Данная статья рассказывает о мониторинге журналов Windows через Zabbix и служит опорой в виде практических примеров, реализованных мной ранее. Важным моментом здесь является не столько сбор данных самого журнала, сколько правильная настройка триггера.

Шаблон или прототип элемента мониторинга будет выглядеть следующим образом (параметры для удобства пронумерованы):
eventlog[1- имя журнала,2-регулярное выражение,3-важность,4-источник,5-eventid,6-макс кол-во строк, 7-режим]
Тип данных: журнал (лог)

Далее рассмотрим конкретные практические примеры.
1. Ошибки в журнале приложений.
Максимально простой пример сбора ошибок в журнале «Приложение» (события уровня «Ошибка»)
eventlog[Application,,"Error",,,,skip]
2. Ошибки отложенной записи.
eventlog[System,,"Warning",,50,,skip]
краткие пояснения:
System — журнал система
Warning — тип события: предупреждение
50 — id события равно 50
skip — берем только свежие значения (не перечитываем весь лог)
триггер:
count(/Terminal server/eventlog[System,,"Warning",,50,,skip],30m)>7 and nodata(/Terminal server/eventlog[System,,"Warning",,50,,skip],60m)<>1
где Terminal server — это просто имя шаблона, в котором используются элемент данных и триггер
3. Ошибки диска.
eventlog[System,,"Warning",,153,,skip]
триггер:
count(/Template OS Windows by Zabbix agent active/eventlog[System,,"Warning",,153,,skip],30m)>5 and nodata(/Template OS Windows by Zabbix agent active/eventlog[System,,"Warning",,153,,skip],60m)<>1
4. ошибки в журнале событий от службы MSSQLSERVER.
eventlog[Application,,"Error","MSSQLSERVER",,,skip]
триггер:
count(/Template OS Windows SQL for 1C/eventlog[Application,,"Error","MSSQLSERVER",,,skip],8m)>0 and nodata(/Template OS Windows SQL for 1C/eventlog[Application,,"Error","MSSQLSERVER",,,skip],10m)<>1
Полезные ссылки:
https://www.zabbix.com/documentation/5.0/ru/manual/config/items/itemtypes/zabbix_agent/win_keys
![]() The Windows Zabbix Agent provides a native interface to the Windows Performance Counters. and Event Log. This means that with minimal overhead, and no additional shells out to Powerscript or the command line, you can collect any of the metrics available from PerfMon or Event Viewer.
The Windows Zabbix Agent provides a native interface to the Windows Performance Counters. and Event Log. This means that with minimal overhead, and no additional shells out to Powerscript or the command line, you can collect any of the metrics available from PerfMon or Event Viewer.
Windows Event Log
To monitor the Windows Event log, use the eventlog[] item keys. This takes the syntax:
eventlog[name,<regexp>,<severity>,<source>,<eventid>,<maxlines>,<mode>]
I would always recommend using Event Viewer on the host to determine which event log names and exact codes you want to pull before trying to craft the query parameters.
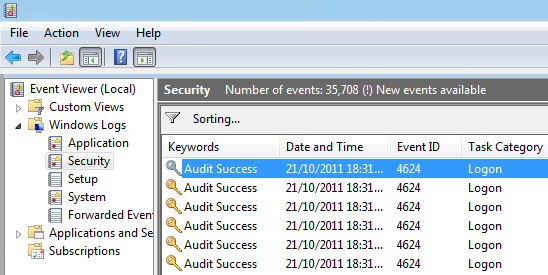
As an example, let’s capture all the interactive login events happening on the host which are logged in the “Security” event log. On a host that has a Zabbix Agent on Windows, create an item with the type “Zabbix agent (active)”:
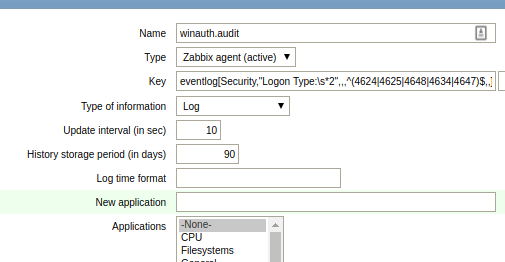
Name: winauth.audit Type: Zabbix agent (active) Key: eventlog[Security,"Logon Type:s*2",,,^(4624|4625|4648|4634|4647)$,,] Type of information: Log Update interval: 30
These 46xx codes are documented by Microsoft, and the logon type=2 signifies interactive logon.
Now going to Monitoring > Latest data after an interactive login should show you the event log entry within 30 seconds. This will show both successful as well as login failures.
Windows Performance Counters
The PerfMon tool comes standard on Windows hosts and can be used to capture and display live metrics as they are collected by the system.
Collecting these same metrics using the Zabbix agent can be done using the perf_counter key. The syntax is:
perf_counter[counter,<interval>]
The easiest way to discover the full path to these counters is to use PerfMon to first find and examine the keys. But you can also list all the full paths from the command line using “typeperf -qx”.
In this example, I’m going to monitor the keys for:
- Microsoft IIS total GET and PUSH operations
- Microsoft FTP Server total files sent and received
- Microsoft SMTP server total mail received, delivered, and pending
Which are represented as the Zabbix key values below:
perf_counter["Web Service(_Total)Total Get Requests",30] perf_counter["Web Service(_Total)Total Post Requests",30] perf_counter["Microsoft FTP Service(_Total)Total Files Sent",30] perf_counter["Microsoft FTP Service(_Total)Total Files Received",30] perf_counter["SMTP Server(_Total)Remote Queue Length",30] perf_counter["SMTP Server(_Total)Messages Received Total",30] perf_counter["SMTP Server(_Total)Messages Delivered Total",30]
This looks like the following when viewed in the Latest Data:
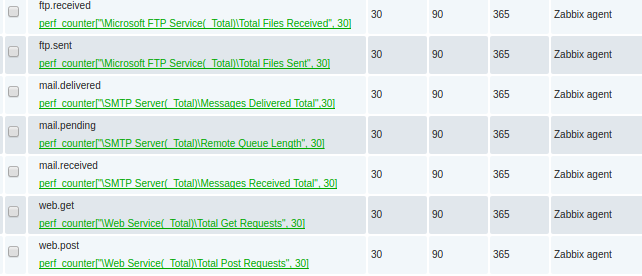
Each of these items created should be type=numeric(float) with an interval every 60 seconds.
REFERENCES
https://zabbix.org/wiki/Get_Zabbix
https://msdn.microsoft.com/en-us/library/ms804624.aspx (Web Service Object)
https://www.zabbix.com/documentation/3.0/manual/appendix/config/zabbix_agentd_win (agent conf, PerfCounter is sythesized avg value of sys perf meaning it needs float)
https://www.zabbix.com/documentation/2.4/manual/appendix/config/zabbix_agentd_win?s[]=perfcounter
https://www.zabbix.com/documentation/3.2/manual/config/items/itemtypes/zabbix_agent/win_keys (special item keys for Zabbix Windows agents)
https://blogs.technet.microsoft.com/brad_rutkowski/2007/09/22/using-typeperf-to-get-performance-data-on-the-command-prompt/
https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2008-R2-and-2008/dd941621(v%3dws.10) (4634 4646 audit logoff)
https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2008-R2-and-2008/dd941635(v%3dws.10) (4624,4625,4648 audit logon)
https://social.microsoft.com/Forums/en-US/712230b0-2d99-4cda-a374-1211117bf2a8/create-a-custom-security-log-event?forum=Offtopic (cannot write to security log, permissions)
NOTES
$ svn co svn://svn.zabbix.com/branches/2.4 (checkout source code)
eventcreate /l System /t INFORMATION /id 99 /d “just a test” (ids < 1000)
Write–EventLog –LogName Application –EntryType Error –Source MSSQLSERVER –EventId 1479 –Message “Test error event – ignore” (cannot write to SECURITY due to permissions)
Monitoring postfix queue on linux:
EnableRemoteCommands=1
UserParameter=mail.pending[*],/usr/sbin/postqueue -p | egrep -c “^[0-9A-F]{10}[^*]”
UserParameter=mail.active[*],/usr/sbin/postqueue -p | egrep -c “^[0-9A-F]{10}[*]”
typeperf -qx
typeperf -qx “SMTP Server”
typeperf -qx “Web Service”
typeperf -qx “Microsoft FTP Server” (“FTP Service” on older IIS6)
И есть ли в этом смысл?

Для тех, кто задумался и сомневается, я решил описать кое-что из своего опыта.
Мониторинг вообще штука полезная, бесспорно. У меня лично в какой-то период возникло сразу несколько задач:
-
Круглосуточно и непрерывно мониторить одну специфическую железку по ряду параметров;
-
Мониторить у рабочих станций информацию о температурах, ЦП в первую очередь;
-
Всякие мелочи в связи с широким внедрением удалёнки: количество подключений по VPN, общее состояние дополнительных виртуальных машин.
Подробнее про локальные задачи:
-
Надо было оценить и наглядно представить данные об интернет-канале. Канал на тот момент представлял собой 4G-роутер Huawei. Это устройство было последним, но далеко не первым в огромном количестве плясок с бубном в попытках избавиться от разного рода нестабильностей. Забегая вперёд: забирать с него данные напрямую о качестве сигнала более-менее стандартными средствами оказалось невозможно, и даже добраться до этих данных — отдельный квест. Пришлось городить дендрофекальную конструкцию, которая, на удивление стабильно, и стала в итоге поставлять данные. Данные в динамике и в графическом представлении оказались настолько неутешительными, что позволили убедить всех причастных таки поменять канал, даже и на более дорогой;
-
Данные о температуре процессора дают сразу несколько линий: можно обнаружить шифровальщик в процессе работы, наглядно сделать вывод о недостаточной мощности рабочей станции, найти повод провести плановую чистку, узнать о нарушении условий эксплуатации. Последний пункт особенно хорош: множество отказов оборудования и BSOD’ов в итоге нашли причину в «я ставлю обогреватель под стол, ну и свой баул, ну да, прям к этой решётке. А что? А я канпуктер развернула, а то неудобно»;
-
Интерфейс того же OpenVPN… ну, он в общем даже и не интерфейс и оставляет желать любого другого. Отдельная история.
Как большой любитель велосипедить всё подряд, сначала я решил свелосипедить и это. Уже валялись под рукой всякие скрипты по сбору статистки, и html проекты с графиками на js, и какие-то тестовые БД… Но тут сработала жадность (и лень, чоужтам). А чего это, подумал я, самому опять корячиться, если в том же Zabbix уже куча всяких шаблонов, и помимо задач из списка можно будет видеть много чего ещё? Да и он бесплатный к тому же. Всего-то делов, виртуалку поднять да клиенты централизованно расставить. Потренируюсь с ним, опять же, он много где используется.
Итак, нам понадобятся:
-
Виртуальная машина или физический хост. Zabbix нетребователен к ресурсам при небольшом количестве хостов на мониторинге: мне хватило одного виртуального процессора на 2ГГц и 4 Гб RAM за глаза;
-
Любой инструмент для автоматического раскидывания zabbix-agent. При некотором скилле это можно делать даже через оригинальный WSUS, или просто батником с psexec, вариантов много. Также желательно запилить предварительно сконфигурированный инсталлятор агента — об этом ниже;
-
Много желания пилить напильником. Скажу честно и сразу: из первоначального списка 3 из 3 реализовывалось руками на местности. Zabbix стандартной комплектации в такое не может.
У Zabbix много вариантов установки. В моём случае (я начинал с 4 LTS) сработала только установка руками в чистую, из собственного образа, OC в виртуальной машине на Hyper-V. Так что, коли не получится с первого раза, — не сдавайтесь, пробуйте. Саму процедуру подробнее описывать не буду, есть куча статей и хороший официальный мануал.

Про формирование инсталлятора агента: один из самых простых способов — использовать утилиты наподобие 7zfx Builder . Нужно будет подготовить:
-
файл zabbix_agentd.conf ;
-
файлы сторонних приложений и скриптов, используемых в userParameters (об этом ниже) ;
-
скрипт инсталлятора с кодом наподобие этого:
SETLOCAL ENABLEDELAYEDEXPANSION
SET INSTDR=C:ZabbixAgent
SET IP=192.168.100.10
set ip_address_string="IPv4-адрес"
for /f "usebackq tokens=2 delims=:" %%F in (ipconfig ^| findstr /c:%ip_address_string%) do SET IP=%%F
SET IP=%IP: =%
ECHO SourceIP=%IP%>> "%INSTDR%confzabbix_agentd.conf"
ECHO ListenIP=%IP%>> "%INSTDR%confzabbix_agentd.conf"
ECHO Hostname=%COMPUTERNAME%>> "%INSTDR%confzabbix_agentd.conf"
"%INSTDR%binzabbix_agentd.exe" -c "%INSTDR%confzabbix_agentd.conf" -i
net start "Zabbix Agent"
ENDLOCALКстати, об IP. Адрес в Zabbix является уникальным идентификатором, так что при «свободном» DHCP нужно будет настроить привязки. Впрочем, это и так хорошая практика.
Также могу порекомендовать добавить в инсталлятор следующий код:
sc failure "Zabbix Agent" reset= 30 actions= restart/60000Как и многие сервисы, Zabbix agent под Windows при загрузке ОС стартует раньше, чем некоторые сетевые адаптеры. Из-за этого агент не может увидеть IP, к которому должен быть привязан, и останавливает службу. В оригинальном дистрибутиве при установке настроек перезапуска нет.
После этого добавляем хосты. Не забудьте выбрать Template – OS Windows. Если сервер не видит клиента — проверяем:
-
IP-адрес;
-
файрвол на клиенте;
-
работу службы на клиенте — смотрим zabbix_agentd.log, он вполне информативный.
По моему опыту, сервер и агенты Zabbix очень стабильны. На сервере, возможно, придётся расширить пул памяти по active checks (уведомление о необходимости такого действия появляется в дашборде), на клиентах донастроить упомянутые выше нюансы с запуском службы, а также, при наличии UserParameters, донастроить параметр timeout (пример будет ниже).
Что видно сразу, без настроек?
Сразу видно, что Zabbix заточен под другое Но и об обычных рабочих станциях в конфигурации «из коробки» можно узнать много: идёт мониторинг оперативной памяти и SWAP, места на жёстких дисках, загрузки ЦП и сетевых адаптеров; будут предупреждения о том, что клиент давно не подключался или недавно перезагружен; агент автоматически создаёт список служб и параметров их работы, и сгенерирует оповещение о «необычном» поведении. Практически из коробки (со скачиванием доп. template’ов с офсайта и небольшой донастройкой) работает всё, что по SNMP: принтеры и МФУ, управляемые свитчи, всякая специфическая мелочь. Иметь алерты по тем же офисным принтерам в едином окне очень удобно.
В общем-то, очень неплохо, но…
Что доделывать?
Оооо. Ну, хотел повелосипедить, так это всегда пожалуйста. Прежде всего, нет алертов на события типа «критические» из системного лога Windows, при том, что механизм доступа к логам Windows встроенный, а не внешний, как Zabbix agent active. Странно, ну штош. Всё придётся добавлять руками.
Например
для записи и оповещения по событию «Система перезагрузилась, завершив работу с ошибками» (Microsoft-Windows-Kernel-Power, коды 41, 1001) нужно создать Item c типом Zabbix agent (active) и кодом в поле Key:
eventlog[System,,,,1001]По этому же принципу создаём оповещения на другие коды. Странно, но готового template я не нашёл.
Cистема автоматизированной генерации по службам генерирует целую тучу спама. Часть служб в Windows предполагает в качестве нормального поведения тип запуска «авто» и остановку впоследствии. Zabbix в такое не может и будет с упорством пьяного сообщать «а BITS-то остановился!». Есть широко рекомендуемый способ избавления от такого поведения — добавление набора служб в фильтр-лист: нужно добавить в Template «Module Windows services by Zabbix agent», в разделе Macros, в фильтре {$SERVICE.NAME.NOT_MATCHES} имя службы в формате RegExp. Получается список наподобие:
^RemoteRegistry|MMCSS|gupdate|SysmonLog|
clr_optimization_v.+|clr_optimization_v.+|
sppsvc|gpsvc|Pml Driver HPZ12|Net Driver HPZ12|
MapsBroker|IntelAudioService|Intel(R) TPM Provisioning Service|
dbupdate|DoSvc|BITS.*|ShellHWDetection.*$И он не работает работает с задержкой в 30 дней.

Про службы, автоматически генерируемые в Windows 10, я вообще промолчу.
Нет никаких температур (но это, если подумать, ладно уж), нет SMART и его алертов (тоже отдельная история, конечно). Нет моих любимых UPS.
Некоторые устройства генерируют данные и алерты, работу с которыми надо выстраивать. В частности, например, управляемый свитч Tp-Link генерирует интересный алерт «скорость на порту понизилась». Почти всегда это означает, что рабочая станция просто выключена в штатном режиме (ушла в S3), но сама постановка вопроса заставляет задуматься: сведения, вообще, полезные — м.б. и драйвер глючит, железо дохнет, время странное…
Некоторые встроенные алерты требуют переработки и перенастройки. Часть из них не закрывается в «ручном» режиме по принципу «знаю, не ори, так надо» и создаёт нагромождение информации на дашборде.
Короче говоря, многое требует допиливания напильником под местные реалии и задачи.

О локальных задачах
Всё, что не встроено в Zabbix agent, реализуется через механизм Zabbix agent (active). Суть проста: пишем скрипт, который будет выдавать нужные нам данные. Прописываем наш скрипт в conf:
UserParameter=имя.параметра,путькскрипту Нюансы:
-
если хотите получать в Zabbix строку на кириллице из cmd — не надо. Только powershell;
-
если параметр специфический – для имени нужно будет придумать и сформулировать дерево параметров, наподобие «hardware.huawei.modem.link.speed» ;
-
отладка и стабильность таких параметров — вопрос и скрипта, и самого Zabbix. Об этом дальше.
Хотелка №1: температуры процессоров рабочих станций
В качестве примера реализуем хотелку «темература ЦП рабочей станции». Вам может встретиться вариант наподобие:
wmic /namespace:rootwmi PATH MSAcpi_ThermalZoneTemperature get CurrentTemperatureно это не работает (вернее, работает не всегда и не везде).
Самый простой способ, что я нашёл — воспользоваться проектом OpenHardwareMonitor. Он свои результаты выгружает прямо в тот же WMI, так что температуру получим так:
@echo OFF
SETLOCAL ENABLEDELAYEDEXPANSION
SET TMPTMP=0
for /f "tokens=* skip=1 delims=" %%I in ('wmic /namespace:rootOpenHardwareMonitor PATH Sensor WHERE Identifier^="/intelcpu/0/temperature/1" get Value') DO (
SET TMPTMP=%%I && GOTO :NXT
)
:NXT
ECHO %TMPTMP%
ENDLOCAL
GOTO :EOFКонечно, при условии, что OHM запущен. В текущем релизе OHM не умеет работать в качестве Windows service. Так что придётся либо смущать пользователей очередной иконкой в трее, либо снова городить свой инсталлятор и запихивать OHM в сервисы принудительно. Я выбрал поcледнее, создав инсталляционный cmd для всё того же 7zfx Builder наподобие:
nssm install OHMservice "%programfiles%OHMOpenHardwareMonitor.exe"
timeout 3
net start "OHMservice"
del nssm.exe /QДва момента:
-
NSSM — простая и достаточно надёжная утилита с многолетней историей. Применяется как раз в случаях, когда ПО не имеет режима работы «сервис», а надо. Во вредоносности утилита не замечена;
-
Обратите внимание на «intelcpu» в скрипте получения температуры от OHM. Т.к. речь идёт о внедрении в малом офисе, можно рассчитывать на единообразие парка техники. Более того, таким образом лично у меня получилось извлечь и температуру ЦП от AMD. Но тем не менее этот пункт требует особого внимания. Возможно, придётся модифицировать и усложнять инсталлятор для большей универсальности.
Работает более чем надёжно, проблем не замечено.
Хотелка № 2: получаем и мониторим температуру чего угодно
Понадобятся нам две вещи:
-
Штука от братского китайского народа: стандартный цифровой термометр DS18B20, совмещённый с USB-UART контроллером. Стоит не сказать что бюджетно, но приемлемо;
-
powershell cкрипт:
param($cPort='COM3')
$port= new-Object System.IO.Ports.SerialPort $cPort,9600,None,8,one
$port.Open()
$tmp = $port.ReadLine()
$port.Close()
$tmp = $tmp -replace "t1="
if (([int]$tmp -lt 1) -or ([int]$tmp -gt 55)){
#echo ("trigg "+$tmp)
$port.Open()
$tmp = $port.ReadLine()
$port.Close()
$tmp = $tmp -replace "t1="
}
echo ($tmp)Связка работает достаточно надёжно, но есть интересный момент: иногда, бессистемно, появляются провалы или пики на графиках:
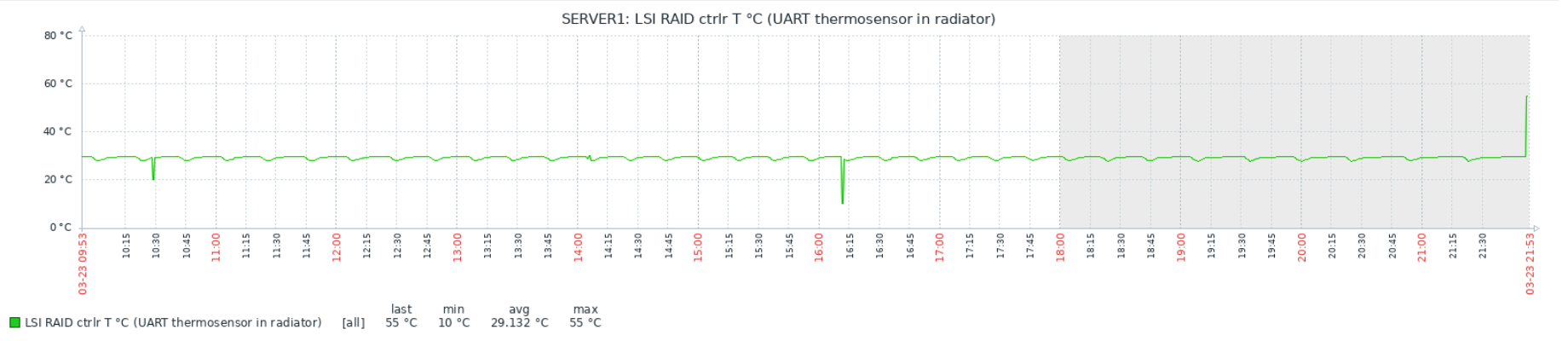
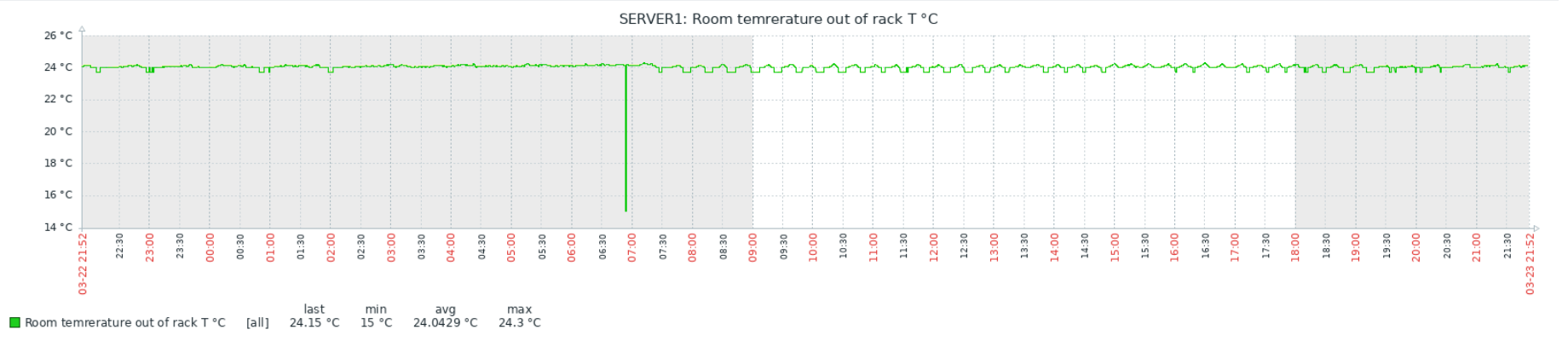
Тесты показали, что проблема в самом Zabbix, а данные с китайских датчиков приходят верные. Детальное рассмотрение пиков и провалов выявило неожиданный факт: похоже Zabbix иногда получает и/или записывает в БД не полное значение, а «хвост». Т.е., например, 1.50 от значения 21.50. При этом положение точки не важно — может получить и 1.50, и 50, и даже 0. Как так происходит, мне выяснить пока не удалось. Изменение timeout на поведение не влияет никак, ни в большую, ни в меньшую сторону.
Наверное, стоило бы написать багрепорт. Но уже вышел 6.0 LTS (у меня 5) и обновляться в текущей ситуации, пожалуй, не буду.
Хотелка № 3: OpenVPN подключения
Template’ов для OpenVPN и Zabbix существует довольно много, но все они реализованы на том или ином sh под *nix’ы . В свою очередь, «dashboard» OpenVPN-сервера представляет из себя, по сути, вывод утилиты в консоль, который пишется в файл по событиям. Мне лень было считать трафик по отдельным пользователям и вообще делать их discover, т.к. подключений и пользователей немного. Ограничился текущим количеством подключений:
$openvpnLogPath = "C:OpenVPNconfig"
$openvpnLogName = "openvpn-status.log"
try {
$logData = Get-Content $openvpnLogPath$openvpnLogName -ErrorAction Stop
}
catch{
Write-Host("Missing log file")
exit 1
}
$logHeader = "OpenVPN CLIENT LIST"
$logHeader2 = "Common Name,Real Address,Bytes Received,Bytes Sent,Connected Since"
$logMark1 = "ROUTING TABLE"
if ($logData[0] -ne $logHeader -or $logData[2] -ne $logHeader2 ){
Write-Host("Bad log file")
exit 1
}
$i = 0
foreach ($tmpStr in ($logData | select -skip 3)) {
if ($tmpStr -eq $logMark1) {break}
$i++
}
Write-Host($i)
exit 0Хотелка № 4: спецжелезка 1
Для большого количества специфического оборудования существуют написанные энтузиастами Template’ы. Обычно они используют и реализуют функционал, уже имеющийся в утилитах к этим железкам.
Боли лирическое отступление
установив один из таких темплейтов, я узнал, что «нормальная рабочая» температура чипа RAID-контроллера в серваке — 65+ градусов. Это, в свою очередь, побудило внимательнее посмотреть и на контроллер, и на сервер в целом. Были найдены косяки и выражены «фи»:
-
Apaptec’у – за игольчатый радиатор из неизвестного крашеного силумина высотой чуть более чем нихрена, поток воздуха к которому закрыт резервной батарейкой с высотой больше, чем радиатор. Особенно мне понравилось потом читать у Adaptec того же «ну, это его нормальная рабочая температура. Не волнуйтесь». Ответственно заявляю: при такой «нормальной рабочей температуре» контроллер безбожно и непредсказуемо-предсказуемо глючил;
-
Одному отечественному сборщику серверов. «Берём толстый жгут проводов. Скрепляем его, чтобы он был толстым, плотным, надёжным. Вешаем это прямо перед забором воздуха вентиляторами продува серверного корпуса. Идеально!». На «полу» сервера было дофига места, длины кабелей тоже хватало, но сделали почему-то так.
Также был замечен интересный нюанс поведения, связанный с Zabbix. Со старым RAID контроллером при наличии в системном логе специфичных репортов, отваливался мониторинг температуры контроллера в Zabbix, но! при запуске руками в консоли скрипта или спец. утилиты температура выводилась корректно и без задержек.
Но полный функционал реализован далеко не всегда. В частности, мне понадобились температуры жёстких дисков с нового RAID-контроллера (ну люблю я температуры, что поделать ), которых в оригинальном темплейте не было. Пришлось самому реализовывать температуры и заодно autodiscover физических дисков: https://github.com/automatize-it/zabbix-lsi-raid/commit/1d3a8b3a0e289b8c2df637028475177a2b940689

Оригинальный репозиторий, вероятно, заброшен, как это довольно часто бывает.
Хотелка № 5, на десерт: спецжелезка 2
Как и обещал, делюсь опытом вырывания данных из беспроводной железки Huawei. Речь о 4G роутере серии B*. Внутри себя железка имеет ПО на ASP, а данные о качестве сигнала — RSSI, SINR и прочее — в пользовательском пространстве показывать не хочет совсем. Смотри, мол, картинку с уровнем сигнала и всё, остальное не твоего юзерского ума дело. К счастью, в ПО остались какие-то хвосты, выводящие нужное в plain JSON. К сожалению, взять да скачать это wget-ом не получается никак: мало того, что авторизация, так ещё и перед генерацией plain json требуется исполнение JS на клиенте. К счастью, существует проект phantomjs. Кроме того, нам понадобится перенесённая руками кука из браузера, где мы единожды авторизовались в веб-интерфейсе, вручную. Кука живёт около полугода, можно было и скрипт написать, но я поленился.
Алгоритм действий и примеры кода:
вызываем phantomjs с кукой и сценарием:
phantomjs.exe --cookies-file=cookie.txt C:cmdyota_signalscenery.jsПримеры сценариев:
//получаем общий уровень сигнала
var url = "http://192.168.2.1/html/home.html";
var page = require('webpage').create();
page.open(url, function(status) {
//console.log("Status: " + status);
if(status === "success") {
var sgnl = page.evaluate(function() {
return document.getElementById("status_img").innerHTML; //
});
var stt = page.evaluate(function() {
return document.getElementById("index_connection_status").innerText; //
});
var sttlclzd = "dis";
var sgnlfnd = "NA";
if (stt.indexOf("Подключено") != -1) {sttlclzd = "conn";}
if (sgnl.indexOf("icon_signal_01") != -1) {sgnlfnd = "1";}
else {
var tmpndx = sgnl.indexOf("icon_signal_0");
sgnlfnd = sgnl.substring(tmpndx+13,tmpndx+14);
}
console.log(sttlclzd+","+sgnlfnd);
var fs = require('fs');
try {
fs.write("C:cmdsiglvl.txt", sgnlfnd, 'w');
} catch(e) {
console.log(e);
}
}
phantom.exit();
});
//получаем технические параметры сигнала через какбэ предназначенный для этого "API"
var url = "http://192.168.2.1/api/device/signal";
var page = require('webpage').create();
page.onLoadFinished = function() {
//console.log("page load finished");
//page.render('export.png');
console.log(page.content);
parser = new DOMParser();
xmlDoc = parser.parseFromString(page.content,"text/xml");
var rsrq = xmlDoc.getElementsByTagName("rsrq")[0].childNodes[0].nodeValue.replace("dB","");
var rsrp = xmlDoc.getElementsByTagName("rsrp")[0].childNodes[0].nodeValue.replace("dBm","");
var rssi = xmlDoc.getElementsByTagName("rssi")[0].childNodes[0].nodeValue.replace("dBm","").replace(">=","");
var sinr = xmlDoc.getElementsByTagName("sinr")[0].childNodes[0].nodeValue.replace("dB","");
var fs = require('fs');
try {
fs.write("C:cmdrsrq.txt", rsrq, 'w');
fs.write("C:cmdrsrp.txt", rsrp, 'w');
fs.write("C:cmdrssi.txt", rssi, 'w');
fs.write("C:cmdsinr.txt", sinr, 'w');
} catch(e) {
console.log(e);
}
phantom.exit();
};
page.open(url, function() {
page.evaluate(function() {
});
});
Конструкция запускается из планировщика задач. В Zabbix-агенте производится лишь чтение соответствующих файлов:
UserParameter=internet.devices.huawei1.signal.level,type C:cmdsiglvl.txt 
Требует постоянного присмотра, ручных прибиваний и перезапусков процессов, обновления кук. Но для такого шаткого нагромождения фекалий и палок работает достаточно стабильно.
Итого
Стоит ли заморачиваться на Zabbix, если у вас 20 машин и 1-2 сервера, да ещё и инфраструктура Windows?
Как можно понять из вышеизложенного, работы будет много. Я даже рискну предположить, что объёмы работ и уровень квалификации для них сравнимы с решением «свелосипедить своё с нуля по-быстрому на коленке».
Не стоит рассматривать Zabbix как панацею или серебряную пулю.
Тем не менее, использование уже готового и популярного продукта имеет свои преимущества — в первую очередь, это релевантный опыт для интересных работодателей.
А красивые графики дают усладу глазам и часто — новое видение процессов в динамике.
Если захочется внедрить, то могу пообещать, как минимум — скучно не будет!
Время на прочтение
9 мин
Количество просмотров 162K

Некоторое время поработав с Zabbix, я подумал, почему бы не попробовать использовать его в качестве решения для мониторинга событий информационной безопасности. Как известно, в ИТ инфраструктуре предприятия множество самых разных систем, генерирующих такой поток событий информационной безопасности, что просмотреть их все просто невозможно. Сейчас в нашей корпоративной системе мониторинга сотни сервисов, которые мы наблюдаем с большой степенью детализации. В данной статье, я рассматриваю особенности использования Zabbix в качестве решения по мониторингу событий ИБ.
Что же позволяет Zabbix для решения нашей задачи? Примерно следующее:
- Максимальная автоматизация процессов инвентаризации ресурсов, управления уязвимостями, контроля соответствия политикам безопасности и изменений.
- Постоянная защита корпоративных ресурсов с помощью автоматического мониторинга информационной безопасности.
- Возможность получать максимально достоверную картину защищенности сети.
- Анализ широкого спектра сложных систем: сетевое оборудование, такое как Cisco, Juniper, платформы Windows, Linux, Unix, СУБД MSQL, Oracle, MySQL и т.д., сетевые приложения и веб-службы.
- Минимизация затрат на аудит и контроль защищенности.
В статье я не буду рассматривать всё выше перечисленное, затронем только наиболее распространённые и простые вопросы.
Подготовка
Итак, для начала я установил сервер мониторинга Zabbix. В качестве платформы мы будем использовать ОС FreeBSD. Думаю, что рассказывать в деталях о процессе установки и настройки нет необходимости, довольно подробная документация на русском языке есть на сайте разработчика, начиная от процесса установки до описания всех возможностей системы.
Мы будем считать что сервер установлен, настроен, а так же настроен web-frontend для работы с ним. На момент написания статьи система работает под управлением ОС FreeBSD 9.1, Zabbix 2.2.1.
Мониторинг событий безопасности MS Windows Server
С помощью системы мониторинга Zabbix можно собирать любую имеющуюся информацию из системных журналов Windows с произвольной степенью детализации. Это означает, что если Windows записывает какое-либо событие в журнал, Zabbix «видит» его, например по Event ID, текстовой, либо бинарной маске. Кроме того, используя Zabbix, мы можем видеть и собирать колоссальное количество интересных для мониторинга безопасности событий, например: запущенные процессы, открытые соединения, загруженные в ядро драйверы, используемые dll, залогиненных через консоль или удалённый доступ пользователей и многое другое.
Всё, что остаётся – определить события возникающие при реализации ожидаемых нами угроз.
Устанавливая решение по мониторингу событий ИБ в ИТ инфраструктуре следует учитывать необходимость выбора баланса между желанием отслеживать всё подряд, и возможностями по обработке огромного количества информации по событиям ИБ. Здесь Zabbix открывает большие возможности для выбора. Ключевые модули Zabbix написаны на C/C++, скорость записи из сети и обработки отслеживаемых событий составляет 10 тысяч новых значений в секунду на более менее обычном сервере с правильно настроенной СУБД.
Всё это даёт нам возможность отслеживать наиболее важные события безопасности на наблюдаемом узле сети под управлением ОС Windows.
Итак, для начала рассмотрим таблицу с Event ID, которые, на мой взгляд, очевидно, можно использовать для мониторинга событий ИБ:
События ИБ MS Windows Server Security Log
Я уделяю внимание локальным группам безопасности, но в более сложных схемах AD необходимо учитывать так же общие и глобальные группы.
Дабы не дублировать информацию, подробнее о критически важных событиях можно почитать в статье:
http://habrahabr.ru/company/netwrix/blog/148501/
Способы мониторинга событий ИБ MS Windows Server
Рассмотрим практическое применение данной задачи.
Для сбора данных необходимо создать новый элемент данных:
Ключ: eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781]
Тип элемента данных: Zabbix агент (активный)
Тип информации: Журнал (лог)
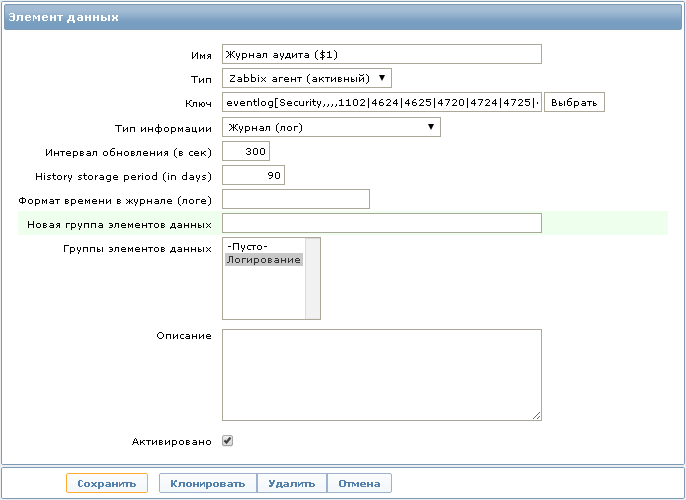
При желании для каждого Event ID можно создать по отдельному элементу данных, но я использую в одном ключе сразу несколько Event ID, чтобы хранить все полученные записи в одном месте, что позволяет быстрее производить поиск необходимой информации, не переключаясь между разными элементами данных.
Хочу заметить что в данном ключе в качестве имени мы используем журнал событий Security.
Теперь, когда элемент данных мы получили, следует настроить триггер. Триггер – это механизм Zabbix, позволяющий сигнализировать о том, что наступило какое-либо из отслеживаемых событий. В нашем случае – это событие из журнала сервера или рабочей станции MS Windows.
Теперь все что будет фиксировать журнал аудита с указанными Event ID будет передано на сервер мониторинга. Указание конкретных Event ID полезно тем, что мы получаем только необходимую информацию, и ничего лишнего.
Вот одно из выражений триггера:
{Template Windows - Eventlog 2008:eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781].logeventid(4624)}=1&{Template Windows - Eventlog 2008:eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781].nodata(5m)}=0

Данное выражение позволит отображать на Dashboard информацию о том что «Вход с учётной записью выполнен успешно», что соответствует Event ID 4624 для MS Windows Server 2008. Событие исчезнет спустя 5 минут, если в течение этого времени не был произведен повторный вход.
Если же необходимо отслеживать определенного пользователя, например “Администратор”, можно добавить к выражению триггера проверку по regexp:
&{Template Windows - Eventlog 2008:eventlog[Security,,,,1102|4624|4625|4720|4724|4725|4726|4731|4732|4733|4734|4735|4738|4781,,skip].regexp(Администратор)}=1
Тогда триггер сработает только в том случае если будет осуществлён вход в систему именно под учетной записью с именем “Администратор”.
P.S.
Мы рассматривали простейший пример, но так же можно использовать более сложные конструкции. Например с использованием типов входа в систему, кодов ошибок, регулярных выражений и других параметров.
Таким образом тонны сообщений, генерируемых системами Windows будет проверять Zabbix, а не наши глаза. Нам остаётся только смотреть на панель Zabbix Dashboard.
Дополнительно, у меня настроена отправка уведомлений на e-mail. Это позволяет оперативно реагировать на события, и не пропустить события произошедшие например в нерабочее время.
Мониторинг событий безопасности Unix систем
Система мониторинга Zabbix так же позволяет собирать информацию из лог-файлов ОС семейства Unix.
События ИБ в Unix системах, подходящие для всех
Такими проблемами безопасности систем семейства Unix являются всё те же попытки подбора паролей к учётным записям, а так же поиск уязвимостей в средствах аутентификации, например, таких как SSH, FTP и прочих.
Некоторые критически важные события в Unix системах
Исходя из вышеуказанного следует, что нам необходимо отслеживать действия, связанные с добавлением, изменением и удалением учётных записей пользователей в системе.
Так же немаловажным фактом будет отслеживание попыток входа в систему. Изменения ключевых файлов типа sudoers, passwd, etc/rc.conf, содержимое каталогов /usr/local/etc/rc.d наличие запущенных процессов и т.п.
Способы мониторинга ИБ в Unix системах
Рассмотрим следующий пример. Нужно отслеживать входы в систему, неудачные попытки входа, попытки подбора паролей в системе FreeBSD по протоколу SSH.
Вся информация об этом, содержится в лог-файле /var/log/auth.log.
По умолчанию права на данный файл — 600, и его можно просматривать только с привилегиями root. Придется немного пожертвовать локальной политикой безопасности, и разрешить читать данный файл группе пользователей zabbix:
Меняем права на файл:
chgrp zabbix /var/log/auth.log
chmod 640 /var/log/auth.log
Нам понадобится новый элемент данных со следующим ключом:
log[/var/log/auth.log,sshd,,,skip]
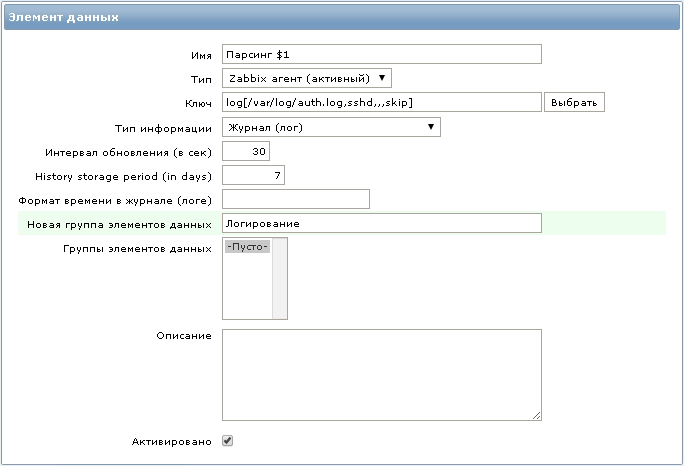
Все строки в файле /var/log/auth.log содержащие слово ”sshd” будут переданы агентом на сервер мониторинга.
Далее можно настроить триггер со следующим выражением:
{Template FreeBSD - SSH:log[/var/log/auth.log,sshd,,,skip].regexp(error:)}|{Template FreeBSD - SSH:log[/var/log/auth.log,sshd,,,skip].regexp(Wrong passwordr:)}&{Template FreeBSD - SSH:log[/var/log/auth.log,sshd,,,skip].nodata(3m)}=0
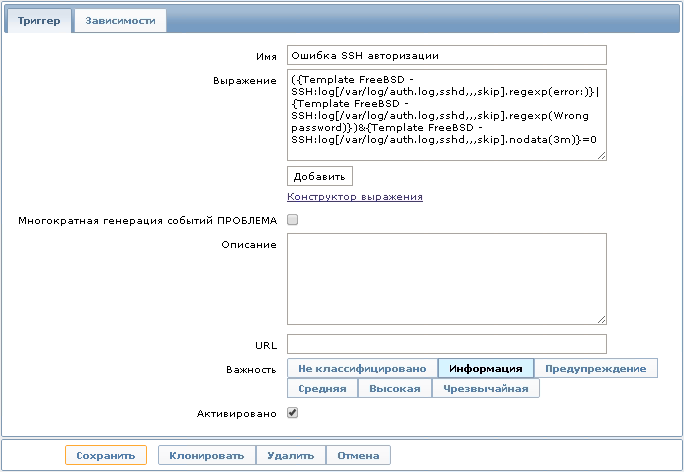
Это выражение определяется как проблема, когда в лог-файле появляются записи, отобранные по регулярному выражению “error:”. Открыв историю полученных данных, мы увидим ошибки, которые возникали при авторизации по протоколу SSH.
Вот пример последнего значения элемента данных, по которому срабатывает данный триггер:

Рассмотрим ещё один пример мониторинга безопасности в ОС FreeBSD:
С помощью агента Zabbix мы можем осуществлять проверку контрольной суммы файла /etc/passwd.
Ключ в данном случае будет следующий:
vfs.file.cksum[/etc/passwd]
Это позволяет контролировать изменения учётных записей, включая смену пароля, добавление или удаление пользователей. В данном случае мы не узнаем, какая конкретная операция была произведена, но если к серверу кроме Вас доступ никто не имеет, то это повод для быстрого реагирования. Если необходимо более детально вести политику то можно использовать другие ключи, например пользовательские параметры.
Например, если мы хотим получать список пользователей, которые на данный момент заведены в системе, можно использовать такой пользовательский параметр:
UserParameter=system.users.list, /bin/cat /etc/passwd | grep -v "#" | awk -F: '{print $$1}'
И, например, настроить триггер на изменение в получаемом списке.
Или же можно использовать такой простой параметр:
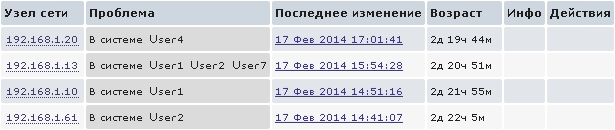
UserParameter=system.users.online, /usr/bin/users
Так мы увидим на Dashboard, кто на данный момент находится в системе:
Мониторинг событий ИБ на сетевых устройствах
С помощью Zabbix можно так же очень эффективно отслеживать события ИБ на сетевых устройствах Cisco и Juniper, используя протокол SNMP. Передача данных с устройств осуществляется с помощью так называемых трапов (SNMP Trap).
С точки зрения ИБ можно выделить следующие события, которые необходимо отслеживать — изменения конфигураций оборудования, выполнение команд на коммутаторе/маршрутизаторе, успешную авторизацию, неудачные попытки входа и многое другое.
Способы мониторинга
Рассмотрим опять же пример с авторизацией:
В качестве стенда я буду использовать эмулятор GNS3 с маршрутизатором Cisco 3745. Думаю многим знакома данная схема.
Для начала нам необходимо настроить отправку SNMP трапов с маршрутизатора на сервер мониторинга. В моём случае это будет выглядеть так:
login block-for 30 attempts 3 within 60
login on-failure log
login on-success log
login delay 5
logging history 5
snmp-server enable traps syslog
snmp-server enable traps snmp authentication
snmp-server host 192.168.1.1 public
Будем отправлять события из Syslog и трапы аутентификации. Замечу, что удачные и неудачные попытки авторизации пишутся именно в Syslog.
Далее необходимо настроить прием нужных нам SNMP трапов на сервере мониторинга.
Добавляем следующие строки в snmptt.conf:
EVENT clogMessageGenerated .1.3.6.1.4.1.9.9.41.2.0.1 "Status Events" Normal
FORMAT ZBXTRAP $ar $N $*
SDESC
EDESC
В нашем примере будем ловить трапы Syslog.
Теперь необходимо настроить элемент данных для сбора статистики со следующим ключом:
snmptrap[“Status”]
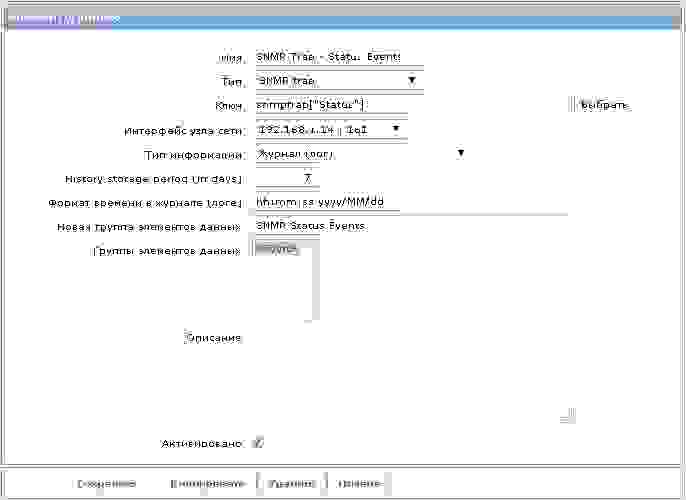
Если трап не настроен на сервере мониторинга, то в логе сервера будут примерно такие записи:
unmatched trap received from [192.168.1.14]:...
В результате в полученном логе будет отражаться информация о попытках входа с детализированной информацией (user, source, localport и reason в случае неудачи):

Ну и можно настроить триггер для отображения события на Dashboard:
{192.168.1.14:snmptrap["Status"].regexp(LOGIN_FAILED)}&{192.168.1.14:snmptrap["Status"].nodata(3m)}=0
В сочетании с предыдущим пунктом у нас на Dashboard будет информация вот такого плана:

Аналогично вышеописанному примеру можно осуществлять мониторинг большого количества событий, происходящих на маршрутизаторах Cisco, для описания которых одной статьей явно не обойтись.
Хочу заметить что приведённый пример не будет работать на продуктах Cisco ASA и PIX, так как там несколько иначе организована работа с логированием авторизации.
Juniper и Syslog
Ещё одним примером мы разберем мониторинг авторизации в JunOS 12.1 для устройств Juniper.
Тут мы не сможем воспользоваться трапами SNMP, потому как нет поддержки отправки трапов из Syslog сообщений. Нам понадобится Syslog сервер на базе Unix, в нашем случае им будет тот же сервер мониторинга.
На маршрутизаторе нам необходимо настроить отправку Syslog на сервер хранения:
system syslog host 192.168.1.1 authorization info
Теперь все сообщения об авторизации будут отправляться на Syslog сервер, можно конечно отправлять все сообщения (any any), но переизбыток информации нам не нужен, отправляем только необходимое.
Далее переходим к Syslog серверу
Смотрим tcpdump, приходят ли сообщения:
tcpdump -n -i em0 host 192.168.1.112 and port 514
12:22:27.437735 IP 192.168.1.112.514 > 192.168.1.1.514: SYSLOG auth.info, length: 106
По умолчанию в настройках syslog.conf все что приходит с auth.info должно записываться в /var/log/auth.log. Далее делаем все аналогично примеру с мониторингом входов в Unix.
Вот пример строки из лога:

Остается только настроить триггер на данное событие так же как это было рассмотрено в примере с авторизацией на Unix сервере.
P.S.
Таким способом можно отслеживать множество событий, среди которых такие как: сохранение конфигурации устройства (commit), вход и выход из режима редактирования конфигурации (edit).
Так же хочу заметить, что аналогичным способом можно осуществлять мониторинг и на устройствах Cisco, но способ с SNMP трапами мне кажется более быстрым и удобным, и исключается необходимость в промежуточном Syslog сервере.
Заключение
В заключении хочу отметить, что я с удовольствием приму замечания и дополнения к данной статье, а так же интересные предложения по использованию мониторинга событий информационной безопасности при помощи Zabbix.
Спасибо за внимание. 
Данная статья рассказывает о мониторинге журналов Windows через Zabbix и служит опорой в виде практических примеров, реализованных мной ранее. Важным моментом здесь является не столько сбор данных самого журнала, сколько правильная настройка триггера.
Шаблон или прототип элемента мониторинга будет выглядеть следующим образом (параметры для удобства пронумерованы):
eventlog[1- имя журнала,2-регулярное выражение,3-важность,4-источник,5-eventid,6-макс кол-во строк, 7-режим]
Тип данных: журнал (лог)
Далее рассмотрим конкретные практические примеры.
1. Ошибки в журнале приложений.
Максимально простой пример сбора ошибок в журнале «Приложение» (события уровня «Ошибка»)
eventlog[Application,,"Error",,,,skip]
2. Ошибки отложенной записи.
eventlog[System,,"Warning",,50,,skip]
краткие пояснения:
System — журнал система
Warning — тип события: предупреждение
50 — id события равно 50
skip — берем только свежие значения (не перечитываем весь лог)
триггер:
count(/Terminal server/eventlog[System,,"Warning",,50,,skip],30m)>7 and nodata(/Terminal server/eventlog[System,,"Warning",,50,,skip],60m)<>1
где Terminal server — это просто имя шаблона, в котором используются элемент данных и триггер
3. Ошибки диска.
eventlog[System,,"Warning",,153,,skip]
триггер:
count(/Template OS Windows by Zabbix agent active/eventlog[System,,"Warning",,153,,skip],30m)>5 and nodata(/Template OS Windows by Zabbix agent active/eventlog[System,,"Warning",,153,,skip],60m)<>1
4. ошибки в журнале событий от службы MSSQLSERVER.
eventlog[Application,,"Error","MSSQLSERVER",,,skip]
триггер:
count(/Template OS Windows SQL for 1C/eventlog[Application,,"Error","MSSQLSERVER",,,skip],8m)>0 and nodata(/Template OS Windows SQL for 1C/eventlog[Application,,"Error","MSSQLSERVER",,,skip],10m)<>1
Полезные ссылки:
https://www.zabbix.com/documentation/5.0/ru/manual/config/items/itemtypes/zabbix_agent/win_keys
Содержание
- Блог белорусского сисадмина
- полезные записки
- Мониторинг логов в Zabbix и возврат триггера в OK
- Zabbix Documentation 5.4
- Sidebar
- Table of Contents
- Специфичные ключи элементов данных для Windows
- Ключи элементов данных
- Мониторинг служб Windows
- Обнаружение служб Windows
- Мониторинг событий информационной безопасности с помощью ZABBIX
- Подготовка
- Мониторинг событий безопасности MS Windows Server
- Мониторинг событий безопасности Unix систем
- Мониторинг событий ИБ на сетевых устройствах
- Ещё раз о хранении логов в Zabbix
- Лирическое отступление
- За дело!
- Общая концепция
- Настройка EvtSys
- Настройка конвейера обработки сообщений
- Конфиг Heka
- Отладка обработки сообщений
- Zabbix Trapper
- Шаблон для Zabbix
- И что же в итоге?
Блог белорусского сисадмина
полезные записки
Мониторинг логов в Zabbix и возврат триггера в OK
Zabbix может многое. Главное — суметь это настроить 🙂 Одна из полезных возможностей — мониторинг лог-файлов на наличие определенных записей. Если вы хотите держать руку на пульсе событий при мониторинге серверов, то без мониторинга логов никак не обойтись: почти все серьезные ошибки пишутся в логи и во многих случаях гораздо эффективнее мониторить один-два лога, чем настраивать отслеживания статуса 50 сервисов, работоспособность которых не всегда легко проверить.
Собственно, в самой настройке мониторинга логов нет ничего сложного: добавляем соответствующий Item, пишем регулярное выражение для триггера и начинаем получать уведомления! Например, мы хотим отслеживать все ошибки из System лога на серверах под управлением OS Windows. Для этого, создаем следующий Item:
Параметры следующие: System — лог, который отслеживаем; второй параметр — регулярное выражение, которое ищем (пропущен, берем все записи); третий — «Error» — важность, согласно классификации ОС; четвертый — любой источник; пятый — @eventlog — макрос, который исключает события с идентификаторами ^(1111|36888|36887|36874)$; шестой — максимальное кол-во строк, которое мы отправляем серверу в секунду (неограниченное); последний параметр — skip — заставляет сервер читать только новые записи лога, а не перечитывать его весь.
В качестве триггера мы используем следующую строку:
Т.е. мы берем любую строку, которая попала в Item и высылаем уведомление.
После такой настройки мы получим первую ошибку из лога и триггер будет висеть в состоянии PROBLEM до скончания веков, т.к. нет события, которое его переводит в состояние OK. Для решения этой проблемы необходимо добавить к триггеру еще одно условие: наличие новых данных в течение промежутка времени, меньшего, чем время опроса Item. Т.е. если мы проверяем лог на ошибки раз в минуту, то нам надо поставить любой промежуток времени, меньший, чем минута. Итоговый триггер будет выглядеть как-то так:
Выглядеть это будет как «нашли что-то в Item» И «за последние 10 секунд были получены новые данные». При следующей проверке триггер перейдет в состояние OK, т.к. за последние 10 секунд новых данных получено не было. Других способов возврата триггера для лога в нормальное состояние в заббиксе версии 2 не предусмотрено.
Источник
Zabbix Documentation 5.4
Table of Contents
Специфичные ключи элементов данных для Windows
Ключи элементов данных
В таблице приводится подробная информация о ключах элементов данных, которые вы можете использовать только с Zabbix Windows агентом.
Обратите внимание, агент не может отправлять события из «Пересланные события» журнала.
Параметр режим поддерживается начиная с версии 2.0.0.
“Windows Eventing 6.0” поддерживается начиная с Zabbix 2.2.0.
Обратите внимание, что выбор не журнального типа информации для этого элемента данных приведет к потере локального штампа времени, а также важности журнала и информации о источнике.
Смотрите дополнительную информацию о мониторинге файлов журналов. net.if.list Список сетевых интерфейсов (включая тип, состояние, IPv4 адрес, описание интерфейса). Текст Поддерживается Zabbix агентом начиная с версии 1.8.1. Начиная с версии 1.8.6 Zabbix агента поддерживаются мультибайтные имена интерфейса. Отключенные интерфейсы не входят в список.
Обратите внимание, что включение/отключение некоторых компонентов Windows могут изменить порядок имён интерфейсов в Windows.
Обратите внимание, что для корректной работы этого элемента данных на 64-битной системе потребуется 64-битный Zabbix агент.
Элементы данных service.info[служба,state] and service.info[служба] вернут одинаковую информацию.
Обратите внимание, что только парам равный state у этого элемента данных возвращает значение по несуществующим службам (255).
Мониторинг статистики виртуальной памяти на основе:
Максимального количества памяти, которое может занять Zabbix агент.
Текущий предел выделенной памяти в системе или Zabbix агенте, смотря что меньше.
Этот ключ поддерживается начиная с Zabbix 3.0.7 и 3.2.3.
Мониторинг служб Windows
Это руководство содержит пошаговые инструкции по настройке мониторинга служб Windows. Предполагается, что Zabbix сервер и агент уже настроены и работают.
Шаг 1
Узнайте имя службы.
Вы можете получить имя, перейдя в оснастку MMC Службы и открыв свойства службы. На вкладке Общие вы должны увидеть поле называемое ‘Имя службы’. Значение которого и будет именем желаемой службы, которое вы будете использовать при настройке элемента данных для наблюдения.
Например, если вы хотите наблюдать службу “workstation”, то ваша служба скорее всего будет: lanmanworkstation.
Шаг 2
Элемент данных service.info[служба, ] возвращает информацию о указанной службе. В зависимости от требемой вам информации, укажите опцию парам, которая принимает следующие значения: displayname, state, path, user, startup или description. Значением по умолчанию является state, если парам не указан (service.info[служба]).
Тип возвращаемого значения зависит от выбранного парам: целое число при state и startup; строка символов при displayname, path и user; текст при description.
Имеется два преобразования значений Windows service state и Windows service startup type, которые сопоставляют числовое значение в веб-интерфейсе его текстовому представлению.
Обнаружение служб Windows
Низкоуровневое обнаружение дает возможность автоматического создания элементов данных, триггеров и графиков по различных объектам на компьютере. Zabbix может автоматически начать наблюдение за службами Windows на вашей машине, без необходимости знания точного имени службы или создания элементов данных по каждой службе вручную. Можно использовать фильтр для генерирования реальных элементов данных, триггеров и графиков только по интересующим службам.
Источник
Мониторинг событий информационной безопасности с помощью ZABBIX

Подготовка
Итак, для начала я установил сервер мониторинга Zabbix. В качестве платформы мы будем использовать ОС FreeBSD. Думаю, что рассказывать в деталях о процессе установки и настройки нет необходимости, довольно подробная документация на русском языке есть на сайте разработчика, начиная от процесса установки до описания всех возможностей системы.
Мы будем считать что сервер установлен, настроен, а так же настроен web-frontend для работы с ним. На момент написания статьи система работает под управлением ОС FreeBSD 9.1, Zabbix 2.2.1.
Мониторинг событий безопасности MS Windows Server
С помощью системы мониторинга Zabbix можно собирать любую имеющуюся информацию из системных журналов Windows с произвольной степенью детализации. Это означает, что если Windows записывает какое-либо событие в журнал, Zabbix «видит» его, например по Event ID, текстовой, либо бинарной маске. Кроме того, используя Zabbix, мы можем видеть и собирать колоссальное количество интересных для мониторинга безопасности событий, например: запущенные процессы, открытые соединения, загруженные в ядро драйверы, используемые dll, залогиненных через консоль или удалённый доступ пользователей и многое другое.
Всё, что остаётся – определить события возникающие при реализации ожидаемых нами угроз.
Устанавливая решение по мониторингу событий ИБ в ИТ инфраструктуре следует учитывать необходимость выбора баланса между желанием отслеживать всё подряд, и возможностями по обработке огромного количества информации по событиям ИБ. Здесь Zabbix открывает большие возможности для выбора. Ключевые модули Zabbix написаны на C/C++, скорость записи из сети и обработки отслеживаемых событий составляет 10 тысяч новых значений в секунду на более менее обычном сервере с правильно настроенной СУБД.
Всё это даёт нам возможность отслеживать наиболее важные события безопасности на наблюдаемом узле сети под управлением ОС Windows.
Итак, для начала рассмотрим таблицу с Event ID, которые, на мой взгляд, очевидно, можно использовать для мониторинга событий ИБ:
События ИБ MS Windows Server Security Log
| Описание EventID | 2008 Server | 2003 Server |
| Очистка журнала аудита | 1102 | 517 |
| Вход с учётной записью выполнен успешно | 4624 | 528, 540 |
| Учётной записи не удалось выполнить вход в систему | 4625 | 529-535, 539 |
| Создана учётная запись пользователя | 4720 | 624 |
| Попытка сбросить пароль учётной записи | 4724 | 628 |
| Отключена учётная запись пользователя | 4725 | 629 |
| Удалена учётная запись пользователя | 4726 | 630 |
| Создана защищённая локальная группа безопасности | 4731 | 635 |
| Добавлен участник в защищённую локальную группу | 4732 | 636 |
| Удален участник из защищённой локальной группы | 4733 | 637 |
| Удалена защищённая локальная группа безопасности | 4734 | 638 |
| Изменена защищённая локальная группа безопасности | 4735 | 639 |
| Изменена учётная запись пользователя | 4738 | 642 |
| Заблокирована учётная запись пользователя | 4740 | 644 |
| Имя учётной записи было изменено | 4781 | 685 |
Я уделяю внимание локальным группам безопасности, но в более сложных схемах AD необходимо учитывать так же общие и глобальные группы.
Дабы не дублировать информацию, подробнее о критически важных событиях можно почитать в статье:
http://habrahabr.ru/company/netwrix/blog/148501/
Способы мониторинга событий ИБ MS Windows Server
Рассмотрим практическое применение данной задачи.
Для сбора данных необходимо создать новый элемент данных:
При желании для каждого Event ID можно создать по отдельному элементу данных, но я использую в одном ключе сразу несколько Event ID, чтобы хранить все полученные записи в одном месте, что позволяет быстрее производить поиск необходимой информации, не переключаясь между разными элементами данных.
Хочу заметить что в данном ключе в качестве имени мы используем журнал событий Security.
Теперь, когда элемент данных мы получили, следует настроить триггер. Триггер – это механизм Zabbix, позволяющий сигнализировать о том, что наступило какое-либо из отслеживаемых событий. В нашем случае – это событие из журнала сервера или рабочей станции MS Windows.
Теперь все что будет фиксировать журнал аудита с указанными Event ID будет передано на сервер мониторинга. Указание конкретных Event ID полезно тем, что мы получаем только необходимую информацию, и ничего лишнего.
Вот одно из выражений триггера:
Данное выражение позволит отображать на Dashboard информацию о том что «Вход с учётной записью выполнен успешно», что соответствует Event ID 4624 для MS Windows Server 2008. Событие исчезнет спустя 5 минут, если в течение этого времени не был произведен повторный вход.
Если же необходимо отслеживать определенного пользователя, например “Администратор”, можно добавить к выражению триггера проверку по regexp:
Тогда триггер сработает только в том случае если будет осуществлён вход в систему именно под учетной записью с именем “Администратор”.
Мы рассматривали простейший пример, но так же можно использовать более сложные конструкции. Например с использованием типов входа в систему, кодов ошибок, регулярных выражений и других параметров.
Таким образом тонны сообщений, генерируемых системами Windows будет проверять Zabbix, а не наши глаза. Нам остаётся только смотреть на панель Zabbix Dashboard.
Дополнительно, у меня настроена отправка уведомлений на e-mail. Это позволяет оперативно реагировать на события, и не пропустить события произошедшие например в нерабочее время.
Мониторинг событий безопасности Unix систем
Система мониторинга Zabbix так же позволяет собирать информацию из лог-файлов ОС семейства Unix.
События ИБ в Unix системах, подходящие для всех
Такими проблемами безопасности систем семейства Unix являются всё те же попытки подбора паролей к учётным записям, а так же поиск уязвимостей в средствах аутентификации, например, таких как SSH, FTP и прочих.
Некоторые критически важные события в Unix системах
Исходя из вышеуказанного следует, что нам необходимо отслеживать действия, связанные с добавлением, изменением и удалением учётных записей пользователей в системе.
Так же немаловажным фактом будет отслеживание попыток входа в систему. Изменения ключевых файлов типа sudoers, passwd, etc/rc.conf, содержимое каталогов /usr/local/etc/rc.d наличие запущенных процессов и т.п.
Способы мониторинга ИБ в Unix системах
Рассмотрим следующий пример. Нужно отслеживать входы в систему, неудачные попытки входа, попытки подбора паролей в системе FreeBSD по протоколу SSH.
Вся информация об этом, содержится в лог-файле /var/log/auth.log.
По умолчанию права на данный файл — 600, и его можно просматривать только с привилегиями root. Придется немного пожертвовать локальной политикой безопасности, и разрешить читать данный файл группе пользователей zabbix:
Меняем права на файл:
Нам понадобится новый элемент данных со следующим ключом:
Все строки в файле /var/log/auth.log содержащие слово ”sshd” будут переданы агентом на сервер мониторинга.
Далее можно настроить триггер со следующим выражением:
Это выражение определяется как проблема, когда в лог-файле появляются записи, отобранные по регулярному выражению “error:”. Открыв историю полученных данных, мы увидим ошибки, которые возникали при авторизации по протоколу SSH.
Вот пример последнего значения элемента данных, по которому срабатывает данный триггер:
Рассмотрим ещё один пример мониторинга безопасности в ОС FreeBSD:
С помощью агента Zabbix мы можем осуществлять проверку контрольной суммы файла /etc/passwd.
Ключ в данном случае будет следующий:
Это позволяет контролировать изменения учётных записей, включая смену пароля, добавление или удаление пользователей. В данном случае мы не узнаем, какая конкретная операция была произведена, но если к серверу кроме Вас доступ никто не имеет, то это повод для быстрого реагирования. Если необходимо более детально вести политику то можно использовать другие ключи, например пользовательские параметры.
Например, если мы хотим получать список пользователей, которые на данный момент заведены в системе, можно использовать такой пользовательский параметр:
И, например, настроить триггер на изменение в получаемом списке.
Или же можно использовать такой простой параметр:
Так мы увидим на Dashboard, кто на данный момент находится в системе:
Мониторинг событий ИБ на сетевых устройствах
С помощью Zabbix можно так же очень эффективно отслеживать события ИБ на сетевых устройствах Cisco и Juniper, используя протокол SNMP. Передача данных с устройств осуществляется с помощью так называемых трапов (SNMP Trap).
С точки зрения ИБ можно выделить следующие события, которые необходимо отслеживать — изменения конфигураций оборудования, выполнение команд на коммутаторе/маршрутизаторе, успешную авторизацию, неудачные попытки входа и многое другое.
Способы мониторинга
Рассмотрим опять же пример с авторизацией:
В качестве стенда я буду использовать эмулятор GNS3 с маршрутизатором Cisco 3745. Думаю многим знакома данная схема.
Для начала нам необходимо настроить отправку SNMP трапов с маршрутизатора на сервер мониторинга. В моём случае это будет выглядеть так:
Будем отправлять события из Syslog и трапы аутентификации. Замечу, что удачные и неудачные попытки авторизации пишутся именно в Syslog.
Далее необходимо настроить прием нужных нам SNMP трапов на сервере мониторинга.
Добавляем следующие строки в snmptt.conf:
В нашем примере будем ловить трапы Syslog.
Теперь необходимо настроить элемент данных для сбора статистики со следующим ключом:
Если трап не настроен на сервере мониторинга, то в логе сервера будут примерно такие записи:
В результате в полученном логе будет отражаться информация о попытках входа с детализированной информацией (user, source, localport и reason в случае неудачи):
Ну и можно настроить триггер для отображения события на Dashboard:
В сочетании с предыдущим пунктом у нас на Dashboard будет информация вот такого плана:
Аналогично вышеописанному примеру можно осуществлять мониторинг большого количества событий, происходящих на маршрутизаторах Cisco, для описания которых одной статьей явно не обойтись.
Хочу заметить что приведённый пример не будет работать на продуктах Cisco ASA и PIX, так как там несколько иначе организована работа с логированием авторизации.
Juniper и Syslog
Ещё одним примером мы разберем мониторинг авторизации в JunOS 12.1 для устройств Juniper.
Тут мы не сможем воспользоваться трапами SNMP, потому как нет поддержки отправки трапов из Syslog сообщений. Нам понадобится Syslog сервер на базе Unix, в нашем случае им будет тот же сервер мониторинга.
На маршрутизаторе нам необходимо настроить отправку Syslog на сервер хранения:
Теперь все сообщения об авторизации будут отправляться на Syslog сервер, можно конечно отправлять все сообщения (any any), но переизбыток информации нам не нужен, отправляем только необходимое.
Далее переходим к Syslog серверу
Смотрим tcpdump, приходят ли сообщения:
По умолчанию в настройках syslog.conf все что приходит с auth.info должно записываться в /var/log/auth.log. Далее делаем все аналогично примеру с мониторингом входов в Unix.
Вот пример строки из лога:
Остается только настроить триггер на данное событие так же как это было рассмотрено в примере с авторизацией на Unix сервере.
Таким способом можно отслеживать множество событий, среди которых такие как: сохранение конфигурации устройства (commit), вход и выход из режима редактирования конфигурации (edit).
Так же хочу заметить, что аналогичным способом можно осуществлять мониторинг и на устройствах Cisco, но способ с SNMP трапами мне кажется более быстрым и удобным, и исключается необходимость в промежуточном Syslog сервере.
Источник
Ещё раз о хранении логов в Zabbix

Тема сбора и хранения логов в Zabbix поднималась уже не раз. И не два. Если не учитывать, что это не вполне корректный подход, серьёзно нагружающий базу, у таких способов есть еще один существенный недостаток – они хранят логи целиком. И если в случае с логами роутеров или Linux с этим можно как-то смириться, то event-log Windows начинает доставлять много страданий, как серверу Zabbix, так и системному администратору, который решится его собирать и хранить. Ниже — о решении этой проблемы.
Лирическое отступление
За дело!
Обычно при обработке Event-лога придерживаются следующей схемы.
EvtSys — крохотный сервис, который преобразует сообщения EventLog в стандарт Syslog.
У этой связки есть, как минимум, 2 недостатка:
Общая концепция
У нашего нового транспортного средства будет треугольное колесо следующая схема работы.
Heka – это сердце нашего пепелаца. Она почти, как Logstash, только труба пониже и дым пожиже. Зато без JRuby, а, значит, не так требовательна к ресурсам и, к тому же, потрясающе шустра. Спокойно переваривает и обрабатывает несколько тысяч строк лога в секунду. Примерно так:
При этом легко и непринужденно расширяется с помощью плагинов, что в дальнейшем и будет проделано. Общая логика работы системы такова. Поступающие сообщения EvtSys приводит к формату Syslog и передает на обработку Heka. Та парсит syslog-сообщение, выделяет внутреннюю часть сообщения (payload) и парсит далее регулярным выражением, формируя новую строку лога. Эта строка передаётся напрямую в Zabbix с помощью самописного плагина. Размещается всё необходимое на Zabbix-сервере, отдельной машине или, как в нашем случае, на Zabbix-прокси. Такой подход к работе системы устраняет оба ранее озвученных недостатка. Разберёмся подробнее, как всё это устроено внутри.
Настройка EvtSys
Настройка конвейера обработки сообщений
Вот мы и добрались до самой интересной и вкусной части нашего решения. Установку Heka я описывать тоже не буду, она тривиальна до ужаса и хорошо расписана в официальной документации. Поэтому просто примем, что Heka уже установлена и перейдём сразу к её настройке. Как и в Logstash, в Heka реализован конвейер преобразования логов на основе меток. Общий путь, который проходит обрабатываемая строка следующий:
Splitter и Filter могут отсутствовать в конвейере. У нас в конечном итоге так и будет. Какой путь пройдет строка лога, через какие фильтры и как в результате станет выглядеть, определяется условиями, основывающимися на полях внутреннего представления сообщения в Heka. Подробнее об этом можно почитать в документации, а нам сейчас надо сформировать следующий алгоритм работы Heka.
Отдельных пояснений заслуживает MultiDecoder. Он представляет собой контейнер для декодеров, которые могут выполняться либо все последовательно (именно таким образом настроено в syslog-decoder), так и до первого успешного декодирования (в events-decoder). Теперь посмотрим, как это реализовано в конфиге Heka. Чтобы не засорять основной конфиг, выносим всю конфигурацию в отдельный файл. У меня это /etc/heka/conf.d/20-eventlog.toml.
Конфиг Heka
Рассмотрим настройки каждого компонента по отдельности.
Здесь в настройках указываем, что слушать будем на всех интерфейсах и порт берём больше 1024, чтобы не иметь проблем с правами доступа к порту. Именно этот порт надо указывать в EvtSys как порт syslog-сервера. Также сразу указываем декодер, которому будем передавать принятые сообщения.
Как уже писалось выше, этот декодер является контейнером для других декодеров с двумя типами поведения (выполнить все декодеры или выполнять до первого успешного декодирования). Тип поведения задается параметром cascade_strategy и в данном случае он указывает, что надо выполнить все декодеры в порядке, указанном в параметре subs. Для отладки мультидекодера полезно использовать опцию log_sub_errors = true. При её указании Heka будет записывать ошибки декодирования sub-декодеров в свой лог.
Events-decoder сам по себе является мультидекодером, но стратегия поведения у него уже другая — first-wins. Она заставляет декодер выполняться, пока один из внутренних декодеров не вернёт успешно декодированные данные. Это помогает обрабатывать данные по нескольким шаблонам, что и будет продемонстрировано далее.
Event-декодеры все похожи один на другой, как братья-близнецы, потому я рассмотрю только один. Отличия в остальных касаются только regexpдля парсинга и выходной строки лога.
Этот декодер прогоняет строку через регулярное выражение и при этом выделяет отдельные её части, которые можно использовать для создания дополнительных полей сообщения. Такие поля потом нам пригодятся для создания выходного сообщения. Также здесь выставляется тип сообщений (поле Type), чтобы направить их на соответствующий выход (связанный с соответствующим encoder-ом).
А теперь жемчужина нашей коллекции – самописный плагин на Lua. Его работу я рассмотрю в свое время (ниже по течению текста). Здесь же достаточно написать, что он кодирует сообщение для Zabbix-а.
Выход для пересылки сообщений в Zabbix. Пропускает через себя не всё, а только сообщения с соответствующим значением в поле Type. Каждое сообщение пропускает через Encoder, который мы описали выше.
Особое внимание рекомендую обратить на параметр reconnect_after = 1. Это очень важный параметр. Дело в том, что TcpOutput содержит в себе баг и не может долго поддерживать TCP сессию. Выглядит это примерно так: в определённый момент Zabbix вместо полноценных сообщений лога начинает получать какие-то ощипки, а потом прекращается и это. Если посмотреть обмен между Heka и Zabbix через Wireshark, можно увидеть, что TcpOutput начинает бить пакеты и связь обрывается. В итоге, чтобы это не происходило, выставляется вышеуказанный параметр, который заставляет TcpOutput переподключаться после каждой отправки сообщения на Zabbix. Да, естественно, это создаёт оверхед, но я не заметил сколь-нибудь значительного роста нагрузки и на хост с Heka, и на Zabbix-прокси. Может просто сообщений мало отправляю? 😉
Отладка обработки сообщений
Для отладки конвейера я рекомендую две вещи: RstEncoder и вывод в файл. RstEncoder кодирует каждое поле сообщения текстовой строкой, что позволяет видеть, из каких полей состоит сообщение и чему они равны. Вывод в файл помогает отслеживать, что кодируется, а что пропускается и как оно кодируется. Организовать вывод в файл можно так:
Все параметры здесь понятны, поясню только назначение параметра flush_operator = «OR». Он указывает, что новые порции сообщений должны дописываться к уже существующему файлу лога. Меняя encoder, можно проверять формат записываемых сообщений, а message_matcher поможет удостовериться, что сообщения имеют нужный тип. Отключая его, мы начинаем записывать всё. Иногда это помогает обнаружить ошибку в фильтре message_matcher или то, что сообщения не создаются.
Zabbix Trapper
И вот мы подошли к описанию того, как устроен кастомный encoder. Все дополнительные плагины должны лежать в /usr/share/heka/. Так как у нас это encoder, то кладем его сюда – /usr/share/heka/lua_encoders/zabbix_trapper.lua. Посмотрим, что за шестерёнки крутятся у него внутри.
Библиотека CJSON должна лежать в месте, доступном Lua, поэтому я расположил её в /usr/share/heka/lua_modules/cjson.so.
Шаблон для Zabbix
Из особенностей шаблона следует отметить, что элементы данных должны быть типа Zabbix Trapper, с типом информации «Журнал (лог)» и ключами вида eventlog.1102.
Наверное, вы уже обратили внимание на странное устройство триггеров. Так как у нас нет порогового значения, и поступающие данные непостоянны, то такое построение триггеров показалось мне самым правильным. Триггер горит 2 минуты, при этом при высокой важности отправляются соответствующие уведомления и событие не теряется.
И что же в итоге?
Система получилась из разряда настроил и забыл. Усердно трудится на ниве эксплуатации уже несколько месяцев, не требуя никакого обслуживания. Конечно, как и у любой хорошей системы, потенциал расширения у нее есть. Из того, что планируется в будущем:
Жалкая попытка включить прямое логирование – видно, как очередь ненормированно растет, а потом Zabbix трескается пополам, больного едва удалось спасти. Логировался один хост с достаточно высокой нагрузкой на security-лог.
Так уже больше похоже на правду. Да, некоторое количество сообщений по-прежнему торчит в очереди, но это не проблема Windows-логов, и в целом, по общей длине очереди можно оценить прирост производительности. Вдобавок, тут мониторятся два хоста, сообщений меньше не стало, но нагрузка именно этой подсистемы мониторинга успешно теряется на общем фоне.
Источник
Zabbix — Monitor Event Log on Windows
Zabbix — Monitor Event Log on Windows
Hardware List:
The following section presents the list of equipment used to create this Zabbix tutorial.
Every piece of hardware listed above can be found at Amazon website.
Zabbix Playlist:
On this page, we offer quick access to a list of videos related to Zabbix installation.
Don’t forget to subscribe to our youtube channel named FKIT.
Zabbix Related Tutorial:
On this page, we offer quick access to a list of tutorials related to Zabbix installation.
Zabbix Agent Configuration Required
First, the Zabbix agent installed on the Windows computer must be configured in Active mode.
Here is an example of a Zabbix agent configuration file in Passive mode: zabbix_agentd.conf
Here is an example of a Zabbix agent configuration file in Active mode: zabbix_agentd.conf
You have finished the required part of the configuration.
Tutorial — Zabbix Monitor Windows Log File
Now, we need to access the Zabbix server dashboard and add the Windows computer as a Host.
Open your browser and enter the IP address of your web server plus /zabbix.
In our example, the following URL was entered in the Browser:
• http://35.162.85.57/zabbix
On the login screen, use the default username and default password.
• Default Username: Admin
• Default Password: zabbix

After a successful login, you will be sent to the Zabbix Dashboard.

On the dashboard screen, access the Configuration menu and select the Host option.

On the top right of the screen, click on the Create host button.
On the Host configuration screen, you will have to enter the following information:
• Host Name — Enter a Hostname to monitor.
• Visible Hostname — Repeat the hostname.
• New group — Enter a name to identify a group of similar devices.
• Agent Interface — Enter the IP address of the Hostname.
Here is the original image, before our configuration.

Here is the new image with our configuration.

Click on the Add button to include this host on the Zabbix database.
On the dashboard screen, access the Configuration menu and select the Host option.
Locate and click on the hostname that you created before.
In our example, we selected the hostname: WINDOWS-SERVER-01
On the Host properties screen, access the Applications tab.
On the top right part of the screen, click on the Create application button.
On the Host applications screen, create a new application named: LOG

After finishing the Application creation, access the Items tab.
On the top right part of the screen, click on the Create item button.
On the Item creation screen, you need to configure the following items:
• Name: Enter an identification like: Windows System Log
• Type: Zabbix Agent (Active)
• Key: eventlog[System,,,,,,skip]
• Type of Information: Log
• Update interval: 1 Second
• Application: LOG

Click on the Add button to finish the Item creation and wait 5 minutes.
In order to test your configuration, access the Monitoring menu and click on the Latest data option.

Use the filter configuration to select the desired hostname and click on the Apply button.
In our example, we selected the hostname WINDOWS-SERVER-01.

You should be able to see the results of your Windows log file monitoring using Zabbix.

Click on the History option to see more Windows event log details.
In our example, we are monitoring the Windows System Event log.

Congratulations! You have configured the Zabbix Event log monitoring feature on Windows.
VirtualCoin CISSP, PMP, CCNP, MCSE, LPIC22019-10-08T13:55:30-03:00
Related Posts
Page load link
Ok