Описание презентации по отдельным слайдам:
-

1 слайд
Коды, обнаруживающие
и исправляющие ошибки -

2 слайд
11101111 11100000 11110000
11101111 11101000 11110000
ПИР
ПАР
11101111 11100000 11110000
Декодируйте сообщение:
Возможна ли ошибка при передаче данных? -

3 слайд
Исходная информация
Сообщение
Информация с искажением
Сообщение с искажением
Декодирование
Кодирование
Канал связи
Шум -
11101111 11101000 1...")
4 слайд
Как обнаружить ошибку?
Повторить сообщение (продублировать)
11101111 11101000 11110000 11101111 11100000 1111000011111100111111111111110001000000111111110000
11111100111111111111110001000000111111110000
Объём информации увеличивается вдвое следовательно скорость…..
— -

5 слайд
Идея более экономичного кодирования
Все передаваемые сообщения – это числовые данные, записанные цифрами десятичной системы счисления.
Позволяет ли двоичное кодирование обнаружить ошибку?
0010 0011 -

6 слайд
Идея более экономичного кодирования
Если сумма единиц четна, то допишем — 0, нечетна -1
10010 00110 10011
Ошибка! -

7 слайд
Чтобы описать способность кода к распознаванию ошибок, используют понятие – расстояние между словами.
а1 а2 … аn – первое слово
b1 b2 … bn – второе слово
Расстояние между словами — количество позиций, в которых символы одного слова не совпадают с символами другого. -

8 слайд
Расстояние между словами называют расстоянием Хемминга
стог и снег
Какое расстояние между словами?
1001001 и 0100001 -

9 слайд
Код Хемминга
расстояние между кодовыми словами =3
Код Хемминга позволяет найти две ошибки.
Какое расстояние между
словами? -

10 слайд
Код Хемминга может гарантированно исправить одну ошибку и поручить выполнение кода Хемминга можно компьютеру.

Проверка четности. Контрольная сумма. Блочные и древовидные коды. Вес и расстояние Хэмминга между двоичными словами.

Коды делятся на два больших класса
Коды с исправлением ошибок
Цель восстановить с вероятностью, близкой к единице, посланное сообщение.
Коды с обнаружением ошибок
Цель выявить с вероятностью, близкой к единице, наличие ошибок.

Коды с обнаружением ошибок в передаче
Введение в передаваемые кодовые комбинации избыточных разрядов все множество кодовых комбинаций разбивает на два подмножества, что снижает мощность и информационную скорость кода, но позволяет, при принятой запрещенной кодовой комбинации, обнаружить ошибку в передаче.
Например,
введение дополнительного бита контроля по четности делает четным число единиц в каждой кодовой комбинации равнодоступного кода и одновременно увеличивает их отличия не менее чем до двух разрядов.
Разрешенные кодовые комбинации
Запрещенные кодовые комбинации
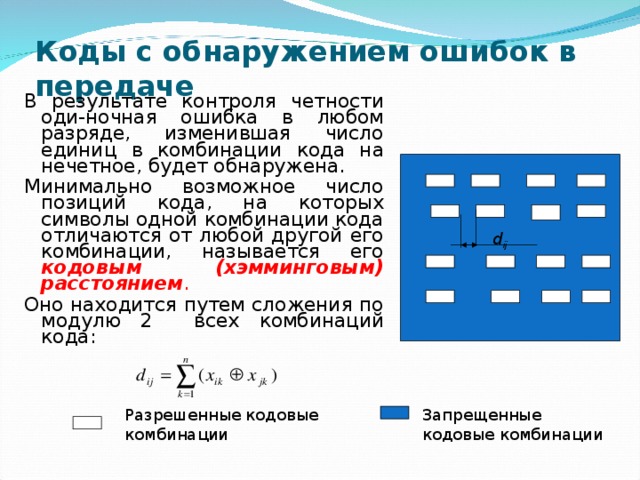
Коды с обнаружением ошибок в передаче
В результате контроля четности оди-ночная ошибка в любом разряде, изменившая число единиц в комбинации кода на нечетное, будет обнаружена.
Минимально возможное число позиций кода, на которых символы одной комбинации кода отличаются от любой другой его комбинации, называется его кодовым (хэмминговым) расстоянием .
Оно находится путем сложения по модулю 2 всех комбинаций кода:
d ij
Разрешенные кодовые комбинации
Запрещенные кодовые комбинации

Виды корректирующих кодов

Коды с исправлением ошибок в передаче
Коды, которые позволяют не только обнаружить ошибку, но и определить номер искаженного символа (позиции), называются кодами с исправлением ошибок .
Для исправления одиночной ошибки придется увеличить кодовое расстояние минимум до 3, двухкратной до 4 и т. п.
В блоковых (блочных) кодах входная непрерывная последовательность информационных символов разбивается на блоки, содержащие k сим — волов.
 k . Этот набор, называемый кодовым словом , передается по каналу связи, искажается шумами и помехами, а затем декодируется независимо от всех других кодовых слов. Величина n называется длиной канального кода или длиной канального блока . Каждое сообщение в этом случае передаётся собственным кодовым словом. Кодовые слова могут объединяться в группы – кодовые предложения или фразы, объединённые некоторой общностью, например, способом защиты от помех кодовых слов, входящих в блок, и т. п. » width=»640″
k . Этот набор, называемый кодовым словом , передается по каналу связи, искажается шумами и помехами, а затем декодируется независимо от всех других кодовых слов. Величина n называется длиной канального кода или длиной канального блока . Каждое сообщение в этом случае передаётся собственным кодовым словом. Кодовые слова могут объединяться в группы – кодовые предложения или фразы, объединённые некоторой общностью, например, способом защиты от помех кодовых слов, входящих в блок, и т. п. » width=»640″
Все дальнейшие операции в кодере производятся над каждым блоком отдельно и независимо от других блоков.
Каждому информационному блоку из k символов ставится в соответствие набор из n символов кода канала передачи сообщений, где n k . Этот набор, называемый кодовым словом , передается по каналу связи, искажается шумами и помехами, а затем декодируется независимо от всех других кодовых слов.
Величина n называется длиной канального кода или длиной канального блока . Каждое сообщение в этом случае передаётся собственным кодовым словом.
Кодовые слова могут объединяться в группы – кодовые предложения или фразы, объединённые некоторой общностью, например, способом защиты от помех кодовых слов, входящих в блок, и т. п.

К онтрольная сумма — это некоторое значение, вычисленное по определённой схеме на основе кодируемого сообщения.
Проверочная информация при систематическом кодировании приписывается к передаваемым данным.
На принимающей стороне абонент знает алгоритм вычисления контрольной суммы: соответственно, программа имеет возможность проверить корректность принятых данных.

Без контрольной суммы, передавать данные опасно, так как помехи присутствуют везде и всегда, весь вопрос только в их вероятности возникновения и вызываемых ими побочных эффектах.
В зависимости от условий и выбирается алгоритм выявления ошибок и количество данных в контрольной сумме.
Чем сложнее алгоритм, и больше контрольная сумма, тем меньше не распознанных ошибок.

Все алгебраические коды можно разделить на два больших класса:
Блочные (блоковые)
Непрерывные
(древовидные)

Блочные коды представляют собой совокупность кодовых символов, состоящих из отдельных комбинаций (блоков) элементов символов кода, которые кодируются и декодируются независимо.

Непрерывные (древовидные) коды представляют собой непрерывную последовательность кодовых символов, причем введение проверочных элементов производится непрерывно, без разделения ее на независимые блоки.

В древовидных (непрерывных) кодах информационная последовательность подвергается обработке без предварительного разбиения на независимые блоки. Длинной, полубесконечной информационной последовательности ставится в соответствие кодовая последовательность, состоящая из большего числа символов.
Непрерывными эти коды называются потому, что операции кодирования и декодирования в них совершаются непрерывно. Они способны исправлять пакетные ошибки при сравнительно простых алгоритмах кодирования и декодирования .

Свойства кодов с исправлением ошибок в передаче
Кодированный цифровой сигнал приобретает свойства обнаружения, а иногда и исправления ошибок, возникающих в процессе передачи и приёма сообщений, т. е. свойство помехозащищенности .
Применение специальных криптографических кодов, известных только соответствующим абонентам, обеспечивает секретность передачи, а зашифрованное сообщение приобретает свойство криптографической стойкости .
Первыми появились блоковые коды, они же также лучше теоретически исследованы. Из древовидных кодов проще всего с точки зрения реализации свёрточные и цепные коды .
Возможности блоковых и древовидных кодов по исправлению ошибок передачи примерно одинаковы. Наибольшее распространение в существующих системах передачи получили разделимые систематические коды , а из них – коды Хэмминга и циклические коды.

Расстоя́ние и вес Хэ́мминга

Пусть u =( u 1 , u 2 , … , u n ) – двоичная последовательность длиной n .
Число единиц в этой последовательности называется весом Хэмминга вектор а u и обозначается как w(u).
Например: u =( 1 0 0 1 0 1 1 ), тогда w ( u )= 4 .
Пусть u и v – двоичные слова длиной n .
Число разрядов, в которых эти слова различаются, называется расстоянием Хэмминга между u и v и обозначается как d(u, v) .
Например: u =( 1 0 0 1 0 1 1 ), v =( 0 1 0 0 0 1 1 ), тогда d ( u , v )= 3 .

Самостоятельно
Найти вес и кодовое расстояние для двоичных слов
- a=011011100
- b=100111001
Решение: Вес для двоичных слов w(a)=5 ; w(b)= 5 .
Кодовое расстояние d(A,B) = 6.
Коды с обнаружением и исправлением ошибок Коды Хэмминга
Эти
коды позволяют обнаруживать и исправлять
все одиночные ошибки (при d=3),
а также исправлять все одиночные ошибки
и обнаруживать все двойные ошибки
(при d=4),
но не исправлять их.
Рассмотрим
Код Хэмминга, исправляющий все одиночные
ошибки.
В
качестве исходного кода берется двоичный
код на все сочетания с числом информационных
символов k,
к которому добавляется m контрольных
символов. Таким образом, общая длина
закодированной комбинацииn=k+m.
Рассмотрим
последовательность кодирования и
декодирования по методу Хэмминга.
Кодирование.
Определение числа контрольных
символов. Для
этого можно воспользоваться следующими
рассуждениями. При передаче по каналу
с шумами может быть или искажен любой
из n символов кода, или слово может быть
передано без искажений. Таким образом,
может быть n+1
вариантов искажения (включая передачу
без искажений).Используя контрольные
символы, мы должны различать все n+1
случаев.
С
помощью m контрольных
символов можно описать 2m событий.
Значит, должно быть выполнено условие
2m ≥ n+1=k+m+1
(3-11)
|
Информ. k |
1 |
|
Контр.m |
2 |
Задаем m,
определим k:
2m ≥
k+m+1
22 ≥ k+2+1, k=1
2m ≥ k+3+1, k=2,
3, 4
Размещение
контрольных символов. В
принципе месторождение этих символов
значения не имеет: их можно приписывать
и перед информационными словами, и после
них, и чередуя информационные символы
с контрольными. Однако произвольное
месторасположение контрольных символов
будет затруднять проверку принятого
кода. Поэтому для удобства обнаружения
искаженного символа целесообразно
размещать их на местах кратных степени
2, то есть в позициях 1, 2, 4, 8 и т.д.
Информационные
символы располагаются на оставшихся
местах. Поэтому, для 7-элементой
закодированной комбинации можно
записать:
23, k=4}
m=3} m1, m2, kн, m3, k3, k2, k1 (3-12)
где k4 —
старший или четвертый разряд исходной
кодовой комбинации двоичного кода,
подлежащий кодированию.
Определение
состава контрольных символов. Выявление
того, какой символ должен стоять на
контрольной позиции (1 или 0), производится
по коэффициентам при помощи проверки
на четность. Рассмотрим определение
коэффициентов на примере комбинации
(3-12).
Таблица
3-11
|
Разряды |
Символы |
|||
|
4(kн) |
3 |
2 |
1(k1) |
|
|
0 |
0 |
0 |
1 |
m1 |
|
0 |
0 |
1 |
0 |
m2 |
|
0 |
0 |
1 |
1 |
k4 |
|
0 |
1 |
0 |
0 |
m3 |
|
0 |
1 |
0 |
1 |
k3 |
|
0 |
1 |
1 |
0 |
k2 |
|
0 |
1 |
1 |
1 |
k1 |
В
таблицу вписаны все кодовые комбинации
(исключая нулевую) для 4-разрядного
двоичного кода на все сочетания.
Таблица
3-12
Проверочная
таблица
|
m1 |
k4 |
k3 |
k1 |
|
m2 |
k4 |
k2 |
k1 |
|
m3 |
k3 |
k2 |
k1 |
Из
таблицы 3-11 составляется таблица 3-12, в
которой вписаны символы в 3 — х строках
в следующей закономерности. В первую
строку таблицы 3-12 записываются
символы m1, .k4, .k3, .k1 против
которых проставлены единицы в младшем
(первом) разряде комбинации двоичного
кода в таблице 3-11. Так в комбинациях
0001, 011, 0101, 0111 единицы находятся в младших
разрядах. Во вторую строку проверочных
коэффициентов записываются символы,
против которых стоит 1 во втором разряде
двоичного кода. Это комбинации 0010, 0011,
0110 и 0111-записали m2, k4, k2, k1.
В третью строку записываются символы,
против которых стоят единицы в третьем
разряде двоичных комбинаций (m3, k3, k2, k1)
В
случае кодирования более длинных кодовых
комбинаций таблицы 3-11 и 3-12 должны быть
расширены, так как должны быть записаны
четвертая, пятая и т.д. строки проверочных
коэффициентов. Так для
комбинации m1,m2, k11, m3, k10, k9, k8, m4, k7, k 6, k5, k4, k3, k2, k1.
таблицы 3-12 будет состоять из 4-х строк.
Число
проверок, а, значит, и число строк таблицы
3-12 равно числу контрольных символов m.
Нахождение
состава контрольных символов при помощи
проверок производится следующим образом.
Суммируются информационные символы,
входящие в каждую строку таблицы 3-12.
Если
сумма единиц в данной строке четная, то
значение символа m, входящее в эту строку,
равно 0, если нечетная, то 1.
При
помощи первой строки табл.3-12 определяется
значение символа m1,
при помощи второй строки — значениеm2,
третьей-m3.
Декодирование. Для
проверки правильности комбинации снова
используется метод проверки на четность
по коэффициентам табл.3-12. Если комбинация
принята без искажения, то сумма единиц
по модулю 2 даст 0.
При
искажении какого-либо символа суммирование
при проверке даст единицу. По результату
суммирования каждой из проверок
составляется двоичное число, указывающее
на место искажения. Например, первая и
вторая проверки показали наличие
искажения, суммирование при третьей
проверке дало 0.Записываем число 011=3,
которое означает, что в 3-ем символе
кодовой комбинации, включающей и
контрольные символы (счет производится
слева направо), возникло искажение,
поэтому этот символ нужно исправить на
обратный ему, то есть 1 переправить на
0 или 0 на 1.
После
этого контрольные символы, стоящие на
заранее известных местах отбрасываются.
Пример
кодирования и декодирования. Предполагаем,
нужно передать комбинацию 1101, то есть k=4.
Согласно
таблице 3-10 число контрольных символов m=3,
и размещаются они на позициях 3, 5, 6, 7.
Можно записать:
m1 m2 k4 m3 k3 k2 k1 (3-13)
?
?
1
?
1
0
1
Для
определения значения контрольных
символов заполним табл. 3-12 значениями
из последовательности (3-13). По полученной
таблице 3-13 произведем проверки на
четность.
Для
того, чтобы вся первая строка после
проставления в нее значения символа m1 дала
в сумме четное число, необходимо,
чтобы m1=1
(m1+ k4+k3+k1=1+1+1+1=0).
Вторая
строка в сумме дает четное число,
если m2=0
(m2+k4+k2+k1=0+1+++1=0)
Третья
строка дает четное число, если m3=0
(m3+k3+k2+k1=0+1+0+1=0)
Таким
образом, в линию послан код 1010101.
Предположим,
что при передаче помеха исказила один
из символов, и был принят код 1010111. Для
нахождения номера ошибки принятого
символа используют метод проверки на
четность по табл.3-12.Для этого запишем:
m1 m2 k4 m3 k3 k2 k1
1
0
1
0
1
1
1
По
полученной последовательности символов
и по таблице 3-12 составим таблицу 3-14.
Таблица
3-13 Таблица 3-14
«Пример
составления таблицы для кода Хэмминга»
«Пример декодирования кода Хэмминга»

После
заполнения этой таблицы сумма символов
первой строки оказалась четной
(1+1+1+1=0), поэтому для четности справа в
первой строке табл. 3-14 приписываем 0.
Сумма символов второй строки равна 3,
поэтому справа для четности добавляется
1. Также для получения четности необходимо
приписать 1 и к третьей строке.
Все
три приписанных символа дали двоичное
число 110 (но не 011), так первая проверка
производилась по коэффициентам,
составленным по младшим разрядам
двоичного кода.
Двоичное
число 110 означает десятичное число 6.
Это значит, что искажение произошло в
шестом символе, считая слева направо,
и символ 1 нужно исправлять на 0. Так как
места расположения контрольных символов
заранее известны, что после коррекции
контрольные символы выбрасывают и
получают переданную кодовую комбинацию,
состоящую из одних информационных
символов 1101.
Итак,
для повышения помехоустойчивости кода
необходимо посылать дополнительные
контрольные символы, которые увеличивают
длину кодовой комбинации, вследствие
чего появляются дополнительные или
избыточные кодовые комбинации, не
используемые непосредственно для
передачи информации.
Так,
семиразрядный код принципиально
обеспечивает передачу 27=128
кодовых комбинаций, однако количество
информационных символов в 7-разрядном
коде Хэмминга к=4,
то есть полезных информационных
Остальные
112 кодовых комбинаций из 128 предназначены
для обеспечения помехоустойчивости
кода и являются запрещенными. Таким
образом, избыточность кола Хэмминга
достаточно велика, хотя мы уже встречались
с кодами, избыточность которых была
больше.
Для
7-разрядного кода Хэмминга, причем с
увеличением разрядности кода избыточность
уменьшается
Выше
был рассмотрен код Хэмминга с обнаружением
и исправлением одиночной ошибки. Такие
коды применяются в том случае, если
статистика показывает, что наиболее
вероятны одиночные искажения в канале
связи. Однако если с некоторой вероятностью
возможно искажение как одного символа
в кодовой комбинации, так и двух, то
целесообразно применение кода Хэмминга,
позволяющего исправлять одиночные
ошибки, если была только одиночная
ошибка, и обнаружить двойные, если были
две ошибки.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

МИНОБРНАУКИ РОССИИ
Федеральное государственное бюджетное образовательное учреждение
высшего образования
«Омский государственный педагогический университет»
(ФГБОУ ВО «ОмГПУ»)
Факультет математики, информатики, физики и технологии
Кафедра прикладной информатики и математики
Курсовая работа
Код Хемминга
Направление: педагогическое образование
Профиль: Информатика и Технология
Дисциплина: Теоретические основы информатики
Выполнила: студентка
32 группы
Коробейникова
Ольга Витальевна
______________________________(подпись)
Научный руководитель:
Курганова
Наталья Александровна
к.п.н., доцент
Оценка _______________
«__» _______________ 20___г.
(подпись)
Омск, 20___
Оглавление
Введение
Глава 1. Теоретические основы изучения помехоустойчивого кодирования
1.1. Виды помехоустойчивого кодирования
1.2. Характеристика кода Хемминга при помехоустойчивом кодировании
1.3. Алгоритмы использования кода Хемминга для нахождения ошибок
Глава 2. Практические основы кода Хемминга
2.1. Примеры использования кода Хемминга для нахождения одной ошибки
2.2. Примеры использования кода Хемминга для нахождения двоичной ошибки
ЗАКЛЮЧЕНИЕ
Список литературы
Введение
На сегодняшний день в мире передается огромное количество информации, хотя системы передачи данных отвечают всем требованиям. Они не являются столь совершенными. При передаче данных могут возникать помехи. Помехоустойчивость – способность системы осуществлять прием информации в условиях наличия помех в линии связи и искажений во внутри аппаратных трактах. Помехоустойчивость обеспечивает надежность и достоверность передаваемой информации (данных).Управление правильностью передачи информации выполняется с помощью помехоустойчивого кодирования. Есть коды, обнаруживающие ошибки, и корректирующие коды, которые еще и исправляют ошибки. Помехозащищенность достигается с помощью введения избыточности, дополнительных битов. В симплексных каналах связи устраняют ошибки с помощью корректирующих кодов. В дуплексных–достаточно применения кодов, обнаруживающих ошибки. [1]
История развития помехоустойчивого кодирования началась еще с 1946г., а именно, после публикации монографии американского ученого К. Шеннона «Работы по теории информации и кибернетике».В этой работе он не показал как построить эти коды, а доказал их существование. Важно отметить, что результаты работы К. Шеннона опирались на работы советских ученых, таких как: А. Я. Хинчин, Р.Р. Варшамов и др. На сегодняшний день проблема передачи данных является особо актуальной,т.к. сбой при передаче может вызвать не только искажение сообщения в целом, но и полную потерю информации. Для этого и существуют помехоустойчивые коды, способные предотвратить потерю и искажение информации. В настоящее время существует ряд разновидностей помехоустойчивых кодов, обеспечивающих высокую достоверность при малой величине избыточности и простоте технической реализации кодирующих и декодирующих устройств. Принципиально коды могут быть использованы как для обнаружения, так и для исправления ошибок. Однако удобства построения кодирующих и декодирующих устройств определили преимущественное применение лишь некоторых из них, в частности корректирующего кода Хемминга.
Цель данной курсовой работы: Ознакомление с помехоустойчивым кодированием и изучение кода Хемминга.
Задачи:
1) Ознакомиться с видами помехоустойчивого кодирования;
2) Ознакомиться с кодом Хемминга, как с одним из видов помехоустойчивого кодирования;
3) Изучить алгоритм построения кода Хемминга.
Объект исследования: помехоустойчивое кодирование.
Предмет исследования: код Хемминга.
Данная курсовая работа состоит из титульного листа, оглавления,введения, двух глав (теоретической и практической), заключения и списка литературы.
Глава 1. Теоретические основы изучения помехоустойчивого кодирования
1.1. Виды помехоустойчивого кодирования
В мире существует немало различных помех и искажений, это могут быть как звуковые искажения, так и на графике. Мы рассмотрим, что понимается под помехой в кодировании информации. Под помехой понимается любое воздействие, накладывающееся на полезный сигнал изатрудняющее его прием. Ниже приведена классификация помех и их источников.
Рис. 1.Помехи и их источники
Внешние источники помех вызывают в основном импульсные помехи, а внутренние –флуктуационные. Помехи, накладываясь на видеосигнал, приводят к двум типам искажений: краевыеи дробления. Краевые искажения связаны со смещением переднего или заднего фронта импульса.Дробление связано с дроблением единого видеосигнала на некоторое количество более коротких сигналов [2].
Приведем классификацию помехоустойчивых кодов.
1) Обнаруживающие ошибки:
блоковые:
А) Разделимые:
- с проверкой на четность;
- корреляционные;
- Хэмминга;
- БЧХ;
Б) Неразделимые:
- с постоянным весом;
- Грея.
2) Корректирующие коды:
Непрерывные:
А) С пороговым декодированием;
Б) По макс. правдоподобия;
В) С последовательным декодированием.
Теперь рассмотрим более подробно каждый вид кодирования.
Код с проверкой на четность.
Проверка четности – очень простой метод для обнаружения ошибок в передаваемом пакете данных. С помощью данного кода мы не можем восстановить данные, но можем обнаружить только лишь одиночную ошибку.
В каждом пакет данных есть один бит четности, или, так называемый, паритетный бит. Этот бит устанавливается во время записи (или отправки) данных, и затем рассчитывается и сравнивается во время чтения (получения) данных. Он равен сумме по модулю 2 всех бит данных в пакете. То есть число единиц в пакете всегда будет четно. Изменение этого бита (например с 0 на 1) сообщает о возникшей ошибке.
Пример:
Начальные данные: 1111
Данные после кодирования: 11110 (1 + 1 + 1 + 1 = 0 (mod 2))
Принятые данные: 10110 (изменился второй бит)
Как мы видим, количество единиц в принятом пакете нечетно, следовательно, при передаче произошла ошибка [3].
Корреляционные коды (код с удвоением).
Элементы данного кода заменяются двумя символами, единица «1» преобразуется в 10, а ноль «0» в 01.
Вместо комбинации 1010011 передается 10011001011010. Ошибка обнаруживается в том случае, если в парных элементах будут одинаковые символы 00 или 11 (вместо 01 и 10) [2].
Код с постоянным весом.
Одним из простейших блочных неразделимых кодов является код с постоянным весом. Примером такого кода может служить семибитный телеграфный код МТК–3, в котором каждая разрешенная кодовая комбинация содержит три единицы и четыре нуля (рис.2). Весом кодовой комбинации называют число содержащихся в ней единиц. В рассматриваемом коде вес кодовых комбинаций равен трем.
Число разрешенных кодовых комбинаций в кодах с постоянным весом определяется как количество сочетаний изnсимволов поgи равно
(1)
Где n–длина кодовой комбинации, аg – вес разрешенной кодовой комбинации. Для кода МТК-3 число разрешенных кодовых комбинаций равно. Таким образом, из общего числа комбинаций
только 35 используются для передачи сообщений[4].

Рис.2. Примеры разрешенных и запрещенных комбинаций кода МТК-3
Инверсный код.
К исходной комбинации добавляется такая же комбинация по длине. В линию посылается удвоенное число символов. Если в исходной комбинации четное число единиц, то добавляемая комбинация повторяет исходную комбинацию, если нечетное, то добавляемая комбинация является инверсной по отношению к исходной.
|
k |
r |
n |
|
11011 |
11011 |
1101111011 |
|
11100 |
00011 |
1110000011 |
Прием инверсного кода осуществляется в два этапа. На первом этапе суммируются единицы в первой основной группе символов. Если число единиц четное, то контрольные символы принимаются без изменения, если нечетное, то контрольные символы инвертируются. На втором этапе контрольные символы суммируются с информационными символами по модулю два. Нулевая сумма говорит об отсутствии ошибок. При ненулевой сумме, принятая комбинация бракуется. Покажем суммирование для принятых комбинаций без ошибок (1,3) и с ошибками (2,4).
|
1) |
11011 11011 |
|
00000 |
|
|
2) |
11111 00100 |
|
11011 |
Обнаруживающие способности данного кода достаточно велики. Данный код обнаруживает практически любые ошибки, кроме редких ошибок смещения, которые одновременно происходят как среди информационных символов, так и среди соответствующих контрольных. Например, при k=5, n=10 и . Коэффициент обнаружения будет составлять
[2].
Код Грея.
По сравнению с простым кодом, код Грея позволяет уменьшить ошибки неоднозначности считывания, а также ошибки из-за помех в канале. Обычно этот код применяется для аналогово-цифрового преобразования непрерывных сообщений.
Недостатком кода Грея является его невесомость, т.е. вес единицы не определяется номером разряда. Информацию в таком виде трудно обрабатывать на ЭВМ. Декодирование кода также связано с большими затратами. Поэтому перед вводом в ЭВМ (или перед декодированием) код Грея преобразуется в простой двоичный код, который удобен для ЭВМ и легко декодируется.
Для перевода простого двоичного кода в код Грея нужно:
- под двоичным числом записать такое же число со сдвигом вправо на один разряд (при этом младший разряд сдвигаемого числа теряется);
- произвести поразрядное сложение двух чисел по модулю 2 (четности). [5].
Таким образом, мы рассмотрели виды помехоустойчивого кодирования и увидели, что их существует не так уж и мало. Каждый код по своему уникален и полезен для кодирования информации. Теперь мы ознакомимся с кодом Хемминга подробнее.
1.2.Характеристика кода Хэмминга при помехоустойчивом кодировании
В середине 40-х годов Ричард Хемминг работал в знаменитых Лабораториях Белла на счётной машине Bell Model V. Это была электромеханическая машина, использующая релейные блоки,скорость которых была очень низка: один оборот за несколько секунд. Данные вводились в машине с помощью перфокарт, и поэтому в процессе чтения часто происходили ошибки. В рабочие дни использовались специальные коды, чтобы обнаруживать и исправлять найденные ошибки, при этом оператор узнавал об ошибке по свечению лампочек, исправлял и запускал машину. В выходные дни, когда не было операторов, при возникновении ошибки машина автоматически выходила из программы и запускала другую.
Р. Хемминг часто работал в выходные дни, и все больше и больше раздражался, потому что часто был должен перегружать свою программу из-за ненадежности перфокарт. На протяжении нескольких лет он проводил много времени над построением эффективных алгоритмов исправления ошибок. В 1950 году он опубликовал способ, который на сегодняшний день мы знаем как код Хемминга.[6.].
Код Хемминга, как и любой (n,k) код, содержит k информационных и избыточных символов. Избыточная часть кода строится таким образом, чтобы при декодировании можно было бы установить не только факт наличия ошибок в принятой – комбинации, но и указать номер позиции, в которой произошла ошибка. Это достигается за счет многократной проверки принятой комбинации на четность. Каждой проверкой должны охватываться часть информационных символов и один из избыточных символов. При каждой проверке получают двоичный контрольный символ. Если результат проверки дает четное число, то контрольному символу присваивается значение 0, если нечетное число– 1. В результате всех проверок получается p-разрядное двоичное число, указывающее номер искаженного символа. Для исправления ошибки достаточно лишь изменить значение данного символа на обратное. [7]
К ним обычно относятся коды с минимальным кодовым расстояниемисправляющие все одиночные ошибки, и коды с расстоянием
исправляющие все одиночные и обнаруживающие все двойные ошибки. Длина кода Хэмминга:
(2)
(r – количество проверочных разрядов).
Характерной особенностью проверочной матрицы кода с является то, что ее столбцы представляют собой любые различные ненулевые комбинации длиной r.Например, при r=4 иn=5 для кода (15,11), проверочная матрица может иметь следующий вид (рис.3)

Рис.3. Проверочная матрица
Перестановкой столбцов, содержащих одну единицу, данную матрицу можно привести к виду(рис.4)

Рис. 4.Измененная матрица
Использование такого кода позволяет исправить любую одиночную ошибку или обнаружить произвольную ошибку кратности два.Если информационные и проверочные разряды кода нумеровать слева направо, то в соответствии с матрицей получаем систему проверочных уравнений, с помощью которых вычисляем проверочные разряды(рис.5):

Рис.5. Система проверочных уравнений
где —
-проверочные разряды;
—
-информационные разряды
Двоичный код Хэмминга с кодовым расстоянием получается путем добавления к коду Хэмминга с
одного проверочного разряда, представляющего собой результат суммирования по модулю два всех разрядов кодового слоя. Длина кода при этом
разрядов, из которых
являются проверочными.
Операция кодирования может выполняться в два этапа. На первом этапе определяется кодовая комбинация с использованием матрицы H, соответствующей коду с на втором — добавляется один проверочный разряд, в котором записывается результат суммирования по модулю два всех разрядов кодового слова, полученного на первом этапе. Операция декодирования также состоит из двух этапов. На первом вычисляется синдром, соответствующий коду на втором — проверяется последнее проверочное соотношение.[8]
Таким образом, ознакомившись с характеристикой кода Хемминга, важно сказать, что состоит код из двух частей и предполагает надежную работу нахождения ошибок и корректировки сообщений.
1.3.Алгоритмы использования кода Хэмминга для нахождения ошибок
Код Хэмминга представляет собой блочный код, который позволяет выявить и исправить ошибочно переданный бит в пределах переданного блока. Код Хэмминга состоит из двух частей. Первая часть кодирует исходное сообщение, вставляя в него в определённых местах контрольные биты (вычисленные особым образом). Вторая часть получает входящее сообщение и заново вычисляет контрольные биты (по тому же алгоритму, что и первая часть). Если все вновь вычисленные контрольные биты совпадают с полученными, то сообщение получено без ошибок. В противном случае, выводится сообщение об ошибке и при возможности ошибка исправляется.
Рассмотрим алгоритм построения кода для исправления одиночной ошибки.
1.По заданному количеству информационных символов – k, либо информационных комбинаций , используя соотношения:
,
(3)
и (4)
(5)
Вычисляют основные параметры кода m и n.
2.Определяем рабочие и контрольные позиции кодовой комбинации. Номера контрольных позиций определяются по закону , где i= 1,2,3,…т.е. они равны 1,2,4,8,16,…а остальные позиции являются рабочими.
3. Определяем значения контрольных разрядов (0 или 1) при помощи многократных проверок кодовой комбинации на четность. Количество проверок равно . В каждую проверку включается один контрольный и определенные проверочные биты. Если результат проверки дает четное число, то контрольному биту присваивается значение – 0, в противном случае – 1. Номера информационных бит, включаемых в каждую проверку, определяются по двоичному коду натуральных n -чисел разрядностью – m (табл. 2, для m = 4) или при помощи проверочной матрицы H(mn), столбцы которой представляют запись в двоичной системе всех целых чисел от 1 до
перечисленных в возрастающем порядке.
Количество разрядов m – определяет количество проверок.
В первую проверку включают коэффициенты, содержащие 1 в младшем (первом) разряде, т.е. b1,b3, b5 и т.д.
Во вторую проверку включают коэффициенты, содержащие 1 во втором разряде, т.е. b2, b3, b6 и т.д.
В третью проверку –коэффициенты которые содержат 1 в третьем разряде и т.д.
Таблица 2
|
Десятичные числа (номера разрядов кодовой комбинации) |
Двоичные числа и их разряды |
|
|
3 |
21 |
|
|
1 |
0 |
01 |
|
2 |
0 |
10 |
|
3 |
0 |
11 |
|
4 |
1 |
00 |
|
5 |
1 |
01 |
|
6 |
1 |
10 |
|
7 |
1 |
11 |
Для обнаружения и исправления ошибки составляются аналогичные проверки на четность контрольных сумм, результатом которых является двоичное (n-k) – разрядное число, называемое синдромом и указывающим на положение ошибки, т.е. номер ошибочной позиции, который определяется по двоичной записи числа, либо по проверочной матрице.
Для исправления ошибки необходимо проинвертировать бит в ошибочной позиции. Для исправления одиночной ошибки и обнаружения двойной используют дополнительную проверку на четность. Если при исправлении ошибки контроль на четность фиксирует ошибку, то значит в кодовой комбинации две ошибки.[9]
Вывод к главе 1: Таким образом, мы узнали, что такое помехоустойчивость, помехоустойчивое кодирование, ознакомились с видами помехоустойчивого кодирования. Затем рассмотрели код Хемминга, изучили алгоритм построения кода Хемминга. При построении кода важно знать, что код Хемминга ищет и исправляет одиночную ошибку, но двойную ошибку. В итоге, изучив теоретическую часть, мы выяснили, какие существуют виды помехоустойчивого кодирования. Ознакомились подробнее с кодом Хемминга, изучили его алгоритм кодирования.
Глава 2. Практические основы кода Хемминга
2.1. Примеры использования кода Хемминга для нахождения одной ошибки
Существует множество различных примеров для нахождения ошибок при помощи кода Хемминга.
Пример 1. Пользуясь кодом Хэмминга найти ошибку в сообщении.
1) 1111 1011 0010 1100 1101 1100 110
РЕШЕНИЕ. Сообщение состоит из 27 символов, из них 22 информационные, а 5 – контрольные. Это разряды b1 = 1, b2 = 1, b4 = 1, b8 = 1, b16=0. Вычислим число J для обнаружения ошибки: Введем для удобства следующие множества:
V1 = 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27… – все числа у которых первый разрядравен 1
V2 = 2, 3, 6, 7, 10, 11, 14, 15, 18, 19, 22, 23, 26, 27… – все числа, у которых второй разрядравен 1
V3 = 4, 5, 6, 7, 12, 13, 14, 15, 20, 21, 22, 23 … – все числа, у которых третий разряд равен1
V4 = 8, 9, 10, 11, 12, 13, 14, 15, 24, 25, 26, 27 … – все числа, у которых четвертый разрядравен 1,
V5 = 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27 … – все числа, у которых пятый разрядравен 1.
Разряды числа J определяются следующим образом:
j1 = b1 +b3+b5+b7+b9+b11+b13+b15+b17+b19+b21+b23+b25+b27 = 1
j2=b2+b3+b6+b7+b10+b11+b14+b15+b18+b19+b22+b23+b26+b27= 0
j3 = b4+b5+b6+b7 +b12+b13+ b14+ b15+ b20 +b21+b22+b23 = 0
j4 =b9+b10+b11+b12+b13+b14+b15+b24+b25+b26+b27 = 0,
j5 = b16+ b17+b18+b19+b20+b21+b22+b23+b24+b25+b26+b27 = 1
то есть число J= =
.
Таким образом, ошибка произошла в семнадцатом разряде переданного числа.[10]. В этом примере мы рассмотрели, как можно обнаружить одиночную ошибку. Далее мы проанализируем пример, как можно найти и исправить эту ошибку.
Пример 2.
Построить код Хемминга для передачи сообщений в виде последовательности десятичных цифр, представленных в виде 4 –х разрядных двоичных слов. Показать процесс кодирования, декодирования и исправления одиночной ошибки на примере информационного слова 0101.
Решение:
1. По заданной длине информационного слова (k = 4 ), определим количество контрольных разрядов m, используя соотношение:
,
при этом т. е. получили (7, 4) -код.
2. Определяем номера рабочих и контрольных позиции кодовой комбинации. Номера контрольных позиций выбираем по закону .
Для рассматриваемой задачи (при n = 7 ) номера контрольных позиций равны 1, 2, 4. При этом кодовая комбинация имеет вид:
b1 b2 b3 b4 b5 b6 b7
k1 k2 0 k2 1 0 1
3. Определяем значения контрольных разрядов (0 или 1), используя проверочную матрицу (рис.3).
Первая проверка:
k1b3 b5 b7 = k1 011 будет четной при k1 = 0.
Вторая проверка:
k2 b3 b6 b7 = k2 001 будет четной при k2 = 1.
Третья проверка:
k3 b5 b6 b7 = k3 101 будет четной при k3 = 0.
1 2 3 4 5 6 7
Передаваемая кодовая комбинация: 0100101
Допустим принято: 0110101
Для обнаружения и исправления ошибки составим аналогичные проверки на четность контрольных сумм, в соответствии с проверочной матрицей результатом которых является двоичное ( ) – разрядное число, называемое синдромом и указывающим на положение ошибки, т. е, номер ошибочной позиции.
1) k1= b3 b5 b7 = 0111 = 1.
2)k2=b3 b6 b7 = 1101 = 1.
3) k3 =b5 b6 b7 = 0101 =0.
Сравнивая синдром ошибки со столбцами проверочной матрицы, определяем номер ошибочного бита. Синдрому 011 соответствует третий столбец, т. е. ошибка в третьем разряде кодовой комбинации. Символ в третьей позиции необходимо изменить на обратный.
Рассмотрев данные задачи, мы выяснили насколько точно код Хемминга может найти и исправить одиночные ошибки.
2.2. Примеры использования кода Хемминга для нахождения двоичной ошибки
Для обнаружения двойной ошибки следует только добавить еще один проверочный разряд.
Пример 1:
Принята кодовая комбинация С = 101000001001, произошло
искажение 2-го и 5-го разрядов. Обнаружить ошибки.
Решение.
Значения проверок равны:
k1= b1 b3 b5 b7 b9 b11 = 110010= 1
k2= b2 b3 b6 b7 b10 b11= 010000=1
k3=b4 b5 b6 b7 b12= 00001=1
k4= b8 b9 b10 b11 b12= 01001=0
Тогда контрольное число (синдром) ошибкиравен 0111.
Таким образом, при наличии двукратной ошибки декодирование дает
номер разряда с ошибкой в позиции 7, в то время как ошибки произошли
во 2-м и 5-м разрядах. В этом случае составляется расширенный код
Хэмминга, путем добавления одного проверочного символа.
Пример 2 :
Передана кодовая комбинация «01001011», закодированная кодом Хемминга с d = 4. Показать процесс выявления ошибки.
Решение:
Принята комбинация «01001111»:
а) проверка на общую четность указывает на наличие ошибки (число единиц четное);
б) частные проверки производятся так же, как это было в других примерах.
При составлении проверочных сумм последние единицы кодовых комбинаций (дополнительные контрольные символы) не учитываются.
2. Принята комбинация «01101111»:
а) проверка на общую четность показывает, что ошибка не фиксируется;
б) частные проверки (последний символ отбрасывается)
Первая проверка 0 1 1 1 = 1
Вторая проверка 1 1 1 1 = 0
Третья проверка 0 1 1 1 = 1
Таким образом, частные проверки фиксируют наличие ошибки. Она, якобы, имела место на пятой позиции. Но так как при этом первая проверка на общую четность ошибки не зафиксировала, то значит, имела место двойная ошибка. Исправить двойную ошибку такой код не может [14].
Вывод к главе 2: Таким образом, мы показали, как работает код Хемминга на практике. Мы видим, что при одиночной ошибке ее можно исправить, но для этого нам нужно знать, сколько потребуется контрольных разрядов, а двойную ошибку можно лишь обнаружить.
ЗАКЛЮЧЕНИЕ
Высокие требования к достоверности передачи, обработки и хранения информации диктуют необходимость такого кодированияинформации, при котором обеспечивалось бы возможность обнаружения и исправления ошибок. Широкому применению результатов теории помехоустойчивогокодирования в современных системах связи, обработки и хранения информацииследует считать отсутствие достаточно простых решений сложных теоретических достижений теории помехоустойчивого кодирования.В данной работе исследовано помехоустойчивое кодирование, в частности код Хемминга.
Список литературы
- Вернер М. Основы кодирования[Текст].– М.: Техносфера, 2004. – 288 с.
- Помехоустойчивое кодирование [Электронный ресурс]. – Режим доступа:https://clck.ru/9cWsc,свободный. Дата обращения: 27.11.2015.
- Помехоустойчивое кодирование [Электронный ресурс]. – Режим доступа:http://habrahabr.ru/post/111336/, свободный. Дата обращения: 05.12.2015.
- Файловый архив для студентов. Лекция: основные понятия кодирования в ЦСПИ [Электронный ресурс]. – Режим доступа: http://www.studfiles.ru/preview/4087325/,свободный. Дата обращения: 27.11.2015.
- Лекция «Простейшие коды» [Электронный ресурс]. – Режим доступа: http://davaiknam.ru/text/lekciya-3-kodirovanie-informacii-prostejshie-kodi, свободный. Дата обращения: 27.11.2015.
- Академик [Электронный ресурс] – Режим доступа: http://dic.academic.ru/dic.nsf/ruwiki/177544, свободный. Дата обращения: 27.11.2015
- Кузьмин И.В.Основы теории информации и кодирования [Текст]. – Киев,1986. – 237 с.
- Научная библиотека. Код Хемминга [Электронный ресурс]. – Режим доступа: http://info.sernam.ru/book_codb.php?id=28, свободный. Дата обращения: 05.12.2015
- Статья корректирующие коды [Электронный ресурс]. – Режим доступа: http://referatwork.ru/refs/source/ref-11094.html#Текст работы, свободный. Дата обращения: 05.12.2015
- МатБюро- решение задач по высшей математике [Электронный ресурс]. – Режим доступа: http://www.matburo.ru/Examples/Files/Hem2.pdf, свободный. Дата обращения: 06.12.2015.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки. [Текст]. – Москва, 1986г. –576 с.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования – методы, алгоритмы, применение. [Текст]. – Москва, 2005г.–320 с.
- Р.Хемминг Теория кодирования и теория информации. / Перевод с английского С.Гальфанда. // [Текст]. – Москва, 1983г. – 176 с.
- Портал студентов «Седьмой бит» [Электронный ресурс]. – Режим доступа: http://www.itmo.ru/work/253/page4, открытый. Дата обращения: 20.12.2015.

To clean up transmission errors introduced by Earth’s atmosphere (left), Goddard scientists applied Reed–Solomon error correction (right), which is commonly used in CDs and DVDs. Typical errors include missing pixels (white) and false signals (black). The white stripe indicates a brief period when transmission was interrupted.
In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
Definitions[edit]
Error detection is the detection of errors caused by noise or other impairments during transmission from the transmitter to the receiver.
Error correction is the detection of errors and reconstruction of the original, error-free data.
History[edit]
In classical antiquity, copyists of the Hebrew Bible were paid for their work according to the number of stichs (lines of verse). As the prose books of the Bible were hardly ever written in stichs, the copyists, in order to estimate the amount of work, had to count the letters.[1] This also helped ensure accuracy in the transmission of the text with the production of subsequent copies.[2][3] Between the 7th and 10th centuries CE a group of Jewish scribes formalized and expanded this to create the Numerical Masorah to ensure accurate reproduction of the sacred text. It included counts of the number of words in a line, section, book and groups of books, noting the middle stich of a book, word use statistics, and commentary.[1] Standards became such that a deviation in even a single letter in a Torah scroll was considered unacceptable.[4] The effectiveness of their error correction method was verified by the accuracy of copying through the centuries demonstrated by discovery of the Dead Sea Scrolls in 1947–1956, dating from c.150 BCE-75 CE.[5]
The modern development of error correction codes is credited to Richard Hamming in 1947.[6] A description of Hamming’s code appeared in Claude Shannon’s A Mathematical Theory of Communication[7] and was quickly generalized by Marcel J. E. Golay.[8]
Introduction[edit]
All error-detection and correction schemes add some redundancy (i.e., some extra data) to a message, which receivers can use to check consistency of the delivered message, and to recover data that has been determined to be corrupted. Error-detection and correction schemes can be either systematic or non-systematic. In a systematic scheme, the transmitter sends the original data, and attaches a fixed number of check bits (or parity data), which are derived from the data bits by some deterministic algorithm. If only error detection is required, a receiver can simply apply the same algorithm to the received data bits and compare its output with the received check bits; if the values do not match, an error has occurred at some point during the transmission. In a system that uses a non-systematic code, the original message is transformed into an encoded message carrying the same information and that has at least as many bits as the original message.
Good error control performance requires the scheme to be selected based on the characteristics of the communication channel. Common channel models include memoryless models where errors occur randomly and with a certain probability, and dynamic models where errors occur primarily in bursts. Consequently, error-detecting and correcting codes can be generally distinguished between random-error-detecting/correcting and burst-error-detecting/correcting. Some codes can also be suitable for a mixture of random errors and burst errors.
If the channel characteristics cannot be determined, or are highly variable, an error-detection scheme may be combined with a system for retransmissions of erroneous data. This is known as automatic repeat request (ARQ), and is most notably used in the Internet. An alternate approach for error control is hybrid automatic repeat request (HARQ), which is a combination of ARQ and error-correction coding.
Types of error correction[edit]
There are three major types of error correction.[9]
Automatic repeat request[edit]
Automatic repeat request (ARQ) is an error control method for data transmission that makes use of error-detection codes, acknowledgment and/or negative acknowledgment messages, and timeouts to achieve reliable data transmission. An acknowledgment is a message sent by the receiver to indicate that it has correctly received a data frame.
Usually, when the transmitter does not receive the acknowledgment before the timeout occurs (i.e., within a reasonable amount of time after sending the data frame), it retransmits the frame until it is either correctly received or the error persists beyond a predetermined number of retransmissions.
Three types of ARQ protocols are Stop-and-wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ.
ARQ is appropriate if the communication channel has varying or unknown capacity, such as is the case on the Internet. However, ARQ requires the availability of a back channel, results in possibly increased latency due to retransmissions, and requires the maintenance of buffers and timers for retransmissions, which in the case of network congestion can put a strain on the server and overall network capacity.[10]
For example, ARQ is used on shortwave radio data links in the form of ARQ-E, or combined with multiplexing as ARQ-M.
Forward error correction[edit]
Forward error correction (FEC) is a process of adding redundant data such as an error-correcting code (ECC) to a message so that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) are introduced, either during the process of transmission or on storage. Since the receiver does not have to ask the sender for retransmission of the data, a backchannel is not required in forward error correction. Error-correcting codes are used in lower-layer communication such as cellular network, high-speed fiber-optic communication and Wi-Fi,[11][12] as well as for reliable storage in media such as flash memory, hard disk and RAM.[13]
Error-correcting codes are usually distinguished between convolutional codes and block codes:
- Convolutional codes are processed on a bit-by-bit basis. They are particularly suitable for implementation in hardware, and the Viterbi decoder allows optimal decoding.
- Block codes are processed on a block-by-block basis. Early examples of block codes are repetition codes, Hamming codes and multidimensional parity-check codes. They were followed by a number of efficient codes, Reed–Solomon codes being the most notable due to their current widespread use. Turbo codes and low-density parity-check codes (LDPC) are relatively new constructions that can provide almost optimal efficiency.
Shannon’s theorem is an important theorem in forward error correction, and describes the maximum information rate at which reliable communication is possible over a channel that has a certain error probability or signal-to-noise ratio (SNR). This strict upper limit is expressed in terms of the channel capacity. More specifically, the theorem says that there exist codes such that with increasing encoding length the probability of error on a discrete memoryless channel can be made arbitrarily small, provided that the code rate is smaller than the channel capacity. The code rate is defined as the fraction k/n of k source symbols and n encoded symbols.
The actual maximum code rate allowed depends on the error-correcting code used, and may be lower. This is because Shannon’s proof was only of existential nature, and did not show how to construct codes which are both optimal and have efficient encoding and decoding algorithms.
Hybrid schemes[edit]
Hybrid ARQ is a combination of ARQ and forward error correction. There are two basic approaches:[10]
- Messages are always transmitted with FEC parity data (and error-detection redundancy). A receiver decodes a message using the parity information, and requests retransmission using ARQ only if the parity data was not sufficient for successful decoding (identified through a failed integrity check).
- Messages are transmitted without parity data (only with error-detection information). If a receiver detects an error, it requests FEC information from the transmitter using ARQ, and uses it to reconstruct the original message.
The latter approach is particularly attractive on an erasure channel when using a rateless erasure code.
Error detection schemes[edit]
Error detection is most commonly realized using a suitable hash function (or specifically, a checksum, cyclic redundancy check or other algorithm). A hash function adds a fixed-length tag to a message, which enables receivers to verify the delivered message by recomputing the tag and comparing it with the one provided.
There exists a vast variety of different hash function designs. However, some are of particularly widespread use because of either their simplicity or their suitability for detecting certain kinds of errors (e.g., the cyclic redundancy check’s performance in detecting burst errors).
Minimum distance coding[edit]
A random-error-correcting code based on minimum distance coding can provide a strict guarantee on the number of detectable errors, but it may not protect against a preimage attack.
Repetition codes[edit]
A repetition code is a coding scheme that repeats the bits across a channel to achieve error-free communication. Given a stream of data to be transmitted, the data are divided into blocks of bits. Each block is transmitted some predetermined number of times. For example, to send the bit pattern «1011», the four-bit block can be repeated three times, thus producing «1011 1011 1011». If this twelve-bit pattern was received as «1010 1011 1011» – where the first block is unlike the other two – an error has occurred.
A repetition code is very inefficient, and can be susceptible to problems if the error occurs in exactly the same place for each group (e.g., «1010 1010 1010» in the previous example would be detected as correct). The advantage of repetition codes is that they are extremely simple, and are in fact used in some transmissions of numbers stations.[14][15]
Parity bit[edit]
A parity bit is a bit that is added to a group of source bits to ensure that the number of set bits (i.e., bits with value 1) in the outcome is even or odd. It is a very simple scheme that can be used to detect single or any other odd number (i.e., three, five, etc.) of errors in the output. An even number of flipped bits will make the parity bit appear correct even though the data is erroneous.
Parity bits added to each «word» sent are called transverse redundancy checks, while those added at the end of a stream of «words» are called longitudinal redundancy checks. For example, if each of a series of m-bit «words» has a parity bit added, showing whether there were an odd or even number of ones in that word, any word with a single error in it will be detected. It will not be known where in the word the error is, however. If, in addition, after each stream of n words a parity sum is sent, each bit of which shows whether there were an odd or even number of ones at that bit-position sent in the most recent group, the exact position of the error can be determined and the error corrected. This method is only guaranteed to be effective, however, if there are no more than 1 error in every group of n words. With more error correction bits, more errors can be detected and in some cases corrected.
There are also other bit-grouping techniques.
Checksum[edit]
A checksum of a message is a modular arithmetic sum of message code words of a fixed word length (e.g., byte values). The sum may be negated by means of a ones’-complement operation prior to transmission to detect unintentional all-zero messages.
Checksum schemes include parity bits, check digits, and longitudinal redundancy checks. Some checksum schemes, such as the Damm algorithm, the Luhn algorithm, and the Verhoeff algorithm, are specifically designed to detect errors commonly introduced by humans in writing down or remembering identification numbers.
Cyclic redundancy check[edit]
A cyclic redundancy check (CRC) is a non-secure hash function designed to detect accidental changes to digital data in computer networks. It is not suitable for detecting maliciously introduced errors. It is characterized by specification of a generator polynomial, which is used as the divisor in a polynomial long division over a finite field, taking the input data as the dividend. The remainder becomes the result.
A CRC has properties that make it well suited for detecting burst errors. CRCs are particularly easy to implement in hardware and are therefore commonly used in computer networks and storage devices such as hard disk drives.
The parity bit can be seen as a special-case 1-bit CRC.
Cryptographic hash function[edit]
The output of a cryptographic hash function, also known as a message digest, can provide strong assurances about data integrity, whether changes of the data are accidental (e.g., due to transmission errors) or maliciously introduced. Any modification to the data will likely be detected through a mismatching hash value. Furthermore, given some hash value, it is typically infeasible to find some input data (other than the one given) that will yield the same hash value. If an attacker can change not only the message but also the hash value, then a keyed hash or message authentication code (MAC) can be used for additional security. Without knowing the key, it is not possible for the attacker to easily or conveniently calculate the correct keyed hash value for a modified message.
Error correction code[edit]
Any error-correcting code can be used for error detection. A code with minimum Hamming distance, d, can detect up to d − 1 errors in a code word. Using minimum-distance-based error-correcting codes for error detection can be suitable if a strict limit on the minimum number of errors to be detected is desired.
Codes with minimum Hamming distance d = 2 are degenerate cases of error-correcting codes, and can be used to detect single errors. The parity bit is an example of a single-error-detecting code.
Applications[edit]
Applications that require low latency (such as telephone conversations) cannot use automatic repeat request (ARQ); they must use forward error correction (FEC). By the time an ARQ system discovers an error and re-transmits it, the re-sent data will arrive too late to be usable.
Applications where the transmitter immediately forgets the information as soon as it is sent (such as most television cameras) cannot use ARQ; they must use FEC because when an error occurs, the original data is no longer available.
Applications that use ARQ must have a return channel; applications having no return channel cannot use ARQ.
Applications that require extremely low error rates (such as digital money transfers) must use ARQ due to the possibility of uncorrectable errors with FEC.
Reliability and inspection engineering also make use of the theory of error-correcting codes.[16]
Internet[edit]
In a typical TCP/IP stack, error control is performed at multiple levels:
- Each Ethernet frame uses CRC-32 error detection. Frames with detected errors are discarded by the receiver hardware.
- The IPv4 header contains a checksum protecting the contents of the header. Packets with incorrect checksums are dropped within the network or at the receiver.
- The checksum was omitted from the IPv6 header in order to minimize processing costs in network routing and because current link layer technology is assumed to provide sufficient error detection (see also RFC 3819).
- UDP has an optional checksum covering the payload and addressing information in the UDP and IP headers. Packets with incorrect checksums are discarded by the network stack. The checksum is optional under IPv4, and required under IPv6. When omitted, it is assumed the data-link layer provides the desired level of error protection.
- TCP provides a checksum for protecting the payload and addressing information in the TCP and IP headers. Packets with incorrect checksums are discarded by the network stack, and eventually get retransmitted using ARQ, either explicitly (such as through three-way handshake) or implicitly due to a timeout.
Deep-space telecommunications[edit]
The development of error-correction codes was tightly coupled with the history of deep-space missions due to the extreme dilution of signal power over interplanetary distances, and the limited power availability aboard space probes. Whereas early missions sent their data uncoded, starting in 1968, digital error correction was implemented in the form of (sub-optimally decoded) convolutional codes and Reed–Muller codes.[17] The Reed–Muller code was well suited to the noise the spacecraft was subject to (approximately matching a bell curve), and was implemented for the Mariner spacecraft and used on missions between 1969 and 1977.
The Voyager 1 and Voyager 2 missions, which started in 1977, were designed to deliver color imaging and scientific information from Jupiter and Saturn.[18] This resulted in increased coding requirements, and thus, the spacecraft were supported by (optimally Viterbi-decoded) convolutional codes that could be concatenated with an outer Golay (24,12,8) code. The Voyager 2 craft additionally supported an implementation of a Reed–Solomon code. The concatenated Reed–Solomon–Viterbi (RSV) code allowed for very powerful error correction, and enabled the spacecraft’s extended journey to Uranus and Neptune. After ECC system upgrades in 1989, both crafts used V2 RSV coding.
The Consultative Committee for Space Data Systems currently recommends usage of error correction codes with performance similar to the Voyager 2 RSV code as a minimum. Concatenated codes are increasingly falling out of favor with space missions, and are replaced by more powerful codes such as Turbo codes or LDPC codes.
The different kinds of deep space and orbital missions that are conducted suggest that trying to find a one-size-fits-all error correction system will be an ongoing problem. For missions close to Earth, the nature of the noise in the communication channel is different from that which a spacecraft on an interplanetary mission experiences. Additionally, as a spacecraft increases its distance from Earth, the problem of correcting for noise becomes more difficult.
Satellite broadcasting[edit]
The demand for satellite transponder bandwidth continues to grow, fueled by the desire to deliver television (including new channels and high-definition television) and IP data. Transponder availability and bandwidth constraints have limited this growth. Transponder capacity is determined by the selected modulation scheme and the proportion of capacity consumed by FEC.
Data storage[edit]
Error detection and correction codes are often used to improve the reliability of data storage media.[19] A parity track capable of detecting single-bit errors was present on the first magnetic tape data storage in 1951. The optimal rectangular code used in group coded recording tapes not only detects but also corrects single-bit errors. Some file formats, particularly archive formats, include a checksum (most often CRC32) to detect corruption and truncation and can employ redundancy or parity files to recover portions of corrupted data. Reed-Solomon codes are used in compact discs to correct errors caused by scratches.
Modern hard drives use Reed–Solomon codes to detect and correct minor errors in sector reads, and to recover corrupted data from failing sectors and store that data in the spare sectors.[20] RAID systems use a variety of error correction techniques to recover data when a hard drive completely fails. Filesystems such as ZFS or Btrfs, as well as some RAID implementations, support data scrubbing and resilvering, which allows bad blocks to be detected and (hopefully) recovered before they are used.[21] The recovered data may be re-written to exactly the same physical location, to spare blocks elsewhere on the same piece of hardware, or the data may be rewritten onto replacement hardware.
Error-correcting memory[edit]
Dynamic random-access memory (DRAM) may provide stronger protection against soft errors by relying on error-correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for mission-critical applications, such as scientific computing, financial, medical, etc. as well as extraterrestrial applications due to the increased radiation in space.
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy. Interleaving allows distributing the effect of a single cosmic ray potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single-event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error-correcting code), and the illusion of an error-free memory system may be maintained.[22]
In addition to hardware providing features required for ECC memory to operate, operating systems usually contain related reporting facilities that are used to provide notifications when soft errors are transparently recovered. One example is the Linux kernel’s EDAC subsystem (previously known as Bluesmoke), which collects the data from error-checking-enabled components inside a computer system; besides collecting and reporting back the events related to ECC memory, it also supports other checksumming errors, including those detected on the PCI bus.[23][24][25] A few systems[specify] also support memory scrubbing to catch and correct errors early before they become unrecoverable.
See also[edit]
- Berger code
- Burst error-correcting code
- ECC memory, a type of computer data storage
- Link adaptation
- List of algorithms § Error detection and correction
- List of hash functions
References[edit]
- ^ a b «Masorah». Jewish Encyclopedia.
- ^ Pratico, Gary D.; Pelt, Miles V. Van (2009). Basics of Biblical Hebrew Grammar: Second Edition. Zondervan. ISBN 978-0-310-55882-8.
- ^ Mounce, William D. (2007). Greek for the Rest of Us: Using Greek Tools Without Mastering Biblical Languages. Zondervan. p. 289. ISBN 978-0-310-28289-1.
- ^ Mishneh Torah, Tefillin, Mezuzah, and Sefer Torah, 1:2. Example English translation: Eliyahu Touger. The Rambam’s Mishneh Torah. Moznaim Publishing Corporation.
- ^ Brian M. Fagan (5 December 1996). «Dead Sea Scrolls». The Oxford Companion to Archaeology. Oxford University Press. ISBN 0195076184.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, p. vii, ISBN 0-88385-023-0
- ^ Shannon, C.E. (1948), «A Mathematical Theory of Communication», Bell System Technical Journal, 27 (3): 379–423, doi:10.1002/j.1538-7305.1948.tb01338.x, hdl:10338.dmlcz/101429, PMID 9230594
- ^ Golay, Marcel J. E. (1949), «Notes on Digital Coding», Proc.I.R.E. (I.E.E.E.), 37: 657
- ^ Gupta, Vikas; Verma, Chanderkant (November 2012). «Error Detection and Correction: An Introduction». International Journal of Advanced Research in Computer Science and Software Engineering. 2 (11). S2CID 17499858.
- ^ a b A. J. McAuley, Reliable Broadband Communication Using a Burst Erasure Correcting Code, ACM SIGCOMM, 1990.
- ^ Shah, Pradeep M.; Vyavahare, Prakash D.; Jain, Anjana (September 2015). «Modern error correcting codes for 4G and beyond: Turbo codes and LDPC codes». 2015 Radio and Antenna Days of the Indian Ocean (RADIO): 1–2. doi:10.1109/RADIO.2015.7323369. ISBN 978-9-9903-7339-4. S2CID 28885076. Retrieved 22 May 2022.
- ^ «IEEE SA — IEEE 802.11ac-2013». IEEE Standards Association.
- ^ «Transition to Advanced Format 4K Sector Hard Drives | Seagate US». Seagate.com. Retrieved 22 May 2022.
- ^ Frank van Gerwen. «Numbers (and other mysterious) stations». Archived from the original on 12 July 2017. Retrieved 12 March 2012.
- ^ Gary Cutlack (25 August 2010). «Mysterious Russian ‘Numbers Station’ Changes Broadcast After 20 Years». Gizmodo. Retrieved 12 March 2012.
- ^ Ben-Gal I.; Herer Y.; Raz T. (2003). «Self-correcting inspection procedure under inspection errors» (PDF). IIE Transactions. IIE Transactions on Quality and Reliability, 34(6), pp. 529-540. Archived from the original (PDF) on 2013-10-13. Retrieved 2014-01-10.
- ^ K. Andrews et al., The Development of Turbo and LDPC Codes for Deep-Space Applications, Proceedings of the IEEE, Vol. 95, No. 11, Nov. 2007.
- ^ Huffman, William Cary; Pless, Vera S. (2003). Fundamentals of Error-Correcting Codes. Cambridge University Press. ISBN 978-0-521-78280-7.
- ^ Kurtas, Erozan M.; Vasic, Bane (2018-10-03). Advanced Error Control Techniques for Data Storage Systems. CRC Press. ISBN 978-1-4200-3649-7.[permanent dead link]
- ^ Scott A. Moulton. «My Hard Drive Died». Archived from the original on 2008-02-02.
- ^ Qiao, Zhi; Fu, Song; Chen, Hsing-Bung; Settlemyer, Bradley (2019). «Building Reliable High-Performance Storage Systems: An Empirical and Analytical Study». 2019 IEEE International Conference on Cluster Computing (CLUSTER): 1–10. doi:10.1109/CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ Jeff Layton. «Error Detection and Correction». Linux Magazine. Retrieved 2014-08-12.
- ^ «EDAC Project». bluesmoke.sourceforge.net. Retrieved 2014-08-12.
- ^ «Documentation/edac.txt». Linux kernel documentation. kernel.org. 2014-06-16. Archived from the original on 2009-09-05. Retrieved 2014-08-12.
Further reading[edit]
- Shu Lin; Daniel J. Costello, Jr. (1983). Error Control Coding: Fundamentals and Applications. Prentice Hall. ISBN 0-13-283796-X.
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
External links[edit]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, contains chapters on elementary error-correcting codes; on the theoretical limits of error-correction; and on the latest state-of-the-art error-correcting codes, including low-density parity-check codes, turbo codes, and fountain codes.
- ECC Page — implementations of popular ECC encoding and decoding routines
To clean up transmission errors introduced by Earth’s atmosphere (left), Goddard scientists applied Reed–Solomon error correction (right), which is commonly used in CDs and DVDs. Typical errors include missing pixels (white) and false signals (black). The white stripe indicates a brief period when transmission was interrupted.
In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
Definitions[edit]
Error detection is the detection of errors caused by noise or other impairments during transmission from the transmitter to the receiver.
Error correction is the detection of errors and reconstruction of the original, error-free data.
History[edit]
In classical antiquity, copyists of the Hebrew Bible were paid for their work according to the number of stichs (lines of verse). As the prose books of the Bible were hardly ever written in stichs, the copyists, in order to estimate the amount of work, had to count the letters.[1] This also helped ensure accuracy in the transmission of the text with the production of subsequent copies.[2][3] Between the 7th and 10th centuries CE a group of Jewish scribes formalized and expanded this to create the Numerical Masorah to ensure accurate reproduction of the sacred text. It included counts of the number of words in a line, section, book and groups of books, noting the middle stich of a book, word use statistics, and commentary.[1] Standards became such that a deviation in even a single letter in a Torah scroll was considered unacceptable.[4] The effectiveness of their error correction method was verified by the accuracy of copying through the centuries demonstrated by discovery of the Dead Sea Scrolls in 1947–1956, dating from c.150 BCE-75 CE.[5]
The modern development of error correction codes is credited to Richard Hamming in 1947.[6] A description of Hamming’s code appeared in Claude Shannon’s A Mathematical Theory of Communication[7] and was quickly generalized by Marcel J. E. Golay.[8]
Introduction[edit]
All error-detection and correction schemes add some redundancy (i.e., some extra data) to a message, which receivers can use to check consistency of the delivered message, and to recover data that has been determined to be corrupted. Error-detection and correction schemes can be either systematic or non-systematic. In a systematic scheme, the transmitter sends the original data, and attaches a fixed number of check bits (or parity data), which are derived from the data bits by some deterministic algorithm. If only error detection is required, a receiver can simply apply the same algorithm to the received data bits and compare its output with the received check bits; if the values do not match, an error has occurred at some point during the transmission. In a system that uses a non-systematic code, the original message is transformed into an encoded message carrying the same information and that has at least as many bits as the original message.
Good error control performance requires the scheme to be selected based on the characteristics of the communication channel. Common channel models include memoryless models where errors occur randomly and with a certain probability, and dynamic models where errors occur primarily in bursts. Consequently, error-detecting and correcting codes can be generally distinguished between random-error-detecting/correcting and burst-error-detecting/correcting. Some codes can also be suitable for a mixture of random errors and burst errors.
If the channel characteristics cannot be determined, or are highly variable, an error-detection scheme may be combined with a system for retransmissions of erroneous data. This is known as automatic repeat request (ARQ), and is most notably used in the Internet. An alternate approach for error control is hybrid automatic repeat request (HARQ), which is a combination of ARQ and error-correction coding.
Types of error correction[edit]
There are three major types of error correction.[9]
Automatic repeat request[edit]
Automatic repeat request (ARQ) is an error control method for data transmission that makes use of error-detection codes, acknowledgment and/or negative acknowledgment messages, and timeouts to achieve reliable data transmission. An acknowledgment is a message sent by the receiver to indicate that it has correctly received a data frame.
Usually, when the transmitter does not receive the acknowledgment before the timeout occurs (i.e., within a reasonable amount of time after sending the data frame), it retransmits the frame until it is either correctly received or the error persists beyond a predetermined number of retransmissions.
Three types of ARQ protocols are Stop-and-wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ.
ARQ is appropriate if the communication channel has varying or unknown capacity, such as is the case on the Internet. However, ARQ requires the availability of a back channel, results in possibly increased latency due to retransmissions, and requires the maintenance of buffers and timers for retransmissions, which in the case of network congestion can put a strain on the server and overall network capacity.[10]
For example, ARQ is used on shortwave radio data links in the form of ARQ-E, or combined with multiplexing as ARQ-M.
Forward error correction[edit]
Forward error correction (FEC) is a process of adding redundant data such as an error-correcting code (ECC) to a message so that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) are introduced, either during the process of transmission or on storage. Since the receiver does not have to ask the sender for retransmission of the data, a backchannel is not required in forward error correction. Error-correcting codes are used in lower-layer communication such as cellular network, high-speed fiber-optic communication and Wi-Fi,[11][12] as well as for reliable storage in media such as flash memory, hard disk and RAM.[13]
Error-correcting codes are usually distinguished between convolutional codes and block codes:
- Convolutional codes are processed on a bit-by-bit basis. They are particularly suitable for implementation in hardware, and the Viterbi decoder allows optimal decoding.
- Block codes are processed on a block-by-block basis. Early examples of block codes are repetition codes, Hamming codes and multidimensional parity-check codes. They were followed by a number of efficient codes, Reed–Solomon codes being the most notable due to their current widespread use. Turbo codes and low-density parity-check codes (LDPC) are relatively new constructions that can provide almost optimal efficiency.
Shannon’s theorem is an important theorem in forward error correction, and describes the maximum information rate at which reliable communication is possible over a channel that has a certain error probability or signal-to-noise ratio (SNR). This strict upper limit is expressed in terms of the channel capacity. More specifically, the theorem says that there exist codes such that with increasing encoding length the probability of error on a discrete memoryless channel can be made arbitrarily small, provided that the code rate is smaller than the channel capacity. The code rate is defined as the fraction k/n of k source symbols and n encoded symbols.
The actual maximum code rate allowed depends on the error-correcting code used, and may be lower. This is because Shannon’s proof was only of existential nature, and did not show how to construct codes which are both optimal and have efficient encoding and decoding algorithms.
Hybrid schemes[edit]
Hybrid ARQ is a combination of ARQ and forward error correction. There are two basic approaches:[10]
- Messages are always transmitted with FEC parity data (and error-detection redundancy). A receiver decodes a message using the parity information, and requests retransmission using ARQ only if the parity data was not sufficient for successful decoding (identified through a failed integrity check).
- Messages are transmitted without parity data (only with error-detection information). If a receiver detects an error, it requests FEC information from the transmitter using ARQ, and uses it to reconstruct the original message.
The latter approach is particularly attractive on an erasure channel when using a rateless erasure code.
Error detection schemes[edit]
Error detection is most commonly realized using a suitable hash function (or specifically, a checksum, cyclic redundancy check or other algorithm). A hash function adds a fixed-length tag to a message, which enables receivers to verify the delivered message by recomputing the tag and comparing it with the one provided.
There exists a vast variety of different hash function designs. However, some are of particularly widespread use because of either their simplicity or their suitability for detecting certain kinds of errors (e.g., the cyclic redundancy check’s performance in detecting burst errors).
Minimum distance coding[edit]
A random-error-correcting code based on minimum distance coding can provide a strict guarantee on the number of detectable errors, but it may not protect against a preimage attack.
Repetition codes[edit]
A repetition code is a coding scheme that repeats the bits across a channel to achieve error-free communication. Given a stream of data to be transmitted, the data are divided into blocks of bits. Each block is transmitted some predetermined number of times. For example, to send the bit pattern «1011», the four-bit block can be repeated three times, thus producing «1011 1011 1011». If this twelve-bit pattern was received as «1010 1011 1011» – where the first block is unlike the other two – an error has occurred.
A repetition code is very inefficient, and can be susceptible to problems if the error occurs in exactly the same place for each group (e.g., «1010 1010 1010» in the previous example would be detected as correct). The advantage of repetition codes is that they are extremely simple, and are in fact used in some transmissions of numbers stations.[14][15]
Parity bit[edit]
A parity bit is a bit that is added to a group of source bits to ensure that the number of set bits (i.e., bits with value 1) in the outcome is even or odd. It is a very simple scheme that can be used to detect single or any other odd number (i.e., three, five, etc.) of errors in the output. An even number of flipped bits will make the parity bit appear correct even though the data is erroneous.
Parity bits added to each «word» sent are called transverse redundancy checks, while those added at the end of a stream of «words» are called longitudinal redundancy checks. For example, if each of a series of m-bit «words» has a parity bit added, showing whether there were an odd or even number of ones in that word, any word with a single error in it will be detected. It will not be known where in the word the error is, however. If, in addition, after each stream of n words a parity sum is sent, each bit of which shows whether there were an odd or even number of ones at that bit-position sent in the most recent group, the exact position of the error can be determined and the error corrected. This method is only guaranteed to be effective, however, if there are no more than 1 error in every group of n words. With more error correction bits, more errors can be detected and in some cases corrected.
There are also other bit-grouping techniques.
Checksum[edit]
A checksum of a message is a modular arithmetic sum of message code words of a fixed word length (e.g., byte values). The sum may be negated by means of a ones’-complement operation prior to transmission to detect unintentional all-zero messages.
Checksum schemes include parity bits, check digits, and longitudinal redundancy checks. Some checksum schemes, such as the Damm algorithm, the Luhn algorithm, and the Verhoeff algorithm, are specifically designed to detect errors commonly introduced by humans in writing down or remembering identification numbers.
Cyclic redundancy check[edit]
A cyclic redundancy check (CRC) is a non-secure hash function designed to detect accidental changes to digital data in computer networks. It is not suitable for detecting maliciously introduced errors. It is characterized by specification of a generator polynomial, which is used as the divisor in a polynomial long division over a finite field, taking the input data as the dividend. The remainder becomes the result.
A CRC has properties that make it well suited for detecting burst errors. CRCs are particularly easy to implement in hardware and are therefore commonly used in computer networks and storage devices such as hard disk drives.
The parity bit can be seen as a special-case 1-bit CRC.
Cryptographic hash function[edit]
The output of a cryptographic hash function, also known as a message digest, can provide strong assurances about data integrity, whether changes of the data are accidental (e.g., due to transmission errors) or maliciously introduced. Any modification to the data will likely be detected through a mismatching hash value. Furthermore, given some hash value, it is typically infeasible to find some input data (other than the one given) that will yield the same hash value. If an attacker can change not only the message but also the hash value, then a keyed hash or message authentication code (MAC) can be used for additional security. Without knowing the key, it is not possible for the attacker to easily or conveniently calculate the correct keyed hash value for a modified message.
Error correction code[edit]
Any error-correcting code can be used for error detection. A code with minimum Hamming distance, d, can detect up to d − 1 errors in a code word. Using minimum-distance-based error-correcting codes for error detection can be suitable if a strict limit on the minimum number of errors to be detected is desired.
Codes with minimum Hamming distance d = 2 are degenerate cases of error-correcting codes, and can be used to detect single errors. The parity bit is an example of a single-error-detecting code.
Applications[edit]
Applications that require low latency (such as telephone conversations) cannot use automatic repeat request (ARQ); they must use forward error correction (FEC). By the time an ARQ system discovers an error and re-transmits it, the re-sent data will arrive too late to be usable.
Applications where the transmitter immediately forgets the information as soon as it is sent (such as most television cameras) cannot use ARQ; they must use FEC because when an error occurs, the original data is no longer available.
Applications that use ARQ must have a return channel; applications having no return channel cannot use ARQ.
Applications that require extremely low error rates (such as digital money transfers) must use ARQ due to the possibility of uncorrectable errors with FEC.
Reliability and inspection engineering also make use of the theory of error-correcting codes.[16]
Internet[edit]
In a typical TCP/IP stack, error control is performed at multiple levels:
- Each Ethernet frame uses CRC-32 error detection. Frames with detected errors are discarded by the receiver hardware.
- The IPv4 header contains a checksum protecting the contents of the header. Packets with incorrect checksums are dropped within the network or at the receiver.
- The checksum was omitted from the IPv6 header in order to minimize processing costs in network routing and because current link layer technology is assumed to provide sufficient error detection (see also RFC 3819).
- UDP has an optional checksum covering the payload and addressing information in the UDP and IP headers. Packets with incorrect checksums are discarded by the network stack. The checksum is optional under IPv4, and required under IPv6. When omitted, it is assumed the data-link layer provides the desired level of error protection.
- TCP provides a checksum for protecting the payload and addressing information in the TCP and IP headers. Packets with incorrect checksums are discarded by the network stack, and eventually get retransmitted using ARQ, either explicitly (such as through three-way handshake) or implicitly due to a timeout.
Deep-space telecommunications[edit]
The development of error-correction codes was tightly coupled with the history of deep-space missions due to the extreme dilution of signal power over interplanetary distances, and the limited power availability aboard space probes. Whereas early missions sent their data uncoded, starting in 1968, digital error correction was implemented in the form of (sub-optimally decoded) convolutional codes and Reed–Muller codes.[17] The Reed–Muller code was well suited to the noise the spacecraft was subject to (approximately matching a bell curve), and was implemented for the Mariner spacecraft and used on missions between 1969 and 1977.
The Voyager 1 and Voyager 2 missions, which started in 1977, were designed to deliver color imaging and scientific information from Jupiter and Saturn.[18] This resulted in increased coding requirements, and thus, the spacecraft were supported by (optimally Viterbi-decoded) convolutional codes that could be concatenated with an outer Golay (24,12,8) code. The Voyager 2 craft additionally supported an implementation of a Reed–Solomon code. The concatenated Reed–Solomon–Viterbi (RSV) code allowed for very powerful error correction, and enabled the spacecraft’s extended journey to Uranus and Neptune. After ECC system upgrades in 1989, both crafts used V2 RSV coding.
The Consultative Committee for Space Data Systems currently recommends usage of error correction codes with performance similar to the Voyager 2 RSV code as a minimum. Concatenated codes are increasingly falling out of favor with space missions, and are replaced by more powerful codes such as Turbo codes or LDPC codes.
The different kinds of deep space and orbital missions that are conducted suggest that trying to find a one-size-fits-all error correction system will be an ongoing problem. For missions close to Earth, the nature of the noise in the communication channel is different from that which a spacecraft on an interplanetary mission experiences. Additionally, as a spacecraft increases its distance from Earth, the problem of correcting for noise becomes more difficult.
Satellite broadcasting[edit]
The demand for satellite transponder bandwidth continues to grow, fueled by the desire to deliver television (including new channels and high-definition television) and IP data. Transponder availability and bandwidth constraints have limited this growth. Transponder capacity is determined by the selected modulation scheme and the proportion of capacity consumed by FEC.
Data storage[edit]
Error detection and correction codes are often used to improve the reliability of data storage media.[19] A parity track capable of detecting single-bit errors was present on the first magnetic tape data storage in 1951. The optimal rectangular code used in group coded recording tapes not only detects but also corrects single-bit errors. Some file formats, particularly archive formats, include a checksum (most often CRC32) to detect corruption and truncation and can employ redundancy or parity files to recover portions of corrupted data. Reed-Solomon codes are used in compact discs to correct errors caused by scratches.
Modern hard drives use Reed–Solomon codes to detect and correct minor errors in sector reads, and to recover corrupted data from failing sectors and store that data in the spare sectors.[20] RAID systems use a variety of error correction techniques to recover data when a hard drive completely fails. Filesystems such as ZFS or Btrfs, as well as some RAID implementations, support data scrubbing and resilvering, which allows bad blocks to be detected and (hopefully) recovered before they are used.[21] The recovered data may be re-written to exactly the same physical location, to spare blocks elsewhere on the same piece of hardware, or the data may be rewritten onto replacement hardware.
Error-correcting memory[edit]
Dynamic random-access memory (DRAM) may provide stronger protection against soft errors by relying on error-correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for mission-critical applications, such as scientific computing, financial, medical, etc. as well as extraterrestrial applications due to the increased radiation in space.
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy. Interleaving allows distributing the effect of a single cosmic ray potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single-event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error-correcting code), and the illusion of an error-free memory system may be maintained.[22]
In addition to hardware providing features required for ECC memory to operate, operating systems usually contain related reporting facilities that are used to provide notifications when soft errors are transparently recovered. One example is the Linux kernel’s EDAC subsystem (previously known as Bluesmoke), which collects the data from error-checking-enabled components inside a computer system; besides collecting and reporting back the events related to ECC memory, it also supports other checksumming errors, including those detected on the PCI bus.[23][24][25] A few systems[specify] also support memory scrubbing to catch and correct errors early before they become unrecoverable.
See also[edit]
- Berger code
- Burst error-correcting code
- ECC memory, a type of computer data storage
- Link adaptation
- List of algorithms § Error detection and correction
- List of hash functions
References[edit]
- ^ a b «Masorah». Jewish Encyclopedia.
- ^ Pratico, Gary D.; Pelt, Miles V. Van (2009). Basics of Biblical Hebrew Grammar: Second Edition. Zondervan. ISBN 978-0-310-55882-8.
- ^ Mounce, William D. (2007). Greek for the Rest of Us: Using Greek Tools Without Mastering Biblical Languages. Zondervan. p. 289. ISBN 978-0-310-28289-1.
- ^ Mishneh Torah, Tefillin, Mezuzah, and Sefer Torah, 1:2. Example English translation: Eliyahu Touger. The Rambam’s Mishneh Torah. Moznaim Publishing Corporation.
- ^ Brian M. Fagan (5 December 1996). «Dead Sea Scrolls». The Oxford Companion to Archaeology. Oxford University Press. ISBN 0195076184.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, p. vii, ISBN 0-88385-023-0
- ^ Shannon, C.E. (1948), «A Mathematical Theory of Communication», Bell System Technical Journal, 27 (3): 379–423, doi:10.1002/j.1538-7305.1948.tb01338.x, hdl:10338.dmlcz/101429, PMID 9230594
- ^ Golay, Marcel J. E. (1949), «Notes on Digital Coding», Proc.I.R.E. (I.E.E.E.), 37: 657
- ^ Gupta, Vikas; Verma, Chanderkant (November 2012). «Error Detection and Correction: An Introduction». International Journal of Advanced Research in Computer Science and Software Engineering. 2 (11). S2CID 17499858.
- ^ a b A. J. McAuley, Reliable Broadband Communication Using a Burst Erasure Correcting Code, ACM SIGCOMM, 1990.
- ^ Shah, Pradeep M.; Vyavahare, Prakash D.; Jain, Anjana (September 2015). «Modern error correcting codes for 4G and beyond: Turbo codes and LDPC codes». 2015 Radio and Antenna Days of the Indian Ocean (RADIO): 1–2. doi:10.1109/RADIO.2015.7323369. ISBN 978-9-9903-7339-4. S2CID 28885076. Retrieved 22 May 2022.
- ^ «IEEE SA — IEEE 802.11ac-2013». IEEE Standards Association.
- ^ «Transition to Advanced Format 4K Sector Hard Drives | Seagate US». Seagate.com. Retrieved 22 May 2022.
- ^ Frank van Gerwen. «Numbers (and other mysterious) stations». Archived from the original on 12 July 2017. Retrieved 12 March 2012.
- ^ Gary Cutlack (25 August 2010). «Mysterious Russian ‘Numbers Station’ Changes Broadcast After 20 Years». Gizmodo. Retrieved 12 March 2012.
- ^ Ben-Gal I.; Herer Y.; Raz T. (2003). «Self-correcting inspection procedure under inspection errors» (PDF). IIE Transactions. IIE Transactions on Quality and Reliability, 34(6), pp. 529-540. Archived from the original (PDF) on 2013-10-13. Retrieved 2014-01-10.
- ^ K. Andrews et al., The Development of Turbo and LDPC Codes for Deep-Space Applications, Proceedings of the IEEE, Vol. 95, No. 11, Nov. 2007.
- ^ Huffman, William Cary; Pless, Vera S. (2003). Fundamentals of Error-Correcting Codes. Cambridge University Press. ISBN 978-0-521-78280-7.
- ^ Kurtas, Erozan M.; Vasic, Bane (2018-10-03). Advanced Error Control Techniques for Data Storage Systems. CRC Press. ISBN 978-1-4200-3649-7.[permanent dead link]
- ^ Scott A. Moulton. «My Hard Drive Died». Archived from the original on 2008-02-02.
- ^ Qiao, Zhi; Fu, Song; Chen, Hsing-Bung; Settlemyer, Bradley (2019). «Building Reliable High-Performance Storage Systems: An Empirical and Analytical Study». 2019 IEEE International Conference on Cluster Computing (CLUSTER): 1–10. doi:10.1109/CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ Jeff Layton. «Error Detection and Correction». Linux Magazine. Retrieved 2014-08-12.
- ^ «EDAC Project». bluesmoke.sourceforge.net. Retrieved 2014-08-12.
- ^ «Documentation/edac.txt». Linux kernel documentation. kernel.org. 2014-06-16. Archived from the original on 2009-09-05. Retrieved 2014-08-12.
Further reading[edit]
- Shu Lin; Daniel J. Costello, Jr. (1983). Error Control Coding: Fundamentals and Applications. Prentice Hall. ISBN 0-13-283796-X.
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
External links[edit]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, contains chapters on elementary error-correcting codes; on the theoretical limits of error-correction; and on the latest state-of-the-art error-correcting codes, including low-density parity-check codes, turbo codes, and fountain codes.
- ECC Page — implementations of popular ECC encoding and decoding routines
Презентация на тему «Помехоустойчивое кодирование информации»
-
Скачать презентацию (0.25 Мб)
-
136 загрузок -
2.7 оценка
Ваша оценка презентации
Оцените презентацию по шкале от 1 до 5 баллов
- 1
- 2
- 3
- 4
- 5
Комментарии
Добавить свой комментарий
Аннотация к презентации
Интересует тема «Помехоустойчивое кодирование информации»? Лучшая powerpoint презентация на эту тему представлена здесь! Данная презентация состоит из 33 слайдов. Средняя оценка: 2.7 балла из 5. Также представлены другие презентации по информатике для студентов. Скачивайте бесплатно.
-
Формат
pptx (powerpoint)
-
Количество слайдов
33
-
Слова
-
Конспект
Отсутствует
Содержание
-

Слайд 1
Помехоустойчивое кодирование
Основные идеи
-

Слайд 2
Литература
Алгебраическая теория кодирования Автор: Берлекэмп Э. Издательство: Мир Год: 1971
Теория кодов, исправляющих ошибки Мак-Вильямс Ф.Дж., Слоэн Н.Дж.А. Издательство: Связь Год: 1979
Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение. Морелос-Сарагоса Р..: Издательство: Техносфера, Год: 2006. -

Слайд 3
Кодирование информации
Кодирование источника – устранение «лишней», сжатие информации
Кодирование канала – добавление избыточности для обнаружения и/или исправления ошибок (в результате шума) – защита от случайных воздействий -

Слайд 4
Шум
Может произойти из-за магнитной бури, молнии, метеоритного дождя, случайного искажения звука в радиопередаче, плохой печати изображения или текста, плохой слышимости …
В результате шума сообщение может исказиться -

Слайд 5
Канал
Например, телефонная линия или атмосфера
-

Слайд 6
Методы борьбы со случайными ошибками
Введение избыточности
Цели: обнаружение иили исправление ошибок -

Слайд 7
Ошибка в одном разряде
-

Слайд 8
Пакет ошибок длины 8
-

Слайд 9
Модель ошибки
Ошибка – замена в двоичном сообщении 0 на 1 иили наоборот, замена 1 на 0
Пример: ИСХОДНОЕ СЛОВО: 00010100
ОШИБОЧНЫЕ СЛОВА: 00110100, 00000100, 00101100 -

Слайд 10
Другие модели
Стирающий канал
Канал со вставками -

Слайд 11
Структура кодера и декодера
-

Слайд 12
Передача по зашумленному каналу
-

Слайд 13
Пример:в результате шума сообщение 00000 искажается в 01001
-

Слайд 14
Продолжение примера
Кодирование:
Код – множество кодовых слов:
-

Слайд 15
Метод борьбы с шумом
Избыточность
0кодируется как 00000,
а 1 кодируется как 11111. -

Слайд 16
Пример(1)
Сообщение Алисы: NNWNNWWSSWWNNNNWWN
-

Слайд 17
Пример(2)
Сообщение Алисы: NNWNNWWSSWWNNNNWWN
Исходное множество символов: {E,W.S,N}
Множество кодовых слов {00,01,10,11}
– любая ошибка приводит к катастрофе -

Слайд 18
Пример(3)
Сообщение Алисы: NNWNNWWSSWWNNNNWWN
Исходное множество символов: {E,W.S,N}
Множество кодовых слов {000,011,101,110}
– обнаружение любой ошибки -

Слайд 19
Пример(4)
Сообщение Алисы: NNWNNWWSSWWNNNNWWN
Исходное множество символов: {E,W.S,N}
Множество кодовых слов {00000,01101,10110,11011}
– локализация ошибки – возможно ее исправление -

Слайд 20
Цели передачи по каналу с шумом
1.Быстрое кодирование информации.
2.Простой способ передачи закодированного сообщения.
3. Быстрое декодирование полученной информации.
4.Надежная очистка от шума.
5.Передача максимального объема информации в единицу времени. -

Слайд 21
ДСК – двоичный симметричный канал
-

Слайд 22
двоичный : (0,1)
симметричный: p( 01) =p(10) -

Слайд 23
Другие модели каналов
0
1
0 (light on)1 (light off)
p
1-p
X Y
P(X=0) = P00
1
0E
1
1-e
ee
1-e
P(X=0) = P0
Z-канал (оптический) Стирающий канал(MAC) -

Слайд 24
BER – bit error rate
Это средняя вероятность ошибки одного бита передаваемой информации
-

Слайд 25
Помехоустойчивое кодирование – две стратегии
Исправление ошибки за счет избыточности (FEC – forward error correction)
Обнаружение ошибок с последующим запросом на повторную передачу ошибочно принятой информации ( ARR – automatic repeat request) -

-

Слайд 27
Помехоустойчивое кодирование – области применения
Хранение информации с высокой плотностью записи –CD-ROM, DVD
Передача данных при ограниченной мощности сигнала –спутниковая и мобильная связь
Передача информации по сильно зашумленным каналам – высокоскоростные проводные линии связи, мобильная связь
Передача данных по каналам связи с повышенными требованиями к надежности информации – вычислительные сети, линии передачи со сжатием -

Слайд 28
Кодирование – замена информационного слова на кодовое
Пример.
-

Слайд 29
В общем случае: B={0,1}
Двоичное кодирование: -

Слайд 30
Расстояние Хэмминга между двумя словами есть число разрядов, в которых эти слова различаются
-

Слайд 31
10.31
1. Расстояние Хэмминга d(000, 011) есть 2 :
Пример
2.Расстояние Хэмминга d(10101, 11110) равно 3 -

Слайд 32
Декодирование – исправление ошибки, если она произошла
Множество кодовых слов {00000,01101,10110,11011}
Если полученное слово 10000, то декодируем в «ближайшее» слово 00000
Если полученное слово 11000 – то только обнаружение, так как два варианта: 11000 – в 00000 или 11000 – в 11011 -

Слайд 33
Выводы
Если в процессе передачи по зашумленному каналу кодовое слово отобразится в другое кодовое слово, не совпадающее с переданным, то происходит необнаруживаемая ошибка –ошибка декодирования
Хорошие коды должны иметь такую структуру, чтобы была возможность не только обнаруживать, но и исправлять ошибки
Посмотреть все слайды
Сообщить об ошибке
Похожие презентации












Спасибо, что оценили презентацию.
Мы будем благодарны если вы поможете сделать сайт лучше и оставите отзыв или предложение по улучшению.
Добавить отзыв о сайте
1. Обнаружение ошибок
2.
3.
• Каналы передачи данных не всегда
надежны, да и само оборудование
обработки информации работает со
сбоями.
• По этой причине важную роль
приобретают механизмы детектирования
ошибок. Ведь если ошибка обнаружена,
можно осуществить повторную передачу
данных и решить проблему.
4. Чтобы найти ошибку, к сообщению добавляют контрольную сумму (checksum).
• В простом случае это сумма всех байтов сообщения.
• Например:
Сообщение: 12 34 56
Контрольная сумма: 12+34+56=102
• После передачи в это сообщение могут быть
внесены помехи, например: искаженное сообщение
12 36 56 и контрольная сумма 102
• Если теперь сложить байты сообщения, результат не
совпадет с контрольной суммой. Программа может
сделать вывод, что данные были повреждены, и
принять меры (например, еще раз запросить пакет
или выдать сообщение, что он поврежден.
5. Чем плоха контрольная сумма
• Во-первых, если просто складывать байты, то старшие биты
будут изменяться реже, чем младшие. То есть, если мы
складываем
12 34 56, контрольная сумма 102
12 34 56 23, контрольная сумма 125
12 34 56 23 45, контрольная сумма 170
результат останется в пределах двух сотен. Если контрольная
сумма записана в 32-разрядное слово, старшие байты будут
содержать нули. Это не хорошо, так как все биты контрольной
суммы должны быть равноценными.
• Во-вторых, сообщения с переставленными байтами будут иметь
одну и ту же сумму:
12 34 56, контрольная сумма 102
56 12 34, контрольная сумма 102
6. Расстояние Хэмминга
• Пусть А и Б две двоичные кодовые последовательности
равной длины. Расстояние Хэмминга между двумя этими
кодовыми последовательностями равно числу символов,
которыми они отличаются. Например, расстояние
Хэмминга между кодами 00111 и 10101 равно 2.
• Для детектирования ошибок в n битах, схема кодирования
требует применения кодовых слов с расстоянием
Хэмминга не менее N+1, а для исправления ошибок в N
битах необходима схема кодирования с расстоянием
Хэмминга между кодами не менее 2N+1.
7. Широко распространены коды с одиночным битом четности
• К каждым М бит добавляется 1 бит, значение которого
определяется четностью (или нечетностью) суммы этих М
бит. Так, например, для двухбитовых кодов 00, 01, 10, 11
кодами с контролем четности будут 000, 011, 101 и 110.
Если в процессе передачи один бит будет передан
неверно, четность кода из М+1 бита изменится.
• Добавление бита четности уменьшает вероятность
необнаруженной ошибки почти в 1000 раз. Использование
одного бита четности типично для асинхронного метода
передачи. В синхронных каналах чаще используется
вычисление и передача битов четности как для строк, так
и для столбцов передаваемого массива данных.
8. Штрих-коды (barcode).
• Банка консервированной кукурузы, на которой написан
штрих-код:
5 998483 710125
• Это код EAN-13 (тринадцать цифр). Правило для его
проверки такое: сложить цифры на четных позициях,
умножить сумму на три и добавь цифры на нечетных
позициях. Должно получиться число, которое делится на
десять:
9 + 8 + 8+ 7 + 0 + 2 = 34
5 + 9 + 4 + 3 + 1 + 1 + 5 = 28
34 * 3 + 28 = 130, делится на 10
• А чтобы это условие выполнялось, последнюю цифру, 5,
делают контрольной суммой.
9. Простой, короткий и быстрый (примерно в 10 раз быстрее CRC) способ подсчета контрольной суммы
• Берем по 4 байта из файла, и делаем с ними
логическую операцию XOR. То, что получится в
результате, — контрольная сумма.
• В этой контрольной сумме все байты
используются полностью, среди них нет более
значимых или менее значимых. Теоретическая
вероятность того, что контрольная сумма
окажется правильной для испорченного файла —
1 шанс на 2 ^ 32.
Контроль по четности достаточно эффективен для
выявления одиночных и множественных ошибок
в условиях, когда они являются независимыми.
10. CRC
• cyclic redundancy code, циклический избыточный
код — способ цифровой идентификации
некоторой последовательности данных, который
заключается в вычислении контрольного значения
её циклического избыточного кода.
• Простая формула: CRC = сообщение % полином
11. CRC
Циклический избыточный контроль (Cyclic Redundancy Check, CRC) является в
настоящее время наиболее популярным методом контроля в вычислительных
сетях (и не только в сетях, например, этот метод широко применяется при
записи данных на диски и дискеты). Метод основан на рассмотрении
исходных данных в виде одного многоразрядного двоичного числа.
Например, кадр стандарта Ethernet, состоящий из 1024 байт, будет
рассматриваться как одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается остаток от деления этого числа на
известный делитель R.
Обычно в качестве делителя выбирается семнадцати- или тридцати
трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2
байт) или 32 разряда (4 байт). При получении кадра данных снова
вычисляется остаток от деления на тот же делитель R, но при этом к данным
кадра добавляется и содержащаяся в нем контрольная сумма.
12. Алгоритм CRC
• Алгоритм CRC базируется на свойствах деления с остатком
двоичных многочленов, то есть является по сути остатком от
деления многочлена, соответствующего входным данным, на
некий фиксированный порождающий многочлен.
• Каждой конечной последовательности битов
взаимооднозначно сопоставляется двоичный многочлен ,
последовательность коэффициентов которого таким образом
представляет собой исходную последовательность. Например,
десятичное число 90 (1011010 в двоичной записи)
соответствует многочлену:
13. Операция деления на примитивный полином эквивалентна следующей схеме:
• Пусть выбран примитивный полином, задающий цикл де Брейна
0010111001011100… и блок данных 0111110, построена таблица, верхняя
строка заполнена блоком данных, а нижние строки — смещения на 0,1,2
бит цикла де Брейна
• Тогда контрольная сумма будет равна операции XOR тех столбцов, над
которыми в верхней строке расположена 1. В этом случае, 010 xor 101 xor
011 xor 111 xor 110 = 101 (CRC).
14. При «правильном» выборе порождающего многочлена (делителя), остатки от деления на него будут обладать нужными свойствами
• хорошей перемешиваемостью и
• быстрым алгоритмом вычисления.
• Второе обеспечивается тем, что степень
порождающего многочлена обычно
пропорциональна длине байта или машинного
слова (например 8, 16 или 32).
15. Формализованный алгоритм расчёта CRC16
• Для получения контрольной суммы, необходимо сгенерировать
полином. Основное требование к полиному: его степень должна быть
равна длине контрольной суммы в битах. При этом старший бит
полинома обязательно должен быть равен «1».
• Из файла берется первое слово. В зависимости от того, равен ли
старший бит этого слова «1» или нет, выполняем (или нет) операцию
XOR на полином. Полученный результат, вне зависимости от того,
выполнялась ли операция XOR, сдвигаем на один бит влево (то есть
умножаем на 2). После сдвига (умножения) теряется старый старший
бит, а младший бит освобождается (обнуляется). На место младшего
бита загружается очередной бит из файла. Операция повторяется до
тех пор, пока не загрузится последний бит файла. После прохождения
всего файла, в слове остается остаток, который и является
контрольной суммой.
16. Используя описанную выше возможность замены полинома на бинарную последовательность, рассмотрим алгоритм подсчета контрольной
суммы CRC8:
Исходный массив данных: 1001 0110 0100 1011.
Порождающий многочлен: 1101 0101.
17. В Ethernet Вычисление crc производится аппаратно.
Реализация аппаратного расчета CRC для образующего полинома
B(x)= 1 + x2 + x3 +x5 + x7.
В этой схеме входной код приходит слева.
18. Эффективность CRC для обнаружения ошибок на многие порядки выше простого контроля четности.
• В настоящее время стандартизовано несколько типов
образующих полиномов. Для оценочных целей можно
считать, что вероятность невыявления ошибки в случае
использования CRC, если ошибка на самом деле имеет
место, равна (1/2)r, где r — степень образующего полинома.
• CRC-12
x12 + x11 + x3 + x2 + x1 + 1
• CRC-16
x16 + x15 + x2 + 1
• CRC-CCITT
x16 + x12 + x5 + 1
19.
20. Обнаружение ошибок
• Обнаружение ошибок
21. Коды Рида-Соломона были предложены в 1960 Ирвином Ридом (Irving S. Reed) и Густавом Соломоном (Gustave Solomon), являвшимися
сотрудниками Линкольнской лаборатории
Популярным кодом Рида-Соломона является
RS(255,223) с 8-битными символами. Каждое
кодовое слово содержит 255 байт, из которых 223
являются информационными и 32 байтами
четности.
Декодер может исправить любые 16 символов
с ошибками в кодовом слове: то есть, ошибки
могут быть исправлены, если число искаженных
байт не превышает 16.
22. Коррекция ошибок
• Процедура коррекции ошибок предполагает два
совмещенных процесса:
• обнаружение ошибки и
• определение места (идентификация сообщения и позиции
в сообщении).
• После решения этих двух задач, исправление тривиально –
надо инвертировать значение ошибочного бита.
В наземных каналах связи, где вероятность ошибки
невелика, обычно используется метод детектирования
ошибок и повторной пересылки фрагмента, содержащего
дефект.
• Для спутниковых каналов с типичными для них большими
задержками системы коррекции ошибок становятся
привлекательными. Здесь используют коды Хэмминга или
коды свертки.
23.
• Код Хэмминга представляет собой
блочный код, который позволяет
выявить и исправить ошибочно
переданный бит в пределах переданного
блока. Обычно код Хэмминга
характеризуется двумя целыми числами,
например, (11,7) используемый при
передаче 7-битных ASCII-кодов.
Предполагается, что имела место
ошибка в одном бите и что ошибка в
двух или более битах существенно
менее вероятна.
24.
• Например, пусть возможны следующие
правильные коды (все они, кроме первого и
последнего, отстоят друг от друга на расстояние
4):
• 00000000
11110000
00001111
11111111
• При получении кода 00000111 можно
предположить, что правильное значение
полученного кода равно 00001111. Другие коды
отстоят от полученного на большее расстояние
Хэмминга.
25. В общем случае код имеет N=M+C бит
• Пусть М=4, а N=7, тогда слово-сообщение будет иметь вид: M4, M3,
M2, C3, M1, C2, C1. Теперь попытаемся вычислить значения С1, С2,
С3. Для этого используются уравнения, где все операции
представляют собой сложение по модулю 2:
• С1 = М1 + М2 + М4
С2 = М1 + М3 + М4
С3 = М2 + М3 + М4
• Для определения того, доставлено ли сообщение без ошибок,
вычисляем следующие выражения (сложение по модулю 2):
• С11 = С1 + М4 + М2 + М1
С12 = С2 + М4 + М3 + М1
С13 = С3 + М4 + М3 + М2
• С11С12С13 Значение
• 1 2 4
Позиция бит
• 0 0 0
Ошибок нет
• 0 0 1
Бит С3 не верен
• 0 1 0
Бит С2 не верен
• 0 1 1
Бит М3 не верен
• 1 0 0
Бит С1 не верен
• 1 0 1
Бит М2 не верен
• 1 1 0
Бит М1 не верен
• 1 1 1
Бит М4 не верен
26. Циклические коды BCH (Bose-Chadhuri-Hocquenghem).
• Пусть общее число бит в блоке равно N, из них
полезную информацию несут в себе K бит, тогда в
случае ошибки, имеется возможность исправить
m бит. Таблица содержит зависимость m от N и K
для кодов ВСН.
Общее число бит N Число полезных бит М Число исправляемых бит m
31
26
1
21
2
16
3
63
57
1
51
2
45
3
127
120
1
113
2
106
3
27. Процент обнаруживаемых ошибок
• Число полезных бит М
• 32
• 40
• 48
Число избыточных бит (n-m)
6
48%
36%
23%
7
74%
68%
62%
8
89%
84%
81%
28. Рассмотрим пример передачи кода буквы s = 0x073 = 1110011 с использованием кода Хэмминга (11,7).
• Позиция бита: 11 10 9 8 7 6 5 4 3 2 1
• Значение бита: 1 1 1 * 0 0 1 * 1 * *
• 11 =1011 10 =1010 09 =1001 05 =0101 03 =0011
контр.сумма=1110
• Приемник получит код
• Позиция бита: 11 10 9 8 7 6 5 4 3 2 1
• Значение бита: 1 1 1 1 0 0 1 1 1 1 0
Просуммируем снова коды позиций ненулевых битов и получим нуль.
• 11 =1011 10 =1010 09 =1001 08 =1000 05 =0101
04 =0100 03 =0011 02 =0010 сумма =0000
29. Коды Рида – Соломона недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора
являются не
биты, а группы битов (блоки). Очень
распространены коды Рида-Соломона,
работающие с байтами (октетами).
Код RS(255,223) может исправить до 16 ошибок в символах.
В худшем случае, могут иметь место 16 битовых ошибок в
разных символах (байтах). В лучшем случае,
корректируются 16 полностью неверных байт, при этом
исправляется 16 x 8=128 битовых ошибок.
30. Циклы де Брейна названы по имени голландского математика Н. Г. де Брeйна (англ.) (англ. Nicolaas Govert de Bruijn), который
Циклы де Брейна названы по имени голландского математика Н. Г. де Брeйна (англ.) (англ. Nicolaas Govert de
Bruijn), который рассматривал их в 1946 году
Примеры циклов де Брейна для k= 2 с
периодом 2, 4, 8, 16:
01 (содержит подпоследовательности 0 и
1)
0011 (содержит подпоследовательности
00, 01, 11, 10)
00010111 (000, 001, 010, 101, 011, 111,
110, 100)
0000100110101111
Перейти к контенту

§ 2. Передача данных ГДЗ по Информатике 11 класс. Углубленный уровень. В 2 ч. Поляков К.Ю.
7. Что такое бит чётности? В каких случаях с помощью бита чётности можно обнаружить ошибку, а в каких — нельзя?
Ответ
Бит чётности (англ. Parity bit) — контрольный бит в вычислительной технике и сетях передачи данных, служащий для проверки общей чётности двоичного числа (чётности количества единичных битов в числе). В последовательной передаче данных часто используется формат 7 бит данных, бит чётности, один или два стоповых бита. Такой формат аккуратно размещает все 7-битные ASCII символы в удобный 8-битный байт. Также допустимы другие форматы: 8 бит данных и бит чётности.
В длинной цепочке применение бита чётности позволяет обнаруживать нечётное число ошибок (1, 3, 5, …), а ошибки в чётном количестве разрядов остаются незамеченными. Контроль с помощью бита чётности применяется для небольших блоков данных (чаще всего — для каждого отдельного байта) и хорошо работает тогда, когда отдельные ошибки при передаче независимы одна от другой и встречаются редко.
Если при передаче неверно передан только один из битов, количество единиц в сообщении стало нечётным, это и служит признаком ошибки при передаче. Однако исправить ошибку нельзя, потому что непонятно, в каком именно разряде она случилась. Если же изменилось два бита, чётность не меняется, и такая ошибка не обнаруживается.