1994), Table B.9, Case 1]. Однако на практике в правую часть оцениваемого уравнения константа обычно включается.
(2b) В коинтеграционное соотношение (SM) константа включается.
В этом случае мы оцениваем
SM: y1t = α + γ2 y2t + … + γN yN t + ut ,
опять получаем ряд остатков – теперь это будет ряд
uˆt = y1t − (αˆ + γˆ2 y2 t +K+ γˆN yN t ),
оцениваем модель регрессии
∆uˆt = ϕ uˆt −1 +ζ1∆uˆt −1 +K+ζ K ∆uˆt − K + εt
с достаточным количеством запаздывающих разностей и проверяем гипотезу H0: φ
= 0 против альтернативы H0: φ < 0 .
Критические значения в этом случае отличаются от случая (2a). При большом
количестве наблюдений можно использовать критические значения, приведенные в
[Hamilton (1994), Table B.9, Case 2]. При небольших T критические значения
вычисляются по формуле, приведенной в [MacKinnon (1991), таблица 1 (вариант “no
trend”)] и воспроизведенной в [Patterson (2000)].
|
(3) |
Хотя бы один из рядов y2t , … , yN t имеет линейный тренд , так что E(∆yk t) |
|
≠ 0 |
хотя бы для одного из регрессоров. |
(3a) В коинтеграционное соотношение включается константа.
В этом случае оценивается
SM: y1t = α + γ2 y2t + … + γN yN t + ut .
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
27 |
Далее действуем опять как в (2b), только критические значения другие. При
большом количестве наблюдений можно использовать критические значения,
приведенные в [Hamilton (1994), Table B.9, Case 3]. При небольших T критические
значения вычисляются по формуле, приведенной в работе [MacKinnon (1991), Table
1 (вариант “with trend”)] и воспроизведенной в [Patterson (2000)].
(3b) В коинтеграционное соотношение включается линейный тренд.
В этом случае оценивается
SM: y1t = α + δt + γ2 y2t + … + γN yN t + ut .
Действуя так же, как и ранее, используем те же таблицы, что и в (3a), но только не для N , а для N + 1 переменных.
Включение тренда в коинтеграционное соотношение приводит к уменьшению
мощности критерия из-за необходимости оценивания “мешающего” параметра δ .
Однако такой подход вполне уместен в тех случаях, когда нет полной уверенности в
том, имеется ли ненулевой тренд хотя бы у одного из рядов y1t, y2t , … , yN t .
Пример
Смоделируем реализации четырех рядов y1t , y2t , y3t , y4t , следуя процессу порождения данных
DGP: y1t = y2, t + y3, t + y4, t + ε1t ,
y2t = y2, t – 1 + ε2t , y3t = y3, t – 1 + ε3t , y4t = y4, t – 1 + ε4t ,
где ε1t , ε2t , ε3t , ε4t – независимые друг от друга процессы гауссовского белого шума с дисперсиями, равными 1 для ε2t , ε3t , ε4t и 2 для ε1t .
Графики полученных реализаций для T = 200 приведены ниже.
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
28 |
|||||||||
|
60 |
||||||||||
|
40 |
||||||||||
|
20 |
||||||||||
|
0 |
||||||||||
|
-20 |
||||||||||
|
-40 |
||||||||||
|
-60 |
||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
Y1 |
Y3 |
|||||||||
|
Y2 |
Y4 |
Не зная точно процесс порождения данных, мы должны были бы начать с исследования отдельных рядов. У всех четырех рядов не обнаруживается детерминированного тренда. Проверка по критерию Дики – Фуллера дает значения t-статистик, равные – 2.18, – 1.78, – 0.57, –1.70, соответственно. Все 4 ряда признаются интегрированными. Продифференцированные ряды идентифицируются как гауссовские белые шумы, так что ряды y1t , y2t , y3t , y4t идентифицируются как AR(1) ряды с единичным корнем, т.е. как интегрированные ряды порядка 1.
Теперь можно приступить к проверке этих четырех рядов на коинтегрированность. (1) Если “экономическая теория” предполагает теоретическое
долговременное соотношение между рассматриваемыми рядами в форме
|
y1t = y2, t + y3, t + y4, t , |
|||||||||
|
то мы просто проверяем на интегрированность ряд |
|||||||||
|
y1t – y2, t – y3, t – y4, t . |
|||||||||
|
График этого ряда |
|||||||||
|
8 |
|||||||||
|
6 |
|||||||||
|
4 |
|||||||||
|
2 |
|||||||||
|
0 |
|||||||||
|
-2 |
|||||||||
|
-4 |
|||||||||
|
-6 |
|||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
COINT |
вполне похож на график стационарного ряда, что подтверждается проверкой по критерию Дики – Фуллера: вычисленное значение t-статистики критерия равно – 15.07. Гипотеза некоинтегрированности рядов отвергается.
Представим теперь, что теория не предлагает нам готового коинтегрирующего вектора.
(2a) Оценивание статистической модели без включения в нее константы дает:
Dependent Variable: Y1
Method: Least Squares
|
Variable |
Coefficient Std. Error |
t-Statistic |
Prob. |
|||||||||
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
29 |
||||||||||||||
|
Y2 |
0.996084 |
0.009973 |
99.88161 |
0.0000 |
|||||||||||
|
Y3 |
0.992550 |
0.009578 |
103.6296 |
0.0000 |
|||||||||||
|
Y4 |
1.002305 |
0.012393 |
80.87922 |
0.0000 |
|||||||||||
При оценивании тестового уравнения Дики – Фуллера для ряда остатков получаем
|
Augmented Dickey-Fuller Test Equation |
|||||||||||||
|
Dependent Variable: D(RESID_2A) |
|||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|||||||||
|
RESID_2A(-1) |
-1.075552 |
0.070892 |
-15.17178 |
0.0000 |
|||||||||
Вычисленное значение t-статистики критерия равно – 15.17, что намного ниже 5%
критического значения – 3.74 ([Hamilton (1994), Table B.9, Case 1]). Гипотеза некоинтегрированности отвергается.
(2b) Оценивание статистической модели с включением константы:
|
Dependent Variable: Y1 |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
C |
0.332183 |
0.373542 |
0.889279 |
0.3749 |
||||||||
|
Y2 |
1.002583 |
0.012369 |
81.05843 |
0.0000 |
||||||||
|
Y3 |
0.987369 |
0.011215 |
88.04048 |
0.0000 |
||||||||
|
Y4 |
0.999022 |
0.012937 |
77.22129 |
0.0000 |
||||||||
При оценивании тестового уравнения Дики – Фуллера для ряда остатков получаем
|
Augmented Dickey-Fuller Test Equation |
|||||||||||||
|
Dependent Variable: D(RESID_2B) |
|||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|||||||||
|
RESID_2B(-1) |
-1.079049 |
0.070861 |
-15.22764 |
0.0000 |
|||||||||
Вычисленное значение t-статистики – 15.23 опять намного ниже 5% критического значения, которое здесь равно – 4.11 ([Hamilton (1994), Table B.9, Case 2]). Гипотеза некоинтегрированности отвергается.
|
(3) Модифицируем теперь ряд y1t , переходя к ряду y*1t = y1t + 0.75t , график которого |
|||||||||
|
в сравнении с графиком ряда y1t |
имеет следующий вид: |
||||||||
|
200 |
|||||||||
|
150 |
|||||||||
|
100 |
|||||||||
|
50 |
|||||||||
|
0 |
|||||||||
|
-50 |
|||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
Y1 |
Y1_STAR |
||||||||
|
Картина изменения всех 4 рядов принимает вид |
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
30 |
|||||||||
|
200 |
||||||||||
|
150 |
||||||||||
|
100 |
||||||||||
|
50 |
||||||||||
|
0 |
||||||||||
|
-50 |
||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
Y1_STAR |
Y3 |
|||||||||
|
Y2 |
Y4 |
(3a) Оцениваем статистическую модель с константой в правой части:
|
Dependent Variable: Y1_STAR |
|||
|
Variable |
Coefficient Std. Error |
t-Statistic |
Prob. |
|
C |
11.49053 |
2.704802 |
4.248195 |
0.0000 |
||||||
|
Y2 |
-1.333762 |
0.089561 |
-14.89224 |
0.0000 |
||||||
|
Y3 |
2.856952 |
0.081207 |
35.18115 |
0.0000 |
||||||
|
Y4 |
0.072630 |
0.093677 |
0.775323 |
0.4391 |
||||||
|
В этом случае график остатков имеет несколько отличный вид: |
||||||||||
|
15 |
||||||||||
|
10 |
||||||||||
|
5 |
||||||||||
|
0 |
||||||||||
|
-5 |
||||||||||
|
-10 |
||||||||||
|
-15 |
||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
RESID_3A |
||||||||||
|
Проверка по Дики – Фуллеру дает следующие результаты: |
При оценивании тестового уравнения Дики – Фуллера для ряда остатков получаем
|
Augmented Dickey-Fuller Test Equation |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
RESID_3A(-1) |
-0.119805 |
0.033630 |
-3.562431 |
0.0005 |
||||||||
Вычисленное значение t-статистики – 3.56 выше 5% критического значения, которое здесь равно – 4.16 ([Hamilton (1994), Table B.9, Case 3]). Гипотеза некоинтегрированности не отвергается.
(3b) Включаем в правую часть тренд:
|
Dependent Variable: Y1_STAR |
||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
C |
0.304068 |
0.390739 |
0.778187 |
0.4374 |
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
31 |
||||||||||
|
@TREND |
0.751890 |
0.007507 |
100.1621 |
0.0000 |
|||||||
|
Y2 |
1.008470 |
0.026468 |
38.10166 |
0.0000 |
|||||||
|
Y3 |
0.982658 |
0.021830 |
45.01453 |
0.0000 |
|||||||
|
Y4 |
1.001356 |
0.015942 |
62.81247 |
0.0000 |
|||||||
|
График остатков: |
|||||||||||
|
8 |
|||||||||||
|
6 |
|||||||||||
|
4 |
|||||||||||
|
2 |
|||||||||||
|
0 |
|||||||||||
|
-2 |
|||||||||||
|
-4 |
|||||||||||
|
-6 |
|||||||||||
|
-8 |
|||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
||
|
RESID_3B |
|||||||||||
|
Последний график похож на график стационарного ряда, что подтверждается |
|||||||||||
|
проверкой по Дики – Фуллеру: |
|
Augmented Dickey-Fuller Test Equation |
|||||||||||||
|
Dependent Variable: D(RESID_3B) |
|||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|||||||||
|
RESID_3B(-1) |
-1.079492 |
0.070859 |
-15.23448 |
0.0000 |
|||||||||
Вычисленное значение t-статистики – 15.234 намного ниже 5% критического значения, которое здесь равно –4.49 ([Hamilton (1994), Table B.9, Case 3]). Гипотеза некоинтегрированности отвергается.
Последние два результата весьма важны для уточнения того, что понимается под коинтеграцией в настоящее время.
Фактически, мы обнаружили следующее. Ряды y1t , y2t , y3t , y4t коинтегрированы в том смысле, который был определен выше (коинтегрированы в узком смысле). Именно в таком виде ввели в обиход понятие коинтеграции Энгл и Гренджер. Ряды y*1t , y2t , y3t , y4t не являются коинтегрированными в узком смысле. В то же время, включение в правую часть статистической модели трендовой составляющей приводит к стационарным остаткам.
Вспомним в связи с этим, что при включении тренда в правую часть линейного регрессионного уравнения коэффициенты при объясняющих переменных интерпретируются как коэффициенты линейной связи между переменными, очищенными от детерминированного тренда. Последние же действительно были коинтегрированы по построению.
Наблюдаемая ситуация известна теперь под названием “стохастическая коинтеграция”. Оно указывает на наличие коинтеграционной связи между стохастическими трендами, входящими в состав рассматриваемых рядов, и не требует согласованности детерминированных трендовых составляющих ( если таковые имеются). В этом случае коинтегрирующий вектор аннулирует стохастический тренд, но не обязан одновременно аннулировать и детерминированный тренд. Другими словами, существует линейная комбинация рассматриваемых рядов, которая образует ряд, стационарный относительно детерминированного тренда, но не обязательно стационарный.
В противоположность стохастической коинтеграции, при наличии коинтеграции в узком смысле коинтегрирующий вектор аннулирует и стохастический и
www.iet.ru/mipt/2/text/curs_econometrics.htm
Коинтеграция
В 2003 году Шведская академия наук объявила о присуждении Нобелевской премии по экономике Роберту Энглу и Клайву Грэнджеру за «методы анализа экономических временных рядов с общим трендом», так называемые методы коинтеграции. Их статья, перевод которой приводится ниже, заложила основы в этой области и изменила подходы прикладных макроэкономистов к анализу данных.
Идея коинтеграции является очень естественным развитием идеи экономического равновесия, если принять во внимание нестационарность большинства макроэкономических переменных. В то время как стационарные временные переменные принимают значения недалеко от своего среднего, часто возвращаясь к нему, для нестационарных переменных ожидаемое время возврата к среднему бесконечно, и они обладают свойством далеко уходить от своего среднего. Нестационарность большинства макроиндикаторов — это хорошо изученная эмпирическая данность. Зачастую экономическое равновесие понимается как связь между несколькими переменными, «подталкивающая» некоторую линейную комбинацию этих переменных к нулю настолько сильно, что отклонения от нуля очень незначительны. Таким образом, эта линейная комбинация нестационарных переменных оказывается стационарной, а изначальные переменные коинтегрированными.
Хотя сама концепция коинтеграции очень естественна, эконометрические методы, необходимые для работы с ней, существенно отличаются от классических эконометрических принципов, используемых в микроэконометрике. Различия в методах столь существенны, что при первом прочтении приведенная ниже статья может вызвать удивление у читателя, хорошо знакомого с классической эконометрикой. Начнем с того, что большая часть классического регрессионного анализа построена на понятии экзогенности, в то время как коинтеграционные регрессии дают состоятельные оценки, даже если все переменные эндогенны, более того, прямая и обратная регрессии дают практически одинаковый результат — вещь, невозможная в микроэконометрике.
Сложность работы с коинтеграцией заключается в том, что знакомые эконометристам статистики сходятся к нестандартным асимптотическим распределениям и требуют нестандартных критических значений. Энгл и Грэнджер показывают, что вполне естественное желание избежать эти сложности путем перехода к первым разностям переменных является ошибочным шагом и ведет к существенно смещенным ошибкам. Смещение в оценках возникает из-за того, что та самая стационарная линейная комбинация нестационарных переменных является необходимым регрессором в регрессии первых разностей. Эта регрессия называется моделью коррекции ошибок. Авторы рассматривают вопрос двухшаговой оценки модели коррекции ошибок, а также вопрос тестирования коинтеграции.
Идеи и статьи Энгла и Грэнджера выделили макроэконометрику и теорию временных рядов в отдельный раздел экономики. Роберт Энгл известен также своими работами по стохастической волатильности (модели ARCH и GARCH), которые были названы в официальном объявлении Нобелевского комитета. Клайв Грэнджер является автором известной концепции «причинности по Грэнджеру». Авторы проработали в университете Калифорнии в Сан-Диего около 30 лет, прежде чем вышли на пенсию в 2003 году. Клайв Грэнджер ушел из жизни в 2009 году.
А. Е. Микушева
Прикладная эконометрика, 2015, 39 (3), с. 107-135.
AppliedEconometrics, 2015, 39 (3), pp. 107-135.
Co-Integration and Error Correction: Representation, Estimation, and Testing
Robert F. Engle and C. W. J. Granger
Коинтеграция и коррекция ошибок: представление, оценивание и тестирование1
Роберт Ф. Энгл, К. У. Дж. Грэнджер2
В работе исследуется взаимосвязь между моделями коинтеграции и коррекции ошибок, изначально предложенная в (Granger, 1981), предлагаются новые методы оценивания и тестирования, рассматриваются эмпирические примеры.
Если каждая компонента векторного временного ряда xt не стационарна, но становится стационарной после взятия первых разностей, а некоторая линейная комбинация a’x, стационарна, такой временной ряд называется коинтегрированным с коин-теграционным вектором а. Если существует несколько линейно независимых коинте-грационных векторов, то в этом случае а — это матрица, составленная построчно из коинтеграционных векторов. Если интерпретировать равенство а’xt = 0 как долгосрочное равновесие, то наличие коинтеграции означает, что отклонение от равновесия является стационарным, с ограниченной дисперсией, даже в том случае, когда исходные ряды являются нестационарными и имеют бесконечную дисперсию. В статье доказана теорема о представлении, основанная на статье (Granger, 1983), в которой связываются понятия скользящего среднего, авторегрессии и коррекции ошибок для коинтегрированных систем. Векторная авторегрессия в разностях
1 Оригинальная статья: Robert F. Engle and C. W. J. Granger (1987). Co-Integration and Error Correction: Representation, Estimation, and Testing. Econometrica, Vol. 55, No. 2 (Mar., 1987), pp. 251-276. © Econometric Society.
The copyright to this article is held by the Econometric Society, http://www.econometricsociety.org/. It may be downloaded, printed and reproduced only for personal or classroom use. Absolutely no downloading or copying may be done for, or on behalf of, any for-profit commercial firm or for other commercial purpose without the explicit permission of the Econometric Society. For this purpose, contact the Editorial Office of the Econometric Society at econometrica@econometricsociety.org.
Редакция благодарит Econometric Society за разрешение на публикацию перевода статьи.
Перевод статьи выполнен под редакцией П. К. Катышева.
2 Robert Fry Engle — Professor, New York University Stern School of Business.
Clive William John Granger (1934-2009).
Авторы выражают благодарность David Hendry и Sam Yoo за множество важных и полезных обсуждений и предложений, так же как и Gene Savin, David Dickey, Alok Bhargava и Marco Lippi. Они признательны двум рецензентам за детальную конструктивную критику, а также Yoshi Baba, Sam Yoo и Alvaro Ecribano за творчески выполненные численные расчеты и примеры. Исследование выполнено при финансовой поддержке Национального научного фонда (США) SES-80-08580 и SES-82-08626. Предыдущая версия этой статьи называлась «Спецификация динамической модели с равновесными ограничениями: Коинтеграция и коррекция ошибок».
несовместима с этими представлениями. В статье предложена простая, но асимптотически эффективная двухшаговая оценка. Тестирование коинтеграции сочетает в себе задачи тестирования единичных корней и тесты с параметрами, неидентифи-цируемыми при нулевой гипотезе. Предложены и проанализированы семь тестовых статистик. Методом Монте-Карло получены критические значения этих статистик. Мощность предложенных тестов проанализирована с использованием полученных критических значений, и одна процедура тестирования рекомендуется для применения. В ряде примеров было обнаружено, что потребление и доход, краткосрочные и долгосрочные процентные ставки являются коинтегрированными, заработные платы и цены не коинтегрированы, номинальный ВНП коинтегрирован с М2, но не с М1, М3 или с совокупными ликвидными активами.
ключевые слова: коинтеграция; векторная авторегрессия; единичные корни; коррекция ошибок; многомерные временные ряды; тесты Дики-Фуллера. JEL classification: C01; C12; C30; C33; C513.
1. введение
Индивидуальная экономическая переменная, рассматриваемая как временной ряд, может меняться весьма значительно, однако встречаются такие переменные, от которых можно ожидать, что, будучи объединенными в пару, подобные ряды будут не слишком удаляться друг от друга. Обычно экономическая теория предлагает некоторый механизм, удерживающий такие ряды вместе. Примерами могут быть краткосрочные и долгосрочные процентные ставки, ассигнования капитала и расходы, доходы и расходы домохозяйств, цены одного товара на различных рынках или цены близких товаров-заменителей на одном рынке. Подобная идея возникает при взгляде на равновесие как на стационарное состояние, в которое стремится вернуться экономика при любом отклонении от этого состояния. Если xt является вектором экономических переменных, то можно сказать, что равновесие достигается при выполнении линейного ограничения:
a’xt = 0.
Как правило, xt не будет находиться в равновесии, и поэтому одномерную переменную zt = a’xt можно назвать ошибкой или отклонением от равновесия. Если понятие равновесия дает правильную спецификацию эконометрической модели, то экономика должна предпочитать малое значение zt большому.
Эти идеи легли в основу данной статьи, и с их помощью показано, что в классе моделей, известных как модели коррекции ошибок, долгосрочные компоненты переменных связаны условиями равновесия, в то время как краткосрочные имеют гибкую динамическую спецификацию. Для того чтобы это утверждение было верным, используется условие коинтеграции, которое впервые было введено в работах (Granger, 1981) и (Granger, Weiss, 1983); его точное определение дано в следующем разделе. В разделе 3 обсуждаются несколько представлений коинтегрированных систем, раздел 4 содержит описание процедур оценивания, а в разделе 5 приведены соответствующие тесты. Некоторые приложения представлены в разделе 6, раздел 7 содержит выводы. В разделе 4 детально рассмотрен простой пример, который может быть полезен для мотивации изучения таких систем.
3 JEL classification добавлены редактором.
2. Интеграция, коинтеграция и коррекция ошибок g-
I
Согласно теореме Вольда, всякий одномерный стационарный временной ряд без де- ¿L терминированной компоненты может быть представлен как некоторый процесс бесконеч- * ного скользящего среднего, который также можно аппроксимировать процессом сколь- ч^ зящего среднего конечного порядка. Более подробно см. (Box, Jenkins, 1970) или (Granger, Newbold, 1977). Часто, однако, для обеспечения стационарности экономических рядов не- | обходимо брать разности. Это приводит к следующему известному определению интег- ^ рации. ^
Определение. Временной ряд без детерминированной компоненты называется интегрированным порядка d и обозначается xt ~ I(d), если его разность порядка d допускает стационарное обратимое ARMA представление.
В большей части статьи для простоты будут рассмотрены только значения d = 0 и d = 1, но почти все результаты могут быть обобщены на другие случаи, включая дробную разностную модель. Таким образом, если d = 0 , то сам ряд xt будет стационарным, а для d = 1 он будет стационарен в первой разности.
Поведение I (0) и I (1) рядов существенно отличается. Для детального рассмотрения см., например, (Feller, 1968) или (Granger, Newbold, 1977).
(a) Если xt ~ I(0) и имеет нулевое среднее, то: (i) дисперсия xt ограничена; (ii) инновации (шоки) имеют только кратковременный эффект на значения xt ; (iii) спектр f (а) ряда xt обладает свойством 0 < f (0) < да ; (iv) среднее время между последовательными пересечениями уровня x = 0 конечно; (v) автокорреляции pk быстро убывают с ростом k, так что их сумма ограничена.
(b) Если xt ~ I(1) с x0 = 0 , то: (i) дисперсия xt стремится к бесконечности при t ^да; (ii) инновации имеют постоянный эффект на значение xt , т. к. xt представляет из себя сумму всех предыдущих изменений; (iii) при малых а спектр xt имеет аппроксимацию f (а) ~ Àa~2d, в частности f (0) = да ; (iv) среднее время между последовательными пересечениями уровня x = 0 равно бесконечности; (v) теоретические автокорреляции pk ^ 1 для всех k при t ^ да.
Бесконечность теоретической дисперсии временного ряда I (1) объясняется полностью вкладом низких частот или долгосрочной части этого ряда. Поэтому по сравнению с рядом I (0) ряд I (1) более гладкий, имеет доминирующие длинные колебания. Из-за относительных размеров дисперсий сумма ряда I(0) и ряда I(1) есть ряд I(1). Более того, если а и b константы, b Ф 0, и если xt ~ I (d ), то а + bxt также будет рядом I (d ).
Если оба ряда xt, yt являются I (d ), то в общем случае линейная комбинация
zt = xt — аЛ
также будет I (d ) . Однако, возможно, что zt ~ I (d — b), b > 0 . Это означает, что на долгосрочные компоненты рядов накладывается некоторое специфическое ограничение. Рассмотрим случай d = b = 1, т. е. xt, yt являются I(1) с доминирующими долгосрочными компонентами, но zt является I(0) без сильных низких частот. Иными словами, константа а выбрана так, что долгосрочные компоненты xt и yt в основном компенсируются. Если же а = 1, то расплывчатое утверждение «xt и yt не могут отклоняться слишком далеко друг от друга» приобретает более точную форму: «разность xt и yt есть I(0)». Использование постоянной а попросту означает некоторое масштабирование, которое должно быть ис-
пользовано перед взятием разности I(0). Следует подчеркнуть, что такое а, для которого zt ~ I(0), может и не существовать.
Аналогичный случай: линейная комбинация zt пары временных рядов xt и yt, каждый из которых содержит значимые сезонные компоненты, не будет содержать сезонности. Понятно, что такое может происходить, но весьма редко.
Для формализации этих идей вводится следующее определение из (Granger, 1981; Granger, Weiss, 1983).
Определение. Компоненты векторного временного ряда xt называются коинтегриро-ванными порядка d, b и обозначаются xt ~ CI(d,b), если: (i) все компоненты xt являются I(d); (ii) существует вектор а (ф 0) такой, что zt =a’xt ~ I(d — b), b > 0. Вектор a называется коинтеграционным вектором.
В случае d = 1, b = 1 наличие коинтеграции означает, что все компоненты вектора xt являются рядами I(1), а ошибка равновесия zt есть I(0). Значит, если zt имеет нулевое среднее, то этот ряд будет редко далеко отклоняться от нуля и часто пересекать нулевой уровень. Иными словами, время от времени будет достигаться точное равновесие или близкое к нему состояние. В то же время, если xt не является коинтегрированным, процесс zt может блуждать, далеко отклоняясь от нуля и редко пересекая нулевой уровень, и в этом случае теория равновесия не имеет практического значения. Возможность снижения порядка интеграции означает наличие специальных отношений, следствия которых можно интерпретировать и тестировать. Однако, если все элементы xt уже являются стационарными, т. е. I(0), то ошибка равновесия zt не имеет отличительных свойств, если она тоже есть I(0) . Возможно, что zt ~ I(-1), тогда его спектр равен нулю на нулевой частоте, но если любая из переменных содержит ошибку измерения, это свойство может быть не выполнено в общем случае, и поэтому данный случай не представляет практического интереса. При интерпретации концепции коинтеграции можно отметить, что в случае N = 2, d = b = 1 Granger и Weiss (1983) показали, что необходимым и достаточным условием коинтеграции является когерентность между двумя рядами на нулевой частоте.
Если xt имеет N компонент, может существовать более чем один коинтеграционный вектор a. Очевидно, возможно несколько равновесных соотношений управления совместным поведением переменных. В дальнейшем будем предполагать, что существует ровно r, r < N — 1, линейно независимых коинтеграционных векторов, образующих матрицу а размерности N х r. По построению ранг a равен r, и это число будет называться коинтеграци-онным рангом ряда xt.
Далее будет установлена тесная связь между коинтеграцией и моделями коррекции ошибок. Механизмы коррекции ошибок широко используются в экономике. Ранние версии рассмотрены в (Sargan, 1964; Phillips, 1957). Идея состоит в том, что некоторая доля отклонения от равновесия в какой-то промежуток времени корректируется в следующем промежутке. Например, изменение в цене за один период может зависеть от степени избыточного спроса в предшествующем периоде. Похожая ситуация возникает в задачах оптимального поведения при наличии издержек адаптации или в условиях неполноты информации. В последнее время эти модели вызвали большой интерес с учетом результатов работ (Davidson et al., 1978; Hendry, von Ungern-Sternberg, 1980; Currie, 1981; Dawson, 1981; Salmon, 1982) и многих других.
В типичной модели коррекции ошибок для системы с двумя переменными изменение одной переменной зависит от ошибки равновесия в предыдущие моменты времени и от из-
í с>
£
менения обеих переменных в прошлом. Для многомерной системы модель коррекции ошибок можно определить с помощью оператора сдвига по времени В следующим образом.
Определение. Векторный временной ряд х{ допускает представление в виде модели коррекции ошибок, если
А(В)(1 — В)х( = _yzt_l + щ, Ы
|
где ^ является стационарным многомерным возмущением, А(0) = I, все элементы матри- <•>
е
а
цы А(1) конечны, zz = а’хт и у Ф 0 .
В этом представлении объясняющей переменной является только неравновесие в предыдущем периоде. Тем не менее, за счет перегруппировки членов модель с любым числом лагов величины z может быть представлена в этой форме, таким образом, модель позволяет описывать любой способ сходимости к равновесию. Заметное различие между этим определением и большинством встречавшихся приложений состоит в том, что в многомерном случае определение не опирается на экзогенность подмножества переменных. Ситуация, когда одна переменная является слабо экзогенной в смысле (Е^1е et а1., 1983), также может быть исследована в рамках данного подхода, что кратко обсуждается ниже. Второе существенное различие состоит в том, что а рассматривается как вектор неизвестных параметров, а не набор констант, представленных экономической теорией.
3. свойства коинтеграционных переменных и их представления
Пусть каждая компонента вектора хг является временным рядом I (1), причем первая разность каждой компоненты есть чисто недетерминированный стационарный случайный процесс с нулевым средним. Любые известные детерминированные компоненты могут быть вычтены перед началом анализа. Тогда процесс х{ допускает многомерное представление Вольда
(1 _ В) х, = С (В (3.1)
в том смысле, что левая и правая части имеют одну и ту же спектральную матрицу. При этом матрица С(В) однозначно определяется такими условиями: нули функции det[C(z)], z = е’а лежат на границе или вне единичного круга, и С(0) = 1Ы — единичная матрица размерности N х N (см. (Наппап, 1970, р. 66)). Здесь — белый шум с нулевым средним,
[0, , Ф 5,
екк]И; ,
Перегруппировкой слагаемых полином скользящего среднего С(В) всегда может быть представлен в виде
С (В) = С (1) + (1 _ В) С *( В). (3.2)
Если С(В) имеет конечный порядок, то С *(В) тоже будет иметь конечный порядок. Если С * (1) тождественно равен нулю, то можно получить аналогичное представление с сомножителем (1 _ В)2.
Связь между моделями коррекции ошибок и коинтеграцией впервые была отмечена в статье (Granger, 1981). Теорема о том, что коинтегрированный ряд может быть представлен моделью коррекции ошибок, была сформулирована и доказана в (Granger, 1983). Поэтому ее версия, сформулированная ниже, называется теоремой Грэнджера о представлении. Анализ похожих, но более сложных случаев представлен в статьях (Johansen, 1985; Yoo, 1985).
Теорема Грэнджера о представлении. Пусть N xi -вектор xt в (3.1) является коинте-грированным с d = 1, b = i, и коинтеграционный ранг равен r . Тогда:
(1) матрица C (1) имеет ранг N — r ;
(2) существует векторное ARMA представление
A(B ) xt = d (B )et, (3.3)
при этом матрица A(1) имеет ранг r, d(B) является скалярным полиномом, величина d(1) ограничена и A(0) = IN ; если d (B) = 1, то это векторная авторегрессия;
(3) существуют матрицы a, g размера N x r и ранга r такие, что:
a’C (1) = 0, C (1)у = 0, A(1) = уа’;
(4) существует представление в виде модели коррекции ошибок с вектором стационарных случайных переменных zt = a’xt размерности r xi :
A * ( B)(1 — B) xt = _gzt-i + d (B )et (3.4)
с A *(0) = In;
(5) вектор zt удовлетворяет соотношениям
zt = K ( B)st, (3.5)
(1 — B) zt = _a’gzt_i + J ( B ) et, (3.6)
где K(B) есть r x N-матрица лаговых полиномов, равная a’C *(B), все элементы матрицы K (1) конечны и имеют ранг r, и det(aY) > 0;
(6) если существует представление в виде конечной авторегрессии, то оно имеет вид (3.3) и (3.4) с d(B) = 1 и матрицами конечных полиномов A(B) и A *(B).
Для доказательства теоремы нам необходимы следующие утверждения о детерминантах и присоединенных матрицах для сингулярных матричных полиномов.
Лемма 1. Пусть G(Â) — матричный полином размерности N x N, принимающий конечные значения для Ле[0,1]. Пусть также ранг матрицы G(0) равен N — r для 0 < r < N, и пусть G *(0) Ф 0 в разложении
G{X) = G (0) + ÀG *(Л).
Тогда: (i) det(G(Л)) = Л g(À)IN, (ii) Adj (G(Л)) = Àr-iH (Л), где IN — единичная N x N-матрица, 1 < rank (H (0)) < r, и H (0) конечна.
Доказательство. Определитель G может быть представлен в виде степенного ряда по Л :
да
det(G^)) = .
1=0
Каждый элемент ôi является суммой конечного числа произведений элементов G^) и поэтому является конечным. Каждая такая сумма имеет некоторые слагаемые из G(0) и не-
которые из ЛG *(Л). Любое произведение с более чем N — г членами из G(0) будет равно нулю, потому что будет являться определителем подматрицы большего порядка, чем ранг
является стационарным чисто недетерминированным г-мерным временным рядом, допускающим представление в виде обратимого скользящего среднего. Умножая обе части равенства (3.1) на а, получаем:
(1 — В)zt = (ас(1) + (1 — В)а’С * (В))ег.
Для того чтобы zt был I(0) процессом, необходимо, чтобы вектор а’С(1) был равен 0. Любой вектор, удовлетворяющий этому свойству, будет коинтеграционным. Следователь-
í
G (0). Поэтому любой ненулевой элемент должен содержать не менее г членов из ЛG *(Л), а значит, соответствующая степень 1 при нем будет не меньше г . Таким образом, первый ^ ненулевой член Si есть Зг. Полагая ч^
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
да
£(1) = , |
‘=г «
получаем первую часть леммы, т. к. член 5г должен быть конечным. ^
Для доказательства второго утверждения разложим присоединенную матрицу для G по степеням Л: ^
да
Аф ^(Л)) = %Л’Н,.
i=0
Так как присоединенная матрица — это матрица, состоящая из определителей порядка N -1, то, как и выше, получаем, что первые г -1 слагаемых должны быть тождественно равны нулю. Поэтому
да
Adj ^(Л)) = Лг-1 ^Л’-Г+1Н1 = ЛГ-1Н(Л).
i=0
Поскольку элементы матрицы Нг -1 являются произведениями конечного числа конечных чисел, матрица Н(0) должна быть конечной.
Произведение матрицы на ее сопряженную — это определитель, умноженный на единичную матрицу. Поэтому
Лг ^(Л) 1М = (Э (0) + ЛG * (Л))Н (Л) = ^(0) Н (Л)ЛГ-1 + ЦЛ^ * (Л))ЛГ.
Приравнивая коэффициенты при одинаковых степенях Л, получаем:
G(0)Н(0) = 0 .
Поэтому ранг матрицы Н(0) должен быть не больше г , т. к. каждый ее столбец лежит в ядре матрицы G(0), имеющей ранг N — г . Если г = 1, первое слагаемое в выражении для присоединенной матрицы будет просто присоединенной матрицей для G(0), которая будет иметь ранг 1, т. к. G(0) имеет ранг N -1.
Доказательство теоремы Грэнджера о представлении. Условия теоремы предполагают существование многомерного представления Вольда (3.1) для коинтегрированного ^мерного случайного процесса х. Пусть а — соответствующая коинтеграционная матрица, такая что процесс
но, матрица С(1) имеет ранг N — г, и все коинтеграционные векторы лежат в ее ядре. Отсюда также следует, что а’С *(В) — обратимое представление в виде скользящего среднего, в частности, а’С * (1) Ф 0 . В противном случае коинтеграция будет с Ь = 2 или выше.
Полагая в Лемме 1 Л = (1 — В), G(Л) = С (В), Н (Л) = А( В) и g(Л) = d (В), получаем утверждение (2). Так как матрица С (В) имеет полный ранг и равна ^ при В = 0, ее обратная матрица есть Л(0) и также будет равна .
Утверждение (3) следует из того факта, что Л(1) имеет ранг между 1 и г и лежит в ядре матрицы С(1). Поскольку а натянуто на это нулевое пространство, Л(1) может быть записана в виде линейной комбинации коинтеграционных векторов
Л(1) = уа’.
Утверждение (4) следует из преобразований авторегрессии. Перегруппировка членов в (3.3) дает:
[АА(В) + А(1)](1 — В)х, = -А(1)х(-1 + d(В)к , А * (В)(1 — В)х( = -72,-1 + d(Вк, А *(0) = А(0) = ^.
Пятое утверждение следует из непосредственной замены в представлении Вольда. Определение коинтеграции подразумевает, что это скользящее среднее будет стационарным и обратимым. Перепишем представление в виде модели коррекции ошибки с А * (В) = I + А * *(В), где Л * *(0) = 0, и умножим слева на а’:
(1- В)г, = —а+ [а’ d(В) + а’А **(В)С(В)]е, = —а+J(В)е,.
Чтобы это представление было эквивалентно стационарному скользящему среднему, авторегрессия должна быть обратимой. Для этого необходимо, чтобы выполнялось условие det(a’у) > 0 . Действительно, если определитель равен нулю, то существует по крайней мере один единичный корень, а если определитель отрицателен, то для некоторого значения т от нуля до единицы выполнено равенство
¿а; (1Г — (1Г —а У)т) = 0, а это значит, что существует корень внутри единичного круга.
Повторяя предыдущие шаги с d (В) = 1, получаем шестое утверждение.
Теорема полностью доказана.
Могут быть получены и более сильные результаты при дополнительных ограничениях на кратность корней в представлении скользящего среднего. Например, Yoo (1985), используя формы Смита-Макмиллана, находит условия, при которых й(1) Ф 0, Л * (1) имеет полный ранг, и которые упрощают переход от модели коррекции ошибок к моделям коинтегра-ции. Однако приведенные выше результаты являются достаточными для задач оценивания и тестирования, рассматриваемых в этой статье.
Авторегрессия и модель коррекции ошибок, заданные формулами (3.3) и (3.4), тесно связаны с часто используемыми в эконометрике моделями векторной авторегрессии (VAR), особенно в случае, когда й(В) можно обоснованно считать равным 1. Тем не менее, каждая из них существенно отличается от стандартной VAR. В представлении авторегрессии
А( В) = к,
коинтеграция переменных хг создает ограничение, которое делает матрицу Л(1) сингулярной. Для г = 1 ранг этой матрицы будет равен 1. Анализ таких систем сложен, т. к. неко- Ц торые численные методы, используемые для нахождения скользящего среднего, являются крайне неустойчивыми. ^
Представление в виде модели коррекции ошибок ч^
I
е
а
А * (В)(1 — В)х = -уа’х-1 + £
выглядит более похожим на стандартную векторную авторегрессию для первых разностей. Здесь коинтеграция приводит к присутствию самих переменных (в уровнях), поэтому, если переменные будут коинтегрированными, чистая VAR для разностей будет неправильной спецификацией модели.
Таким образом, если ряды коинтегрированы, векторная авторегрессия для первых разностей является неверной спецификацией. Если же использовать векторную авторегерес-сию для уровней, то будут упущены существенные ограничения. Конечно, эти ограничения асимптотически будут выполняться, но если учесть их явно, можно повысить эффективность модели и улучшить многошаговый прогноз.
Так как хг ~ I(1), zt ~ I(0), то все члены в модели коррекции ошибок являются I(0). Верно и обратное: если хг ~ I(1) порождается моделью коррекции ошибок, то хг обязательно будет коинтегрированным. Также отметим, что если хг ~ I(0), то этот процесс всегда может быть представлен в виде модели ошибки коррекции, и поэтому в данном случае идея равновесия не имеет значения.
Как уже говорилось выше, в большинстве эмпирических примеров модель коррекции ошибок формулируется как реакция зависимой переменной на шоки независимой переменной. В этой статье все переменные являются совместно эндогенными; тем не менее, структура модели допускает причинность по Грэнджеру или слабые и сильные условия эк-зогенности, как в статье (Е^1е et а1., 1983). Например, двумерная коинтегрированная система должна иметь причинно-следственную связь по крайней мере в одном направлении. Поскольку вектор z должен включать обе переменные, и у не может быть тождественно нулем, то они должны входить в одно или оба уравнения. Если слагаемое коррекции ошибок входит в оба уравнения, ни одна из переменных не может быть слабо экзогенной для параметров другого уравнения из-за кросс-ограничений между уравнениями.
Понятие коинтеграции в принципе может быть применено к рядам с трендами или к авторегрессиям, корни которых лежат внутри единичного круга. В этих случаях коинтеграци-онный вектор по-прежнему будет необходим для приведения рядов к стационарности. Следовательно, тренды должны быть пропорциональными, и корни, лежащие внутри единичного круга, должны быть идентичными для всех рядов. Мы не рассматриваем эти случаи в данной работе и осознаем, что при оценивании и тестировании могут возникнуть существенные сложности.
4. оценивание коинтегрированных систем
Различные представления коинтегрированных систем неявно предполагают и различные способы их оценивания. Наиболее удобным является представление в виде модели коррекции ошибок (особенно если можно предположить, что нет никакого скользящего среднего).
При этом остаются кросс-ограничения на параметры между уравнениями, поэтому в предположении нормальности оценивание методом максимального правдоподобия требует применение итеративных процедур.
В этом разделе предлагается другой метод оценивания, состоящий из двух этапов. На первом этапе оцениваются параметры коинтеграционного вектора, а на втором они используются в модели коррекции ошибок. На каждом шаге нужно оценивать лишь одно уравнение методом наименьших квадратов, при этом, как будет показано далее, оценки всех параметров будут состоятельными. Эта процедура особенно удобна тем, что не требует спецификации динамики до тех пор, пока структура оценок коррекции не оценена. В качестве «побочного продукта» получаются некоторые статистики, полезные для тестирования коинтеграции.
Из (3.5) можно непосредственно выразить выборочную матрицу моментов. Обозначим
MT = 1/T2Xxtx’t.
t
Напомним, что zt = a’xt, тогда из формулы (3.5) следует
a’MT =X[K(B)e,]x; /T2.
t
Используя те же аргументы, что и в (Dickey, Fuller, 1979) или (Stock, 1984), можно показать, что для процесса, удовлетворяющего (3.1), справедливы следующие утверждения:
lim E (M T ) = M (4.1)
T ^да
и a’M = 0 или (vec a)'(I ® M) = 0 . (4.2)
Хотя выборочная матрица моментов для коинтегрированного процесса будет несингулярной для любой выборки, в пределе она будет иметь ранг N — r . Это хорошо согласуется с общим наблюдением, что данные экономических временных рядов сильно коллинеар-ны друг с другом, так что матрицы моментов могут быть близки к сингулярным даже при больших выборках. Таким образом, с аналитической точки зрения коинтеграция является правдоподобной гипотезой.
Уравнения (4.2) не определяют однозначно коинтеграционные векторы, если нет ограничений типа нормализации. Пусть q и Q являются матрицами, задающими эту нормализацию, которая после перепараметризации a в j х 1 -вектор может быть записана так:
vec a = q + Qd. (4.3)
При этом предполагается, что вектор в лежит в компактном подмножестве пространства RJ.
Обычно q и Q состоят полностью из нулей или единиц, тем самым определяя один коэффициент в каждом столбце матрицы а равным единице, и определяя повороты при r > 1. Параметр в называется идентифицируемым, если существует единственное решение уравнений (4.2) и (4.3). Это решение определяется равенством
(I ®M)Qe = —(I ® M)q, (4.4)
где по предположению идентифицируемости у матрицы (I ® M)Q существует левая обратная матрица, даже если у M ее нет.
í
Так как матрица моментов MT будет иметь полный ранг для конечных выборок, разумным подходом к оценке является минимизация суммы квадратов отклонений от равновесия. В случае единственного коинтеграционного вектора оценка а будет минимизировать ¿L а’Мта при ограничениях (4.3), и результатом будет оценка обычным методом наименьших % квадратов. Для нескольких коинтеграционных векторов определим а как результат мини- ч^
мизации следа tr (а’M¿.а). Тогда задача оценки принимает вид: ^
|
min ^(а’Мта) = min уеса'(! ®MT)уеса = min(q + Q§)'(I ®MT)(q + Q§). <•>
а, s.t.(4.3) ‘ а, s.t.(4.3) ‘ T ф
h-
Ее решение есть ^
§ = -(Q'(I ®MT)Q)-1 (Q'(I ®MT)q, vec а = q + Q§. (4.5) *
Такой подход к оценке должен обеспечивать очень хорошее приближение к истинному коинтеграционному вектору, поскольку ищутся векторы с минимальной остаточной дисперсией, а асимптотически все линейные комбинации компонент вектора x будут иметь бесконечную дисперсию, за исключением коинтеграционных векторов.
При r = 1 эта оценка получается просто регрессией нормализованной переменной, коэффициент при которой равен единице, на остальные переменные. Эта регрессия будет называться «коинтеграционной регрессией», т. к. она стремится реализовать долговременное или равновесное соотношение, не заботясь о динамике. Такую регрессию Granger, Newbold (1974) уничижительно называют «ложной» регрессией в основном потому, что стандартные ошибки приводят к ошибочным выводам. Авторы в первую очередь рассматривали случай отсутствия коинтеграции, когда между переменными не было никакой связи, однако наличие единичного корня в остатках приводило к малому значению статистики Дарбина-Уот-сона, большому значению R2 и высокой значимости коэффициентов. Здесь ищутся только оценки коэффициентов для использования на втором этапе и тестирования долговременного равновесия. Распределение оценок коэффициентов было исследовано в статье (Stock, 1984).
Если N = 2, существуют две возможные регрессии в зависимости от выбранной нормализации. Неединственность оценки есть следствие хорошо известного факта, согласно которому оценка параметра обратной регрессии не равна величине, обратной оценке параметра прямой регрессии. Однако в нашем случае нормализация не играет существенной роли: матрица моментов стремится к сингулярной, и, значит, коэффициент детерминации R2 приближается к 1 , а он, в свою очередь, является произведением оценок коэффициентов прямой и обратной регрессий. Это было бы абсолютно верно, если бы существовали только два наблюдения, которые, конечно, определяют сингулярную матрицу. Для переменных, которые имеют общую тенденцию, корреляция стремится к единице, в то время как дисперсия каждой приближается к бесконечности. Линия регрессии практически проходит через крайние точки, как если бы существовали всего два наблюдения.
Stock (1984) в Theorem 3 доказывает следующее утверждение.
Предложение 1. Предположим, что xt удовлетворяет соотношению (3.1) с абсолютно суммируемым C *(B), ошибки имеют четвертый конечный момент, а xt является коинте-грированным (1,1) с r коинтеграционными векторами, удовлетворяющими равенству (4.3), в котором параметр § идентифицируем. Тогда оценка §, определяемая равенством (4.5), удовлетворяет соотношению
Tl-S{§-в) Л 0 для 5> 0. (4.6)
Предложение утверждает, что оценки параметров очень быстро сходятся к их вероятностным пределам. Оно также говорит, что для конечной выборки смещение имеет порядок 1/ T. Используя метод Монте-Карло, Stock показал, что на малых выборках это смещение может быть значительным, а также нашел выражения для предельного распределения оценок.
В двухшаговой процедуре, предлагаемой для этой коинтегрированной системы, оценка а из (4.5) используется как известный параметр при оценивании модели коррекции ошибок. Это существенно упрощает процедуру оценки путем наложения кросс-ограничений и позволяет специфицировать индивидуальные уравнения для динамических составляющих независимо друг от друга. Отметим, что для оценивания a не требуется специфицировать динамику. Удивительно, но эта двухшаговая оценка имеет превосходные свойства. Оказывается, она так же эффективна, как и оценка максимального правдоподобия, основанная на известном значении а , что устанавливается в приводимой ниже теореме.
Теорема 2. Двухшаговая оценка параметров уравнения в модели коррекции ошибки, использующая а из (4.5) как истинное значение а, имеет такое же предельное распределение, как и оценка максимального правдоподобия с истинным значением а. Стандартные ошибки метода наименьших квадратов будут состоятельными оценками истинных стандартных ошибок.
Доказательство. Перепишем первое уравнение системы в модели коррекции ошибок (3.4) следующим образом:
У = Yzt-i + Wtfi + st + у(zt-i — zt-i), zt = Xtа, zt = Xtoc,
где Xt = x’t, W — матрица, элементами которой являются Axt i, а y является элементом вектора Axt, так что все регрессоры имеют тип I(0). Опуская нижние индексы, получаем:
VT
Y -Y ß -ß
= [(z,W)'(z,W) / T]-1 [(z,W)'{e + y)(z — z)/ T] / VT.
Это выражение упрощается, потому что z'(z — z) = 0 . Из работ (Fuller, 1976) или (Stock, 1984) следует, что XX ¡T2 и XW/T имеют порядок 1. Значит,
W'(z — z)/yfr = [WX/T][T(a — a)]/[l/ VT],
и, следовательно, первый и второй коэффициенты справа от знака равенства имеют порядок 1, а третий стремится к нулю, так что все выражение асимптотически равно нулю. Так как слагаемые в (z — z)/VT в пределе исчезают, стандартные ошибки метода наименьших квадратов будут состоятельными.
Пусть S = plim[(Z,W)'(z,W)/T], тогда
VT
Y -Y ß -ß.
U D(0,а2S-1),
где D является предельным распределением. При дополнительных стандартных предположениях можно гарантировать нормальность этого распределения.
Для утверждения, что оценка с использованием истинного значения а имеет то же предельное распределение, достаточно показать, что предел по вероятности последовательно-
сти [(z,W) ‘(z,W)/T ] также равен S, и что zS
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Д/T
имеет то же предельное распределение,
что и z ‘s/JT . Рассмотрим сначала внедиагональные элементы S: -с
£
z W/Т — zW/Т = Т(а-а)'[W’X /T] /(1/T) . ^
Первый и второй коэффициенты имеют порядок 1, а третий коэффициент — порядок ^ 1/T , поэтому все выражение асимптотически обращается в ноль:
(z — z) ‘ (z — z) /T = z’z /T — zz /T = T(á -a) [XX /T2]T(á -a)(1 /T) .
Л
é
Снова первые три коэффициента имеют порядок 1, а последним коэффициентом явля-
о
ется 1/ Т , так что даже если разность между этими ковариационными матрицами будет по- £ ложительно определена, она асимптотически исчезнет. И, наконец,
(г — г)’е /л/Т = Т(а — а)Х£ / Т]1 / л/Т ,
что тоже асимптотически исчезает.
При выполнении стандартных условий оценка с использованием истинного значения а будет являться асимптотически нормальной и, следовательно, двухступенчатая оценка также будет асимптотически нормальной в этих условиях. Это завершает доказательство.
Приведем простой пример, который иллюстрирует многие из этих вопросов и обосновывает подход к тестированию, описываемый в следующем разделе. Предположим, что имеется два ряда, хи и х2(, которые совместно генерируются как функция от возможно коррелированных белых шумов еи и е2г в соответствии со следующей моделью:
ХИ + РХ21 = иИ , иИ = иИ-1 + £И , (4.7)
хи + ах21 = и21, и21 = ри2{-1 + е21., р< 1. (4.8)
Очевидно, параметры а и в являются неидентифицируемыми в обычном смысле, т. к. нет экзогенных переменных и ошибки коррелируют в один и тот же момент времени.
В приведенной форме этой системы ряды хи и х2, являются линейными комбинациями ии и и21, следовательно, оба имеют тип I(1). Второе уравнение описывает стационарную линейную комбинацию этих переменных. Таким образом, хи и х2( являются С1 (1,1) и вопрос состоит в том, можно ли это выявить и оценить параметры.
Удивительно, но это сделать легко. Линейная регрессии метода наименьших квадратов хи на х2( дает отличную оценку параметра а. Это и есть «коинтеграционная регрессия». Все линейные комбинации хи и х21, за исключением заданной уравнением (4.8), будут иметь бесконечную дисперсию, и, следовательно, метод наименьших квадратов легко сможет оценить а . Корреляция между х2( и и2г, которая приводит к смещению в одновременных уравнениях, имеет по Т более низкий порядок, чем дисперсии х2(. На самом деле обратная регрессия х2( на х1( имеет такие же свойства и, следовательно, дает состоятельную оценку параметра 1/ а. Эти оценки сходятся к истинному значению быстрее, чем в стандартных эконометрических моделях.
Хотя существуют и другие состоятельные оценки а, однако некоторые кажущиеся очевидными оценки таковыми не будут. Например, регрессия первых разностей хи на первые разности х2( не будет состоятельной, и использование процедуры Кохрейна-Оркатта или другой коррекции на автокорреляцию в коинтеграционной регрессии будет приводить к не-
состоятельным оценкам. После построения оценки параметра а другие параметры на ее основе могут быть оценены различными способами.
Для модели в (4.7) и (4.8) можно получить представление в виде авторегрессии, вычитая лагированные значения из обеих частей равенства и обозначая 8 = (1 — р) / (а — в)):
Дхи = в8хи-1 + аРхъ-1 , (4.9)
Ax2t = -8 хи-1 + а8 x2t-1 + п, (4.10)
где Г1 представляют собой линейную комбинацию е. Тогда модель коррекции ошибок приобретает следующий вид:
Дхи =р8г-1 , (4.11)
^ = -8-1 + П , (4.12)
где zt_1 = x1t + аx2t. В исходной модели есть три неизвестных параметра, представление в виде авторегрессии содержит четыре неизвестных коэффициента, в то время как модель коррекции ошибок содержит два параметра. После того как а становится известно, ограничение в модели коррекции ошибок, которое обуславливает двухшаговую оценку, исчезает. Отметим, что если р ^ 1, ряды превращаются в коррелированные случайные блуждания, которые не являются коинтегрированными.
5. тестирование коинтеграции
Проблема тестирования коинтеграции возникает довольно часто. Например, при ответе на вопрос, находится ли экономическая система в долговременном равновесии. Целесообразно также проверить подобную гипотезу прежде, чем оценивать многомерную динамическую систему.
К сожалению, эта ситуация является нестандартной, и проверка гипотезы не сводится к применению обычных тестов типа теста Вальда, отношения правдоподобия или теста множителей Лагранжа. Эта проблема тесно связана с задачей тестирования единичных корней в наблюдаемых рядах, которую первоначально сформулировали Fuller (1976) и Dickey, Fuller (1979,1981) и затем Evans, Savin (1981), Sargan, Bhargava (1983), Bhargava (1984) и Nelson, Plosser (1983). Она также связана с задачей тестирования с параметрами, не идентифицируемыми при нулевой гипотезе, как это описано в работах (Davies, 1977) и (Watson, Engle, 1982).
Для иллюстрации проблем, возникающих при тестировании подобных гипотез, рассмотрим простую модель (4.7) и (4.8). В данном случае нулевая гипотеза — это отсутствие коинтеграции или р = 1. Если бы параметр а был известен, то тест можно было построить по аналогии с тестом Дики-Фуллера, считая, что ряд zt имеет единичный корень при нулевой гипотезе. Уже в данном случае распределение не будет стандартным, оно вычислено с помощью метода Монте-Карло и описано в статье (Dickey, 1976). Однако, когда параметр а неизвестен, он должен быть оценен. Но если нулевая гипотеза утверждает, что р = 1, параметр а не идентифицируем. Таким образом, только если ряды коинтегрированы, а может быть просто оценен с помощью «коинтеграционной регрессии», но тест должен быть основан на распределении статистики, когда верна нулевая гипотеза. МНК строит оценку параметра а, минимизируя дисперсию остатков и делая остатки как можно более стацио-
нарными. Иными словами, тест Дики-Фуллера будет отвергать нулевую гипотезу слишком
часто, если параметр a оценивается. Ц
В этой статье предлагается набор из семи тестовых статистик для проверки нулевой ги- ¿L
потезы отсутствия коинтеграции против альтернативной гипотезы ее существования. Пред- %
„ „ Ч
полагается, что истинная система является двумерной линейной векторной авторегрессией ч^
с гауссовскими ошибками, причем каждый из рядов является I(1). Так как нулевая гипотеза ^
является составной, эти тесты строились таким образом, чтобы вероятность ее отвергнуть |
была постоянной по набору параметров, включенных в нулевую гипотезу. Более подробно ^
см. (Cox, Hinkley, 1974, pp. 134-136). ^
Можно выделить два случая. В первом случае система имеет первый порядок, и поэтому
нулевая гипотеза описывается соотношениями
Очевидно, что это — модель (4.11) и (4.12), когда р = 1, откуда следует, что 5 = 0. Составная нулевая гипотеза включает в себя все положительно определенные ковариационные матрицы О. Как будет показано ниже, распределения всех тестовых статистик инвариантны относительно матрицы О, поэтому без ограничения общности можно считать, что О = I.
Во втором случае предполагается, что система стационарна в разностях. Следовательно, нулевая гипотеза включает все коэффициенты стационарных моделей авторегрессии и скользящего среднего, а также О. Описываемые ниже «расширенные» тесты в этом случае имеют асимптотически инвариантные распределения подобно тому, что было установлено Дики и Фуллером для тестов в одномерном случае.
Семь предложенных тестовых статистик вычисляются с помощью метода наименьших квадратов. Для каждой из них путем моделирования 10000 повторений найдены критические значения. С использованием симуляций вычисляются мощности тестов для различных альтернатив. Ниже дается краткое описание каждого теста.
1. CRDW. Оценивается коинтеграционная регрессия и вычисляется статистика Дарбина-Уотсона (ОЖ) для проверки стационарности остатков. Если они не стационарны, ОЖстремится к нулю и, следовательно, если ОЖ принимает слишком большие значения, тест отвергает отсутствие коинтеграции (находит коинтеграцию). Этот тест был предложен Bhargava (1984) для случая, когда нулевая и альтернативная гипотезы являются моделями первого порядка.
2. БЕ Этот тест проверяет остатки коинтеграционной регрессии, оценивая дополнительную регрессию, как описано Дики и Фуллером и показано в табл. I. Также предполагается, что модель первого порядка верна.
3. АБЕ Расширенный тест Дики-Фуллера допускает более сложную динамику в регрессии DF и, следовательно, имеет слишком много параметров в случае модели первого порядка, но правильно специфицирован в случае высших порядков.
4. ЯУАЯ. Тест для векторной авторегрессии с ограничениями похож на двухшаговую оценку. На основании коинтеграционной регрессии оценивается коинтеграционный вектор, который затем участвует в оценке модели коррекции ошибок. Тест проверяет, является ли переменная коррекции ошибок значимой. Этот тест требует, чтобы динамика системы была полностью специфицирована. При этом предполагается, что система имеет первый порядок. Приведение системы к треугольному виду делает ошибки некоррелированными, и в пред-
4y = £it T(£it) ^Xt = S2t _(s2t )
~ N (0, Q) .
(5.1)
положении нормальности г-статистики будут независимы. Тест основан на сумме квадратов г-статистик.
5. ARVAR. Расширенный RVAR — тест аналогичен RVAR за исключением того, что система по предположению имеет более высокий порядок.
6. UVAR. Тест VAR без ограничения основан на векторной авторегрессии в уровнях при отсутствии ограничений на коинтеграцию. При нулевой гипотезе коинтеграции и так нет, поэтому тест просто проверяет, может ли модель быть выражена адекватно исключительно через разности. Снова, приводя матрицу коэффициентов к треугольной форме, можно независимо вычислить ^-статистики каждой из двух регрессий, и общая тестовая статистики будет являться их суммой, умноженной на их степени свободы, т. е. на 2. При этом вновь предполагается, что система имеет первый порядок.
7. AUVAR. Это расширенная версия предыдущего теста для систем более высокого порядка.
Чтобы установить сходство этих тестов в случае систем первого порядка для всех положительно определенных симметричных матриц О, достаточно показать, что остатки от регрессии у на х для общей матрицы О отличаются скалярным множителем от остатков для случая О = I. Чтобы установить это, предположим, что еи и еъ, являются независимыми стандартными нормальными случайными величинами. Тогда
У = Еек-, Ъ = Е£2, (5.2)
¿=1, г ¿=1,г
и ut = У1 — X ЕХг2 . (5.3)
Для создания у * и х * в случае произвольной матрицы О положим
4 = с£и, 4 = а£и + Ьем, (5.4)
где
С = , а = ®ух / С , Ь =®уу / ®хх .
Тогда, подставляя (5.4) в (5.2), получаем:
х* = сх , у* = ау + Ьх ,
ау( + Ьх1 — сх Е(ау( + Ьх1) сх^Е с2х2 = аи ,
что и устанавливает инвариантность распределений тестов. Если используются одни и те же случайные числа, вне зависимости от О будут получены одни и те же тестовые статистики.
В более сложном, но вполне реалистичной случае, когда система имеет бесконечный порядок, но может быть аппроксимирована авторегрессией порядкар, распределения статистики будут совпадать только асимптотически. Хотя точное совпадение достигается в гауссов-ских моделях с фиксированными регрессорами, в моделях временных рядов эта ситуация не реализуется, и совпадение только асимптотическое. Поэтому тесты 5 и 7 асимптотически подобны, если модель порядкар верна, но тесты 1, 2, 4 и 6 заведомо не являются даже асимптотически подобными, т. к. в них опущены лагированные значения переменных (ситуация аналогична возникновению смещений стандартных ошибок при наличии автокорреляции ошибочных членов). На этом основании мы предпочитаем не предлагать эти последние упо-
мянутые тесты, кроме случая первого порядка. Тест 3 также будет асимптотически подоб- ^
ным в предположении, что и, остаток от коинтеграционной регрессии, является процессом Ц
порядка p. Этот результат был доказан в статье (Dickey, Fuller, 1981, pp. 1065-1066). Хотя ¿L
предположение, что система имеет порядок p, допускает остатки бесконечного порядка, су- %
Ч
ществует, вероятно, конечная модель авторегрессии, возможно, меньшего порядка, чем p, ч^ которая будет хорошим приближением. Поэтому целесообразно провести некоторое ис- ^ следование для нахождения наиболее подходящего значения p в обоих случаях. Альтерна- | тивной стратегией является выбор параметра p, который медленно растет как неслучайная ^ функция от T, что тесно связано с тестом, предложенным Phillips (1985) и Phillips, Durlauf ¡^ (1985). Только численное моделирование позволит понять, предпочтительно ли использовать выбранное на основе данных p для этой тестовой процедуры, хотя ниже показано, что оценка лишних параметров приводит к снижению мощности теста.
В таблице I формально описаны статистики семи тестов. В таблице II представлены критические значения и мощности тестов, когда система имеет первый порядок. Следует ожидать, что расширенные тесты будут менее мощными, потому что они оценивают параметры, которые в действительности являются нулями и при нулевой, и при альтернативной гипотезах. Остальные четыре теста не оценивают внешние параметры и правильно специфицированы для этого эксперимента.
С помощью табл. II можно на 5%-ном уровне проверить гипотезу отсутствия коинтеграции, просто вычислив статистику Дарбина-Уотсона DW в коинтеграционной регрессии, и, если это значение DW превышает 0.386, отвергнуть нулевую гипотезу и найти коинте-грацию. Если истинная модель — это модель II с р = 0.9, а не 1, это будет выявлено только в 20% случаев; однако если р = 0.8, частота выявления составит 66%. Ясно, что тест 1 является лучшим по мощности и должен быть выбран для этой спецификации, а показатели теста 2 почти в каждом случае находятся на втором месте после теста 1. Заметим также, что расширенные тесты имеют практически те же критические значения, что и базовые, но, как и ожидалось, они имеют несколько меньшую мощность. Таким образом, если известно, что система имеет первый порядок, не следует вводить дополнительные лаги. Вопрос о том, полезен ли предварительный тест для установления порядка системы, остается открытым.
В таблице III и при нулевой, и при альтернативной гипотезах система есть авторегрессия четвертого порядка. Поэтому использование нерасширенных тестов приводит к неправильной спецификации, и корректным является применение расширенных тестов (хотя некоторые из промежуточных лагов могут быть обнулены, если это известно). Заметим, что уменьшение критических значений в тестах 1, 2, 4 и 6 вызвано отсутствием инвариантности распределения, о котором говорилось выше. При этих новых критических значениях тест 3 является самым мощным для локальной альтернативы, а при р = 0.8 тест 1 является лучшим, в то время как тесты 2 и 3 слегка уступают. Неправильно специфицированные или нерасширенные тесты 4 и 6 в этой ситуации работают плохо. Хотя таблица II демонстрирует их умеренную мощность, рассматривать их здесь нет необходимости.
Несмотря на то что тест 1 имеет в целом лучшее качество, его следует использовать с осторожностью, поскольку критическое значение очень чувствительно к значениям параметров в рамках нулевой гипотезы. Для большинства экономических данных разности не являются белым шумом, и поэтому на практике не всегда понятно, какими критическими значениями следует пользоваться. Тест 3, расширенный тест Дики-Фуллера, по существу, имеет то же критическое значение для обеих конечных выборок, использовавшихся в экс-
Таблица I. Тестовые статистики: отвергать нулевую гипотезу для больших значений
1. Коинтеграционная регрессия Дарбина-Уотсона yt = axt + c + ut. £1 = DW . Нулевая гипотеза: DW = 0.
2. Регрессия Дики-Фуллера: Dut = —ful—1 + et. £2 =тф : t статистика для ф.
3. Расширенная регрессия Дики-Фуллера: Dut = —фи1—1 + b1Aul—1 +… + blAul — p + st.
£3 =тф.
4. VAR с ограничениями: Dyt = b1ut—1 + e1t, Dxt = b2ut—1 + gDyt + e2t. £ =t2 +T2
£4 l01 + Lb 2′
5. Расширенная VAR с ограничениями: такая же, как в 4, но с p лагами Dyt и Dxt в каждом уравнении. £ =т2 +т2
£ 5 Lb1 + Lb 2′
6. VAR без ограничений: Dyt = b1yt—1 + b2xt—1 + c1 + e1t, Dxt = b3yt—1 + b4xt—1 + yDyt + c2 + e2t.
£6 = 2 [F¡ + F2 ] , где F1 — F-статистика для тестирования гипотезы о равенстве нулю b1 и b2 в первом уравнении, F2 — аналогичная F-статистика для второго уравнения.
7. Расширенная VAR без ограничений: такая же, как в 6, но с p лагами Dxt и Dyt в каждом уравнении.
у7 = 2[ F + F2 ]._
Примечание. yt и xt — исходные ряды данных, ut — остатки из коинтеграционной регрессии.
периментах, то же теоретическое критическое значение для большой выборки в обоих случаях, и почти такие же хорошо наблюдаемые свойства мощности в большинстве сравнений, и, значит, именно этот тест рекомендуется использовать.
Из-за своей простоты тест CRDW может быть применен для быстрого получения приближенного результата. Замечательно, что лучшие из предложенных тестов не требуют оценки всей системы, а только коинтеграционной регрессии, а затем, возможно, вспомогательных временных регрессий.
Этот анализ оставляет много вопросов без ответа. Критические значения построены только для выборки одного размера и только в двумерном случае, хотя в последнее время Engle, Yoo (1986) подсчитали критические значения для нескольких переменных и разных размеров выборки, используя тот же общий подход. Теории оптимальности для таких тестов пока нет, и, возможно, альтернативные подходы могут дать лучшие результаты. Исследования теории предельного распределения в статьях (Phillips, 1985) и (Phillips, Durlauf, 1985) могут привести к улучшению качества тестов.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Тем не менее, кажется, что критические значения для ADF, приведенные в табл. II, могут быть использованы как хороший ориентир в прикладных исследованиях по данному вопросу. В следующем разделе рассмотрены некоторые примеры.
6. примеры
Эмпирические примеры, рассматриваемые ниже, демонстрируют качество тестов на практике. Довольно подробно будет изучено соотношение между потреблением и доходом, подобно тому, как оно было проанализировано с помощью модели коррекции ошибок в (Davidson et al., 1978) и с помощью анализа временных рядов в работе (Hall, 1978) и дру-
Таблица II. Критические значения и мощность
I модель: Dyt, Dxt независимые стандартные нормальные, 100 наблюдений, 10 000 повторений, p = 4 .
Статистика
Название
Критические значения 1%
5%
10%
i CRDW 0.511 0.386 0.322
2 DF 4.07 3.37 3.03
3 ADF 3.77 3.17 2.84
4 RVAR 18.3 13.6 11.0
5 ARVAR 15.8 11.8 9.7
6 UVAR 23.4 18.6 16.0
7 AUVAR 22.6 17.9 15.5
II модель: yt + 2xt = ut. , Dut = (p-l)ut_ i +et, xt + У, =vt, Avt: = v,; p = 0.8,0.9 ,
100 наблюдений, 1000 повторений, p = 4.
Отклонений на 100: p = 0.9
Статистика Название 1% 5% 10%
i CRDW 4.8 19.9 33.6
2 DF 2.2 15.4 29.0
3 ADF 1.5 11.0 22.7
4 RVAR 2.3 11.4 25.3
5 ARVAR 1.0 9.2 17.9
6 UVAR 4.3 13.3 26.1
7 AUVAR 1.6 8.3 16.3
Отклонений на 100: p = 0.8
Статистика Название 1% 5% 10%
í
С) £
4 ¡
é
h-£
О
о.
CRDW
DF
ADF
RVAR
ARVAR
UVAR
AUVAR
34.0 20.5 7.8 15.8 4.6 19.0 4.8
66.4 59.2 30.9
46.2 22.4 45.9
18.3
82.1 76.1
51.6 67.4 39.0
63.7 33.4
гих. Более кратко анализируется связь заработной платы и цен, краткосрочных и долгосрочных процентных ставок. Обсуждение скорости обращения денег завершит этот раздел.
В работе (Davidson et al., 1978) приведены эмпирические и теоретические аргументы в пользу модели коррекции ошибок для описания потребительского поведения. Потребители формируют планы, которые могут не реализоваться. Тогда потребители корректируют планы на следующий период, чтобы компенсировать долю ошибки между доходом и по-
Таблица III. Критические значения и мощность с лагами
Модель I: Ay, = 0.8Ayt-4 + et, Axt = 0.8Axt-4 + r]t, 100 наблюдений, 10 000 повторений, p = 4,
et, r]t — независимые стандартные нормальные.
Критические значения
Статистика Название 1% 5% 10%
1 CRDW 0.455 0.282 0.209
2 DF 3.90 3.05 2.71
3 ADF 3.73 3.17 2.91
4 RVAR 37.2 22.4 17.2
5 ARVAR 16.2 12.3 10.5
6 UVAR 59.0 40.3 31.4
7 AUVAR 28.0 22.0 19.2
Модель II: yt + 2 xt = ut, Aut = (p-1)ut_ 4 + .8Aut-4 + et, yt + xt = vt, Avt = 0.8Avt-4 + p = 0.9, 0.8,
100 наблюдений, 1000 повторений, p = 4.
Отклонений на 100 : p = 0.9
Статистика Название 1% 5% 10%
1 CRDW 15.6 39.9 65.6
2 DF 9.4 25.5 37.8
3 ADF 36.0 61.2 72.2
4 RVAR 0.3 4.4 10.9
5 ARVAR 26.4 48.5 62.8
6 UVAR 0.0 0.5 3.5
7 AUVAR 9.4 26.8 40.3
Отклонений на 100 : p = 0.8
Статистика Название 1% 5% 10%
1 CRDW 77.5 96.4 98.6
2 DF 66.8 89.7 96.0
3 ADF 68.9 90.3 94.4
4 RVAR 7.0 42.4 62.5
5 ARVAR 57.2 80.5 89.3
6 UVAR 2.5 10.8 25.9
7 AUVAR 32.2 53.0 67.7
треблением. Hall считает, что потребление в США является случайным блужданием, и последние значения дохода не имеют объясняющей силы. Отсюда вытекает, что доходы и потребления являются некоинтегрированными, по крайней мере, если доход не зависит от переменной коррекции ошибок. Ни одна из рассмотренных теорий не моделирует доход сам по себе, и в (Davidson et al., 1978) он является экзогенным.
Используются квартальные данные реального потребления на душу населения товаров недлительного пользования и реального располагаемого дохода на душу населения в США Ц с 1947:1 по 1981: II. Первоначально было проверено, что временные ряды являются 7(1). ¿L При оценивании регрессии первой разности потребления на его прошлый уровень и две ^ первых лагированных разности было получено значение /-статистики, равное +0.77, даже ч^ знак этой статистики указывает на неверность гипотезы о стационарности потребления. ^ Оценивание аналогичной регрессии вторых разностей на прошлые значения первых раз- | ностей и два лагированных значения вторых разностей дает значение /-статистики, равное ^ -5.36, что свидетельствует о стационарности ряда первых разностей. Для дохода были ис- ¡^ пользованы четыре последних лага, и две /-статистики оказались равными -0.01 и -6.27 соответственно, что снова говорит о стационарности первой разности. Иными словами, доход также является I (1).
Было проведено оценивание коинтеграционной регрессии потребления на доход (Y ) и константу. Коэффициент при Y в этой регрессии равен 0.23 (со значениями /-статистики и R , равными 123 и 0.99 соответственно). Статистика DW оказалась равной 0.465, что в соответствии с обоими табличными критическими значениями позволяет отвергнуть нулевую гипотезу «отсутствия коинтеграции» на 5%-ном уровне, т. е. принять гипотезу о наличии ко-интеграции. Регрессия первой разности остатков на предыдущий уровень и четыре лагированных разности дает /-статистику для коэффициента при уровне, равную 3.1, что является 5%-ным критическим значением для ADF теста. Поскольку лаги незначимы, оценивается DF регрессия, которая дает значение тестовой статистики, равное 4.3, что является 1%-ным критическим значением. Это иллюстрирует тот факт, что если DF тест подходит, то он имеет большую мощность, чем ADF тест. В обратной регрессии Y на С коэффициент равен 4.3, обратное этому числу равно 0.23 — такое же, как коэффициент в прямой регрессии. Статистика DW теперь равна 0.463, и /-статистика теста ADF есть 3.2 . Опять обычный DF представляется целесообразным и дает тестовую статистику 4.4. Какую бы регрессию ни запускать, данные отвергают гипотезу отсутствия коинтеграции на любом уровне выше 5%.
Чтобы установить, что совместное распределение и Y является системой коррекции ошибок, оценивается несколько моделей. В таблице IV представлена векторная авторегрессия (без ограничения) разности потребления на четыре лагированных значения разности потребления и разности дохода плюс лагированные значения уровней потребления и дохода. Коэффициенты при лагированных значениях уровней потребления и дохода имеют «правильные» знаки, а коэффициенты при корректирующем слагаемом — «правильные» размеры. Эти коэффициенты индивидуально значимы или почти значимы. Из всех лагированных значений разностей значимым является только первый лаг разности дохода. Таким образом, итоговая модель включает переменную коррекции ошибок, оцененную из коинтеграцион-ной регрессии, и один лаг разности дохода. Стандартная ошибка этой модели даже ниже, чем модели VAR. Для этой модели был проведен ряд диагностических тестов на автокорреляцию, лаги зависимых переменных, нелинейность, ARCH и пропущенные переменные, такие как временной тренд и другие лаги.
Можно заметить, что удобная стратегия построения модели в этом случае предлагает оценить сначала простейшую модель коррекции ошибок, а затем тестировать значимость дополнительных лагов и Y, следуя методу «от частного к общему».
Подход к построению модели для дохода Y аналогичен. Оценивается та же векторная авторегрессия без ограничений, а затем она приводится к простой модели, содержащей кор-
Таблица IV. Регрессии дохода и потребления
C DEC DEC DC DEC
Y 0.23 (123)
C(-l) -0.19 (-2.5)
Y(-l) 0.046 (2.5)
EC(-l) -0.22 (-3.1) -0.26 (-4.3) -0.14 (-2.2)
AC(-l) 0.092 (0.9)
AC(-2) 0.017 (0.2)
AC(-3) 0.016 (1.5)
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
AC(-4) 0.009 (0.1)
AY(-l) 0.059 (1.8) 0.068 (2.5)
AY(-2) -0.023 (-0.7)
AY(-3) -0.027 (-0.8)
AY(-4) -0.020 (-0.7)
AEC( -1) -0.13 (-1.4)
AEC(-2) 0.12 (1.4)
AEC(-3) 0.03 (0.4)
AEC(-4) -0.13 (-1.6)
CONST 0.52 (85) 0.10 (2.4) 0.003 (2.6)
a 0.01628 0.00999 0.01015 0.01094 0.01078
DW 0.46 2.0 2.2 2.0 1.9
Y DEY DEY DY DY
C 4.29 (123)
C(-l) 0.15 (0.67)
Y (-1) -0.034 (0.63)
EY(-l) -0.053 (-1.1)
AC(-l) 0.79 (2.5) 0.66 (2.4)
AC(-2) -0.48 (-1.5)
AC(-3) 0.68 (2.2)
AC(-4) 0.56 (1.8) 0.60 (2.1)
AY(-l) -0.027 (-0.3)
AY(-2) -0.051 (-0.5)
AY(-3) 0.011 (0.1)
AY(-4) -0.23 (-2.5) -0.19 (2.1)
AEY(-l) -0.13 (-1.5)
AEY(-2) 0.12 (1.4)
AEY(-3) 0.03 (0.4)
AEY(-4) -0.14 (-1.6)
CONST 2.22 (-50) -0.071 (-0.6) 0.016 (4.6)
a 0.07012 0.04279 0.04350 0.03255 0.03321
DW 0.046 2.0 2.2 2.1 2.2
Примечание. Данные с 1947:1 по 1981:11. ЕС — остатки из первой регрессии, EY — остатки из шестой регрессии. В скобках указаны Г-статистики.
ректирующее слагаемое, первый и четвертый лаги первой разности и четвертый лаг первой разности У. Переменная коррекции ошибок в данном случае незначима (г-статистика
í
равна -1.1). Это означает, что доход может быть слабо экзогенным, даже несмотря на то, ¿L что переменные коинтегрированы. Стандартная ошибка в модели с ограничением немного ^ выше, но разница несущественна. Как и раньше, модель «выдерживает» соответствующие ч^ диагностические тесты. ^
Campbell (1985) применяет аналогичный подход для проверки гипотезы постоянства до- | хода, которая включает в себя поведение «экономия на черный день». В этом случае пере- ^ менная коррекции ошибок приближенно представляет сбережение, которое должно быть ^ больше, когда ожидается уменьшение дохода (например, когда текущий доход выше постоянного дохода). Расширяя меру потребления и сужая меру дохода, он получает значимой переменную коррекции ошибок в уравнении дохода.
Во втором примере анализируется связь между ежемесячной заработной платой и ценами в США. Данные представлены в логарифмах индекса потребительских цен и зарплаты работников обрабатывающей промышленности за три десятилетия — 50-е, 60-е и 70-е годы. Снова проводится тест в обоих направлениях, чтобы показать небольшое различие в результатах. Для каждого из десятилетий имеется 120 наблюдений, поэтому можно пользоваться табличными критическими значениями.
Для коинтеграционной регрессии по полной выборке статистика Дарбина-Уотсона в любом направлении равна 0.0054 . Она незначимо отличается от нуля даже для выборок, значительно больших, чем эта. Значение тестовой статистики в расширенном тесте Дики-Фуллера для p на w равно -0.6 и для w на p равно +0.2 . Добавление двенадцатого лага в ADF тестах приводит к существенному улучшению подгонки модели и увеличивает тестовую статистику до 0.88 и 1.50 соответственно. Ни в одном из случаев критическое значение 3.2 не достигается. Поэтому принимается нулевая гипотеза об отсутствии коинтеграции заработной платы и цен за период тридцать лет.
Для отдельных десятилетий ни один из ADF тестов не является значимым даже на 10%-ном уровне. Наибольшая из этих шести тестовых статистик для 50-х годов в регрессии p на w равна 2.4 , что все еще ниже 10%-ного уровня 2.8 . Таким образом, можно сделать вывод о том, что заработная плата и цены в США не коинтегрированы. Конечно, если бы была доступна третья переменная, например производительность, и она тоже была бы I (1), возможно, коинтеграция была бы выявлена.
В следующем примере исследуется коинтеграция краткосрочных и долгосрочных процентных ставок. В качестве долгосрочных ставок R используется ежемесячная доходность к погашению 20-летних государственных облигаций, а краткосрочная ставка rt — это ставка одномесячных казначейских векселей. Оценка коинтеграционной регрессии долгосрочной ставки на краткосрочную на промежутке времени с февраля 1952 г. по декабрь 1982 г. дает следующие результаты:
Rt = 1.93 + 0.785rt + ER, DW = 0.126, R2 = 0.866,
t-статистика коэффициента при короткой ставке равна 46 . В соответствии с табл. II и III статистика DW незначимо отличается от нуля, однако точное критическое значение зависит от динамики ошибок (и, конечно, размер выборки в 340 намного больше, чем для табличных значений). Результаты ADF теста с четырьмя лагами:
AER = -0.06 ER . + 0.25 AER . — 0.24 AER, 2 + 0.24 AER, 3 — 0.09 AER, 4.
‘ (-3.27) ‘ 1 (4.55) ‘ 1 (-4.15) ‘ 2 (4.15) ‘ 3 (-1.48) ‘ 4
Когда добавляется двенадцатый лаг вместо четвертого, тестовая статистика увеличивается до 3.49. Обратная регрессия дает похожие результаты: статистики равны 3.61 и 3.89 соответственно. Каждая из этих тестовых статистик превышает 5%-ные критические значения из табл. III. Поэтому эти процентные ставки можно считать коинтегрироваными.
Этот вывод полностью согласуется с гипотезой эффективного рынка. Однопериодная избыточная доходность долгосрочных облигаций в соответствии с линеаризацией (Shiller, Campbell, 1984) есть
EHY = DRt-1 — (D -1) Rt — rt, где D — дюрация облигации, определяемая равенством
D = ((1 + c)’ -1)/(c(1 + c)-1),
где c — ставка купона, i — число периодов до даты погашения. Гипотеза эффективного рынка предполагает, что ожидание EHY постоянно и представляет собой премию за риск, если агенты не склонны к риску. Определяя EHY = k + s и переставляя слагаемые, получаем модель коррекции ошибок
AR = (D -1)-1 (Rt-i — -i) + kt’+st,
в которой R и r являются коинтегрированными с единичным коэффициентом, и для длительных сроков погашения коэффициент при переменной коррекции ошибок равен c, т. е. ставке купона. Если премия за риск меняется с течением времени, но является рядом I (0), то не нужно включать ее в тест на коинтеграцию.
Последний пример основан на уравнении количественной теории: MV = PY. Эмпирические выводы вытекают из предположения, что скорость постоянна или, по крайней мере, стационарна. При этом условии logM, log P и log Y должны быть коинтегрированы с единичными параметрами. Также коинтегрированными должны быть номинальная денежная масса и номинальный ВНП. Была проведена проверка этой гипотезы для четырех денежных агрегатов: Mi, M2, M3 и L (все ликвидные активы). В каждом случае использовались квартальные данные с 1959: I по 1981: II. Ниже приведены статистики ADF тестов:
Ml 1.81 1.90
M2 3.23 3.13
M3 2.65 2.55
L 2.15 2.13
Первый столбец соответствует регрессиям, где зависимой переменной является логарифм соответствующего денежного агрегата, второй — логарифм ВНП. Только один из тестов для М2 значим на 5%-ном уровне, и ни один из других агрегатов не являются значимым даже на 10%-ном уровне (в некоторых случаях можно было бы использовать DF тест и получить большую мощность). Таким образом, наиболее устойчивое соотношение имеется между М2 и номинальным ВНП, а для других агрегатов коинтеграция и стационарность скорости отвергаются.
7. Выводы 8-
I
Если каждый элемент вектора временного ряда хг является стационарным только после
взятия первой разности, но при этом линейная комбинация а’хг является стационарной, ^
временной ряд хг является коинтегрированным порядка (1,1) с коинтегрирующим вектором ч^
а . Если интерпретировать равенство а’хг = 0 как долгосрочное равновесие, коинтеграция ^
означает, что долговременное равновесие существует с точностью до стационарных возму- |
о
е
а
Вф
статье приведено несколько представлений коинтегрированных систем, включая авто-
ои
щений с конечной дисперсией, даже если исходные временные ряды не являются стационарными и имеют бесконечную дисперсию.
регрессии и модель коррекции ошибок. Векторная авторегрессия в разностях несовместна с этими представлениями, потому что в ней отсутствует корректирующее слагаемое. Векторная авторегрессия в уровнях игнорирует перекрестные ограничения и порождает сингулярный авторегрессионный оператор. Обсуждается состоятельность и эффективность оценки моделей коррекции ошибок и описывается двухшаговая процедура оценивания. Для проверки коинтеграции предложены семь тестовых статистик. Методом Монте-Карло получены их критические значения. С помощью полученных критических значений исследованы мощности тестов, и одна из процедур тестирования рекомендована для применения.
Рассмотренные примеры показывают, что потребление и доход являются коинтегриро-ваными, а заработная плата и цены нет, краткосрочные и долгосрочные процентные ставки коинтегрированы, а номинальный ВНП не является коинтегрированным с М1, М3 или всеми ликвидными активами, но возможно, коинтегрирован с М2.
Департамент экономики Университета Калифорнии — Сан-Диего, США.
Рукопись получена в сентябре 1983 г., окончательный вариант получен в июне 1986 г.
Список литературы
Bhargava Alok (l984). On the theory of testing for unit roots in observed time series. Manuscript, ICERD, London School of Economics.
Box G. E. P., Jenkins G. M. (l970). Time series analysis, forecasting and control. San Francisco: Holden Day.
Campbell J. Y. (l985). Does saving anticipate declining labor income? An alternative test of the permanent income hypothesis. Manuscript, Princeton University.
Cox D. R., Hinkley C. V (l974). Theoretical statistics. London: Chapman and Hall.
Currie D. (l98l). Some long-run features of dynamic time-series models. The Economic Journal, 9l, 704-7l5.
Davidson J. E. H., Hendry D. F., Srba F., Yeo S. (l978). Econometric modelling of the aggregate time-series relationship between consumer’s expenditure and income in the United Kingdom. Economic Journal, 88, 66l-692.
Davies R. R. (l977). Hypothesis testing when a nuisance parameter is present only under the alternative. Biometrika, 64, 247-254.
Dawson A. (l98l). Sargan’s wage equation: A theoretical and empirical reconstruction. Applied Economics, l3, 35l-363.
Dickey D. A. (1976). Estimation and hypothesis testing for nonstationary time series. PhD. Thesis, Iowa State University, Ames.
Dickey D. A., Fuller W. A. (1979). Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74, 427-431.
Dickey D. A., Fuller W. A. (1981). The likelihood ratio statistics for autoregressive time series with a unit root. Econometrica, 49, 1057-1072.
Engle R. F., Hendry D. F., Richard J. F. (1983). Exogeneity. Econometrica, 51, 277-304.
Engle R. F., Yoo B. S. (1986). Forecasting and testing in co-integrated systems. UCSD Discussion Paper.
Evans G. B. A., Savin N. E. (1981). Testing for unit roots: 1. Econometrica, 49, 753-779.
Feller W. (1968). An introduction to probability theory and its applications, volume I. New York: John Wiley.
Fuller W. A. (1976). Introduction to statistical time series. New York: John Wiley.
Granger C. W. J. (1981). Some properties of time series data and their use in econometric model specification. Journal of Econometrics, 121-130.
Granger C. W. J. (1983). Co-integrated variables and error-correcting models. Unpublished UCSD Discussion Paper 83-13.
Granger C. W. J., Newbold P. (1977). Forecasting economic time series. New York: Academic Press.
Granger C. W. J., Newbold P. (1974). Spurious regressions in econometrics. Journal of Econometrics, 26, 1045-1066.
Granger C. W. J., Weiss A. A. (1983). Time series analysis of error-correcting models. In: Studies in Econometrics, Time Series, and Multivariate Statistics. New York: Academic Press, 255-278.
Hall R. E. (1978). A stochastic life cycle model of aggregate consumption. Journal of Political Economy,, 971-987.
Hannan E. J. (1970). Multiple time series. New York: Wiley.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Hendry D. F., von Ungern-Sternberg T. (1981). Liquidity and inflation effects on consumer’s expenditure. In: Essays in the Theory and Measurement of Consumer’s Behavior, ed. by A. S. Deaton. Cambridge: Cambridge University Press.
Johansen S. (1985). The mathematical structure of error correction models. Manuscript, University of Copenhagen.
Nelson C. R., Plosser C. (1982). Trends and random walks in macroeconomic time series. Journal of Monetary Economics, 10, 139-162.
Pagan A. R. (1984). Econometric issues in the analysis of regressions with generated regressor. International Economic Review, 25, 221-248.
Phillips A. W. (1957). Stabilization policy and the time forms of lagged responses. Economic Journal, 67, 265-277.
Phillips P. C. B. (1985). Time series regression with unit roots. Cowles Foundation Discussion Paper No. 740, Yale University.
Phillips P. C. B., Durlauf S. N. (1985). Multiple time series regression with integrated processes. Cowles Foundation Discussion Paper 768.
Salmon M. (1982). Error correction mechanisms. The Economic Journal, 92, 615-629.
Sargan J. D. (1964). Wages and prices in the United Kingdom: A study in econometric methodology. In: Econometric Analysis for National Economic Planning, ed. by P. E. Hart, G. Mills, and J. N. Whittaker. London: Butterworths.
Sargan J. D., Bhargava A. (l983). Testing residuals from least squares regression for being generated by a
the Gaussian random walk. Econometrica, 5l, l53-l74. ||
Shiller R. J., Campbell J. Y. (l984). A simple account of the behaviour of long-term interest rates. Ameri- |
can Economic Review, 74, 44-48. ^
Stock J. H. (1984). Asymptotic properties of least squares estimators of co-integrating vectors. Manu- ^
script, Harvard University. :><
Watson M. W., Engle R. F. (1985). A test for regression coefficient stability with a stationary AR(1) al- | ternative. Forthcoming in Review of Economics and Statistics4. ^
Yoo S. (1985). Multi-co-integrated time series and generalized error correction models. Manuscript in ¡^ preparation, U.C.S.D.
a.
Engle R. F., Granger C. W. J. Co-integration and error correction: Representation, estimation, and testing. Applied Econometrics, 2015, 39 (3), pp. 107-135 (translation in Russian from Econometrica, Vol. 55, No. 2 (March, 1987), 251-276).
Robert F. Engle
New York University Stern School of Business, USA Clive W. J. Granger
Co-integration and error correction: Representation, estimation, and testing
The relationship between co-integration and error correction models, first suggested in Granger (1981), is here extended and used to develop estimation procedures, tests, and empirical examples. If each element of a vector of time series x, first achieves stationarity after differencing, but a linear combination a’xt is already stationary, the time series x, are said to be co-integrated with co-integrating vector a. There may be several such co-integrating vectors so that a becomes a matrix. Interpreting a ‘ xt = 0 as a long run equilibrium, co-integration implies that deviations from equilibrium are stationary, with finite variance, even though the series themselves are nonstationary and have infinite variance. The paper presents a representation theorem based on Granger (1983), which connects the moving average, autoregressive, and error correction representations for co-integrated systems. A vector autoregression in differenced variables is incompatible with these representations. Estimation of these models is discussed and a simple but asymptotically efficient two-step estimator is proposed. Testing for co-integration combines the problems of unit root tests and tests with parameters unidentified under the null. Seven statistics are formulated and analyzed. The critical values of these statistics are calculated based on a Monte Carlo simulation. Using these critical values, the power properties of the tests are examined and one test procedure is recommended for application.
In a veries of examples it is found that consumption and income are co-integrated, wages and prices are not, short and long interest rates are, and nominal GNP is co-integrated with M2, but not Ml, M3, or aggregate liquid assets.
Keywords: co-integration; vector autoregression; unit roots; error correction; multivariate time series; Dickey-Fuller tests.
JEL classification: C01; C12; C30; C33; C51.
4 Опубликовано в Review of Economics and Statistics, l985, 67, 34l-346 — Прим. ред.
References
Bhargava Alok (1984). On the theory of testing for unit roots in observed time series. Manuscript, ICERD, London School of Economics.
Box G. E. P., Jenkins G. M. (1970). Time series analysis, forecasting and control. San Francisco: Holden Day.
Campbell J. Y. (1985). Does saving anticipate declining labor income? An alternative test of the permanent income hypothesis. Manuscript, Princeton University.
Cox D. R., Hinkley C. V (1974). Theoretical statistics. London: Chapman and Hall.
Currie D. (1981). Some long-run features of dynamic time-series models. The Economic Journal, 91, 704-715.
Davidson J. E. H., Hendry D. F., Srba F., Yeo S. (1978). Econometric modelling of the aggregate time-series relationship between consumer’s expenditure and income in the United Kingdom. Economic Journal, 88, 661-692.
Davies R. R. (1977). Hypothesis testing when a nuisance parameter is present only under the alternative. Biometrika, 64, 247-254.
Dawson A. (1981). Sargan’s wage equation: A theoretical and empirical reconstruction. Applied Economics, 13, 351-363.
Dickey D. A. (1976). Estimation and hypothesis testing for nonstationary time series. PhD. Thesis, Iowa State University, Ames.
Dickey D. A., Fuller W. A. (1979). Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74, 427-431.
Dickey D. A., Fuller W. A. (1981). The likelihood ratio statistics for autoregressive time series with a unit root. Econometrica, 49, 1057-1072.
Engle R. F., Hendry D. F., Richard J. F. (1983). Exogeneity. Econometrica, 51, 277-304.
Engle R. F., Yoo B. S. (1986). Forecasting and testing in co-integrated systems. UCSD Discussion Paper.
Evans G. B. A., Savin N. E. (1981). Testing for unit roots: 1. Econometrica, 49, 753-779.
Feller W. (1968). An introduction to probability theory and its applications, volume I. New York: John Wiley.
Fuller W. A. (1976). Introduction to statistical time series. New York: John Wiley.
Granger C. W. J. (1981). Some properties of time series data and their use in econometric model specification. Journal of Econometrics, 121-130.
Granger C. W. J. (1983). Co-integrated variables and error-correcting models. Unpublished UCSD Discussion Paper 83-13.
Granger C. W. J., Newbold P. (1977). Forecasting economic time series. New York: Academic Press.
Granger C. W. J., Newbold P. (1974). Spurious regressions in econometrics. Journal of Econometrics, 26, 1045-1066.
Granger C. W. J., Weiss A. A. (1983). Time series analysis of error-correcting models. In: Studies in Econometrics, Time Series, and Multivariate Statistics. New York: Academic Press, 255-278.
Hall R. E. (1978). A stochastic life cycle model of aggregate consumption. Journal of Political Economy,, 971-987.
Hannan E. J. (1970). Multiple time series. New York: Wiley.
APPLIED ECONOMETRICS / ПРИКЛАДНАЯ ЭКОНОМЕТРИКА_| 2015, 39 (3)
Hendry D. F., von Ungern-Sternberg T. (1981). Liquidity and inflation effects on consumer’s expendi- a
ture. In: Essays in the Theory and Measurement of Consumer’s Behavior, ed. by A. S. Deaton. Cambridge: ||
Cambridge University Press. | Johansen S. (1985). The mathematical structure of error correction models. Manuscript, University
of Monetary Economics, 10, 139-162.
Pagan A. R. (1984). Econometric issues in the analysis of regressions with generated regressor. International Economic Review, 25, 221-248.
£
of Copenhagen. ^
Nelson C. R., Plosser C. (1982). Trends and random walks in macroeconomic time series. Journal ^
!
é
h-&
Phillips A. W. (1957). Stabilization policy and the time forms of lagged responses. Economic Journal, 67, 265-277. 01
Phillips P. C. B. (1985). Time series regression with unit roots. Cowles Foundation Discussion Paper 740, Yale University.
Phillips P. C. B., Durlauf S. N. (1985). Multiple time series regression with integrated processes. Cowles Foundation Discussion Paper 768.
Salmon M. (1982). Error correction mechanisms. The Economic Journal, 92, 615-629. Sargan J. D. (1964). Wages and prices in the United Kingdom: A study in econometric methodology. In: Econometric Analysis for National Economic Planning, ed. by P. E. Hart, G. Mills, and J. N. Whittaker. London: Butterworths.
Sargan J. D., Bhargava A. (1983). Testing residuals from least squares regression for being generated by the Gaussian random walk. Econometrica, 51, 153-174.
Shiller R. J., Campbell J. Y. (1984). A simple account of the behaviour of long-term interest rates. American Economic Review, 74, 44-48.
Stock J. H. (1984). Asymptotic properties of least squares estimators of co-integrating vectors. Manuscript, Harvard University.
Watson M. W., Engle R. F. (1985). A test for regression coefficient stability with a stationary AR(1) alternative. Forthcoming in Review of Economics and Statistics.
Yoo S. (1985). Multi-co-integrated time series and generalized error correction models. Manuscript in preparation, U.C.S.D.
Раздел 11 регрессионный анализ для нестационарных переменных. коинтегрированные временные ряды. модели коррекции ошибок тема 11.1 проблема ложной регрессии. коинтегрированные временные ряды. модели коррекции ошибок
Проблема ложной регрессии
Начнем обсуждение с проблемы ложной (фиктивной, паразитной — spurious) регрессии. О ней говорилось в первой части учебника (см. пример 1.3.4 в разд. 1) и при этом был сделан вывод о том, что близость к 1 абсолютной величины наблюдаемого значения коэффициента детерминации необязательно означает наличие причинной связи между двумя переменными, а может являться лишь следствием наличия тренда значений обеих переменных.
ПРИМЕР 11.1.1
Смоделируем реализации двух статистически независимых между собой последовательностей єи и s2t независимых, одинаково распределенных случайных величин, имеющих стандартное нормальное распределение 7V(0, 1). Смоделированные реализации показаны на рис. 11.1 и 11.2. На их основе построим реализацию линейной модели DGP
DGP: xt = 1 +0.2t+sln
yt = 2 + 0At + e2n
в которой переменные х и у не связаны между собой причинными отношениями.
Рассмотрим, однако, результаты оценивания статистической модели
SM: yt = а + J3xt + st
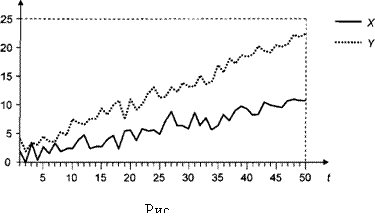 |
по смоделированной реализации. Графики рядов xt иу, приведены на рис. 11.3. Оба ряда имеют выраженные линейные тренды.
Оцененная статистическая модель приведена в табл. 11.1.
Оцененные коэффициенты статистически значимы, коэффициент детерминации высокий, проверка на адекватность не выявляет нарушений стандартных предположений классической линейной модели регрессии.
Включим в правую часть статистической модели линейный тренд. Оценивание расширенной модели дает следующий результат (табл. 11.2).
Остатки проходят тесты на адекватность, так что можно обратить внимание на протокол оценивания расширенной статистической модели. В соот ветствии с этим протоколом коэффициент при переменной xt статистически незначим, так что хп по существу, не проявляет себя в качестве переменной, объясняющей изменчивость значений переменной^.
ветствии с этим протоколом коэффициент при переменной xt статистически незначим, так что хп по существу, не проявляет себя в качестве переменной, объясняющей изменчивость значений переменной^.
Исключение xt из правой части уравнения приводит к оцененной модели (табл. 11.3), которая предпочтительнее расширенной модели и по критерию Акаике, и по критерию Шварца.
Более того, по этим критериям последняя модель намного предпочтительнее исходной модели j;, = а + j3xt + єг Это связано с тем, что при оценивании исходной SM остаточная сумма квадратов равна 233.59, а при оценивании
 последней модели — равна всего лишь 41.91. Это еще более убедительно подтверждает, что изменчивость переменной yt в действительности не объясняется изменчивостью переменной хгШ
последней модели — равна всего лишь 41.91. Это еще более убедительно подтверждает, что изменчивость переменной yt в действительности не объясняется изменчивостью переменной хгШ
В рассмотренном примере паразитная связь между переменными была обусловлена тем, что в модели DGP обе переменные имеют в своем составе детерминированный линейный тренд.
Однако ложная (паразитная) связь между переменными может возникать не только в результате наличия у этих переменных детерминированного тренда. Паразитная связь может возникать и между переменными, имеющими не детерминированный, а стохастический тренд. Приведем соответствующий пример.
ПРИМЕР 11.1.2
Возьмем процесс порождения данных в виде:
DGP: xt =х,_! + €и,
где єи и єь — те же, что и в примере 11.1.1. Графики рядов xt nyt показаны на рис. 11.4.
Предположим, что нам доступны статистические данные, соответствующие последним 50 наблюдениям (с 51-го по 100-е). Оценивание по этим наблюдениям статистической модели
SM: yt = а + j3xt + st
приводит к следующим результатам (табл. 11.4).
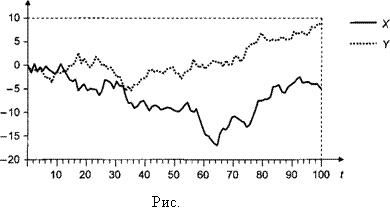 |
Таблица 11.4
Объясняемая переменная У
Sample: 51 100; Included observations: 50
|
Переменная |
Коэффициент |
Стандартная ошибка |
/-статистика |
Р-значение |
|
С |
8.616496 |
0.748277 |
11.515120 |
0.0000 |
|
X |
0.597513 |
0.077520 |
7.707873 |
0.0000 |
|
R-squared |
0.553120 |
Mean dependent var |
3.404232 |
|
|
Adjusted R-squared |
0.543810 |
S.D. dependent var |
3.354003 |
|
|
S.E. of regression |
2.265356 |
Akaike info criterion |
4.512519 |
|
|
Sum squared resid |
246.3283 |
Schwarz criterion |
4.589000 |
|
|
Log likelihood |
-110.8130 |
F-statistic |
59.41131 |
|
|
Durbin-Watson stat |
0.213611 |
Prob. (F-statistic) |
0.000000 |
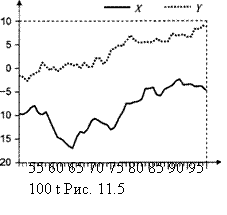 |
Несмотря на то что в DGP ряды yt и xt порождаются независимо друг от друга и их модели не содержат детерминированного тренда, здесь также наблюдаем довольно высокое значение коэффициента детерминации: 0.553. Конечно, это связано с тем, что на рассматриваемом периоде реализации обоих рядов имеют видимый тренд (рис. 11.5).
Если, однако, обратиться ко всему периоду из 100 наблюдений, то результаты оценивания будут совсем другими (табл. 11.5).
 В этом случае значение коэффициента детерминации близко к нулю, а оцененный коэффициент при xt равен 0.0551 против 0.5975, полученного при оценивании по наблюдениям с 51-го по 100-е. Это отражает действительное отсутствие детерминированного тренда в DGP и в связи с этим крайнюю нестабильность оценок коэффициента при хп полученных на различных интервалах. Последнее сопровождается также крайне низкими значениями статистики Дарбина — Уотсона (0.214 на полном периоде наблюдений и 0.062 на второй половине этого интервала). ■
В этом случае значение коэффициента детерминации близко к нулю, а оцененный коэффициент при xt равен 0.0551 против 0.5975, полученного при оценивании по наблюдениям с 51-го по 100-е. Это отражает действительное отсутствие детерминированного тренда в DGP и в связи с этим крайнюю нестабильность оценок коэффициента при хп полученных на различных интервалах. Последнее сопровождается также крайне низкими значениями статистики Дарбина — Уотсона (0.214 на полном периоде наблюдений и 0.062 на второй половине этого интервала). ■
Все указанные признаки являются характерными чертами, которые присущи результатам оценивания линейной модели связи между переменными, которые имеют стохастический (но не детерминированный!) тренд и порождаются статистически независимыми моделями. Теоретическое исследование подобной ситуации показывает следующее.
Пусть DGP: xt =xt_{ + єи, yt = yt_x + є2п где xQ = 0, yQ = 0, a eu и slt — статистически независимые между собой последовательности одинаково распределенных случайных величин, єи ~ N(0, <j{2 єь ~ N(0, сг^Х так что Cov(xn yt) = 0. Предположим, что по Т наблюдениям (хп yt)9 t 1,2, Г, производится оценивание статистической модели
SM: yt = j3xt + ип ut i.i.d. 7V(0, <тм2), Cov(xn ut) = 0.
Стандартная оценка наименьших квадратов для коэффициента J3 в этой гипотетической модели имеет вид:
т
t=
При сделанных предположениях относительно DGP оценка /3Т не сходится по вероятности при Т -> оо ни к какой константе и имеет предельное распределение, отличное от нормального.
Вместе с тем при выбранной спецификации SM (статистической модели), в предположениях этой модели (а не DGP!) имеем
Cov(xt, yt) = Cov(xn J3xt+ut) = j3Cov(xn xt) = /?£)(*,),
т.е. оцениваемым параметром является
Cov(xnyt) D(xt)
Поскольку в действительности (в DGP) Cov(xn yt) = О, то и это значение J5 равно нулю, так что если бы гипотетическая модель (соответствующая SM) была верна, то имело бы место J3T —> О по вероятности.
Далее, при Т -> со значения /-статистики tp для проверки гипотезы Я0: J3= О неограниченно возрастают по абсолютной величине, так что использование таблиц /-распределения будет практически всегда приводить к отклонению этой гипотезы, т.е. к выводу о том, что между переменными xt и yt существует линейная регрессионная связь. В действительности нетривиальное предель1
ное распределение имеет не статистика tfi9 а статистика —f=tp, причем прел/71
дельное распределение последней является нестандартным.
Что касается статистики Дарбина — Уотсона (DW), то в рассматриваемой ситуации DW —> 0 по вероятности при Т —» оо, и это позволяет распознавать неправильную спецификацию статистической модели в форме паразитной регрессии. Последнее обстоятельство проявляется в поведении остатков от оцененной статистической модели, которое не соответствует поведению стационарного процесса.
ПРИМЕР 11.1.3
В предыдущем примере было задано
DGP: xt =xt_x + єи, y,=yt-x +еЬ9
где єи и s2t — последовательности независимых, одинаково распределенных случайных величин, имеющих стандартное нормальное распределение yV(0, 1).
Мы оценивали статистическую модель
SM: yt = а + Pxt + st
и по наблюдениям с 51-го по 100-е получили
рТ = 0.598, /, = 7.708, DW= 0.214.
При этом график остатков (рис. 11.6) не похож на график стационарного ряда.И
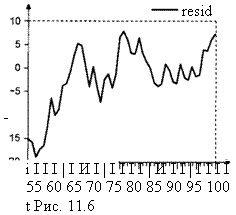 Естественно было бы для выявления такого «неподобающего» поведения остатков не просто увидеть график остатков, но и попытаться использовать формальные статистические критерии, тем более что критерии проверки интегрированное™ временных рядов были рассмотрены ранее (критерии Дики — Фуллера, Филлипса — Перрона и др.).
Естественно было бы для выявления такого «неподобающего» поведения остатков не просто увидеть график остатков, но и попытаться использовать формальные статистические критерии, тем более что критерии проверки интегрированное™ временных рядов были рассмотрены ранее (критерии Дики — Фуллера, Филлипса — Перрона и др.).
Проблема, однако, в том, что теперь мы имеем дело не с «сырым» рядом, а с рядом остатков, которые вычисляются после предварительного оценивания модели (коэффициентов а и Р в последнем примере). Это обстоятельство существенно влияет на распределения соответствующих статистик и не дает возможности пользоваться таблицами, которые были использованы ранее при анализе на интегрированность «сырых» рядов. С учетом этого были построены таблицы, позволяющие производить анализ остатков в случае интегрированных объясняемой и объясняющих переменных, о чем подробнее будет сказано в теме 11.2. Сейчас же только покажем, что дает применение соответствующих таблиц к рассмотренному выше примеру.
ПРИМЕР 11.1.4
При оценивании статистической модели SM: yt = а + Pxt + st по наблюдениям с 51-го по 100-е получили оцененную модель
yt = 8.616 + 0.598х, + е,.
С полученным рядом остатков поступим так же, как и в случае применения критерия Дики — Фуллера к «сырому» ряду, т.е. оценим модель
Aet = (pet_ j + V,
и вычислим /-статистику / для проверки гипотезы Я0: 0, интерпретируя эту гипотезу как гипотезу единичного корня для ряда остатков.
Гипотеза Н0 отвергается в пользу НА: (р < 0 (интерпретируемой как гипотеза стационарности ряда остатков), если /^ < /крит. Приближенные значения /крит (в применении к ряду остатков) можно найти по формуле: ^крит ~ к™ + КТ + ,
где к^, кх, лг2 зависят от выбранного уровня значимости и указаны в табл. П-9 в Приложении к заданиям для семинарских занятий… (MacKinnon, 1991). Для 5%-го уровня значимости
/крит * -3.3377 5.967Г»1 8.98Г»2,
что при Т = 50 дает /крит = -3.46. Последнее значение существенно меньше 5%-го критического значения статистики Дики — Фуллера (-2.92), рассчитанного для случая «сырого» ряда.
В нашем примере оценивание тестового уравнения Дики — Фуллера дает значение f = -2.01. Последнее существенно выше 5%-го критического уровня, и гипотеза единичного корня не отвергается. ■
Вообще говоря, вопрос о ложной (паразитной) или неложной (действительной) линейной регрессионной связи между двумя переменными xt и уп представляющими интегрированные ряды первого порядка (xt, yt ~ 7(1)), более точно формулируется следующим образом: существует ли такое значение Д при котором ряд yt Де, стационарен?
Если ответ на этот вопрос положительный, то говорят, что ряды xt и yt (переменные xt и yt) коинтегрированы (cointegrated time series). Если же ответ оказывается отрицательным, то ряды xt и yt (переменные xt и yt) не являются коинтегрированными.
В последнем случае непосредственное оценивание модели yt = а + f3xt + ut
бессмысленно, так как получаемая оценка J3T, собственно говоря, не является оценкой какого-либо теоретического параметра связи между переменными xt nyt (см., впрочем, ниже замечание 11.1.6).
Напротив, если переменные xt и yt коинтегрированы, то (3Т является оценкой того единственного значения Д при котором ряд jy, J3xt стационарен. Заметим теперь, что если в
DGP: xt =xt_{ + єи,
Уг=Уг+£lt
допустить коррелированность значений єи и slt в совпадающие моменты времени, т.е. Cov(slt, s2t) * 0, то коррелированность єи и s2t вовсе не означает, что ряды xt и yt коинтегрированы. Предположим все же, что существует некоторое значение Д при которому, = j5xt + ut, где ut — стационарный ряд. Тогдаyt_x = /3xt_x + ut_x, так что Ayt = (5Axt + Aut, а отсюда єь = /Зєи + Aut. Последнее можно записать в виде ut -ut_x + rjt, где
Пі = £it ~P£ ~ iidN(09 rf). Но это означает, что ut — нестационарный процесс. В то же время если х0 = у0 = 0, то
Cov(xt,yt) = Cov(sn + … + єи, є2Х + … + єь) = tCov(slu є2)9
так что xt и yt — коррелированные, но не коинтегрированные случайные блуждания.
Существенно, что распределение статистики Дики — Фуллера в подобной ситуации не зависит от конкретного вида матрицы ковариаций
І, = (Соу(єкІ9єЯІ))9 k9s =192.
Тем же свойством обладает и распределение статистики Дарбина — Уотсона, примененной к ряду остатков (CRDW — cointegrating regression DW)
et=yt~ dTpTxt.
При T = 50 5%-е критическое значение последней статистики равно 0.78. Гипотеза некоинтегрированности рядов отвергается, если наблюдаемое значение этой статистики превышает критическое значение.
В примере 11.1.3 значение статистики Дарбина — Уотсона равно 0.214, так что гипотеза некоинтегрированности не отвергается и этим критерием.
Что следует предпринять в случае обнаружения паразитной связи между интегрированными порядка 1 переменными xt nyt? Имеются три возможных пути обхода возникающих здесь трудностей.
1. Включить в правую часть уравнения запаздывающие значения обеих переменных, точнее, рассмотреть статистическую модель
SM: yt = а+ уУг+ Pxt + $xt+ ип где ut — стационарный ряд и переменная xt трактуется как экзогенная переменная.
Последнее уравнение можно записать иначе в следующих двух формах:
а) yt = а+ ryt+ + (/? + S)xt_x + щ9
б) yt = а+ ryt-i S)xt SAxt + ut9
В обеих формах слева стоит интегрированная переменная^ ~/(1).
В правой части уравнения а) параметр J3 является коэффициентом при стационарной переменной Ахп имеющей нулевое математическое ожидание; yt_l9 xt_x ~ 1(1), ut — стационарный ряд. Как было показано в (Sims, Stock, Watson, 1990), в такой ситуации оценки наименьших квадратов для всех коэффициентов SM состоятельны, оценка параметра Д асимптотически нормальна. Обычная /-статистика для проверки гипотезы Я0: Р = 0 имеет асимптотически нормальное распределение N(0, 1), если ut — белый шум.
Аналогично в правой части уравнения б) параметр -8 является коэффициентом при стационарной переменной Ахп имеющей нулевое математическое ожидание; yt_l9 xt ~ 1(1), ut — стационарный ряд. Поэтому оценка параметра 8 в рамках модели SM асимптотически нормальна, и /-статистика для проверки гипотезы Н0: 8 = 0 имеет асимптотически нормальное распределение N(0, 1), если ut — белый шум.
Оценки для Р и 8 остаются асимптотически нормальными и в том случае, если ut — стационарный ряд, не являющийся белым шумом. Однако при этом асимптотическое распределение N(0, 1) имеет скорректированные варианты /-статистик, в знаменателях которых стандартные оценки дисперсии ряда ut заменяются состоятельными оценками долговременной дисперсии этого ряда, определенной в теме 10.2.
В то же время статистика qF = 2F для проверки гипотезы Н0: Р = 8 = О
не имеет асимптотического распределения ;f2(2), поскольку рассматриваемую SM не удается линейно репараметризовать таким образом, чтобы в правой части преобразованного уравнения и р и 8 одновременно стали коэффициентами при стационарных переменных, имеющих нулевые математические ожидания (у нас они становятся таковыми при разных репараметризациях).
Перед оцениванием модели связи продифференцировать ряды xt и уп т.е. рассмотреть модель в разностях
SM: Ay, = а + ДДх, + ип
где ut — стационарный ряд.
В этой модели оценки наименьших квадратов и для а, и для Р асимптотически нормальны. Обе /-статистики имеют асимптотически нормальное распределение N(0, 1), если ut — белый шум. Если ut — стационарный ряд, не являющийся белым шумом, то необходимо произвести коррекцию /-статистик, как в предыдущем пункте.
Использовать для оценивания модель регрессии с автокоррелированными остатками:
SM: yt = а + Pxt + ип ut = pxt_x + єп ut ~ i.i.d. N(0, a]),
При этом предпочтительнее оценивать все три параметра а, Д, р одновременно, используя представление
Уг-РУг= а(1 -Р) + Р(Х,-РХ,_Х) + ЄГ
В случае ложной регрессии р —> 1 (по вероятности), так что при больших Т этот метод фактически равносилен предварительному дифференцированию рядов.
ПРИМЕР 11.1.5
Применим указанные три подхода к анализу реализаций, смоделированных ранее в данном разделе в соответствии с
DGP: xt =xt+ єп
где єи и slt — последовательности независимых, одинаково распределенных случайных величин, имеющих стандартное нормальное распределение 7V(0, 1).
Для анализа используем последние 50 наблюдений.
 Применив первый подход, получим оцененную модель, приведенную в табл. 11.6.
Применив первый подход, получим оцененную модель, приведенную в табл. 11.6.
Наблюдаемые Р-значения для коэффициентов при переменных xt и xt_x указывают на то, что переменная xt фактически не объясняет изменчивость переменной уг
Применив второй подход, получим оцененную модель, приведенную в табл. 11.7.
 Оба коэффициента статистически незначимы, и это отражает некоррелированность рЯДОВ Єи И £1г.
Оба коэффициента статистически незначимы, и это отражает некоррелированность рЯДОВ Єи И £1г.
Применив третий подход, оценим модель
yt -pyt.x = a(l -р) + J3(xt -pxt_x) + єп
т.е.
 Уг = a+Pyt+ A*r -Pxt-i) + *r При этом получим следующие результаты (табл. 11.8).
Уг = a+Pyt+ A*r -Pxt-i) + *r При этом получим следующие результаты (табл. 11.8).
Как и ожидалось, коэффициент при оказался очень близким к 1, а два других коэффициента статистически незначимы. Проверка на одновременное зануление этих двух коэффициентов дает Р-значение 0.367.■
ПРИМЕР 11.1.6
Изменим процесс порождения данных, оставляя те же формулы для xt и уп т.е.
Xt — Xt_ і + £f, yt=yt-x +£2r
Но теперь пусть:
s -> £2t — последовательности независимых, одинаково распределенных случайных величин, имеющих нормальное распределение N(0, 1.25); Cov(su, s2s) 0 для t*s, Cov(su, s2t) = 1.
Отсюда, в частности, следует, что Согг(єи, s2t) = 0.8.
Смоделированные реализации єи и s2t изображены на рис. 11.7.
Траектории смоделированной пары рядов єи и є2і ведут себя достаточно согласованным образом, оцененный коэффициент корреляции между этими рядами равен 0.789. Полученные при этом реализации рядов xt nyt ведут себя так, как показано на рис. 11.8. Для сравнения на рис. 11.9 изображено поведение реализаций рядов хг и уг при полной статистической независимости
рЯДОВ £и И Є2г
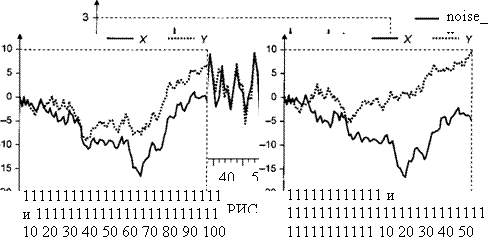 Для сопоставимости с ранее полученными результатами опять обратимся ко второй части отрезка наблюдений; здесь оцененный коэффициент корреляции между рядами еи и e2t равен 0.792.
Для сопоставимости с ранее полученными результатами опять обратимся ко второй части отрезка наблюдений; здесь оцененный коэффициент корреляции между рядами еи и e2t равен 0.792.
Сначала оценим модель yt = а + J3xt + иг В результате получим для ряда остатков значение статистики Дики — Фуллера, равное -2.112, которое выше 5%-го критического уровня -3.46. Соответственно гипотеза о ложности регрессионной связи не отвергается.
Применив первый подход, получим оцененную модель, приведенную в табл. 11.9.
По сравнению с ранее рассмотренным случаем, где ряды єи и еъ были между собой статистически не связанными, теперь оказываются статистически значимыми и коэффициенты при переменных xt и xt_!. Исключив из правой части модели константу, получим табл. 11.10.
 То есть>>г = .005yt_x + 0.695л;, 0.101 xt_x + et. Оценка коэффициента при^_! близка к 1, оцененные коэффициенты при xt и xt_x близки по абсолютной величине и противоположны по знаку, что вполне согласуется с реализованной моделью DGP.
То есть>>г = .005yt_x + 0.695л;, 0.101 xt_x + et. Оценка коэффициента при^_! близка к 1, оцененные коэффициенты при xt и xt_x близки по абсолютной величине и противоположны по знаку, что вполне согласуется с реализованной моделью DGP.
Объясняемая переменная D(Y)
 Применив второй подход, получим оцененную модель, приведенную в табл. 11.11.
Применив второй подход, получим оцененную модель, приведенную в табл. 11.11.
И здесь в отличие от ранее использовавшегося DGP становится значимым коэффициент при переменной Ахп что отражает коррелированность случайных величин єи и s2t, т.е. коррелированность Axt и Ауг Исключив из правой части уравнения статистически незначимую константу, получим результаты, приведенные в табл. 11.12.
 То есть Ayt = 0.7ЮДх, 4еп ишу{ = yt_x + 0.710jc, 0.710хг_! 4et. Наконец, применив третий подход, оценим модель
То есть Ayt = 0.7ЮДх, 4еп ишу{ = yt_x + 0.710jc, 0.710хг_! 4et. Наконец, применив третий подход, оценим модель
yt = a+ pyt.! + j3(xt -pxt_х) + єг
 При этом получим табл. 11.13.
При этом получим табл. 11.13.
Объясняемая переменная У
Convergence achieved after 8 iterations; У=С(1)+С(2)*У(-1)+С(3)*(Х-С(2)*Х(-1))
Объясняемая переменная У
Convergence achieved after Л iterations; У=С(2)*У(-1)+С(3)*(Х-С(2)*Х(-1))

Здесь становится статистически значимым коэффициент Д Исключение из правой части константы дает табл. 11.14.
То есть
yt = 1.014уг_! + 0.702(jc, №4xt_x) + en
или
yt = 1.014>>,_i + 0.702jc, 0.712jcr_! + er
Отметим близость результатов, полученных тремя методами:
yt = 1.005^.! + 0.695jc, 0.707х,_! + et (метод 1);
yt = yt-X + 0.71 Ox, 0.7 Юх^ 4et (метод 2);
yt = 1.014^_! + 0.702x, 0.712jc,_! + e, (метод 3).
Фактически во всех трех случаях воспроизводится одна и та же линейная модель связи между рядами разностей:
Ду, = 0.7Дх, 4ег
Эта регрессионная связь между продифференцированными рядами не является ложной (в отличие от регрессионной связи между рядами уровней): статистика Дарбина — Уотсона принимает значение 1.985, Р-значение критерия Харке — Бера равно 0.344.■
у/ Замечание 11.1.1. В связи с результатами, полученными в последних примерах, естественно возникает следующий вопрос, который поднимался в свое время различными исследователями. Не будет ли разумным, имея дело с рядами, траектории которых обнаруживают выраженный тренд, сразу приступать к оцениванию связей между рядами разностей (между продифференцированными рядами)?
Против некритичного использования такого подхода говорят два обстоятельства:
если ряды в действительности стационарны относительно детерминированного тренда, то дифференцирование приводит к передифференцированным рядам, имеющим необратимую МА-составляющую;
если ряды являются интегрированными порядка 1 и при этом коинтегрированы, то при переходе к продифференцированным рядам теряется информация о долговременной связи между уровнями этих рядов.
Дифференцирование рядов оправданно и полезно, если ряды являются интегрированными, но при этом между ними отсутствует коинтеграционная связь.
Коинтегрированные временные ряды
Пусть yt ~ 7(1), х, ~ ДО). Строить регрессию уг на xt в этом случае бессмысленно, так как для любых аиЬв такой ситуации
yt a bxt ~/(1).
Пусть, наоборот, yt ~ 1(0), xt ~ 7(1). Для любых аиЬ^О здесь опять
yt a bxt ~/(1)
и только при Ь = 0 получаем
yt-a-bxt -1(0%
так что и в таком сочетании строить регрессию одного ряда на другой не имеет смысла.
Пусть теперь^ ~ 7(1), xt ~1(1) — два интегрированных ряда. Если для любого Ъ
yt-bxt ~/(1),
то регрессия yt на xt является фиктивной, и мы уже выяснили, как следует действовать в такой ситуации.
Обратимся теперь к случаю, когда при некотором ЬфО
yt bxt ~ 1(0) — стационарный ряд.
Если это так, то ряды yt и xt называют коинтегрированными, а вектор (1, -Ь)Т— коинтегрирующим вектором (cointegrating vector).
Вообще, ряды^г ~ 1(1), xt ~1(1) называют коинтегрированными (в узком смысле — детерминистская коинтеграция, deterministic cointegration), если существует ненулевой (коинтегрирующий) вектор Р= (Рх, J32)T * 0, для которого
Pxxt + P2yt ~ 1(0) — стационарный ряд.
Заметим, что если вектор /? = (Д, р2)Т является коинтегрирующим для рядов xt nyt, то коинтегрирующим для этих рядов будет и любой вектор вида с/? = (сД, сР2)т, где с ф 0 — постоянная величина. Чтобы выделить какой-то определенный вектор, приходится вводить условие нормировки (normalization) — например, рассматривать только векторы вида (1, -Ь)т (или только векторы (-а, )т).
Поскольку предполагаем в данном случае, что xt,yt ~ 1(1), то ряды разностей Дх,, Ayt стационарны. Будем предполагать в дополнение, что стационарен векторный ряд (Axt, Ayt)T и для него существует представление в виде векторного скользящего среднего (VMA)
(Axt, Ayt)T = ju +B(L)st, где /£ = (jil9 ju2)T, ju{ = E(Axt), ju2 = E(Ayt), 6t = (eXt, s2t)T — векторный белый шум,
т.е. єх, є2, … — последовательность не коррелированных между собой, одинаково распределенных случайных векторов, для которых
E(st) = (О, 0)Т, d(sXt) = <jx, d(s2t) = <j2, Cov(sXt, є2і) = an— постоянные величины;
B(L) =
О 1
+ 1
k =
(h{k) h(k)
Uik) r(k) u2l u22 J
Таким образом, предполагается, что разложение Вольда центрированного векторного ряда (Дх„ Ayt)Tju не содержит линейно детерминированной компоненты.
Знаменитый результат Грейнджера (см. (Granger, 1983), а также (Engle, Granger, 1987)), состоит в том, что в случае коинтегрированности 7(1) рядов xt nyt (в узком смысле):
в представлении (Axt, Ayt)T = ju + B(L)st матрица 5(1) имеет ранг 1;
система рядов xt и yt допускает векторное ARMA представление
A(L)(xt,yt)T = c + d(L)st,
где et — тот же векторный белый шум, что и в (I); с = (сх, с2)Т, сх и с2 — постоянные; А(Ь)— матричный полином от оператора запаздывания; d(L) — скалярный полином от оператора запаздывания,
причем ДО) = 12 (единичная матрица размера (2 х 2)),
rank А() = 1 (ранг (2 х 2)-матрицыЛ(1) равен 1), значение d() конечно.
В связи с тем что в последнем представлении ранг (2 х 2)-матрицы А() меньше двух, об этом представлении часто говорят как о векторной авторегрессии пониженного ранга (reduced rank VAR).
В развернутой форме представление (II) имеет вид:
Р ч
xt = ci + ХКЛ-У Y*ek*u-k>
7=1 k = 0
Р Я
Уі~С2 + Z(*2/*f-y +b2jyt_j)+ YuekS2,t-k7=1 k = 0
При этом верхние пределы р и q у сумм в правых частях могут быть бес-конечными.
Если возможно векторное AR представление, то в нем d(L) =1,р <ю.
Система рядов xt и yt допускает представление в форме модели коррекции ошибок (error correction model — ЕСМ)
00 00
Axt =fix + axzt_x + Х(Гі7-Л*,-7 +sijAyt-j)+ Z^*u-*>
7=1 k=0
00 00
Ayt = //2 + a2zt_x + Y.iYij A*,-; + S2J Ayt_j) + ^0ke2tt_k,
7=1 k=0
где zt=yt J3xt E(yt J3xt) — стационарный ряд с нулевым математическим ожиданием, zt ~ 1(0); ах2 + ai > 0.
Если в (II) возможно векторное AR(p) представление (р < оо), то ЕСМ принимает вид:
РAxt=px+axzt_x + Y, (Г и Л*, -у + sj ДУг -j ) +
7 = 1
Ayt = р2 + a2zt_x + £(^f Дх,_, + ДУг-у) + *2,г
7 = 1
Здесь важно отметить следующее.
Если ряды xt, yt ~ 1(1) коинтегрированы, то все составляющие в ЕСМ стационарны.
Если векторный ряд (xt, yt)T ~ 1(1) (так что векторный ряд (Дх„ Ayt)T стационарен) и порождается ЕСМ-моделью, то ряды xt и yt коинтегрированы. (Действительно, в этом случае все составляющие ЕСМ, отличные от zt_х, стационарны, но тогда стационарна и z,_ х.)
Если ряды xt, уг ~1(1) коинтегрированы, то VAR в разностях не может иметь конечный порядок (в отличие от случая, когда ряды xt и yt не коинтегрированы).
Абсолютную величину zt-yta-J3xt, где а = E(yt J3xt), можно рассматривать как расстояние, отделяющее систему в момент t от равновесия (equilibrium), задаваемого соотношением yt a-fixt = 0. Величины и направления изменений хг и yt принимают во внимание величину и знак предыдущего отклонения от равновесия zt_x. Ряд zt, конечно, вовсе не обязательно убывает по абсолютной величине при переходе от одного периода времени к другому, но он является стационарным и поэтому расположен к движению по направлению к своему среднему (mean-reversion).
Замечание 11.1.2. Переменная xt не является причиной по Грейнд-жеру для переменной уt, если неучет прошлых значений переменной xt не приводит к ухудшению качества прогноза значения yt по совокупности прошлых значений этих двух переменных. Переменная yt не является причиной по Грейнджеру для переменной xt, если неучет прошлых значений переменной yt не приводит к ухудшению качества прогноза значения xt по совокупности прошлых значений этих двух переменных1. (Качество прогноза измеряется среднеквадрати-ческой ошибкой прогноза.)
В четвертой части учебника рассмотрим более подробно вопросы, связанные с определением причинности по Грейнджеру.
Если xt, yt ~1(1) и коинтегрированы, то должна иметь место причинность по Грейнджеру (Granger causality), по крайней мере, в одном направлении. Этот факт вытекает из представления такой системы рядов в форме ЕСМ, в которой ах + а2 > 0. Значение xt_x через посредство zt_ х помогает в прогнозировании значения yt (т.е. переменная хг является причиной по Грейнджеру для переменной yt), если а2 ф 0. Значение yt_ х через посредство zt_, помогает в прогнозировании значения xt (т.е. переменная yt является причиной по Грейнджеру для переменной xt), если ах ф 0.
Замечание 11.1.3. Пусть xt, yt ~ 1(1) коинтегрированы и wt ~ 1(0). Тогда для любого к коинтегрированы ряды xt и yyt_k + wt, у ф 0. Если xt ~ 1(1), то коинтегрированы ряды xt и xt_k. (Действительно, тогда xt хг_к = Axt + Axt_x 4… + Axt_k — сумма /(О)-переменных, которая также является /(О)-переменной.)
Процедура Энгла — Грейнджера построения модели коррекции ошибок
Итак, при коинтегрированности рядов xt,yt ~ 1(1) имеем:
модель долговременной (равновесной) связи уt = а + J3xt;
модель краткосрочной динамики в форме ЕСМ,
и эти модели согласуются друг с другом.
Проблема, однако, состоит в том, что для построения ЕСМ по реальным статистическим данным надо знать коинтегрирующий вектор (в данном случае — знать значение /?). Хорошо, если этот вектор определяется экономической теорией. К сожалению, чаще его приходится оценивать по имеющимся данным.
Энгл и Грейнджер (Engle, Granger, 1987) предложили двухшаговую процедуру построения ЕСМ для коинтегрированных рядов.
На первом шаге значения а и (5 оцениваются в рамках модели регрессии Ух на xt
ytа лJ3xt + ut.
Получив методом наименьших квадратов оценки а и ft для параметров этой модели (МНК-оценки), находим оцененные значения отклонений от положения равновесия
zt=yt-d-f3xt, т.е. остатки от оцененной регрессии.
На втором шаге методом наименьших квадратов раздельно (не как система!) оцениваются уравнения:
рAxt=jux + axzt_x + ХО^’-У +SXJAyt_j) + vn р-і
Ayt=ju2 + a2zt_x + ^(rij^t-j +S2jAyt_j) + wn y = i
т.е. предполагается модель VAR(p) для xt9yr
Определяющим в этой процедуре является то обстоятельство, что (в случае коинтегрированности рядов xt nyt) полученная на первом шаге оценка J3 быстрее обычного приближается (по вероятности) к истинному значению (З — второй компоненте коинтегрирующего вектора (1, Д)г (иначе говоря, /? является суперсостоятельной оценкой для Д). Это, в конечном счете, приводит к тому, что оценки в отдельном уравнении ЕСМ, использующие оцененные значения zt_l9 имеют то же асимптотическое распределение, что и оценка максимального правдоподобия, использующая истинные значения zt_ х (обычно это асимптотически нормальное распределение). При этом МНК-оценки стандартных ошибок всех коэффициентов являются состоятельными оценками истинных стандартных ошибок.
Заметим, что последние результаты справедливы, несмотря на то что ряд оцененных значений £, формально не является стационарным, поскольку
Отметим также, что если использовать другую нормировку коинтегрирующего вектора в виде (Д 1)г, то придется оценивать регрессию xt на константу иуп а это приведет к вектору, не пропорциональному вектору, оцененному в первом случае.
/
v Замечание 11.1.4. Тот факт, что Р быстрее обычного сходится (по вероятности) к Д вовсе не означает, что на первом шаге процедуры Энгла — Грейнджера можно использовать обычные регрессионные критерии. Дело в том, что получаемые на первом шаге оценки и статистики имеют, вообще говоря, нестандартные асимптотические распределения. Кроме того, при небольших Т оценка J3 может иметь весьма значительное смещение.
Однако в данном контексте первый шаг является вспомогательным, и на этом шаге нет необходимости обращать внимание на сообщаемые в протоколах соответствующих пакетов программ значения статистик. Напротив, на втором шаге можно использовать обычные статистические процедуры (разумеется, если количество наблюдений достаточно велико и ряды коинтегрированы).
у/ Замечание 11.1.5. При практическом применении двухшаговой процедуры Энгла — Грейнджера полученный на первом шаге ряд остатков z , -yt а j5xt используют не только при оценивании модели коррекции ошибок на втором шаге процедуры, но и для проверки гипотезы о некоинтегрированности рядов xtnyr
Эту гипотезу можно проверять следующим образом. Для ряда z, строится статистика Дики — Фуллера t9, которая использовалась бы для проверки гипотезы существования единичного корня у этого ряда, если бы этот ряд был «сырым», а не являлся рядом остатков от оцененной регрессии. Гипотеза некоинтегрированности рядов xt и yt отвергается, если вычисленное значение f оказывается ниже критического значения tKpm, соответствующего заданному уровню значимости, т.е. если t < tKpm. Следует отметить только, что это tKpm отличается от критического значения статистики t9, рассчитанного для случая «сырого» ряда, так что здесь необходимы другие таблицы критических значений. В связи с этим уже указывалась работа (MacKinnon, 1991); среди других источников, содержащих необходимые таблицы, упомянем монографии (Patterson, 2000) и (Hamilton, 1994). Более подробно этот вопрос будет рассмотрен в теме 11.2.
ПРИМЕР 11.1.7
Расмотрим реализацию процесса порождения данных
DGP: xt = х,_1 + st, Уг = 2х, + v„
где х{ = 0;
et и v, — порождаемые независимо друг от друга последовательности независимых, одинаково распределенных случайных величин, имеющих стандартное нормальное распределение yV(0, 1).
Графики полученных реализаций рядов xt uyt изображены на рис. 11.10. Пара (xt,yt) образует векторный процесс авторегрессии
xt — xt_ і 4st, yt = 2xt_l + r/t,
где 77, = v, 42st ~ Lid. N(0, 5).
В форме ЕСМ пара уравнений принимает вид:
Ду, = -(у,_і -2xt_x) + rit = -zt_x + //„
rjxezt =yt-2xt,
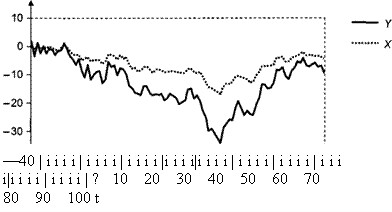 |
ИЛИ
Дх, = alzt_l + єп
Ayt = a2zt_x + rjn
где ax = 0, a2 = -1, так что ах + а2 > 0.
На практике, приступая к анализу статистических данных, исследователь не знает точно, какой порядок имеет VAR в DGP. Имея это в виду, выберем для оценивания в качестве статистической модели ЕСМ в виде:
Axt = axzt_x +ГцА*/-і +£ц4У/-і +v»
Ayt = a2zt_x + y2XAxt_x + S2xAyt.x + w„
допуская, что данные порождаются моделью векторной авторегрессии второго порядка (р = 2). Для анализа используем 100 наблюдений.
 Шаг I. Исходим из модели yt а + (3xt + иг Оцененная модель приведена в табл. 11.15.
Шаг I. Исходим из модели yt а + (3xt + иг Оцененная модель приведена в табл. 11.15.
То есть у, = -0.006764 + 1.983373л:, + й„ так что
zt = u,=y, + 0.006764 1.983373jc,.
Допустив, что VAR имеет порядок 2, при использовании критерия Дики — Фуллера для проверки рядов yt и xt на коинтегрированность в правую часть уравнения включаем одну запаздывающую разность:
 Azt=<pzt_x +6xl±zt_x + £. Оценивив последнее уравнение, получим табл. 11.16.
Azt=<pzt_x +6xl±zt_x + £. Оценивив последнее уравнение, получим табл. 11.16.
Значение тестовой статистики f = -7.614 ниже 5%-го критического уровня -3.396 (см. {Patterson, 2000, табл. 8.7)). Гипотеза некоинтегрированности рассматриваемых рядов уверенно отвергается. (Ввиду статистической незначимости коэффициента при запаздывающей разности можно было бы переоценить модель, не включая запаздывающую разность в правую часть уравнения. Но это дало бы значение f = -11.423, при котором гипотеза некоинтегрированности отвергается еще более уверенно.)
Таким образом, принимаем решение о коинтегрированности рядову, и^и переходим к построению модели коррекции ошибок.
 Шаг П. Сначала отдельно оцениваем уравнение для Axt (табл. 11.17).
Шаг П. Сначала отдельно оцениваем уравнение для Axt (табл. 11.17).
Поочередное исключение из правой части уравнения переменных со статистически незначимыми коэффициентами и наибольшим Р-значением приводит к оцененной модели (табл. 11.18) и, в конечном счете, к модели
Ах, = v„
которая и была использована при порождении ряда хг
 Исключая из правой части оцениваемого уравнения константу, получаем табл. 11.20.
Исключая из правой части оцениваемого уравнения константу, получаем табл. 11.20.
Хотя формально здесь следовало бы начать исключение статистически незначимых переменных с £j, необходимо учитывать уже принятое решение о коинтегрированности рядову, и хг Но если эти ряды действительно коинтег-рированы, то в ЕСМ должно выполняться соотношение ах2 + а2 > 0. Поскольку переменная z,_! не вошла в правую часть уравнения для Дх„ она должна оставаться в правой части уравнения для Ауг Если начать исключение с переменной Ду,_і, то в оцененном редуцированном уравнении (табл. 11.21) оказывается статистически незначимым коэффициент при Дх,_15 что приводит нас к уравнению Ay, = a2zt_{ + wr Оценивая последнее, получаем табл. 11.22.
Проверка гипотезы Н0: а2=-1 дает табл. 11.23.
 Поскольку эта гипотеза не отвергается, можно остановиться на модели ЕСМ
Поскольку эта гипотеза не отвергается, можно остановиться на модели ЕСМ
Axt = st, Ayt=-zt_x +и>„ где £,_! = yt_x + 0.0067641.983373х,_1.
Подстановка последнего выражения для zt_ х в уравнение для Ayt приводит к соотношению
yt = -0.0068 + 1.983*,.! + wn которое близко к соотношению
yt = 2xt_x + rjn
соответствующему использованному DGP.
Заметим, наконец, что последовательность wt = Ayt + zt_ х идентифицируется по наблюдаемой ее реализации как гауссовский белый шум с оцененной дисперсией 4.62 (использованному DGP соответствует значение 5.00), а последовательность et Ах, идентифицируется как гауссовский белый шум с оцененной дисперсией 1.04 (использованному DGP соответствует значение 1.00).
Остановившись на модели
Axt = sn Ayt = -zt_x +и>„ тем самым получили, что коррекция производится только в отношении ряда>>„ а именно — при положительных zt_x, т.е. при
yt_x (-0.0068 + 1.983Х,.!) > 0,
в правой части уравнения для Ду, корректирующая составляющая £,_ х отрицательна и действует в сторону уменьшения приращения переменной^,. Напротив, при отрицательных z,_ х корректирующая составляющая действует в сторону увеличения приращения переменной^,.
Прошлые значения переменной х, через посредство £,_ х помогают в прогнозировании значения уп т.е. переменная х, является причиной по Грейнджеру для переменной уг В то же время прошлые значения переменной yt никак не помогают прогнозированию значения х„ так что у, не является причиной по Грейнджеру для х,.И
Заметим далее, что даже если в ЕСМ Cov(vn wt) Ф 0, оценивание пары уравнений ЕСМ как системы не повышает эффективности оценок, поскольку в правые части обоих уравнений входят одни и те же переменные.
Расмотренный в нашем примере процесс порождения данных
DGP: х, = х,_! + £„ yt = 2х, + v,
является частным случаем модели, известной как треугольная система Филлипса (Phillips’s triangular system). В общем случае (для двух рядов) эта система имеет вид:
Уг = P*t + V/f X, — Х,_ і + €t9
где (snvt)T ~ lid. N2(0, X) — последовательность независимых, одинаково распределенных случайных векторов, имеющих двумерное нормальное распределение с нулевым математическим ожиданием и ковариационной матрицей I. Такая последовательность называется двумерным гауссовским белым шумом (two-dimentional Gaussian white noise).
Если матрица X диагональная, так что Cov(sn v,) = 0, то х, является экзогенной переменной в первом уравнении, и никаких проблем с оцениванием коэффициента /? в этом случае не возникает.
Если же Cov(sn v,) Ф 0, то х, не является экзогенной переменной в первом уравнении, так как при этом Cov(x„ v,) = Cov(xt_x + єп v,) Ф 0. Поэтому получаемая в первом уравнении оценка наименьших квадратов для /3 не имеет даже асимптотически нормального распределения.
В дальнейшем еще вернемся к проблеме оценивания коинтегрирующего вектора, а сейчас обратимся к вопросу о коинтеграции нескольких временных рядов.
Коинтегрированная система нескольких временных рядов. Проверка на коинтегрированность нескольких временных рядов
Пусть имеем N временных рядову,,yNt, каждый из которых является интегрированным порядка 1. Если существует такой ненулевой вектор Р=(РХ,PN)T, для которого
РУи + • • • + P^y^t ~ ДО) — стационарный ряд,
то говорят, что эти ряды коинтегрированы (в узком смысле), такой вектор Р называется коинтегрирующим. Если при этом
c = E(PxyXt + …+pNyNt),
то можно говорить о долговременном положении равновесия системы
{long-run equilibrium relation) в виде:
Pxyx + …+PNyN = c.
В каждый конкретный момент времени t существует некоторое отклонение (deviation) системы от этого положения равновесия, характеризующееся величиной
В силу сделанных предположений ряд zt является стационарным, имеющим нулевое математическое ожидание, так что он достаточно часто пересекает нулевой уровень, т.е. система колеблется вокруг указанного выше положения равновесия.
При проверке на коинтегрированность нескольких рядов надо различать несколько случаев.
Коинтегрирующий вектор определяется экономической теорией.
В этом случае надо просто проверить на наличие единичного корня соответствующую линейную комбинацию
РУи + — +РыУиг При этом используются те же критические значения, которые рассчитаны на применение к отдельно взятому «сырому» ряду. Эти значения не зависят от количества задействованных рядов N.
Пусть возможный коинтегрирующий вектор не определен заранее.
Тогда отдельно рассматриваются следующие ситуации.
Ряды у1п yNt не имеют детерминированного тренда (точнее, E(Aykt) = О для всех к =1,2,N).
2а. В коинтеграционное соотношение (SM) константа не включается. В этом случае оцениваем
SM: yXt = y2y2t + … + yNyNt + щ, получаем ряд остатков
оцениваем модель регрессии
Aut = (piit_x + £xAut_x + … + £KAut_K + st
с достаточным количеством запаздывающих разностей и проверяем гипотезу Н0: <р = 0 против альтернативы Н0: ^ < 0.
На этот раз критические значения для ^-статистики f зависят от количества задействованных рядов N. При большом количестве наблюдений можно использовать критические значения, приведенные в (Hamilton, 1994, табл. В.9, случай 1). Однако на практике в правую часть оцениваемого уравнения константа обычно включается.
2Ь. В коинтеграционное соотношение (SM) константа включается.
В этом случае оцениваем
SM: уи = а+ y2y2t + … + yNyNt + щ, опять получаем ряд остатков — теперь это будет ряд
«/ =Уи ~ (а + y2y2t + … + yNyNt оцениваем модель регрессии
Aw, = cput_x + £xAut_x + … + + €t
с достаточным количеством запаздывающих разностей и проверяем гипотезу Н0: ср 0 против альтернативы Н0: р<0.
Критические значения в этом случае отличаются от случая 2а. При большом количестве наблюдений можно использовать критические значения, приведенные в (Hamilton, 1994, табл. В.9, случай 2). При небольших Т критические значения вычисляются по формуле, приведенной в (MacKinnon, 1991, табл. 1 (вариант «по trend»)) (см. также (Patterson, 2000)).
3. Хотя бы один из рядов у1п yNt имеет линейный тренд, так что
E(Aykt) Ф 0 хотя бы для одного из регрессоров.
За. В коинтеграционное соотношение включается константа. В этом случае оцениваем
SM: ylt = a+ y2y2t + … + yNyNt + ur
Действуем опять как в случае 2Ь, только критические значения другие. При большом количестве наблюдений можно использовать критические значения, приведенные в (Hamilton, 1994, табл. В.9, случай 3). При небольших Т критические значения вычисляются по формуле, приведенной в работе (MacKinnon, 1991, табл. 1 (вариант «with trend»)) и воспроизведенной в (Patterson, 2000).
ЗЬ. В коинтеграционное соотношение включается линейный тренд.
В этом случае оцениваем
SM: уи = а+ St+y2y2t + … + yNyNt + ur
Действуя так же, как и ранее, используем те же таблицы, что и в случае За, но не для N, а для (Л/Ч 1) переменных.
Включение тренда в коинтеграционное соотношение приводит к уменьшению мощности критерия из-за необходимости оценивания «мешающего» параметра 8. Однако такой подход вполне уместен в тех случаях, когда нет полной уверенности в том, имеется ли ненулевой тренд хотя бы у одного из рядовуи,у2п .Ум-пример 11.1.8
Смоделируем реализации 4 рядов уи, y2t, y3t, y4t, следуя процессу порождения данных
DGP: уи=Уъ+Уы+Уъ + еи
Уіі ~Уі,і+ Є2п
Узг=Уз,гУаі =Уа,і+ ^4/’
где єи, s2t, s3t, s4t— независимые друг от друга процессы гауссовского белого шума с дисперсиями, равными 1 для s2t, s3t, s4t и 2 для єи.
Графики полученных реализаций для Т= 200 приведены на рис. 11.11.
Не зная точно процесс порождения данных, нужно было бы начать с исследования отдельных рядов. У всех 4 рядов не обнаруживается детерминированного тренда. Проверка по критерию Дики — Фуллера дает значения /-статистик, равные -2.18, -1.78, -0.57, -1.70 соответственно. Все 4 ряда признаются интегрированными. Продифференцированные ряды идентифицируются как гауссовские белые шумы, так что ряды уи, y2t, y3t, y4t идентифицируются как АЫ(1)-ряды с единичным корнем, т.е. как интегрированные ряды порядка 1.
Раздел 11 регрессионный анализ для нестационарных переменных. коинтегрированные временные ряды. модели коррекции ошибок тема 11.1 проблема ложной регрессии. коинтегрированные временные ряды. модели коррекции ошибок: Эконометрика Книга первая Часть 2, Носко Владимир Петрович, 2011 читать онлайн, скачать pdf, djvu, fb2 скачать на телефон Под временным рядом (time series) в экономике понимается ряд значений некоторой переменной, измеренных в последовательные моменты времени.
Коинтеграция
В 2003 году Шведская академия наук объявила о присуждении Нобелевской премии по экономике Роберту Энглу и Клайву Грэнджеру за «методы анализа экономических временных рядов с общим трендом», так называемые методы коинтеграции. Их статья, перевод которой приводится ниже, заложила основы в этой области и изменила подходы прикладных макроэкономистов к анализу данных.
Идея коинтеграции является очень естественным развитием идеи экономического равновесия, если принять во внимание нестационарность большинства макроэкономических переменных. В то время как стационарные временные переменные принимают значения недалеко от своего среднего, часто возвращаясь к нему, для нестационарных переменных ожидаемое время возврата к среднему бесконечно, и они обладают свойством далеко уходить от своего среднего. Нестационарность большинства макроиндикаторов — это хорошо изученная эмпирическая данность. Зачастую экономическое равновесие понимается как связь между несколькими переменными, «подталкивающая» некоторую линейную комбинацию этих переменных к нулю настолько сильно, что отклонения от нуля очень незначительны. Таким образом, эта линейная комбинация нестационарных переменных оказывается стационарной, а изначальные переменные коинтегрированными.
Хотя сама концепция коинтеграции очень естественна, эконометрические методы, необходимые для работы с ней, существенно отличаются от классических эконометрических принципов, используемых в микроэконометрике. Различия в методах столь существенны, что при первом прочтении приведенная ниже статья может вызвать удивление у читателя, хорошо знакомого с классической эконометрикой. Начнем с того, что большая часть классического регрессионного анализа построена на понятии экзогенности, в то время как коинтеграционные регрессии дают состоятельные оценки, даже если все переменные эндогенны, более того, прямая и обратная регрессии дают практически одинаковый результат — вещь, невозможная в микроэконометрике.
Сложность работы с коинтеграцией заключается в том, что знакомые эконометристам статистики сходятся к нестандартным асимптотическим распределениям и требуют нестандартных критических значений. Энгл и Грэнджер показывают, что вполне естественное желание избежать эти сложности путем перехода к первым разностям переменных является ошибочным шагом и ведет к существенно смещенным ошибкам. Смещение в оценках возникает из-за того, что та самая стационарная линейная комбинация нестационарных переменных является необходимым регрессором в регрессии первых разностей. Эта регрессия называется моделью коррекции ошибок. Авторы рассматривают вопрос двухшаговой оценки модели коррекции ошибок, а также вопрос тестирования коинтеграции.
Идеи и статьи Энгла и Грэнджера выделили макроэконометрику и теорию временных рядов в отдельный раздел экономики. Роберт Энгл известен также своими работами по стохастической волатильности (модели ARCH и GARCH), которые были названы в официальном объявлении Нобелевского комитета. Клайв Грэнджер является автором известной концепции «причинности по Грэнджеру». Авторы проработали в университете Калифорнии в Сан-Диего около 30 лет, прежде чем вышли на пенсию в 2003 году. Клайв Грэнджер ушел из жизни в 2009 году.
А. Е. Микушева
Прикладная эконометрика, 2015, 39 (3), с. 107-135.
AppliedEconometrics, 2015, 39 (3), pp. 107-135.
Co-Integration and Error Correction: Representation, Estimation, and Testing
Robert F. Engle and C. W. J. Granger
Коинтеграция и коррекция ошибок: представление, оценивание и тестирование1
Роберт Ф. Энгл, К. У. Дж. Грэнджер2
В работе исследуется взаимосвязь между моделями коинтеграции и коррекции ошибок, изначально предложенная в (Granger, 1981), предлагаются новые методы оценивания и тестирования, рассматриваются эмпирические примеры.
Если каждая компонента векторного временного ряда xt не стационарна, но становится стационарной после взятия первых разностей, а некоторая линейная комбинация a’x, стационарна, такой временной ряд называется коинтегрированным с коин-теграционным вектором а. Если существует несколько линейно независимых коинте-грационных векторов, то в этом случае а — это матрица, составленная построчно из коинтеграционных векторов. Если интерпретировать равенство а’xt = 0 как долгосрочное равновесие, то наличие коинтеграции означает, что отклонение от равновесия является стационарным, с ограниченной дисперсией, даже в том случае, когда исходные ряды являются нестационарными и имеют бесконечную дисперсию. В статье доказана теорема о представлении, основанная на статье (Granger, 1983), в которой связываются понятия скользящего среднего, авторегрессии и коррекции ошибок для коинтегрированных систем. Векторная авторегрессия в разностях
1 Оригинальная статья: Robert F. Engle and C. W. J. Granger (1987). Co-Integration and Error Correction: Representation, Estimation, and Testing. Econometrica, Vol. 55, No. 2 (Mar., 1987), pp. 251-276. © Econometric Society.
The copyright to this article is held by the Econometric Society, http://www.econometricsociety.org/. It may be downloaded, printed and reproduced only for personal or classroom use. Absolutely no downloading or copying may be done for, or on behalf of, any for-profit commercial firm or for other commercial purpose without the explicit permission of the Econometric Society. For this purpose, contact the Editorial Office of the Econometric Society at econometrica@econometricsociety.org.
Редакция благодарит Econometric Society за разрешение на публикацию перевода статьи.
Перевод статьи выполнен под редакцией П. К. Катышева.
2 Robert Fry Engle — Professor, New York University Stern School of Business.
Clive William John Granger (1934-2009).
Авторы выражают благодарность David Hendry и Sam Yoo за множество важных и полезных обсуждений и предложений, так же как и Gene Savin, David Dickey, Alok Bhargava и Marco Lippi. Они признательны двум рецензентам за детальную конструктивную критику, а также Yoshi Baba, Sam Yoo и Alvaro Ecribano за творчески выполненные численные расчеты и примеры. Исследование выполнено при финансовой поддержке Национального научного фонда (США) SES-80-08580 и SES-82-08626. Предыдущая версия этой статьи называлась «Спецификация динамической модели с равновесными ограничениями: Коинтеграция и коррекция ошибок».
несовместима с этими представлениями. В статье предложена простая, но асимптотически эффективная двухшаговая оценка. Тестирование коинтеграции сочетает в себе задачи тестирования единичных корней и тесты с параметрами, неидентифи-цируемыми при нулевой гипотезе. Предложены и проанализированы семь тестовых статистик. Методом Монте-Карло получены критические значения этих статистик. Мощность предложенных тестов проанализирована с использованием полученных критических значений, и одна процедура тестирования рекомендуется для применения. В ряде примеров было обнаружено, что потребление и доход, краткосрочные и долгосрочные процентные ставки являются коинтегрированными, заработные платы и цены не коинтегрированы, номинальный ВНП коинтегрирован с М2, но не с М1, М3 или с совокупными ликвидными активами.
ключевые слова: коинтеграция; векторная авторегрессия; единичные корни; коррекция ошибок; многомерные временные ряды; тесты Дики-Фуллера. JEL classification: C01; C12; C30; C33; C513.
1. введение
Индивидуальная экономическая переменная, рассматриваемая как временной ряд, может меняться весьма значительно, однако встречаются такие переменные, от которых можно ожидать, что, будучи объединенными в пару, подобные ряды будут не слишком удаляться друг от друга. Обычно экономическая теория предлагает некоторый механизм, удерживающий такие ряды вместе. Примерами могут быть краткосрочные и долгосрочные процентные ставки, ассигнования капитала и расходы, доходы и расходы домохозяйств, цены одного товара на различных рынках или цены близких товаров-заменителей на одном рынке. Подобная идея возникает при взгляде на равновесие как на стационарное состояние, в которое стремится вернуться экономика при любом отклонении от этого состояния. Если xt является вектором экономических переменных, то можно сказать, что равновесие достигается при выполнении линейного ограничения:
a’xt = 0.
Как правило, xt не будет находиться в равновесии, и поэтому одномерную переменную zt = a’xt можно назвать ошибкой или отклонением от равновесия. Если понятие равновесия дает правильную спецификацию эконометрической модели, то экономика должна предпочитать малое значение zt большому.
Эти идеи легли в основу данной статьи, и с их помощью показано, что в классе моделей, известных как модели коррекции ошибок, долгосрочные компоненты переменных связаны условиями равновесия, в то время как краткосрочные имеют гибкую динамическую спецификацию. Для того чтобы это утверждение было верным, используется условие коинтеграции, которое впервые было введено в работах (Granger, 1981) и (Granger, Weiss, 1983); его точное определение дано в следующем разделе. В разделе 3 обсуждаются несколько представлений коинтегрированных систем, раздел 4 содержит описание процедур оценивания, а в разделе 5 приведены соответствующие тесты. Некоторые приложения представлены в разделе 6, раздел 7 содержит выводы. В разделе 4 детально рассмотрен простой пример, который может быть полезен для мотивации изучения таких систем.
3 JEL classification добавлены редактором.
2. Интеграция, коинтеграция и коррекция ошибок g-
I
Согласно теореме Вольда, всякий одномерный стационарный временной ряд без де- ¿L терминированной компоненты может быть представлен как некоторый процесс бесконеч- * ного скользящего среднего, который также можно аппроксимировать процессом сколь- ч^ зящего среднего конечного порядка. Более подробно см. (Box, Jenkins, 1970) или (Granger, Newbold, 1977). Часто, однако, для обеспечения стационарности экономических рядов не- | обходимо брать разности. Это приводит к следующему известному определению интег- ^ рации. ^
Определение. Временной ряд без детерминированной компоненты называется интегрированным порядка d и обозначается xt ~ I(d), если его разность порядка d допускает стационарное обратимое ARMA представление.
В большей части статьи для простоты будут рассмотрены только значения d = 0 и d = 1, но почти все результаты могут быть обобщены на другие случаи, включая дробную разностную модель. Таким образом, если d = 0 , то сам ряд xt будет стационарным, а для d = 1 он будет стационарен в первой разности.
Поведение I (0) и I (1) рядов существенно отличается. Для детального рассмотрения см., например, (Feller, 1968) или (Granger, Newbold, 1977).
(a) Если xt ~ I(0) и имеет нулевое среднее, то: (i) дисперсия xt ограничена; (ii) инновации (шоки) имеют только кратковременный эффект на значения xt ; (iii) спектр f (а) ряда xt обладает свойством 0 < f (0) < да ; (iv) среднее время между последовательными пересечениями уровня x = 0 конечно; (v) автокорреляции pk быстро убывают с ростом k, так что их сумма ограничена.
(b) Если xt ~ I(1) с x0 = 0 , то: (i) дисперсия xt стремится к бесконечности при t ^да; (ii) инновации имеют постоянный эффект на значение xt , т. к. xt представляет из себя сумму всех предыдущих изменений; (iii) при малых а спектр xt имеет аппроксимацию f (а) ~ Àa~2d, в частности f (0) = да ; (iv) среднее время между последовательными пересечениями уровня x = 0 равно бесконечности; (v) теоретические автокорреляции pk ^ 1 для всех k при t ^ да.
Бесконечность теоретической дисперсии временного ряда I (1) объясняется полностью вкладом низких частот или долгосрочной части этого ряда. Поэтому по сравнению с рядом I (0) ряд I (1) более гладкий, имеет доминирующие длинные колебания. Из-за относительных размеров дисперсий сумма ряда I(0) и ряда I(1) есть ряд I(1). Более того, если а и b константы, b Ф 0, и если xt ~ I (d ), то а + bxt также будет рядом I (d ).
Если оба ряда xt, yt являются I (d ), то в общем случае линейная комбинация
zt = xt — аЛ
также будет I (d ) . Однако, возможно, что zt ~ I (d — b), b > 0 . Это означает, что на долгосрочные компоненты рядов накладывается некоторое специфическое ограничение. Рассмотрим случай d = b = 1, т. е. xt, yt являются I(1) с доминирующими долгосрочными компонентами, но zt является I(0) без сильных низких частот. Иными словами, константа а выбрана так, что долгосрочные компоненты xt и yt в основном компенсируются. Если же а = 1, то расплывчатое утверждение «xt и yt не могут отклоняться слишком далеко друг от друга» приобретает более точную форму: «разность xt и yt есть I(0)». Использование постоянной а попросту означает некоторое масштабирование, которое должно быть ис-
пользовано перед взятием разности I(0). Следует подчеркнуть, что такое а, для которого zt ~ I(0), может и не существовать.
Аналогичный случай: линейная комбинация zt пары временных рядов xt и yt, каждый из которых содержит значимые сезонные компоненты, не будет содержать сезонности. Понятно, что такое может происходить, но весьма редко.
Для формализации этих идей вводится следующее определение из (Granger, 1981; Granger, Weiss, 1983).
Определение. Компоненты векторного временного ряда xt называются коинтегриро-ванными порядка d, b и обозначаются xt ~ CI(d,b), если: (i) все компоненты xt являются I(d); (ii) существует вектор а (ф 0) такой, что zt =a’xt ~ I(d — b), b > 0. Вектор a называется коинтеграционным вектором.
В случае d = 1, b = 1 наличие коинтеграции означает, что все компоненты вектора xt являются рядами I(1), а ошибка равновесия zt есть I(0). Значит, если zt имеет нулевое среднее, то этот ряд будет редко далеко отклоняться от нуля и часто пересекать нулевой уровень. Иными словами, время от времени будет достигаться точное равновесие или близкое к нему состояние. В то же время, если xt не является коинтегрированным, процесс zt может блуждать, далеко отклоняясь от нуля и редко пересекая нулевой уровень, и в этом случае теория равновесия не имеет практического значения. Возможность снижения порядка интеграции означает наличие специальных отношений, следствия которых можно интерпретировать и тестировать. Однако, если все элементы xt уже являются стационарными, т. е. I(0), то ошибка равновесия zt не имеет отличительных свойств, если она тоже есть I(0) . Возможно, что zt ~ I(-1), тогда его спектр равен нулю на нулевой частоте, но если любая из переменных содержит ошибку измерения, это свойство может быть не выполнено в общем случае, и поэтому данный случай не представляет практического интереса. При интерпретации концепции коинтеграции можно отметить, что в случае N = 2, d = b = 1 Granger и Weiss (1983) показали, что необходимым и достаточным условием коинтеграции является когерентность между двумя рядами на нулевой частоте.
Если xt имеет N компонент, может существовать более чем один коинтеграционный вектор a. Очевидно, возможно несколько равновесных соотношений управления совместным поведением переменных. В дальнейшем будем предполагать, что существует ровно r, r < N — 1, линейно независимых коинтеграционных векторов, образующих матрицу а размерности N х r. По построению ранг a равен r, и это число будет называться коинтеграци-онным рангом ряда xt.
Далее будет установлена тесная связь между коинтеграцией и моделями коррекции ошибок. Механизмы коррекции ошибок широко используются в экономике. Ранние версии рассмотрены в (Sargan, 1964; Phillips, 1957). Идея состоит в том, что некоторая доля отклонения от равновесия в какой-то промежуток времени корректируется в следующем промежутке. Например, изменение в цене за один период может зависеть от степени избыточного спроса в предшествующем периоде. Похожая ситуация возникает в задачах оптимального поведения при наличии издержек адаптации или в условиях неполноты информации. В последнее время эти модели вызвали большой интерес с учетом результатов работ (Davidson et al., 1978; Hendry, von Ungern-Sternberg, 1980; Currie, 1981; Dawson, 1981; Salmon, 1982) и многих других.
В типичной модели коррекции ошибок для системы с двумя переменными изменение одной переменной зависит от ошибки равновесия в предыдущие моменты времени и от из-
í с>
£
менения обеих переменных в прошлом. Для многомерной системы модель коррекции ошибок можно определить с помощью оператора сдвига по времени В следующим образом.
Определение. Векторный временной ряд х{ допускает представление в виде модели коррекции ошибок, если
А(В)(1 — В)х( = _yzt_l + щ, Ы
|
где ^ является стационарным многомерным возмущением, А(0) = I, все элементы матри- <•>
е
а
цы А(1) конечны, zz = а’хт и у Ф 0 .
В этом представлении объясняющей переменной является только неравновесие в предыдущем периоде. Тем не менее, за счет перегруппировки членов модель с любым числом лагов величины z может быть представлена в этой форме, таким образом, модель позволяет описывать любой способ сходимости к равновесию. Заметное различие между этим определением и большинством встречавшихся приложений состоит в том, что в многомерном случае определение не опирается на экзогенность подмножества переменных. Ситуация, когда одна переменная является слабо экзогенной в смысле (Е^1е et а1., 1983), также может быть исследована в рамках данного подхода, что кратко обсуждается ниже. Второе существенное различие состоит в том, что а рассматривается как вектор неизвестных параметров, а не набор констант, представленных экономической теорией.
3. свойства коинтеграционных переменных и их представления
Пусть каждая компонента вектора хг является временным рядом I (1), причем первая разность каждой компоненты есть чисто недетерминированный стационарный случайный процесс с нулевым средним. Любые известные детерминированные компоненты могут быть вычтены перед началом анализа. Тогда процесс х{ допускает многомерное представление Вольда
(1 _ В) х, = С (В (3.1)
в том смысле, что левая и правая части имеют одну и ту же спектральную матрицу. При этом матрица С(В) однозначно определяется такими условиями: нули функции det[C(z)], z = е’а лежат на границе или вне единичного круга, и С(0) = 1Ы — единичная матрица размерности N х N (см. (Наппап, 1970, р. 66)). Здесь — белый шум с нулевым средним,
[0, , Ф 5,
екк]И; ,
Перегруппировкой слагаемых полином скользящего среднего С(В) всегда может быть представлен в виде
С (В) = С (1) + (1 _ В) С *( В). (3.2)
Если С(В) имеет конечный порядок, то С *(В) тоже будет иметь конечный порядок. Если С * (1) тождественно равен нулю, то можно получить аналогичное представление с сомножителем (1 _ В)2.
Связь между моделями коррекции ошибок и коинтеграцией впервые была отмечена в статье (Granger, 1981). Теорема о том, что коинтегрированный ряд может быть представлен моделью коррекции ошибок, была сформулирована и доказана в (Granger, 1983). Поэтому ее версия, сформулированная ниже, называется теоремой Грэнджера о представлении. Анализ похожих, но более сложных случаев представлен в статьях (Johansen, 1985; Yoo, 1985).
Теорема Грэнджера о представлении. Пусть N xi -вектор xt в (3.1) является коинте-грированным с d = 1, b = i, и коинтеграционный ранг равен r . Тогда:
(1) матрица C (1) имеет ранг N — r ;
(2) существует векторное ARMA представление
A(B ) xt = d (B )et, (3.3)
при этом матрица A(1) имеет ранг r, d(B) является скалярным полиномом, величина d(1) ограничена и A(0) = IN ; если d (B) = 1, то это векторная авторегрессия;
(3) существуют матрицы a, g размера N x r и ранга r такие, что:
a’C (1) = 0, C (1)у = 0, A(1) = уа’;
(4) существует представление в виде модели коррекции ошибок с вектором стационарных случайных переменных zt = a’xt размерности r xi :
A * ( B)(1 — B) xt = _gzt-i + d (B )et (3.4)
с A *(0) = In;
(5) вектор zt удовлетворяет соотношениям
zt = K ( B)st, (3.5)
(1 — B) zt = _a’gzt_i + J ( B ) et, (3.6)
где K(B) есть r x N-матрица лаговых полиномов, равная a’C *(B), все элементы матрицы K (1) конечны и имеют ранг r, и det(aY) > 0;
(6) если существует представление в виде конечной авторегрессии, то оно имеет вид (3.3) и (3.4) с d(B) = 1 и матрицами конечных полиномов A(B) и A *(B).
Для доказательства теоремы нам необходимы следующие утверждения о детерминантах и присоединенных матрицах для сингулярных матричных полиномов.
Лемма 1. Пусть G(Â) — матричный полином размерности N x N, принимающий конечные значения для Ле[0,1]. Пусть также ранг матрицы G(0) равен N — r для 0 < r < N, и пусть G *(0) Ф 0 в разложении
G{X) = G (0) + ÀG *(Л).
Тогда: (i) det(G(Л)) = Л g(À)IN, (ii) Adj (G(Л)) = Àr-iH (Л), где IN — единичная N x N-матрица, 1 < rank (H (0)) < r, и H (0) конечна.
Доказательство. Определитель G может быть представлен в виде степенного ряда по Л :
да
det(G^)) = .
1=0
Каждый элемент ôi является суммой конечного числа произведений элементов G^) и поэтому является конечным. Каждая такая сумма имеет некоторые слагаемые из G(0) и не-
которые из ЛG *(Л). Любое произведение с более чем N — г членами из G(0) будет равно нулю, потому что будет являться определителем подматрицы большего порядка, чем ранг
является стационарным чисто недетерминированным г-мерным временным рядом, допускающим представление в виде обратимого скользящего среднего. Умножая обе части равенства (3.1) на а, получаем:
(1 — В)zt = (ас(1) + (1 — В)а’С * (В))ег.
Для того чтобы zt был I(0) процессом, необходимо, чтобы вектор а’С(1) был равен 0. Любой вектор, удовлетворяющий этому свойству, будет коинтеграционным. Следователь-
í
G (0). Поэтому любой ненулевой элемент должен содержать не менее г членов из ЛG *(Л), а значит, соответствующая степень 1 при нем будет не меньше г . Таким образом, первый ^ ненулевой член Si есть Зг. Полагая ч^
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
да
£(1) = , |
‘=г «
получаем первую часть леммы, т. к. член 5г должен быть конечным. ^
Для доказательства второго утверждения разложим присоединенную матрицу для G по степеням Л: ^
да
Аф ^(Л)) = %Л’Н,.
i=0
Так как присоединенная матрица — это матрица, состоящая из определителей порядка N -1, то, как и выше, получаем, что первые г -1 слагаемых должны быть тождественно равны нулю. Поэтому
да
Adj ^(Л)) = Лг-1 ^Л’-Г+1Н1 = ЛГ-1Н(Л).
i=0
Поскольку элементы матрицы Нг -1 являются произведениями конечного числа конечных чисел, матрица Н(0) должна быть конечной.
Произведение матрицы на ее сопряженную — это определитель, умноженный на единичную матрицу. Поэтому
Лг ^(Л) 1М = (Э (0) + ЛG * (Л))Н (Л) = ^(0) Н (Л)ЛГ-1 + ЦЛ^ * (Л))ЛГ.
Приравнивая коэффициенты при одинаковых степенях Л, получаем:
G(0)Н(0) = 0 .
Поэтому ранг матрицы Н(0) должен быть не больше г , т. к. каждый ее столбец лежит в ядре матрицы G(0), имеющей ранг N — г . Если г = 1, первое слагаемое в выражении для присоединенной матрицы будет просто присоединенной матрицей для G(0), которая будет иметь ранг 1, т. к. G(0) имеет ранг N -1.
Доказательство теоремы Грэнджера о представлении. Условия теоремы предполагают существование многомерного представления Вольда (3.1) для коинтегрированного ^мерного случайного процесса х. Пусть а — соответствующая коинтеграционная матрица, такая что процесс
но, матрица С(1) имеет ранг N — г, и все коинтеграционные векторы лежат в ее ядре. Отсюда также следует, что а’С *(В) — обратимое представление в виде скользящего среднего, в частности, а’С * (1) Ф 0 . В противном случае коинтеграция будет с Ь = 2 или выше.
Полагая в Лемме 1 Л = (1 — В), G(Л) = С (В), Н (Л) = А( В) и g(Л) = d (В), получаем утверждение (2). Так как матрица С (В) имеет полный ранг и равна ^ при В = 0, ее обратная матрица есть Л(0) и также будет равна .
Утверждение (3) следует из того факта, что Л(1) имеет ранг между 1 и г и лежит в ядре матрицы С(1). Поскольку а натянуто на это нулевое пространство, Л(1) может быть записана в виде линейной комбинации коинтеграционных векторов
Л(1) = уа’.
Утверждение (4) следует из преобразований авторегрессии. Перегруппировка членов в (3.3) дает:
[АА(В) + А(1)](1 — В)х, = -А(1)х(-1 + d(В)к , А * (В)(1 — В)х( = -72,-1 + d(Вк, А *(0) = А(0) = ^.
Пятое утверждение следует из непосредственной замены в представлении Вольда. Определение коинтеграции подразумевает, что это скользящее среднее будет стационарным и обратимым. Перепишем представление в виде модели коррекции ошибки с А * (В) = I + А * *(В), где Л * *(0) = 0, и умножим слева на а’:
(1- В)г, = —а+ [а’ d(В) + а’А **(В)С(В)]е, = —а+J(В)е,.
Чтобы это представление было эквивалентно стационарному скользящему среднему, авторегрессия должна быть обратимой. Для этого необходимо, чтобы выполнялось условие det(a’у) > 0 . Действительно, если определитель равен нулю, то существует по крайней мере один единичный корень, а если определитель отрицателен, то для некоторого значения т от нуля до единицы выполнено равенство
¿а; (1Г — (1Г —а У)т) = 0, а это значит, что существует корень внутри единичного круга.
Повторяя предыдущие шаги с d (В) = 1, получаем шестое утверждение.
Теорема полностью доказана.
Могут быть получены и более сильные результаты при дополнительных ограничениях на кратность корней в представлении скользящего среднего. Например, Yoo (1985), используя формы Смита-Макмиллана, находит условия, при которых й(1) Ф 0, Л * (1) имеет полный ранг, и которые упрощают переход от модели коррекции ошибок к моделям коинтегра-ции. Однако приведенные выше результаты являются достаточными для задач оценивания и тестирования, рассматриваемых в этой статье.
Авторегрессия и модель коррекции ошибок, заданные формулами (3.3) и (3.4), тесно связаны с часто используемыми в эконометрике моделями векторной авторегрессии (VAR), особенно в случае, когда й(В) можно обоснованно считать равным 1. Тем не менее, каждая из них существенно отличается от стандартной VAR. В представлении авторегрессии
А( В) = к,
коинтеграция переменных хг создает ограничение, которое делает матрицу Л(1) сингулярной. Для г = 1 ранг этой матрицы будет равен 1. Анализ таких систем сложен, т. к. неко- Ц торые численные методы, используемые для нахождения скользящего среднего, являются крайне неустойчивыми. ^
Представление в виде модели коррекции ошибок ч^
I
е
а
А * (В)(1 — В)х = -уа’х-1 + £
выглядит более похожим на стандартную векторную авторегрессию для первых разностей. Здесь коинтеграция приводит к присутствию самих переменных (в уровнях), поэтому, если переменные будут коинтегрированными, чистая VAR для разностей будет неправильной спецификацией модели.
Таким образом, если ряды коинтегрированы, векторная авторегрессия для первых разностей является неверной спецификацией. Если же использовать векторную авторегерес-сию для уровней, то будут упущены существенные ограничения. Конечно, эти ограничения асимптотически будут выполняться, но если учесть их явно, можно повысить эффективность модели и улучшить многошаговый прогноз.
Так как хг ~ I(1), zt ~ I(0), то все члены в модели коррекции ошибок являются I(0). Верно и обратное: если хг ~ I(1) порождается моделью коррекции ошибок, то хг обязательно будет коинтегрированным. Также отметим, что если хг ~ I(0), то этот процесс всегда может быть представлен в виде модели ошибки коррекции, и поэтому в данном случае идея равновесия не имеет значения.
Как уже говорилось выше, в большинстве эмпирических примеров модель коррекции ошибок формулируется как реакция зависимой переменной на шоки независимой переменной. В этой статье все переменные являются совместно эндогенными; тем не менее, структура модели допускает причинность по Грэнджеру или слабые и сильные условия эк-зогенности, как в статье (Е^1е et а1., 1983). Например, двумерная коинтегрированная система должна иметь причинно-следственную связь по крайней мере в одном направлении. Поскольку вектор z должен включать обе переменные, и у не может быть тождественно нулем, то они должны входить в одно или оба уравнения. Если слагаемое коррекции ошибок входит в оба уравнения, ни одна из переменных не может быть слабо экзогенной для параметров другого уравнения из-за кросс-ограничений между уравнениями.
Понятие коинтеграции в принципе может быть применено к рядам с трендами или к авторегрессиям, корни которых лежат внутри единичного круга. В этих случаях коинтеграци-онный вектор по-прежнему будет необходим для приведения рядов к стационарности. Следовательно, тренды должны быть пропорциональными, и корни, лежащие внутри единичного круга, должны быть идентичными для всех рядов. Мы не рассматриваем эти случаи в данной работе и осознаем, что при оценивании и тестировании могут возникнуть существенные сложности.
4. оценивание коинтегрированных систем
Различные представления коинтегрированных систем неявно предполагают и различные способы их оценивания. Наиболее удобным является представление в виде модели коррекции ошибок (особенно если можно предположить, что нет никакого скользящего среднего).
При этом остаются кросс-ограничения на параметры между уравнениями, поэтому в предположении нормальности оценивание методом максимального правдоподобия требует применение итеративных процедур.
В этом разделе предлагается другой метод оценивания, состоящий из двух этапов. На первом этапе оцениваются параметры коинтеграционного вектора, а на втором они используются в модели коррекции ошибок. На каждом шаге нужно оценивать лишь одно уравнение методом наименьших квадратов, при этом, как будет показано далее, оценки всех параметров будут состоятельными. Эта процедура особенно удобна тем, что не требует спецификации динамики до тех пор, пока структура оценок коррекции не оценена. В качестве «побочного продукта» получаются некоторые статистики, полезные для тестирования коинтеграции.
Из (3.5) можно непосредственно выразить выборочную матрицу моментов. Обозначим
MT = 1/T2Xxtx’t.
t
Напомним, что zt = a’xt, тогда из формулы (3.5) следует
a’MT =X[K(B)e,]x; /T2.
t
Используя те же аргументы, что и в (Dickey, Fuller, 1979) или (Stock, 1984), можно показать, что для процесса, удовлетворяющего (3.1), справедливы следующие утверждения:
lim E (M T ) = M (4.1)
T ^да
и a’M = 0 или (vec a)'(I ® M) = 0 . (4.2)
Хотя выборочная матрица моментов для коинтегрированного процесса будет несингулярной для любой выборки, в пределе она будет иметь ранг N — r . Это хорошо согласуется с общим наблюдением, что данные экономических временных рядов сильно коллинеар-ны друг с другом, так что матрицы моментов могут быть близки к сингулярным даже при больших выборках. Таким образом, с аналитической точки зрения коинтеграция является правдоподобной гипотезой.
Уравнения (4.2) не определяют однозначно коинтеграционные векторы, если нет ограничений типа нормализации. Пусть q и Q являются матрицами, задающими эту нормализацию, которая после перепараметризации a в j х 1 -вектор может быть записана так:
vec a = q + Qd. (4.3)
При этом предполагается, что вектор в лежит в компактном подмножестве пространства RJ.
Обычно q и Q состоят полностью из нулей или единиц, тем самым определяя один коэффициент в каждом столбце матрицы а равным единице, и определяя повороты при r > 1. Параметр в называется идентифицируемым, если существует единственное решение уравнений (4.2) и (4.3). Это решение определяется равенством
(I ®M)Qe = —(I ® M)q, (4.4)
где по предположению идентифицируемости у матрицы (I ® M)Q существует левая обратная матрица, даже если у M ее нет.
í
Так как матрица моментов MT будет иметь полный ранг для конечных выборок, разумным подходом к оценке является минимизация суммы квадратов отклонений от равновесия. В случае единственного коинтеграционного вектора оценка а будет минимизировать ¿L а’Мта при ограничениях (4.3), и результатом будет оценка обычным методом наименьших % квадратов. Для нескольких коинтеграционных векторов определим а как результат мини- ч^
мизации следа tr (а’M¿.а). Тогда задача оценки принимает вид: ^
|
min ^(а’Мта) = min уеса'(! ®MT)уеса = min(q + Q§)'(I ®MT)(q + Q§). <•>
а, s.t.(4.3) ‘ а, s.t.(4.3) ‘ T ф
h-
Ее решение есть ^
§ = -(Q'(I ®MT)Q)-1 (Q'(I ®MT)q, vec а = q + Q§. (4.5) *
Такой подход к оценке должен обеспечивать очень хорошее приближение к истинному коинтеграционному вектору, поскольку ищутся векторы с минимальной остаточной дисперсией, а асимптотически все линейные комбинации компонент вектора x будут иметь бесконечную дисперсию, за исключением коинтеграционных векторов.
При r = 1 эта оценка получается просто регрессией нормализованной переменной, коэффициент при которой равен единице, на остальные переменные. Эта регрессия будет называться «коинтеграционной регрессией», т. к. она стремится реализовать долговременное или равновесное соотношение, не заботясь о динамике. Такую регрессию Granger, Newbold (1974) уничижительно называют «ложной» регрессией в основном потому, что стандартные ошибки приводят к ошибочным выводам. Авторы в первую очередь рассматривали случай отсутствия коинтеграции, когда между переменными не было никакой связи, однако наличие единичного корня в остатках приводило к малому значению статистики Дарбина-Уот-сона, большому значению R2 и высокой значимости коэффициентов. Здесь ищутся только оценки коэффициентов для использования на втором этапе и тестирования долговременного равновесия. Распределение оценок коэффициентов было исследовано в статье (Stock, 1984).
Если N = 2, существуют две возможные регрессии в зависимости от выбранной нормализации. Неединственность оценки есть следствие хорошо известного факта, согласно которому оценка параметра обратной регрессии не равна величине, обратной оценке параметра прямой регрессии. Однако в нашем случае нормализация не играет существенной роли: матрица моментов стремится к сингулярной, и, значит, коэффициент детерминации R2 приближается к 1 , а он, в свою очередь, является произведением оценок коэффициентов прямой и обратной регрессий. Это было бы абсолютно верно, если бы существовали только два наблюдения, которые, конечно, определяют сингулярную матрицу. Для переменных, которые имеют общую тенденцию, корреляция стремится к единице, в то время как дисперсия каждой приближается к бесконечности. Линия регрессии практически проходит через крайние точки, как если бы существовали всего два наблюдения.
Stock (1984) в Theorem 3 доказывает следующее утверждение.
Предложение 1. Предположим, что xt удовлетворяет соотношению (3.1) с абсолютно суммируемым C *(B), ошибки имеют четвертый конечный момент, а xt является коинте-грированным (1,1) с r коинтеграционными векторами, удовлетворяющими равенству (4.3), в котором параметр § идентифицируем. Тогда оценка §, определяемая равенством (4.5), удовлетворяет соотношению
Tl-S{§-в) Л 0 для 5> 0. (4.6)
Предложение утверждает, что оценки параметров очень быстро сходятся к их вероятностным пределам. Оно также говорит, что для конечной выборки смещение имеет порядок 1/ T. Используя метод Монте-Карло, Stock показал, что на малых выборках это смещение может быть значительным, а также нашел выражения для предельного распределения оценок.
В двухшаговой процедуре, предлагаемой для этой коинтегрированной системы, оценка а из (4.5) используется как известный параметр при оценивании модели коррекции ошибок. Это существенно упрощает процедуру оценки путем наложения кросс-ограничений и позволяет специфицировать индивидуальные уравнения для динамических составляющих независимо друг от друга. Отметим, что для оценивания a не требуется специфицировать динамику. Удивительно, но эта двухшаговая оценка имеет превосходные свойства. Оказывается, она так же эффективна, как и оценка максимального правдоподобия, основанная на известном значении а , что устанавливается в приводимой ниже теореме.
Теорема 2. Двухшаговая оценка параметров уравнения в модели коррекции ошибки, использующая а из (4.5) как истинное значение а, имеет такое же предельное распределение, как и оценка максимального правдоподобия с истинным значением а. Стандартные ошибки метода наименьших квадратов будут состоятельными оценками истинных стандартных ошибок.
Доказательство. Перепишем первое уравнение системы в модели коррекции ошибок (3.4) следующим образом:
У = Yzt-i + Wtfi + st + у(zt-i — zt-i), zt = Xtа, zt = Xtoc,
где Xt = x’t, W — матрица, элементами которой являются Axt i, а y является элементом вектора Axt, так что все регрессоры имеют тип I(0). Опуская нижние индексы, получаем:
VT
Y -Y ß -ß
= [(z,W)'(z,W) / T]-1 [(z,W)'{e + y)(z — z)/ T] / VT.
Это выражение упрощается, потому что z'(z — z) = 0 . Из работ (Fuller, 1976) или (Stock, 1984) следует, что XX ¡T2 и XW/T имеют порядок 1. Значит,
W'(z — z)/yfr = [WX/T][T(a — a)]/[l/ VT],
и, следовательно, первый и второй коэффициенты справа от знака равенства имеют порядок 1, а третий стремится к нулю, так что все выражение асимптотически равно нулю. Так как слагаемые в (z — z)/VT в пределе исчезают, стандартные ошибки метода наименьших квадратов будут состоятельными.
Пусть S = plim[(Z,W)'(z,W)/T], тогда
VT
Y -Y ß -ß.
U D(0,а2S-1),
где D является предельным распределением. При дополнительных стандартных предположениях можно гарантировать нормальность этого распределения.
Для утверждения, что оценка с использованием истинного значения а имеет то же предельное распределение, достаточно показать, что предел по вероятности последовательно-
сти [(z,W) ‘(z,W)/T ] также равен S, и что zS
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Д/T
имеет то же предельное распределение,
что и z ‘s/JT . Рассмотрим сначала внедиагональные элементы S: -с
£
z W/Т — zW/Т = Т(а-а)'[W’X /T] /(1/T) . ^
Первый и второй коэффициенты имеют порядок 1, а третий коэффициент — порядок ^ 1/T , поэтому все выражение асимптотически обращается в ноль:
(z — z) ‘ (z — z) /T = z’z /T — zz /T = T(á -a) [XX /T2]T(á -a)(1 /T) .
Л
é
Снова первые три коэффициента имеют порядок 1, а последним коэффициентом явля-
о
ется 1/ Т , так что даже если разность между этими ковариационными матрицами будет по- £ ложительно определена, она асимптотически исчезнет. И, наконец,
(г — г)’е /л/Т = Т(а — а)Х£ / Т]1 / л/Т ,
что тоже асимптотически исчезает.
При выполнении стандартных условий оценка с использованием истинного значения а будет являться асимптотически нормальной и, следовательно, двухступенчатая оценка также будет асимптотически нормальной в этих условиях. Это завершает доказательство.
Приведем простой пример, который иллюстрирует многие из этих вопросов и обосновывает подход к тестированию, описываемый в следующем разделе. Предположим, что имеется два ряда, хи и х2(, которые совместно генерируются как функция от возможно коррелированных белых шумов еи и е2г в соответствии со следующей моделью:
ХИ + РХ21 = иИ , иИ = иИ-1 + £И , (4.7)
хи + ах21 = и21, и21 = ри2{-1 + е21., р< 1. (4.8)
Очевидно, параметры а и в являются неидентифицируемыми в обычном смысле, т. к. нет экзогенных переменных и ошибки коррелируют в один и тот же момент времени.
В приведенной форме этой системы ряды хи и х2, являются линейными комбинациями ии и и21, следовательно, оба имеют тип I(1). Второе уравнение описывает стационарную линейную комбинацию этих переменных. Таким образом, хи и х2( являются С1 (1,1) и вопрос состоит в том, можно ли это выявить и оценить параметры.
Удивительно, но это сделать легко. Линейная регрессии метода наименьших квадратов хи на х2( дает отличную оценку параметра а. Это и есть «коинтеграционная регрессия». Все линейные комбинации хи и х21, за исключением заданной уравнением (4.8), будут иметь бесконечную дисперсию, и, следовательно, метод наименьших квадратов легко сможет оценить а . Корреляция между х2( и и2г, которая приводит к смещению в одновременных уравнениях, имеет по Т более низкий порядок, чем дисперсии х2(. На самом деле обратная регрессия х2( на х1( имеет такие же свойства и, следовательно, дает состоятельную оценку параметра 1/ а. Эти оценки сходятся к истинному значению быстрее, чем в стандартных эконометрических моделях.
Хотя существуют и другие состоятельные оценки а, однако некоторые кажущиеся очевидными оценки таковыми не будут. Например, регрессия первых разностей хи на первые разности х2( не будет состоятельной, и использование процедуры Кохрейна-Оркатта или другой коррекции на автокорреляцию в коинтеграционной регрессии будет приводить к не-
состоятельным оценкам. После построения оценки параметра а другие параметры на ее основе могут быть оценены различными способами.
Для модели в (4.7) и (4.8) можно получить представление в виде авторегрессии, вычитая лагированные значения из обеих частей равенства и обозначая 8 = (1 — р) / (а — в)):
Дхи = в8хи-1 + аРхъ-1 , (4.9)
Ax2t = -8 хи-1 + а8 x2t-1 + п, (4.10)
где Г1 представляют собой линейную комбинацию е. Тогда модель коррекции ошибок приобретает следующий вид:
Дхи =р8г-1 , (4.11)
^ = -8-1 + П , (4.12)
где zt_1 = x1t + аx2t. В исходной модели есть три неизвестных параметра, представление в виде авторегрессии содержит четыре неизвестных коэффициента, в то время как модель коррекции ошибок содержит два параметра. После того как а становится известно, ограничение в модели коррекции ошибок, которое обуславливает двухшаговую оценку, исчезает. Отметим, что если р ^ 1, ряды превращаются в коррелированные случайные блуждания, которые не являются коинтегрированными.
5. тестирование коинтеграции
Проблема тестирования коинтеграции возникает довольно часто. Например, при ответе на вопрос, находится ли экономическая система в долговременном равновесии. Целесообразно также проверить подобную гипотезу прежде, чем оценивать многомерную динамическую систему.
К сожалению, эта ситуация является нестандартной, и проверка гипотезы не сводится к применению обычных тестов типа теста Вальда, отношения правдоподобия или теста множителей Лагранжа. Эта проблема тесно связана с задачей тестирования единичных корней в наблюдаемых рядах, которую первоначально сформулировали Fuller (1976) и Dickey, Fuller (1979,1981) и затем Evans, Savin (1981), Sargan, Bhargava (1983), Bhargava (1984) и Nelson, Plosser (1983). Она также связана с задачей тестирования с параметрами, не идентифицируемыми при нулевой гипотезе, как это описано в работах (Davies, 1977) и (Watson, Engle, 1982).
Для иллюстрации проблем, возникающих при тестировании подобных гипотез, рассмотрим простую модель (4.7) и (4.8). В данном случае нулевая гипотеза — это отсутствие коинтеграции или р = 1. Если бы параметр а был известен, то тест можно было построить по аналогии с тестом Дики-Фуллера, считая, что ряд zt имеет единичный корень при нулевой гипотезе. Уже в данном случае распределение не будет стандартным, оно вычислено с помощью метода Монте-Карло и описано в статье (Dickey, 1976). Однако, когда параметр а неизвестен, он должен быть оценен. Но если нулевая гипотеза утверждает, что р = 1, параметр а не идентифицируем. Таким образом, только если ряды коинтегрированы, а может быть просто оценен с помощью «коинтеграционной регрессии», но тест должен быть основан на распределении статистики, когда верна нулевая гипотеза. МНК строит оценку параметра а, минимизируя дисперсию остатков и делая остатки как можно более стацио-
нарными. Иными словами, тест Дики-Фуллера будет отвергать нулевую гипотезу слишком
часто, если параметр a оценивается. Ц
В этой статье предлагается набор из семи тестовых статистик для проверки нулевой ги- ¿L
потезы отсутствия коинтеграции против альтернативной гипотезы ее существования. Пред- %
„ „ Ч
полагается, что истинная система является двумерной линейной векторной авторегрессией ч^
с гауссовскими ошибками, причем каждый из рядов является I(1). Так как нулевая гипотеза ^
является составной, эти тесты строились таким образом, чтобы вероятность ее отвергнуть |
была постоянной по набору параметров, включенных в нулевую гипотезу. Более подробно ^
см. (Cox, Hinkley, 1974, pp. 134-136). ^
Можно выделить два случая. В первом случае система имеет первый порядок, и поэтому
нулевая гипотеза описывается соотношениями
Очевидно, что это — модель (4.11) и (4.12), когда р = 1, откуда следует, что 5 = 0. Составная нулевая гипотеза включает в себя все положительно определенные ковариационные матрицы О. Как будет показано ниже, распределения всех тестовых статистик инвариантны относительно матрицы О, поэтому без ограничения общности можно считать, что О = I.
Во втором случае предполагается, что система стационарна в разностях. Следовательно, нулевая гипотеза включает все коэффициенты стационарных моделей авторегрессии и скользящего среднего, а также О. Описываемые ниже «расширенные» тесты в этом случае имеют асимптотически инвариантные распределения подобно тому, что было установлено Дики и Фуллером для тестов в одномерном случае.
Семь предложенных тестовых статистик вычисляются с помощью метода наименьших квадратов. Для каждой из них путем моделирования 10000 повторений найдены критические значения. С использованием симуляций вычисляются мощности тестов для различных альтернатив. Ниже дается краткое описание каждого теста.
1. CRDW. Оценивается коинтеграционная регрессия и вычисляется статистика Дарбина-Уотсона (ОЖ) для проверки стационарности остатков. Если они не стационарны, ОЖстремится к нулю и, следовательно, если ОЖ принимает слишком большие значения, тест отвергает отсутствие коинтеграции (находит коинтеграцию). Этот тест был предложен Bhargava (1984) для случая, когда нулевая и альтернативная гипотезы являются моделями первого порядка.
2. БЕ Этот тест проверяет остатки коинтеграционной регрессии, оценивая дополнительную регрессию, как описано Дики и Фуллером и показано в табл. I. Также предполагается, что модель первого порядка верна.
3. АБЕ Расширенный тест Дики-Фуллера допускает более сложную динамику в регрессии DF и, следовательно, имеет слишком много параметров в случае модели первого порядка, но правильно специфицирован в случае высших порядков.
4. ЯУАЯ. Тест для векторной авторегрессии с ограничениями похож на двухшаговую оценку. На основании коинтеграционной регрессии оценивается коинтеграционный вектор, который затем участвует в оценке модели коррекции ошибок. Тест проверяет, является ли переменная коррекции ошибок значимой. Этот тест требует, чтобы динамика системы была полностью специфицирована. При этом предполагается, что система имеет первый порядок. Приведение системы к треугольному виду делает ошибки некоррелированными, и в пред-
4y = £it T(£it) ^Xt = S2t _(s2t )
~ N (0, Q) .
(5.1)
положении нормальности г-статистики будут независимы. Тест основан на сумме квадратов г-статистик.
5. ARVAR. Расширенный RVAR — тест аналогичен RVAR за исключением того, что система по предположению имеет более высокий порядок.
6. UVAR. Тест VAR без ограничения основан на векторной авторегрессии в уровнях при отсутствии ограничений на коинтеграцию. При нулевой гипотезе коинтеграции и так нет, поэтому тест просто проверяет, может ли модель быть выражена адекватно исключительно через разности. Снова, приводя матрицу коэффициентов к треугольной форме, можно независимо вычислить ^-статистики каждой из двух регрессий, и общая тестовая статистики будет являться их суммой, умноженной на их степени свободы, т. е. на 2. При этом вновь предполагается, что система имеет первый порядок.
7. AUVAR. Это расширенная версия предыдущего теста для систем более высокого порядка.
Чтобы установить сходство этих тестов в случае систем первого порядка для всех положительно определенных симметричных матриц О, достаточно показать, что остатки от регрессии у на х для общей матрицы О отличаются скалярным множителем от остатков для случая О = I. Чтобы установить это, предположим, что еи и еъ, являются независимыми стандартными нормальными случайными величинами. Тогда
У = Еек-, Ъ = Е£2, (5.2)
¿=1, г ¿=1,г
и ut = У1 — X ЕХг2 . (5.3)
Для создания у * и х * в случае произвольной матрицы О положим
4 = с£и, 4 = а£и + Ьем, (5.4)
где
С = , а = ®ух / С , Ь =®уу / ®хх .
Тогда, подставляя (5.4) в (5.2), получаем:
х* = сх , у* = ау + Ьх ,
ау( + Ьх1 — сх Е(ау( + Ьх1) сх^Е с2х2 = аи ,
что и устанавливает инвариантность распределений тестов. Если используются одни и те же случайные числа, вне зависимости от О будут получены одни и те же тестовые статистики.
В более сложном, но вполне реалистичной случае, когда система имеет бесконечный порядок, но может быть аппроксимирована авторегрессией порядкар, распределения статистики будут совпадать только асимптотически. Хотя точное совпадение достигается в гауссов-ских моделях с фиксированными регрессорами, в моделях временных рядов эта ситуация не реализуется, и совпадение только асимптотическое. Поэтому тесты 5 и 7 асимптотически подобны, если модель порядкар верна, но тесты 1, 2, 4 и 6 заведомо не являются даже асимптотически подобными, т. к. в них опущены лагированные значения переменных (ситуация аналогична возникновению смещений стандартных ошибок при наличии автокорреляции ошибочных членов). На этом основании мы предпочитаем не предлагать эти последние упо-
мянутые тесты, кроме случая первого порядка. Тест 3 также будет асимптотически подоб- ^
ным в предположении, что и, остаток от коинтеграционной регрессии, является процессом Ц
порядка p. Этот результат был доказан в статье (Dickey, Fuller, 1981, pp. 1065-1066). Хотя ¿L
предположение, что система имеет порядок p, допускает остатки бесконечного порядка, су- %
Ч
ществует, вероятно, конечная модель авторегрессии, возможно, меньшего порядка, чем p, ч^ которая будет хорошим приближением. Поэтому целесообразно провести некоторое ис- ^ следование для нахождения наиболее подходящего значения p в обоих случаях. Альтерна- | тивной стратегией является выбор параметра p, который медленно растет как неслучайная ^ функция от T, что тесно связано с тестом, предложенным Phillips (1985) и Phillips, Durlauf ¡^ (1985). Только численное моделирование позволит понять, предпочтительно ли использовать выбранное на основе данных p для этой тестовой процедуры, хотя ниже показано, что оценка лишних параметров приводит к снижению мощности теста.
В таблице I формально описаны статистики семи тестов. В таблице II представлены критические значения и мощности тестов, когда система имеет первый порядок. Следует ожидать, что расширенные тесты будут менее мощными, потому что они оценивают параметры, которые в действительности являются нулями и при нулевой, и при альтернативной гипотезах. Остальные четыре теста не оценивают внешние параметры и правильно специфицированы для этого эксперимента.
С помощью табл. II можно на 5%-ном уровне проверить гипотезу отсутствия коинтеграции, просто вычислив статистику Дарбина-Уотсона DW в коинтеграционной регрессии, и, если это значение DW превышает 0.386, отвергнуть нулевую гипотезу и найти коинте-грацию. Если истинная модель — это модель II с р = 0.9, а не 1, это будет выявлено только в 20% случаев; однако если р = 0.8, частота выявления составит 66%. Ясно, что тест 1 является лучшим по мощности и должен быть выбран для этой спецификации, а показатели теста 2 почти в каждом случае находятся на втором месте после теста 1. Заметим также, что расширенные тесты имеют практически те же критические значения, что и базовые, но, как и ожидалось, они имеют несколько меньшую мощность. Таким образом, если известно, что система имеет первый порядок, не следует вводить дополнительные лаги. Вопрос о том, полезен ли предварительный тест для установления порядка системы, остается открытым.
В таблице III и при нулевой, и при альтернативной гипотезах система есть авторегрессия четвертого порядка. Поэтому использование нерасширенных тестов приводит к неправильной спецификации, и корректным является применение расширенных тестов (хотя некоторые из промежуточных лагов могут быть обнулены, если это известно). Заметим, что уменьшение критических значений в тестах 1, 2, 4 и 6 вызвано отсутствием инвариантности распределения, о котором говорилось выше. При этих новых критических значениях тест 3 является самым мощным для локальной альтернативы, а при р = 0.8 тест 1 является лучшим, в то время как тесты 2 и 3 слегка уступают. Неправильно специфицированные или нерасширенные тесты 4 и 6 в этой ситуации работают плохо. Хотя таблица II демонстрирует их умеренную мощность, рассматривать их здесь нет необходимости.
Несмотря на то что тест 1 имеет в целом лучшее качество, его следует использовать с осторожностью, поскольку критическое значение очень чувствительно к значениям параметров в рамках нулевой гипотезы. Для большинства экономических данных разности не являются белым шумом, и поэтому на практике не всегда понятно, какими критическими значениями следует пользоваться. Тест 3, расширенный тест Дики-Фуллера, по существу, имеет то же критическое значение для обеих конечных выборок, использовавшихся в экс-
Таблица I. Тестовые статистики: отвергать нулевую гипотезу для больших значений
1. Коинтеграционная регрессия Дарбина-Уотсона yt = axt + c + ut. £1 = DW . Нулевая гипотеза: DW = 0.
2. Регрессия Дики-Фуллера: Dut = —ful—1 + et. £2 =тф : t статистика для ф.
3. Расширенная регрессия Дики-Фуллера: Dut = —фи1—1 + b1Aul—1 +… + blAul — p + st.
£3 =тф.
4. VAR с ограничениями: Dyt = b1ut—1 + e1t, Dxt = b2ut—1 + gDyt + e2t. £ =t2 +T2
£4 l01 + Lb 2′
5. Расширенная VAR с ограничениями: такая же, как в 4, но с p лагами Dyt и Dxt в каждом уравнении. £ =т2 +т2
£ 5 Lb1 + Lb 2′
6. VAR без ограничений: Dyt = b1yt—1 + b2xt—1 + c1 + e1t, Dxt = b3yt—1 + b4xt—1 + yDyt + c2 + e2t.
£6 = 2 [F¡ + F2 ] , где F1 — F-статистика для тестирования гипотезы о равенстве нулю b1 и b2 в первом уравнении, F2 — аналогичная F-статистика для второго уравнения.
7. Расширенная VAR без ограничений: такая же, как в 6, но с p лагами Dxt и Dyt в каждом уравнении.
у7 = 2[ F + F2 ]._
Примечание. yt и xt — исходные ряды данных, ut — остатки из коинтеграционной регрессии.
периментах, то же теоретическое критическое значение для большой выборки в обоих случаях, и почти такие же хорошо наблюдаемые свойства мощности в большинстве сравнений, и, значит, именно этот тест рекомендуется использовать.
Из-за своей простоты тест CRDW может быть применен для быстрого получения приближенного результата. Замечательно, что лучшие из предложенных тестов не требуют оценки всей системы, а только коинтеграционной регрессии, а затем, возможно, вспомогательных временных регрессий.
Этот анализ оставляет много вопросов без ответа. Критические значения построены только для выборки одного размера и только в двумерном случае, хотя в последнее время Engle, Yoo (1986) подсчитали критические значения для нескольких переменных и разных размеров выборки, используя тот же общий подход. Теории оптимальности для таких тестов пока нет, и, возможно, альтернативные подходы могут дать лучшие результаты. Исследования теории предельного распределения в статьях (Phillips, 1985) и (Phillips, Durlauf, 1985) могут привести к улучшению качества тестов.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Тем не менее, кажется, что критические значения для ADF, приведенные в табл. II, могут быть использованы как хороший ориентир в прикладных исследованиях по данному вопросу. В следующем разделе рассмотрены некоторые примеры.
6. примеры
Эмпирические примеры, рассматриваемые ниже, демонстрируют качество тестов на практике. Довольно подробно будет изучено соотношение между потреблением и доходом, подобно тому, как оно было проанализировано с помощью модели коррекции ошибок в (Davidson et al., 1978) и с помощью анализа временных рядов в работе (Hall, 1978) и дру-
Таблица II. Критические значения и мощность
I модель: Dyt, Dxt независимые стандартные нормальные, 100 наблюдений, 10 000 повторений, p = 4 .
Статистика
Название
Критические значения 1%
5%
10%
i CRDW 0.511 0.386 0.322
2 DF 4.07 3.37 3.03
3 ADF 3.77 3.17 2.84
4 RVAR 18.3 13.6 11.0
5 ARVAR 15.8 11.8 9.7
6 UVAR 23.4 18.6 16.0
7 AUVAR 22.6 17.9 15.5
II модель: yt + 2xt = ut. , Dut = (p-l)ut_ i +et, xt + У, =vt, Avt: = v,; p = 0.8,0.9 ,
100 наблюдений, 1000 повторений, p = 4.
Отклонений на 100: p = 0.9
Статистика Название 1% 5% 10%
i CRDW 4.8 19.9 33.6
2 DF 2.2 15.4 29.0
3 ADF 1.5 11.0 22.7
4 RVAR 2.3 11.4 25.3
5 ARVAR 1.0 9.2 17.9
6 UVAR 4.3 13.3 26.1
7 AUVAR 1.6 8.3 16.3
Отклонений на 100: p = 0.8
Статистика Название 1% 5% 10%
í
С) £
4 ¡
é
h-£
О
о.
CRDW
DF
ADF
RVAR
ARVAR
UVAR
AUVAR
34.0 20.5 7.8 15.8 4.6 19.0 4.8
66.4 59.2 30.9
46.2 22.4 45.9
18.3
82.1 76.1
51.6 67.4 39.0
63.7 33.4
гих. Более кратко анализируется связь заработной платы и цен, краткосрочных и долгосрочных процентных ставок. Обсуждение скорости обращения денег завершит этот раздел.
В работе (Davidson et al., 1978) приведены эмпирические и теоретические аргументы в пользу модели коррекции ошибок для описания потребительского поведения. Потребители формируют планы, которые могут не реализоваться. Тогда потребители корректируют планы на следующий период, чтобы компенсировать долю ошибки между доходом и по-
Таблица III. Критические значения и мощность с лагами
Модель I: Ay, = 0.8Ayt-4 + et, Axt = 0.8Axt-4 + r]t, 100 наблюдений, 10 000 повторений, p = 4,
et, r]t — независимые стандартные нормальные.
Критические значения
Статистика Название 1% 5% 10%
1 CRDW 0.455 0.282 0.209
2 DF 3.90 3.05 2.71
3 ADF 3.73 3.17 2.91
4 RVAR 37.2 22.4 17.2
5 ARVAR 16.2 12.3 10.5
6 UVAR 59.0 40.3 31.4
7 AUVAR 28.0 22.0 19.2
Модель II: yt + 2 xt = ut, Aut = (p-1)ut_ 4 + .8Aut-4 + et, yt + xt = vt, Avt = 0.8Avt-4 + p = 0.9, 0.8,
100 наблюдений, 1000 повторений, p = 4.
Отклонений на 100 : p = 0.9
Статистика Название 1% 5% 10%
1 CRDW 15.6 39.9 65.6
2 DF 9.4 25.5 37.8
3 ADF 36.0 61.2 72.2
4 RVAR 0.3 4.4 10.9
5 ARVAR 26.4 48.5 62.8
6 UVAR 0.0 0.5 3.5
7 AUVAR 9.4 26.8 40.3
Отклонений на 100 : p = 0.8
Статистика Название 1% 5% 10%
1 CRDW 77.5 96.4 98.6
2 DF 66.8 89.7 96.0
3 ADF 68.9 90.3 94.4
4 RVAR 7.0 42.4 62.5
5 ARVAR 57.2 80.5 89.3
6 UVAR 2.5 10.8 25.9
7 AUVAR 32.2 53.0 67.7
треблением. Hall считает, что потребление в США является случайным блужданием, и последние значения дохода не имеют объясняющей силы. Отсюда вытекает, что доходы и потребления являются некоинтегрированными, по крайней мере, если доход не зависит от переменной коррекции ошибок. Ни одна из рассмотренных теорий не моделирует доход сам по себе, и в (Davidson et al., 1978) он является экзогенным.
Используются квартальные данные реального потребления на душу населения товаров недлительного пользования и реального располагаемого дохода на душу населения в США Ц с 1947:1 по 1981: II. Первоначально было проверено, что временные ряды являются 7(1). ¿L При оценивании регрессии первой разности потребления на его прошлый уровень и две ^ первых лагированных разности было получено значение /-статистики, равное +0.77, даже ч^ знак этой статистики указывает на неверность гипотезы о стационарности потребления. ^ Оценивание аналогичной регрессии вторых разностей на прошлые значения первых раз- | ностей и два лагированных значения вторых разностей дает значение /-статистики, равное ^ -5.36, что свидетельствует о стационарности ряда первых разностей. Для дохода были ис- ¡^ пользованы четыре последних лага, и две /-статистики оказались равными -0.01 и -6.27 соответственно, что снова говорит о стационарности первой разности. Иными словами, доход также является I (1).
Было проведено оценивание коинтеграционной регрессии потребления на доход (Y ) и константу. Коэффициент при Y в этой регрессии равен 0.23 (со значениями /-статистики и R , равными 123 и 0.99 соответственно). Статистика DW оказалась равной 0.465, что в соответствии с обоими табличными критическими значениями позволяет отвергнуть нулевую гипотезу «отсутствия коинтеграции» на 5%-ном уровне, т. е. принять гипотезу о наличии ко-интеграции. Регрессия первой разности остатков на предыдущий уровень и четыре лагированных разности дает /-статистику для коэффициента при уровне, равную 3.1, что является 5%-ным критическим значением для ADF теста. Поскольку лаги незначимы, оценивается DF регрессия, которая дает значение тестовой статистики, равное 4.3, что является 1%-ным критическим значением. Это иллюстрирует тот факт, что если DF тест подходит, то он имеет большую мощность, чем ADF тест. В обратной регрессии Y на С коэффициент равен 4.3, обратное этому числу равно 0.23 — такое же, как коэффициент в прямой регрессии. Статистика DW теперь равна 0.463, и /-статистика теста ADF есть 3.2 . Опять обычный DF представляется целесообразным и дает тестовую статистику 4.4. Какую бы регрессию ни запускать, данные отвергают гипотезу отсутствия коинтеграции на любом уровне выше 5%.
Чтобы установить, что совместное распределение и Y является системой коррекции ошибок, оценивается несколько моделей. В таблице IV представлена векторная авторегрессия (без ограничения) разности потребления на четыре лагированных значения разности потребления и разности дохода плюс лагированные значения уровней потребления и дохода. Коэффициенты при лагированных значениях уровней потребления и дохода имеют «правильные» знаки, а коэффициенты при корректирующем слагаемом — «правильные» размеры. Эти коэффициенты индивидуально значимы или почти значимы. Из всех лагированных значений разностей значимым является только первый лаг разности дохода. Таким образом, итоговая модель включает переменную коррекции ошибок, оцененную из коинтеграцион-ной регрессии, и один лаг разности дохода. Стандартная ошибка этой модели даже ниже, чем модели VAR. Для этой модели был проведен ряд диагностических тестов на автокорреляцию, лаги зависимых переменных, нелинейность, ARCH и пропущенные переменные, такие как временной тренд и другие лаги.
Можно заметить, что удобная стратегия построения модели в этом случае предлагает оценить сначала простейшую модель коррекции ошибок, а затем тестировать значимость дополнительных лагов и Y, следуя методу «от частного к общему».
Подход к построению модели для дохода Y аналогичен. Оценивается та же векторная авторегрессия без ограничений, а затем она приводится к простой модели, содержащей кор-
Таблица IV. Регрессии дохода и потребления
C DEC DEC DC DEC
Y 0.23 (123)
C(-l) -0.19 (-2.5)
Y(-l) 0.046 (2.5)
EC(-l) -0.22 (-3.1) -0.26 (-4.3) -0.14 (-2.2)
AC(-l) 0.092 (0.9)
AC(-2) 0.017 (0.2)
AC(-3) 0.016 (1.5)
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
AC(-4) 0.009 (0.1)
AY(-l) 0.059 (1.8) 0.068 (2.5)
AY(-2) -0.023 (-0.7)
AY(-3) -0.027 (-0.8)
AY(-4) -0.020 (-0.7)
AEC( -1) -0.13 (-1.4)
AEC(-2) 0.12 (1.4)
AEC(-3) 0.03 (0.4)
AEC(-4) -0.13 (-1.6)
CONST 0.52 (85) 0.10 (2.4) 0.003 (2.6)
a 0.01628 0.00999 0.01015 0.01094 0.01078
DW 0.46 2.0 2.2 2.0 1.9
Y DEY DEY DY DY
C 4.29 (123)
C(-l) 0.15 (0.67)
Y (-1) -0.034 (0.63)
EY(-l) -0.053 (-1.1)
AC(-l) 0.79 (2.5) 0.66 (2.4)
AC(-2) -0.48 (-1.5)
AC(-3) 0.68 (2.2)
AC(-4) 0.56 (1.8) 0.60 (2.1)
AY(-l) -0.027 (-0.3)
AY(-2) -0.051 (-0.5)
AY(-3) 0.011 (0.1)
AY(-4) -0.23 (-2.5) -0.19 (2.1)
AEY(-l) -0.13 (-1.5)
AEY(-2) 0.12 (1.4)
AEY(-3) 0.03 (0.4)
AEY(-4) -0.14 (-1.6)
CONST 2.22 (-50) -0.071 (-0.6) 0.016 (4.6)
a 0.07012 0.04279 0.04350 0.03255 0.03321
DW 0.046 2.0 2.2 2.1 2.2
Примечание. Данные с 1947:1 по 1981:11. ЕС — остатки из первой регрессии, EY — остатки из шестой регрессии. В скобках указаны Г-статистики.
ректирующее слагаемое, первый и четвертый лаги первой разности и четвертый лаг первой разности У. Переменная коррекции ошибок в данном случае незначима (г-статистика
í
равна -1.1). Это означает, что доход может быть слабо экзогенным, даже несмотря на то, ¿L что переменные коинтегрированы. Стандартная ошибка в модели с ограничением немного ^ выше, но разница несущественна. Как и раньше, модель «выдерживает» соответствующие ч^ диагностические тесты. ^
Campbell (1985) применяет аналогичный подход для проверки гипотезы постоянства до- | хода, которая включает в себя поведение «экономия на черный день». В этом случае пере- ^ менная коррекции ошибок приближенно представляет сбережение, которое должно быть ^ больше, когда ожидается уменьшение дохода (например, когда текущий доход выше постоянного дохода). Расширяя меру потребления и сужая меру дохода, он получает значимой переменную коррекции ошибок в уравнении дохода.
Во втором примере анализируется связь между ежемесячной заработной платой и ценами в США. Данные представлены в логарифмах индекса потребительских цен и зарплаты работников обрабатывающей промышленности за три десятилетия — 50-е, 60-е и 70-е годы. Снова проводится тест в обоих направлениях, чтобы показать небольшое различие в результатах. Для каждого из десятилетий имеется 120 наблюдений, поэтому можно пользоваться табличными критическими значениями.
Для коинтеграционной регрессии по полной выборке статистика Дарбина-Уотсона в любом направлении равна 0.0054 . Она незначимо отличается от нуля даже для выборок, значительно больших, чем эта. Значение тестовой статистики в расширенном тесте Дики-Фуллера для p на w равно -0.6 и для w на p равно +0.2 . Добавление двенадцатого лага в ADF тестах приводит к существенному улучшению подгонки модели и увеличивает тестовую статистику до 0.88 и 1.50 соответственно. Ни в одном из случаев критическое значение 3.2 не достигается. Поэтому принимается нулевая гипотеза об отсутствии коинтеграции заработной платы и цен за период тридцать лет.
Для отдельных десятилетий ни один из ADF тестов не является значимым даже на 10%-ном уровне. Наибольшая из этих шести тестовых статистик для 50-х годов в регрессии p на w равна 2.4 , что все еще ниже 10%-ного уровня 2.8 . Таким образом, можно сделать вывод о том, что заработная плата и цены в США не коинтегрированы. Конечно, если бы была доступна третья переменная, например производительность, и она тоже была бы I (1), возможно, коинтеграция была бы выявлена.
В следующем примере исследуется коинтеграция краткосрочных и долгосрочных процентных ставок. В качестве долгосрочных ставок R используется ежемесячная доходность к погашению 20-летних государственных облигаций, а краткосрочная ставка rt — это ставка одномесячных казначейских векселей. Оценка коинтеграционной регрессии долгосрочной ставки на краткосрочную на промежутке времени с февраля 1952 г. по декабрь 1982 г. дает следующие результаты:
Rt = 1.93 + 0.785rt + ER, DW = 0.126, R2 = 0.866,
t-статистика коэффициента при короткой ставке равна 46 . В соответствии с табл. II и III статистика DW незначимо отличается от нуля, однако точное критическое значение зависит от динамики ошибок (и, конечно, размер выборки в 340 намного больше, чем для табличных значений). Результаты ADF теста с четырьмя лагами:
AER = -0.06 ER . + 0.25 AER . — 0.24 AER, 2 + 0.24 AER, 3 — 0.09 AER, 4.
‘ (-3.27) ‘ 1 (4.55) ‘ 1 (-4.15) ‘ 2 (4.15) ‘ 3 (-1.48) ‘ 4
Когда добавляется двенадцатый лаг вместо четвертого, тестовая статистика увеличивается до 3.49. Обратная регрессия дает похожие результаты: статистики равны 3.61 и 3.89 соответственно. Каждая из этих тестовых статистик превышает 5%-ные критические значения из табл. III. Поэтому эти процентные ставки можно считать коинтегрироваными.
Этот вывод полностью согласуется с гипотезой эффективного рынка. Однопериодная избыточная доходность долгосрочных облигаций в соответствии с линеаризацией (Shiller, Campbell, 1984) есть
EHY = DRt-1 — (D -1) Rt — rt, где D — дюрация облигации, определяемая равенством
D = ((1 + c)’ -1)/(c(1 + c)-1),
где c — ставка купона, i — число периодов до даты погашения. Гипотеза эффективного рынка предполагает, что ожидание EHY постоянно и представляет собой премию за риск, если агенты не склонны к риску. Определяя EHY = k + s и переставляя слагаемые, получаем модель коррекции ошибок
AR = (D -1)-1 (Rt-i — -i) + kt’+st,
в которой R и r являются коинтегрированными с единичным коэффициентом, и для длительных сроков погашения коэффициент при переменной коррекции ошибок равен c, т. е. ставке купона. Если премия за риск меняется с течением времени, но является рядом I (0), то не нужно включать ее в тест на коинтеграцию.
Последний пример основан на уравнении количественной теории: MV = PY. Эмпирические выводы вытекают из предположения, что скорость постоянна или, по крайней мере, стационарна. При этом условии logM, log P и log Y должны быть коинтегрированы с единичными параметрами. Также коинтегрированными должны быть номинальная денежная масса и номинальный ВНП. Была проведена проверка этой гипотезы для четырех денежных агрегатов: Mi, M2, M3 и L (все ликвидные активы). В каждом случае использовались квартальные данные с 1959: I по 1981: II. Ниже приведены статистики ADF тестов:
Ml 1.81 1.90
M2 3.23 3.13
M3 2.65 2.55
L 2.15 2.13
Первый столбец соответствует регрессиям, где зависимой переменной является логарифм соответствующего денежного агрегата, второй — логарифм ВНП. Только один из тестов для М2 значим на 5%-ном уровне, и ни один из других агрегатов не являются значимым даже на 10%-ном уровне (в некоторых случаях можно было бы использовать DF тест и получить большую мощность). Таким образом, наиболее устойчивое соотношение имеется между М2 и номинальным ВНП, а для других агрегатов коинтеграция и стационарность скорости отвергаются.
7. Выводы 8-
I
Если каждый элемент вектора временного ряда хг является стационарным только после
взятия первой разности, но при этом линейная комбинация а’хг является стационарной, ^
временной ряд хг является коинтегрированным порядка (1,1) с коинтегрирующим вектором ч^
а . Если интерпретировать равенство а’хг = 0 как долгосрочное равновесие, коинтеграция ^
означает, что долговременное равновесие существует с точностью до стационарных возму- |
о
е
а
Вф
статье приведено несколько представлений коинтегрированных систем, включая авто-
ои
щений с конечной дисперсией, даже если исходные временные ряды не являются стационарными и имеют бесконечную дисперсию.
регрессии и модель коррекции ошибок. Векторная авторегрессия в разностях несовместна с этими представлениями, потому что в ней отсутствует корректирующее слагаемое. Векторная авторегрессия в уровнях игнорирует перекрестные ограничения и порождает сингулярный авторегрессионный оператор. Обсуждается состоятельность и эффективность оценки моделей коррекции ошибок и описывается двухшаговая процедура оценивания. Для проверки коинтеграции предложены семь тестовых статистик. Методом Монте-Карло получены их критические значения. С помощью полученных критических значений исследованы мощности тестов, и одна из процедур тестирования рекомендована для применения.
Рассмотренные примеры показывают, что потребление и доход являются коинтегриро-ваными, а заработная плата и цены нет, краткосрочные и долгосрочные процентные ставки коинтегрированы, а номинальный ВНП не является коинтегрированным с М1, М3 или всеми ликвидными активами, но возможно, коинтегрирован с М2.
Департамент экономики Университета Калифорнии — Сан-Диего, США.
Рукопись получена в сентябре 1983 г., окончательный вариант получен в июне 1986 г.
Список литературы
Bhargava Alok (l984). On the theory of testing for unit roots in observed time series. Manuscript, ICERD, London School of Economics.
Box G. E. P., Jenkins G. M. (l970). Time series analysis, forecasting and control. San Francisco: Holden Day.
Campbell J. Y. (l985). Does saving anticipate declining labor income? An alternative test of the permanent income hypothesis. Manuscript, Princeton University.
Cox D. R., Hinkley C. V (l974). Theoretical statistics. London: Chapman and Hall.
Currie D. (l98l). Some long-run features of dynamic time-series models. The Economic Journal, 9l, 704-7l5.
Davidson J. E. H., Hendry D. F., Srba F., Yeo S. (l978). Econometric modelling of the aggregate time-series relationship between consumer’s expenditure and income in the United Kingdom. Economic Journal, 88, 66l-692.
Davies R. R. (l977). Hypothesis testing when a nuisance parameter is present only under the alternative. Biometrika, 64, 247-254.
Dawson A. (l98l). Sargan’s wage equation: A theoretical and empirical reconstruction. Applied Economics, l3, 35l-363.
Dickey D. A. (1976). Estimation and hypothesis testing for nonstationary time series. PhD. Thesis, Iowa State University, Ames.
Dickey D. A., Fuller W. A. (1979). Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74, 427-431.
Dickey D. A., Fuller W. A. (1981). The likelihood ratio statistics for autoregressive time series with a unit root. Econometrica, 49, 1057-1072.
Engle R. F., Hendry D. F., Richard J. F. (1983). Exogeneity. Econometrica, 51, 277-304.
Engle R. F., Yoo B. S. (1986). Forecasting and testing in co-integrated systems. UCSD Discussion Paper.
Evans G. B. A., Savin N. E. (1981). Testing for unit roots: 1. Econometrica, 49, 753-779.
Feller W. (1968). An introduction to probability theory and its applications, volume I. New York: John Wiley.
Fuller W. A. (1976). Introduction to statistical time series. New York: John Wiley.
Granger C. W. J. (1981). Some properties of time series data and their use in econometric model specification. Journal of Econometrics, 121-130.
Granger C. W. J. (1983). Co-integrated variables and error-correcting models. Unpublished UCSD Discussion Paper 83-13.
Granger C. W. J., Newbold P. (1977). Forecasting economic time series. New York: Academic Press.
Granger C. W. J., Newbold P. (1974). Spurious regressions in econometrics. Journal of Econometrics, 26, 1045-1066.
Granger C. W. J., Weiss A. A. (1983). Time series analysis of error-correcting models. In: Studies in Econometrics, Time Series, and Multivariate Statistics. New York: Academic Press, 255-278.
Hall R. E. (1978). A stochastic life cycle model of aggregate consumption. Journal of Political Economy,, 971-987.
Hannan E. J. (1970). Multiple time series. New York: Wiley.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Hendry D. F., von Ungern-Sternberg T. (1981). Liquidity and inflation effects on consumer’s expenditure. In: Essays in the Theory and Measurement of Consumer’s Behavior, ed. by A. S. Deaton. Cambridge: Cambridge University Press.
Johansen S. (1985). The mathematical structure of error correction models. Manuscript, University of Copenhagen.
Nelson C. R., Plosser C. (1982). Trends and random walks in macroeconomic time series. Journal of Monetary Economics, 10, 139-162.
Pagan A. R. (1984). Econometric issues in the analysis of regressions with generated regressor. International Economic Review, 25, 221-248.
Phillips A. W. (1957). Stabilization policy and the time forms of lagged responses. Economic Journal, 67, 265-277.
Phillips P. C. B. (1985). Time series regression with unit roots. Cowles Foundation Discussion Paper No. 740, Yale University.
Phillips P. C. B., Durlauf S. N. (1985). Multiple time series regression with integrated processes. Cowles Foundation Discussion Paper 768.
Salmon M. (1982). Error correction mechanisms. The Economic Journal, 92, 615-629.
Sargan J. D. (1964). Wages and prices in the United Kingdom: A study in econometric methodology. In: Econometric Analysis for National Economic Planning, ed. by P. E. Hart, G. Mills, and J. N. Whittaker. London: Butterworths.
Sargan J. D., Bhargava A. (l983). Testing residuals from least squares regression for being generated by a
the Gaussian random walk. Econometrica, 5l, l53-l74. ||
Shiller R. J., Campbell J. Y. (l984). A simple account of the behaviour of long-term interest rates. Ameri- |
can Economic Review, 74, 44-48. ^
Stock J. H. (1984). Asymptotic properties of least squares estimators of co-integrating vectors. Manu- ^
script, Harvard University. :><
Watson M. W., Engle R. F. (1985). A test for regression coefficient stability with a stationary AR(1) al- | ternative. Forthcoming in Review of Economics and Statistics4. ^
Yoo S. (1985). Multi-co-integrated time series and generalized error correction models. Manuscript in ¡^ preparation, U.C.S.D.
a.
Engle R. F., Granger C. W. J. Co-integration and error correction: Representation, estimation, and testing. Applied Econometrics, 2015, 39 (3), pp. 107-135 (translation in Russian from Econometrica, Vol. 55, No. 2 (March, 1987), 251-276).
Robert F. Engle
New York University Stern School of Business, USA Clive W. J. Granger
Co-integration and error correction: Representation, estimation, and testing
The relationship between co-integration and error correction models, first suggested in Granger (1981), is here extended and used to develop estimation procedures, tests, and empirical examples. If each element of a vector of time series x, first achieves stationarity after differencing, but a linear combination a’xt is already stationary, the time series x, are said to be co-integrated with co-integrating vector a. There may be several such co-integrating vectors so that a becomes a matrix. Interpreting a ‘ xt = 0 as a long run equilibrium, co-integration implies that deviations from equilibrium are stationary, with finite variance, even though the series themselves are nonstationary and have infinite variance. The paper presents a representation theorem based on Granger (1983), which connects the moving average, autoregressive, and error correction representations for co-integrated systems. A vector autoregression in differenced variables is incompatible with these representations. Estimation of these models is discussed and a simple but asymptotically efficient two-step estimator is proposed. Testing for co-integration combines the problems of unit root tests and tests with parameters unidentified under the null. Seven statistics are formulated and analyzed. The critical values of these statistics are calculated based on a Monte Carlo simulation. Using these critical values, the power properties of the tests are examined and one test procedure is recommended for application.
In a veries of examples it is found that consumption and income are co-integrated, wages and prices are not, short and long interest rates are, and nominal GNP is co-integrated with M2, but not Ml, M3, or aggregate liquid assets.
Keywords: co-integration; vector autoregression; unit roots; error correction; multivariate time series; Dickey-Fuller tests.
JEL classification: C01; C12; C30; C33; C51.
4 Опубликовано в Review of Economics and Statistics, l985, 67, 34l-346 — Прим. ред.
References
Bhargava Alok (1984). On the theory of testing for unit roots in observed time series. Manuscript, ICERD, London School of Economics.
Box G. E. P., Jenkins G. M. (1970). Time series analysis, forecasting and control. San Francisco: Holden Day.
Campbell J. Y. (1985). Does saving anticipate declining labor income? An alternative test of the permanent income hypothesis. Manuscript, Princeton University.
Cox D. R., Hinkley C. V (1974). Theoretical statistics. London: Chapman and Hall.
Currie D. (1981). Some long-run features of dynamic time-series models. The Economic Journal, 91, 704-715.
Davidson J. E. H., Hendry D. F., Srba F., Yeo S. (1978). Econometric modelling of the aggregate time-series relationship between consumer’s expenditure and income in the United Kingdom. Economic Journal, 88, 661-692.
Davies R. R. (1977). Hypothesis testing when a nuisance parameter is present only under the alternative. Biometrika, 64, 247-254.
Dawson A. (1981). Sargan’s wage equation: A theoretical and empirical reconstruction. Applied Economics, 13, 351-363.
Dickey D. A. (1976). Estimation and hypothesis testing for nonstationary time series. PhD. Thesis, Iowa State University, Ames.
Dickey D. A., Fuller W. A. (1979). Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association, 74, 427-431.
Dickey D. A., Fuller W. A. (1981). The likelihood ratio statistics for autoregressive time series with a unit root. Econometrica, 49, 1057-1072.
Engle R. F., Hendry D. F., Richard J. F. (1983). Exogeneity. Econometrica, 51, 277-304.
Engle R. F., Yoo B. S. (1986). Forecasting and testing in co-integrated systems. UCSD Discussion Paper.
Evans G. B. A., Savin N. E. (1981). Testing for unit roots: 1. Econometrica, 49, 753-779.
Feller W. (1968). An introduction to probability theory and its applications, volume I. New York: John Wiley.
Fuller W. A. (1976). Introduction to statistical time series. New York: John Wiley.
Granger C. W. J. (1981). Some properties of time series data and their use in econometric model specification. Journal of Econometrics, 121-130.
Granger C. W. J. (1983). Co-integrated variables and error-correcting models. Unpublished UCSD Discussion Paper 83-13.
Granger C. W. J., Newbold P. (1977). Forecasting economic time series. New York: Academic Press.
Granger C. W. J., Newbold P. (1974). Spurious regressions in econometrics. Journal of Econometrics, 26, 1045-1066.
Granger C. W. J., Weiss A. A. (1983). Time series analysis of error-correcting models. In: Studies in Econometrics, Time Series, and Multivariate Statistics. New York: Academic Press, 255-278.
Hall R. E. (1978). A stochastic life cycle model of aggregate consumption. Journal of Political Economy,, 971-987.
Hannan E. J. (1970). Multiple time series. New York: Wiley.
APPLIED ECONOMETRICS / ПРИКЛАДНАЯ ЭКОНОМЕТРИКА_| 2015, 39 (3)
Hendry D. F., von Ungern-Sternberg T. (1981). Liquidity and inflation effects on consumer’s expendi- a
ture. In: Essays in the Theory and Measurement of Consumer’s Behavior, ed. by A. S. Deaton. Cambridge: ||
Cambridge University Press. | Johansen S. (1985). The mathematical structure of error correction models. Manuscript, University
of Monetary Economics, 10, 139-162.
Pagan A. R. (1984). Econometric issues in the analysis of regressions with generated regressor. International Economic Review, 25, 221-248.
£
of Copenhagen. ^
Nelson C. R., Plosser C. (1982). Trends and random walks in macroeconomic time series. Journal ^
!
é
h-&
Phillips A. W. (1957). Stabilization policy and the time forms of lagged responses. Economic Journal, 67, 265-277. 01
Phillips P. C. B. (1985). Time series regression with unit roots. Cowles Foundation Discussion Paper 740, Yale University.
Phillips P. C. B., Durlauf S. N. (1985). Multiple time series regression with integrated processes. Cowles Foundation Discussion Paper 768.
Salmon M. (1982). Error correction mechanisms. The Economic Journal, 92, 615-629. Sargan J. D. (1964). Wages and prices in the United Kingdom: A study in econometric methodology. In: Econometric Analysis for National Economic Planning, ed. by P. E. Hart, G. Mills, and J. N. Whittaker. London: Butterworths.
Sargan J. D., Bhargava A. (1983). Testing residuals from least squares regression for being generated by the Gaussian random walk. Econometrica, 51, 153-174.
Shiller R. J., Campbell J. Y. (1984). A simple account of the behaviour of long-term interest rates. American Economic Review, 74, 44-48.
Stock J. H. (1984). Asymptotic properties of least squares estimators of co-integrating vectors. Manuscript, Harvard University.
Watson M. W., Engle R. F. (1985). A test for regression coefficient stability with a stationary AR(1) alternative. Forthcoming in Review of Economics and Statistics.
Yoo S. (1985). Multi-co-integrated time series and generalized error correction models. Manuscript in preparation, U.C.S.D.