Построение кодов обнаружения ошибок (защитных кодов)
В процессе
преобразования информации, представленной
в закодированной форме, часто возникают
ошибки, связанные со сбоями в работе
технических средств преобразования
информации ,а также допущенные людьми
при работе с компьютером и оргтехникой.
Построение кодов
обнаружения ошибок основано на трех
основных принципах:
1) Использование
признаков делимости
2) Запрещение
использования определенной части
кодовых слов.
3) Запрещение
использования определенных символов.
1. Построение кодов обнаружения ошибок с использованием признака делимости числа
Суть
данного способа построения кодов
обнаружения ошибок состоит в следующем:
допустим необходимо построить код
обнаружения ошибок для табельного
номера, состоящего из четырех цифр:
5621 а)
в данном случае выбирается число М,
называемое модулем (желательно простое
целое число) и исходное кодовое число
делится на модуль М. Например, М=9
5621
: 9
54
22
18
41
36
5
и
остаток от деления (в данном случае
равный 5) дописывается справа от исходного
кодового слова. Таким образом, табельный
номер примет вид 56215,
где первые четыре разряда информационные,
а последний контрольный.
б)
контроль по модулю «10». Допустим,
необходимо построить код обнаружения
ошибок для номенклатурного номера
материала 62154. Находим сумму чисел:
6+2+1+5+4=18.
Далее
определяется ближайшее, большее 18, число
кратное 10. Это число 20. Определяется
разность этих чисел 20-18=2. Полученное
значение и является контрольным разрядом.
Таким образом, будет обрабатываться
на всех стадиях число 621542,
содержащее 5 информационных разрядов
и 1 контрольный. В данном случае
присутствует избыточная информация,
введение которой оправдано необходимостью
контроля правильности преобразования
информации. Однако, данный способ не
позволяет обнаружить ошибки, связанные
с перестановкой цифр.
Для
этого существует способ построения
кодов обнаружения ошибок с
учетом весовых коэффициентов.
Суть которого в том, что на каждый разряд
числа «навешивается» весовой коэффициент.
Далее применяется контроль по модулю
«10», только с использованием весовых
коэффициентов числа.
Например, требуется
построить код инвентарного номера
оборудования 190624. Для каждого разряда
числа вводится весовой коэффициент,
причем, чем старше разряд, тем больше
коэффициент. Данное число имеет весовые
коэффициенты:
6
5 4 3 2 1
1
9 0 6 2 4
Находится
сумма цифр числа, умноженных на весовые
коэффициенты: 1*6+9*5+0*4+6*3+2*2+4*1=77.
Находится разность между ближайшим
большим числом, кратным 10, и данным
числом 80-77=3 и эта разность дописывается
к исходному кодовому числу в качестве
контрольного разряда: 1906243.
Построение
защитных кодов для информации,
представленной в двоичном коде
Одним
из основных способов контроля двоичной
информации является контроль «на
ЧЕТ». В
исходном кодовом числе подсчитывается
количество единиц, если оно является
нечетным, в качестве контрольного
разряда к числу приписывается 1,
если четным — 0.
В полученном кодовом слове число единиц
должно быть обязательно четным.
Например: а)
110011 — исходное кодовое слово
1100110
— кодовое слово с контрольным разрядом
б)
11001 — исходное кодовое слово
110011
— кодовое слово с контрольным разрядом
Коды
обнаружения ошибок, построенные по
принципу применения кодовых словарей
Данный способ
построения кодов обнаружения ошибок
заключается в использовании слов,
входящих в специальным образом
составленные кодовые словари. Только
данные слова являются разрешенными,
все остальные запрещенными для
использования. Если кодовое слово,
подлежащее преобразованию, содержится
в кодовом словаре, значит информация
преобразуется без ошибок, если данного
слова в кодовом словаре нет, значит
выдается сообщение об ошибке. Кодовые
словари могут быть построены на 10 и на
100 слов.
Пример построения
кодового словаря на 10 слов:01 12 23 34 45 56 67
78 89 90. Все остальные двузначные слова
являются запрещенными. В данном случае
коэффициент использования информационной
емкости кода равен: 10/99=0,1.
Здесь
10- количество слов в словаре , 99 —
максимально возможное количество цифр
в словаре.
Например, если
получено при передаче информации слово
13, то выдается сообщение об ошибке, т.к.
данное слово в кодовом словаре
отсутствует. В
случае одиночной ошибки она может быть
исправлена: это может быть либо слово
23,либо — 12.
Кодовый словарь
на 100 слов строится следующим образом:
|
Десятки |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
0 1 2 3 4 5 6 7 8 9 |
001 012 023 034 045 056 067 078 089 090 |
102 113 124 135 146 157 168 179 180 191 |
203 214 225 236 247 258 269 270 281 292 |
304 315 326 337 348 359 360 371 382 393 |
405 416 427 438 449 450 461 472 483 494 |
506 517 528 539 540 551 562 573 584 595 |
607 618 629 630 641 652 663 674 685 696 |
708 719 720 731 742 753 764 775 786 797 |
809 810 821 832 843 854 865 876 887 898 |
900 912 923 934 945 956 967 978 989 999 |
Проверка
правильности переданных кодовых слов
выполняется несколькими способами.
Основные способы контроля приведены
ниже:
-
похожие
по написанию цифры кодового слова (3 и
8, 5 и 6, 9 и 0, 6 и 9 и т.д.) ; -
ошибки,
совершенные при вводе с клавиатуры
(рядом расположенные клавиши: с 1 рядом
2 и 4, с 5 – рядом 2, 4 и 6 и т.д.); -
перестановка
цифр числа при вводе с клавиатуры.
Коды
обнаружения ошибок, построенные по
принципу запрещения использования
определенной части символов
Очень часто в
процессе преобразования информации
возникают ошибки, связанные с нечетким
заполнением первичных документов или
с нажатием на устройствах передачи или
подготовки данных ошибочно рядом
расположенной клавиши. При нечетком
заполнении документов бывает сложно
различить похожие по начертанию цифры
4 и 7, 0 и 6, 0 и 9. Для избежания подобного
рода ошибок, а также устранения возможности
ошибок при нажатии рядом расположенных
на клавиатуре клавиш запрещается
использовать для построения кодовых
слов следующие символы: например: 0,6,9.
Все остальные символы являются
разрешенными. В случае, если в процессе
преобразования информации возникает
кодовое слово, содержащее разрешенные
символы, выдается сообщение об ошибке.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Кодирование и защита от ошибок
Существует три наиболее распространенных орудия борьбы с ошибками в процессе передачи данных:
- коды обнаружения ошибок;
- коды с коррекцией ошибок, называемые также схемами прямой коррекции ошибок (Forward Error Correction — FEC);
- протоколы с автоматическим запросом повторной передачи (Automatic Repeat Request — ARQ).
Код обнаружения ошибок позволяет довольно легко установить наличие ошибки. Как правило, подобные коды используются совместно с определенными протоколами канального или транспортного уровней, имеющими схему ARQ. В схеме ARQ приемник попросту отклоняет блок данных, в котором была обнаружена ошибка, после чего передатчик передает этот блок повторно. Коды с прямой коррекцией ошибок позволяют не только обнаружить ошибки, но и исправить их, не прибегая к повторной передаче. Схемы FEC часто используются в беспроводной передаче, где повторная передача крайне неэффективна, а уровень ошибок довольно высок.
1) Методы обнаружения ошибок
Методы обнаружения ошибок основаны на передаче в составе блока данных избыточной служебной информации, по которой можно судить с некоторой степенью вероятности о достоверности принятых данных.
Избыточную служебную информацию принято называть контрольной суммой, или контрольной последовательностью кадра (Frame Check Sequence, FCS). Контрольная сумма вычисляется как функция от основной информации, причем не обязательно путем суммирования. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей стороной, делает вывод о том, что данные были переданы через сеть корректно. Рассмотрим несколько распространенных алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же время это наименее мощный алгоритм контроля, так как с его помощью можно обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех битов контролируемой информации. Нетрудно заметить, что для информации, состоящей из нечетного числа единиц, контрольная сумма всегда равна 1, а при четном числе единиц — 0. Например, для данных 100101011 результатом контрольного суммирования будет значение 1. Результат суммирования также представляет собой один дополнительный бит данных, который пересылается вместе с контролируемой информацией. При искажении в процессе пересылки любого бита исходных данных (или контрольного разряда) результат суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные данные. Поэтому контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод редко применяется в компьютерных сетях из-за значительной избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного выше метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд подсчитывается отдельно для каждой строки и для каждого столбца матрицы. Этот метод обнаруживает значительную часть двойных ошибок, однако обладает еще большей избыточностью. Он сейчас также почти не применяется при передаче информации по сети.
Циклический избыточный контроль (Cyclic Redundancy Check — CRC) является в настоящее время наиболее популярным методом контроля в вычислительных сетях (и не только в сетях; в частности, этот метод широко применяется при записи данных на гибкие и жесткие диски). Метод основан на рассмотрении исходных данных в виде одного многоразрядного двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт, будет рассматриваться как одно число, состоящее из 8192 бит. Контрольной информацией считается остаток от деления этого числа на известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцатитрехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт) или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток от деления на тот же делитель R, но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма.
Если остаток от деления на R равен нулю, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо шире, чем у методов контроля по паритету. Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном числе битов. Метод также обладает невысокой степенью избыточности. Например, для кадра Ethernet размером 1024 байта контрольная информация длиной 4 байта составляет только 0,4 %.
2) Методы коррекции ошибок
Техника кодирования, которая позволяет приемнику не только понять, что присланные данные содержат ошибки, но и исправить их, называется прямой коррекцией ошибок (Forward Error Correction — FEC). Коды, обеспечивающие прямую коррекцию ошибок, требуют введения большей избыточности в передаваемые данные, чем коды, которые только обнаруживают ошибки.
При применении любого избыточного кода не все комбинации кодов являются разрешенными. Например, контроль по паритету делает разрешенными только половину кодов. Если мы контролируем три информационных бита, то разрешенными 4-битными кодами с дополнением до нечетного количества единиц будут:
000 1, 001 0, 010 0, 011 1, 100 0, 101 1, 110 1, 111 0, то есть всего 8 кодов из 16 возможных.
Для того чтобы оценить количество дополнительных битов, необходимых для исправления ошибок, нужно знать так называемое расстояние Хемминга между разрешенными комбинациями кода. Расстоянием Хемминга называется минимальное число битовых разрядов, в которых отличается любая пара разрешенных кодов. Для схем контроля по паритету расстояние Хемминга равно 2.
Можно доказать, что если мы сконструировали избыточный код с расстоянием Хемминга, равным n, такой код будет в состоянии распознавать (n-1) -кратные ошибки и исправлять (n-1)/2 -кратные ошибки. Так как коды с контролем по паритету имеют расстояние Хемминга, равное 2, они могут только обнаруживать однократные ошибки и не могут исправлять ошибки.
Коды Хемминга эффективно обнаруживают и исправляют изолированные ошибки, то есть отдельные искаженные биты, которые разделены большим количеством корректных битов. Однако при появлении длинной последовательности искаженных битов (пульсации ошибок) коды Хемминга не работают.
Наиболее часто в современных системах связи применяется тип кодирования, реализуемый сверхточным кодирующим устройством (Сonvolutional coder), потому что такое кодирование несложно реализовать аппаратно с использованием линий задержки (delay) и сумматоров. В отличие от рассмотренного выше кода, который относится к блочным кодам без памяти, сверточный код относится к кодам с конечной памятью (Finite memory code); это означает, что выходная последовательность кодера является функцией не только текущего входного сигнала, но также нескольких из числа последних предшествующих битов. Длина кодового ограничения (Constraint length of a code) показывает, как много выходных элементов выходит из системы в пересчете на один входной. Коды часто характеризуются их эффективной степенью (или коэффициентом) кодирования (Code rate). Вам может встретиться сверточный код с коэффициентом кодирования 1/2.
Этот коэффициент указывает, что на каждый входной бит приходится два выходных. При сравнении кодов обращайте внимание на то, что, хотя коды с более высокой эффективной степенью кодирования позволяют передавать данные с более высокой скоростью, они, соответственно, более чувствительны к шуму.
В беспроводных системах с блочными кодами широко используется метод чередования блоков. Преимущество чередования состоит в том, что приемник распределяет пакет ошибок, исказивший некоторую последовательность битов, по большому числу блоков, благодаря чему становится возможным исправление ошибок. Чередование выполняется с помощью чтения и записи данных в различном порядке. Если во время передачи пакет помех воздействует на некоторую последовательность битов, то все эти биты оказываются разнесенными по различным блокам. Следовательно, от любой контрольной последовательности требуется возможность исправить лишь небольшую часть от общего количества инвертированных битов.
3) Методы автоматического запроса повторной передачи
В простейшем случае защита от ошибок заключается только в их обнаружении. Система должна предупредить передатчик об обнаружении ошибки и необходимости повторной передачи. Такие процедуры защиты от ошибок известны как методы автоматического запроса повторной передачи (Automatic Repeat Request — ARQ). В беспроводных локальных сетях применяется процедура «запрос ARQ с остановками» (stop-and-wait ARQ).
В этом случае источник, пославший кадр, ожидает получения подтверждения (Acknowledgement — ACK), или, как еще его называют, квитанции, от приемника и только после этого посылает следующий кадр. Если же подтверждение не приходит в течение тайм-аута, то кадр (или подтверждение) считается утерянным и его передача повторяется. На
рис.
1.13 видно, что в этом случае производительность обмена данными ниже потенциально возможной; хотя передатчик и мог бы послать следующий кадр сразу же после отправки предыдущего, он обязан ждать прихода подтверждения.
Канальный уровень должен обнаруживать ошибки передачи данных, связанные с
искажением бит в принятом кадре данных или с потерей кадра, и по возможности их
корректировать.
Большая часть протоколов канального уровня выполняет только первую задачу —
обнаружение ошибок, считая, что корректировать ошибки, то есть повторно
передавать данные, содержавшие искаженную информацию, должны протоколы верхних
уровней. Так работают такие популярные протоколы локальных сетей, как Ethernet,
Token Ring, FDDI и другие. Однако существуют протоколы канального уровня, например
LLC2 или LAP-B, которые самостоятельно решают задачу восстановления искаженных
или потерянных кадров.
Очевидно, что протоколы должны работать наиболее эффективно в типичных
условиях работы сети. Поэтому для сетей, в которых искажения и потери кадров являются
очень редкими событиями, разрабатываются протоколы типа Ethernet, в которых не
предусматриваются процедуры устранения ошибок. Действительно, наличие процедур
восстановления данных потребовало бы от конечных узлов дополнительных
вычислительных затрат, которые в условиях надежной работы сети являлись бы
избыточными.
Напротив, если в сети искажения и потери случаются часто, то желательно уже
на канальном уровне использовать протокол с коррекцией ошибок, а не оставлять
эту работу протоколам верхних уровней. Протоколы верхних уровней, например
транспортного или прикладного, работая с большими тайм-аутами, восстановят
потерянные данные с большой задержкой. В глобальных сетях первых поколений,
например сетях Х.25, которые работали через ненадежные каналы связи, протоколы
канального уровня всегда выполняли процедуры восстановления потерянных и
искаженных кадров.
Поэтому нельзя считать, что один протокол лучше другого потому, что он
восстанавливает ошибочные кадры, а другой протокол — нет. Каждый протокол должен
работать в тех условиях, для которых он разработан.
Методы обнаружения ошибок
Все методы обнаружения ошибок основаны на передаче в составе кадра данных
служебной избыточной информации, по которой можно судить с некоторой степенью
вероятности о достоверности принятых данных. Эту служебную информацию принято
называть контрольной суммой или (последовательностью
контроля кадра — Frame Check Sequence, FCS). Контрольная сумма вычисляется
как функция от основной информации, причем необязательно только путем суммирования.
Принимающая сторона повторно вычисляет контрольную сумму кадра по известному
алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей
стороной, делает вывод о том, что данные были переданы через сеть корректно.
Существует несколько распространенных алгоритмов вычисления контрольной
суммы, отличающихся вычислительной сложностью и способностью обнаруживать
ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же
время это наименее мощный алгоритм контроля, так как с его помощью можно
обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в
суммировании по модулю 2 всех бит контролируемой информации. Например, для
данных 100101011 результатом контрольного суммирования будет значение 1.
Результат суммирования также представляет собой один бит данных, который
пересылается вместе с контролируемой информацией. При искажении при пересылке
любого одного бита исходных данных (или контрольного разряда) результат суммирования
будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные
данные. Поэтому контроль по паритету применяется к небольшим порциям данных,
как правило, к каждому байту, что дает коэффициент избыточности для этого
метода 1/8. Метод редко применяется в вычислительных сетях из-за его большой
избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию
описанного выше метода. Его отличие состоит в том, что исходные данные
рассматриваются в виде матрицы, строки которой составляют байты данных.
Контрольный разряд подсчитывается отдельно для каждой строки и для каждого
столбца матрицы. Этот метод обнаруживает большую часть двойных ошибок, однако
обладает еще большей избыточностью. На практике сейчас также почти не
применяется.
Циклический избыточный контроль (Cyclic Redundancy Check, CRC) является в настоящее время наиболее
популярным методом контроля в вычислительных сетях (и не только в сетях,
например, этот метод широко применяется при записи данных на диски и дискеты).
Метод основан на рассмотрении исходных данных в виде одного многоразрядного
двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт,
будет рассматриваться как одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается остаток от деления этого числа на
известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцати
трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт)
или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток
от деления на тот же делитель R, но при этом к данным кадра добавляется и
содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю1 (1 Существуетнесколько
модифицированная процедура вычисления остатка, приводящая к получению в случае
отсутствия ошибок известного ненулевого остатка, что является более надежным
показателем корректности.), то делается вывод об отсутствии ошибок в полученном
кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его
диагностические возможности гораздо выше, чем у методов контроля по паритету.
Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном
числе бит. Метод обладает также невысокой степенью избыточности. Например, для
кадра Ethernet размером в 1024 байт контрольная информация длиной в 4 байт
составляет только 0,4 %.
Методы восстановления искаженных и потерянных кадров
Методы коррекции ошибок в вычислительных сетях основаны на повторной
передаче кадра данных в том случае, если кадр теряется и не доходит до адресата
или приемник обнаружил в нем искажение информации. Чтобы убедиться в
необходимости повторной передачи данных, отправитель нумерует отправляемые
кадры и для каждого кадра ожидает от приемника так называемой положительной
квитанции — служебного кадра, извещающего о том, что исходный кадр был
получен и данные в нем оказались корректными. Время этого ожидания ограничено —
при отправке каждого кадра передатчик запускает таймер, и, если по его
истечении положительная квитанция на получена, кадр считается утерянным.
Приемник в случае получения кадра с искаженными данными может отправить отрицательную
квитанцию — явное указание на то, что данный кадр нужно передать
повторно.
Существуют два подхода к организации процесса обмена квитанциями: с
простоями и с организацией «окна».
Метод с простоями (Idle Source) требует, чтобы источник, пославший кадр, ожидал получения квитанции
(положительной или отрицательной) от приемника и только после этого посылал
следующий кадр (или повторял искаженный). Если же квитанция не приходит в
течение тайм-аута, то кадр (или квитанция) считается утерянным и его передача
повторяется. На рис. 2.24, а видно, что в этом случае производительность обмена
данными существенно снижается, — хотя передатчик и мог бы послать следующий
кадр сразу же после отправки предыдущего, он обязан ждать прихода квитанции.
Снижение производительности этого метода коррекции особенно заметно на
низкоскоростных каналах связи, то есть в территориальных сетях.

Рис. 2.24. Методы восстановления искаженных и
потерянных кадров
Второй метод называется методом «скользящего окна» (sliding
window). В этом методе для повышения коэффициента использования линии
источнику разрешается передать некоторое количество кадров в непрерывном
режиме, то есть в максимально возможном для источника темпе, без получения на
эти кадры положительных ответных квитанций. (Далее, где это не искажает
существо рассматриваемого вопроса, положительные квитанции для краткости будут
называться просто «квитанциями».) Количество кадров, которые разрешается
передавать таким образом, называется размером окна. Рисунок 2.24, б
иллюстрирует данный метод для окна размером в W кадров.
В начальный момент, когда еще не послано ни одного кадра, окно определяет
диапазон кадров с номерами от 1 до W включительно. Источник начинает передавать
кадры и получать в ответ квитанции. Для простоты предположим, что квитанции
поступают в той же последовательности, что и кадры, которым они соответствуют.
В момент t1 при получении первой квитанции К1 окно сдвигается
на одну позицию, определяя новый диапазон от 2 до (W+1).
Процессы отправки кадров и получения квитанций идут достаточно независимо
друг от друга. Рассмотрим произвольный момент времени tn, когда источник
получил квитанцию на кадр с номером n. Окно сдвинулось вправо и определило
диапазон разрешенных к передаче кадров от (n+1) до (W+n). Все множество кадров,
выходящих из источника, можно разделить на перечисленные ниже группы (рис.
2.24, б).
- Кадры с номерами от 1 доп. уже были отправлены и квитанции на них
получены, то есть они находятся за пределами окна слева. - Кадры, начиная с номера (п+1) и кончая номером
(W+n), находятся в пределах окна и
потому могут быть отправлены не дожидаясь прихода какой-либо квитанции.
Этот диапазон может быть разделен еще на два поддиапазона: - кадры с номерами от (n+1) до
т, которые уже отправлены, но квитанции на них еще не получены; - кадры с номерами от m до
(W+n), которые пока не отправлены, хотя запрета на это нет. - Все кадры с номерами, большими или равными
(W+n+1), находятся за пределами окна
справа и поэтому пока не могут быть отправлены.
Перемещение окна вдоль последовательности номеров кадров показано на рис.
2.24, в. Здесь t0 — исходный момент, t1 и tn —
моменты прихода квитанций на первый и n-й кадр соответственно. Каждый раз,
когда приходит квитанция, окно сдвигается влево, но его размер при этом не
меняется и остается равным W. Заметим, что хотя в данном примере размер окна в
процессе передачи остается постоянным, в реальных протоколах (например, TCP)
можно встретить варианты данного алгоритма с изменяющимся размером окна.
Итак, при отправке кадра с номером n источнику разрешается передать еще W-1
кадров до получения квитанции на кадр n, так что в сеть последним уйдет кадр с
номером (W+n-1). Если же за это время квитанция на кадр n так и не пришла, то
процесс передачи приостанавливается, и по истечении некоторого тайм-аута кадр n
(или квитанция на него) считается утерянным, и он передается снова.
Если же поток квитанций поступает более-менее регулярно, в пределах допуска
в W кадров, то скорость обмена достигает максимально возможной величины для
данного канала и принятого протокола.
Метод скользящего окна более сложен в реализации, чем метод с простоями,
так как передатчик должен хранить в буфере все кадры, на которые пока не
получены положительные квитанции. Кроме того, требуется отслеживать несколько
параметров алгоритма: размер окна W, номер кадра, на который получена
квитанция, номер кадра, который еще можно передать до получения новой
квитанции.
Приемник может не посылать квитанции на каждый принятый корректный кадр.
Если несколько кадров пришли почти одновременно, то приемник может послать
квитанцию только на последний кадр. При этом подразумевается, что все
предыдущие кадры также дошли благополучно.
Некоторые методы используют отрицательные квитанции. Отрицательные
квитанции бывают двух типов — групповые и избирательные. Групповая квитанция
содержит номер кадра, начиная с которого нужно повторить передачу всех кадров,
отправленных передатчиком в сеть. Избирательная отрицательная квитанция требует
повторной передачи только одного кадра.
Метод скользящего окна реализован во многих протоколах: LLC2, LAP-B, X.25,
TCP, Novell NCP Burst Mode.
Метод с простоями является частным случаем метода скользящего окна, когда
размер окна равен единице.
Метод скользящего окна имеет два параметра, которые могут заметно влиять на
эффективность передачи данных между передатчиком и приемником, — размер окна и
величина тайм-аута ожидания квитанции. В надежных сетях, когда кадры искажаются
и теряются редко, для повышения скорости обмена данными размер окна нужно
увеличивать, так как при этом передатчик будет посылать кадры с меньшими
паузами. В ненадежных сетях размер окна следует уменьшать, так как при частых
потерях и искажениях кадров резко возрастает объем вторично передаваемых через
сеть кадров, а значит, пропускная способность сети будет расходоваться во
многом вхолостую — полезная пропускная способность сети будет падать.
Выбор тайм-аута зависит не от надежности сети, а от задержек передачи
кадров сетью.
Во многих реализациях метода скользящего окна величина окна и тайм-аут
выбираются адаптивно, в зависимости от текущего состояния сети.
Построение кодов обнаружения ошибок (защитных кодов)
В процессе
преобразования информации, представленной
в закодированной форме, часто возникают
ошибки, связанные со сбоями в работе
технических средств преобразования
информации ,а также допущенные людьми
при работе с компьютером и оргтехникой.
Построение кодов
обнаружения ошибок основано на трех
основных принципах:
1) Использование
признаков делимости
2) Запрещение
использования определенной части
кодовых слов.
3) Запрещение
использования определенных символов.
1. Построение кодов обнаружения ошибок с использованием признака делимости числа
Суть
данного способа построения кодов
обнаружения ошибок состоит в следующем:
допустим необходимо построить код
обнаружения ошибок для табельного
номера, состоящего из четырех цифр:
5621 а)
в данном случае выбирается число М,
называемое модулем (желательно простое
целое число) и исходное кодовое число
делится на модуль М. Например, М=9
5621
: 9
54
22
18
41
36
5
и
остаток от деления (в данном случае
равный 5) дописывается справа от исходного
кодового слова. Таким образом, табельный
номер примет вид 56215,
где первые четыре разряда информационные,
а последний контрольный.
б)
контроль по модулю «10». Допустим,
необходимо построить код обнаружения
ошибок для номенклатурного номера
материала 62154. Находим сумму чисел:
6+2+1+5+4=18.
Далее
определяется ближайшее, большее 18, число
кратное 10. Это число 20. Определяется
разность этих чисел 20-18=2. Полученное
значение и является контрольным разрядом.
Таким образом, будет обрабатываться
на всех стадиях число 621542,
содержащее 5 информационных разрядов
и 1 контрольный. В данном случае
присутствует избыточная информация,
введение которой оправдано необходимостью
контроля правильности преобразования
информации. Однако, данный способ не
позволяет обнаружить ошибки, связанные
с перестановкой цифр.
Для
этого существует способ построения
кодов обнаружения ошибок с
учетом весовых коэффициентов.
Суть которого в том, что на каждый разряд
числа «навешивается» весовой коэффициент.
Далее применяется контроль по модулю
«10», только с использованием весовых
коэффициентов числа.
Например, требуется
построить код инвентарного номера
оборудования 190624. Для каждого разряда
числа вводится весовой коэффициент,
причем, чем старше разряд, тем больше
коэффициент. Данное число имеет весовые
коэффициенты:
6
5 4 3 2 1
1
9 0 6 2 4
Находится
сумма цифр числа, умноженных на весовые
коэффициенты: 1*6+9*5+0*4+6*3+2*2+4*1=77.
Находится разность между ближайшим
большим числом, кратным 10, и данным
числом 80-77=3 и эта разность дописывается
к исходному кодовому числу в качестве
контрольного разряда: 1906243.
Построение
защитных кодов для информации,
представленной в двоичном коде
Одним
из основных способов контроля двоичной
информации является контроль «на
ЧЕТ». В
исходном кодовом числе подсчитывается
количество единиц, если оно является
нечетным, в качестве контрольного
разряда к числу приписывается 1,
если четным — 0.
В полученном кодовом слове число единиц
должно быть обязательно четным.
Например: а)
110011 — исходное кодовое слово
1100110
— кодовое слово с контрольным разрядом
б)
11001 — исходное кодовое слово
110011
— кодовое слово с контрольным разрядом
Коды
обнаружения ошибок, построенные по
принципу применения кодовых словарей
Данный способ
построения кодов обнаружения ошибок
заключается в использовании слов,
входящих в специальным образом
составленные кодовые словари. Только
данные слова являются разрешенными,
все остальные запрещенными для
использования. Если кодовое слово,
подлежащее преобразованию, содержится
в кодовом словаре, значит информация
преобразуется без ошибок, если данного
слова в кодовом словаре нет, значит
выдается сообщение об ошибке. Кодовые
словари могут быть построены на 10 и на
100 слов.
Пример построения
кодового словаря на 10 слов:01 12 23 34 45 56 67
78 89 90. Все остальные двузначные слова
являются запрещенными. В данном случае
коэффициент использования информационной
емкости кода равен: 10/99=0,1.
Здесь
10- количество слов в словаре , 99 —
максимально возможное количество цифр
в словаре.
Например, если
получено при передаче информации слово
13, то выдается сообщение об ошибке, т.к.
данное слово в кодовом словаре
отсутствует. В
случае одиночной ошибки она может быть
исправлена: это может быть либо слово
23,либо — 12.
Кодовый словарь
на 100 слов строится следующим образом:
|
Десятки |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
0 1 2 3 4 5 6 7 8 9 |
001 012 023 034 045 056 067 078 089 090 |
102 113 124 135 146 157 168 179 180 191 |
203 214 225 236 247 258 269 270 281 292 |
304 315 326 337 348 359 360 371 382 393 |
405 416 427 438 449 450 461 472 483 494 |
506 517 528 539 540 551 562 573 584 595 |
607 618 629 630 641 652 663 674 685 696 |
708 719 720 731 742 753 764 775 786 797 |
809 810 821 832 843 854 865 876 887 898 |
900 912 923 934 945 956 967 978 989 999 |
Проверка
правильности переданных кодовых слов
выполняется несколькими способами.
Основные способы контроля приведены
ниже:
-
похожие
по написанию цифры кодового слова (3 и
8, 5 и 6, 9 и 0, 6 и 9 и т.д.) ; -
ошибки,
совершенные при вводе с клавиатуры
(рядом расположенные клавиши: с 1 рядом
2 и 4, с 5 – рядом 2, 4 и 6 и т.д.); -
перестановка
цифр числа при вводе с клавиатуры.
Коды
обнаружения ошибок, построенные по
принципу запрещения использования
определенной части символов
Очень часто в
процессе преобразования информации
возникают ошибки, связанные с нечетким
заполнением первичных документов или
с нажатием на устройствах передачи или
подготовки данных ошибочно рядом
расположенной клавиши. При нечетком
заполнении документов бывает сложно
различить похожие по начертанию цифры
4 и 7, 0 и 6, 0 и 9. Для избежания подобного
рода ошибок, а также устранения возможности
ошибок при нажатии рядом расположенных
на клавиатуре клавиш запрещается
использовать для построения кодовых
слов следующие символы: например: 0,6,9.
Все остальные символы являются
разрешенными. В случае, если в процессе
преобразования информации возникает
кодовое слово, содержащее разрешенные
символы, выдается сообщение об ошибке.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Построение кодов обнаружения ошибок (защитных кодов)
В процессе
преобразования информации, представленной
в закодированной форме, часто возникают
ошибки, связанные со сбоями в работе
технических средств преобразования
информации ,а также допущенные людьми
при работе с компьютером и оргтехникой.
Построение кодов
обнаружения ошибок основано на трех
основных принципах:
1) Использование
признаков делимости
2) Запрещение
использования определенной части
кодовых слов.
3) Запрещение
использования определенных символов.
1. Построение кодов обнаружения ошибок с использованием признака делимости числа
Суть
данного способа построения кодов
обнаружения ошибок состоит в следующем:
допустим необходимо построить код
обнаружения ошибок для табельного
номера, состоящего из четырех цифр:
5621 а)
в данном случае выбирается число М,
называемое модулем (желательно простое
целое число) и исходное кодовое число
делится на модуль М. Например, М=9
5621
: 9
54
22
18
41
36
5
и
остаток от деления (в данном случае
равный 5) дописывается справа от исходного
кодового слова. Таким образом, табельный
номер примет вид 56215,
где первые четыре разряда информационные,
а последний контрольный.
б)
контроль по модулю «10». Допустим,
необходимо построить код обнаружения
ошибок для номенклатурного номера
материала 62154. Находим сумму чисел:
6+2+1+5+4=18.
Далее
определяется ближайшее, большее 18, число
кратное 10. Это число 20. Определяется
разность этих чисел 20-18=2. Полученное
значение и является контрольным разрядом.
Таким образом, будет обрабатываться
на всех стадиях число 621542,
содержащее 5 информационных разрядов
и 1 контрольный. В данном случае
присутствует избыточная информация,
введение которой оправдано необходимостью
контроля правильности преобразования
информации. Однако, данный способ не
позволяет обнаружить ошибки, связанные
с перестановкой цифр.
Для
этого существует способ построения
кодов обнаружения ошибок с
учетом весовых коэффициентов.
Суть которого в том, что на каждый разряд
числа «навешивается» весовой коэффициент.
Далее применяется контроль по модулю
«10», только с использованием весовых
коэффициентов числа.
Например, требуется
построить код инвентарного номера
оборудования 190624. Для каждого разряда
числа вводится весовой коэффициент,
причем, чем старше разряд, тем больше
коэффициент. Данное число имеет весовые
коэффициенты:
6
5 4 3 2 1
1
9 0 6 2 4
Находится
сумма цифр числа, умноженных на весовые
коэффициенты: 1*6+9*5+0*4+6*3+2*2+4*1=77.
Находится разность между ближайшим
большим числом, кратным 10, и данным
числом 80-77=3 и эта разность дописывается
к исходному кодовому числу в качестве
контрольного разряда: 1906243.
Построение
защитных кодов для информации,
представленной в двоичном коде
Одним
из основных способов контроля двоичной
информации является контроль «на
ЧЕТ». В
исходном кодовом числе подсчитывается
количество единиц, если оно является
нечетным, в качестве контрольного
разряда к числу приписывается 1,
если четным — 0.
В полученном кодовом слове число единиц
должно быть обязательно четным.
Например: а)
110011 — исходное кодовое слово
1100110
— кодовое слово с контрольным разрядом
б)
11001 — исходное кодовое слово
110011
— кодовое слово с контрольным разрядом
Коды
обнаружения ошибок, построенные по
принципу применения кодовых словарей
Данный способ
построения кодов обнаружения ошибок
заключается в использовании слов,
входящих в специальным образом
составленные кодовые словари. Только
данные слова являются разрешенными,
все остальные запрещенными для
использования. Если кодовое слово,
подлежащее преобразованию, содержится
в кодовом словаре, значит информация
преобразуется без ошибок, если данного
слова в кодовом словаре нет, значит
выдается сообщение об ошибке. Кодовые
словари могут быть построены на 10 и на
100 слов.
Пример построения
кодового словаря на 10 слов:01 12 23 34 45 56 67
78 89 90. Все остальные двузначные слова
являются запрещенными. В данном случае
коэффициент использования информационной
емкости кода равен: 10/99=0,1.
Здесь
10- количество слов в словаре , 99 —
максимально возможное количество цифр
в словаре.
Например, если
получено при передаче информации слово
13, то выдается сообщение об ошибке, т.к.
данное слово в кодовом словаре
отсутствует. В
случае одиночной ошибки она может быть
исправлена: это может быть либо слово
23,либо — 12.
Кодовый словарь
на 100 слов строится следующим образом:
|
Десятки |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
0 1 2 3 4 5 6 7 8 9 |
001 012 023 034 045 056 067 078 089 090 |
102 113 124 135 146 157 168 179 180 191 |
203 214 225 236 247 258 269 270 281 292 |
304 315 326 337 348 359 360 371 382 393 |
405 416 427 438 449 450 461 472 483 494 |
506 517 528 539 540 551 562 573 584 595 |
607 618 629 630 641 652 663 674 685 696 |
708 719 720 731 742 753 764 775 786 797 |
809 810 821 832 843 854 865 876 887 898 |
900 912 923 934 945 956 967 978 989 999 |
Проверка
правильности переданных кодовых слов
выполняется несколькими способами.
Основные способы контроля приведены
ниже:
-
похожие
по написанию цифры кодового слова (3 и
8, 5 и 6, 9 и 0, 6 и 9 и т.д.) ; -
ошибки,
совершенные при вводе с клавиатуры
(рядом расположенные клавиши: с 1 рядом
2 и 4, с 5 – рядом 2, 4 и 6 и т.д.); -
перестановка
цифр числа при вводе с клавиатуры.
Коды
обнаружения ошибок, построенные по
принципу запрещения использования
определенной части символов
Очень часто в
процессе преобразования информации
возникают ошибки, связанные с нечетким
заполнением первичных документов или
с нажатием на устройствах передачи или
подготовки данных ошибочно рядом
расположенной клавиши. При нечетком
заполнении документов бывает сложно
различить похожие по начертанию цифры
4 и 7, 0 и 6, 0 и 9. Для избежания подобного
рода ошибок, а также устранения возможности
ошибок при нажатии рядом расположенных
на клавиатуре клавиш запрещается
использовать для построения кодовых
слов следующие символы: например: 0,6,9.
Все остальные символы являются
разрешенными. В случае, если в процессе
преобразования информации возникает
кодовое слово, содержащее разрешенные
символы, выдается сообщение об ошибке.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Кодирование и защита от ошибок
Существует три наиболее распространенных орудия борьбы с ошибками в процессе передачи данных:
- коды обнаружения ошибок;
- коды с коррекцией ошибок, называемые также схемами прямой коррекции ошибок (Forward Error Correction — FEC);
- протоколы с автоматическим запросом повторной передачи (Automatic Repeat Request — ARQ).
Код обнаружения ошибок позволяет довольно легко установить наличие ошибки. Как правило, подобные коды используются совместно с определенными протоколами канального или транспортного уровней, имеющими схему ARQ. В схеме ARQ приемник попросту отклоняет блок данных, в котором была обнаружена ошибка, после чего передатчик передает этот блок повторно. Коды с прямой коррекцией ошибок позволяют не только обнаружить ошибки, но и исправить их, не прибегая к повторной передаче. Схемы FEC часто используются в беспроводной передаче, где повторная передача крайне неэффективна, а уровень ошибок довольно высок.
1) Методы обнаружения ошибок
Методы обнаружения ошибок основаны на передаче в составе блока данных избыточной служебной информации, по которой можно судить с некоторой степенью вероятности о достоверности принятых данных.
Избыточную служебную информацию принято называть контрольной суммой, или контрольной последовательностью кадра (Frame Check Sequence, FCS). Контрольная сумма вычисляется как функция от основной информации, причем не обязательно путем суммирования. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей стороной, делает вывод о том, что данные были переданы через сеть корректно. Рассмотрим несколько распространенных алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же время это наименее мощный алгоритм контроля, так как с его помощью можно обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех битов контролируемой информации. Нетрудно заметить, что для информации, состоящей из нечетного числа единиц, контрольная сумма всегда равна 1, а при четном числе единиц — 0. Например, для данных 100101011 результатом контрольного суммирования будет значение 1. Результат суммирования также представляет собой один дополнительный бит данных, который пересылается вместе с контролируемой информацией. При искажении в процессе пересылки любого бита исходных данных (или контрольного разряда) результат суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные данные. Поэтому контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод редко применяется в компьютерных сетях из-за значительной избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного выше метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд подсчитывается отдельно для каждой строки и для каждого столбца матрицы. Этот метод обнаруживает значительную часть двойных ошибок, однако обладает еще большей избыточностью. Он сейчас также почти не применяется при передаче информации по сети.
Циклический избыточный контроль (Cyclic Redundancy Check — CRC) является в настоящее время наиболее популярным методом контроля в вычислительных сетях (и не только в сетях; в частности, этот метод широко применяется при записи данных на гибкие и жесткие диски). Метод основан на рассмотрении исходных данных в виде одного многоразрядного двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт, будет рассматриваться как одно число, состоящее из 8192 бит. Контрольной информацией считается остаток от деления этого числа на известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцатитрехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт) или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток от деления на тот же делитель R, но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма.
Если остаток от деления на R равен нулю, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо шире, чем у методов контроля по паритету. Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном числе битов. Метод также обладает невысокой степенью избыточности. Например, для кадра Ethernet размером 1024 байта контрольная информация длиной 4 байта составляет только 0,4 %.
2) Методы коррекции ошибок
Техника кодирования, которая позволяет приемнику не только понять, что присланные данные содержат ошибки, но и исправить их, называется прямой коррекцией ошибок (Forward Error Correction — FEC). Коды, обеспечивающие прямую коррекцию ошибок, требуют введения большей избыточности в передаваемые данные, чем коды, которые только обнаруживают ошибки.
При применении любого избыточного кода не все комбинации кодов являются разрешенными. Например, контроль по паритету делает разрешенными только половину кодов. Если мы контролируем три информационных бита, то разрешенными 4-битными кодами с дополнением до нечетного количества единиц будут:
000 1, 001 0, 010 0, 011 1, 100 0, 101 1, 110 1, 111 0, то есть всего 8 кодов из 16 возможных.
Для того чтобы оценить количество дополнительных битов, необходимых для исправления ошибок, нужно знать так называемое расстояние Хемминга между разрешенными комбинациями кода. Расстоянием Хемминга называется минимальное число битовых разрядов, в которых отличается любая пара разрешенных кодов. Для схем контроля по паритету расстояние Хемминга равно 2.
Можно доказать, что если мы сконструировали избыточный код с расстоянием Хемминга, равным n, такой код будет в состоянии распознавать (n-1) -кратные ошибки и исправлять (n-1)/2 -кратные ошибки. Так как коды с контролем по паритету имеют расстояние Хемминга, равное 2, они могут только обнаруживать однократные ошибки и не могут исправлять ошибки.
Коды Хемминга эффективно обнаруживают и исправляют изолированные ошибки, то есть отдельные искаженные биты, которые разделены большим количеством корректных битов. Однако при появлении длинной последовательности искаженных битов (пульсации ошибок) коды Хемминга не работают.
Наиболее часто в современных системах связи применяется тип кодирования, реализуемый сверхточным кодирующим устройством (Сonvolutional coder), потому что такое кодирование несложно реализовать аппаратно с использованием линий задержки (delay) и сумматоров. В отличие от рассмотренного выше кода, который относится к блочным кодам без памяти, сверточный код относится к кодам с конечной памятью (Finite memory code); это означает, что выходная последовательность кодера является функцией не только текущего входного сигнала, но также нескольких из числа последних предшествующих битов. Длина кодового ограничения (Constraint length of a code) показывает, как много выходных элементов выходит из системы в пересчете на один входной. Коды часто характеризуются их эффективной степенью (или коэффициентом) кодирования (Code rate). Вам может встретиться сверточный код с коэффициентом кодирования 1/2.
Этот коэффициент указывает, что на каждый входной бит приходится два выходных. При сравнении кодов обращайте внимание на то, что, хотя коды с более высокой эффективной степенью кодирования позволяют передавать данные с более высокой скоростью, они, соответственно, более чувствительны к шуму.
В беспроводных системах с блочными кодами широко используется метод чередования блоков. Преимущество чередования состоит в том, что приемник распределяет пакет ошибок, исказивший некоторую последовательность битов, по большому числу блоков, благодаря чему становится возможным исправление ошибок. Чередование выполняется с помощью чтения и записи данных в различном порядке. Если во время передачи пакет помех воздействует на некоторую последовательность битов, то все эти биты оказываются разнесенными по различным блокам. Следовательно, от любой контрольной последовательности требуется возможность исправить лишь небольшую часть от общего количества инвертированных битов.
3) Методы автоматического запроса повторной передачи
В простейшем случае защита от ошибок заключается только в их обнаружении. Система должна предупредить передатчик об обнаружении ошибки и необходимости повторной передачи. Такие процедуры защиты от ошибок известны как методы автоматического запроса повторной передачи (Automatic Repeat Request — ARQ). В беспроводных локальных сетях применяется процедура «запрос ARQ с остановками» (stop-and-wait ARQ).
В этом случае источник, пославший кадр, ожидает получения подтверждения (Acknowledgement — ACK), или, как еще его называют, квитанции, от приемника и только после этого посылает следующий кадр. Если же подтверждение не приходит в течение тайм-аута, то кадр (или подтверждение) считается утерянным и его передача повторяется. На
рис.
1.13 видно, что в этом случае производительность обмена данными ниже потенциально возможной; хотя передатчик и мог бы послать следующий кадр сразу же после отправки предыдущего, он обязан ждать прихода подтверждения.
Канальный уровень должен обнаруживать ошибки передачи данных, связанные с
искажением бит в принятом кадре данных или с потерей кадра, и по возможности их
корректировать.
Большая часть протоколов канального уровня выполняет только первую задачу —
обнаружение ошибок, считая, что корректировать ошибки, то есть повторно
передавать данные, содержавшие искаженную информацию, должны протоколы верхних
уровней. Так работают такие популярные протоколы локальных сетей, как Ethernet,
Token Ring, FDDI и другие. Однако существуют протоколы канального уровня, например
LLC2 или LAP-B, которые самостоятельно решают задачу восстановления искаженных
или потерянных кадров.
Очевидно, что протоколы должны работать наиболее эффективно в типичных
условиях работы сети. Поэтому для сетей, в которых искажения и потери кадров являются
очень редкими событиями, разрабатываются протоколы типа Ethernet, в которых не
предусматриваются процедуры устранения ошибок. Действительно, наличие процедур
восстановления данных потребовало бы от конечных узлов дополнительных
вычислительных затрат, которые в условиях надежной работы сети являлись бы
избыточными.
Напротив, если в сети искажения и потери случаются часто, то желательно уже
на канальном уровне использовать протокол с коррекцией ошибок, а не оставлять
эту работу протоколам верхних уровней. Протоколы верхних уровней, например
транспортного или прикладного, работая с большими тайм-аутами, восстановят
потерянные данные с большой задержкой. В глобальных сетях первых поколений,
например сетях Х.25, которые работали через ненадежные каналы связи, протоколы
канального уровня всегда выполняли процедуры восстановления потерянных и
искаженных кадров.
Поэтому нельзя считать, что один протокол лучше другого потому, что он
восстанавливает ошибочные кадры, а другой протокол — нет. Каждый протокол должен
работать в тех условиях, для которых он разработан.
Методы обнаружения ошибок
Все методы обнаружения ошибок основаны на передаче в составе кадра данных
служебной избыточной информации, по которой можно судить с некоторой степенью
вероятности о достоверности принятых данных. Эту служебную информацию принято
называть контрольной суммой или (последовательностью
контроля кадра — Frame Check Sequence, FCS). Контрольная сумма вычисляется
как функция от основной информации, причем необязательно только путем суммирования.
Принимающая сторона повторно вычисляет контрольную сумму кадра по известному
алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей
стороной, делает вывод о том, что данные были переданы через сеть корректно.
Существует несколько распространенных алгоритмов вычисления контрольной
суммы, отличающихся вычислительной сложностью и способностью обнаруживать
ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же
время это наименее мощный алгоритм контроля, так как с его помощью можно
обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в
суммировании по модулю 2 всех бит контролируемой информации. Например, для
данных 100101011 результатом контрольного суммирования будет значение 1.
Результат суммирования также представляет собой один бит данных, который
пересылается вместе с контролируемой информацией. При искажении при пересылке
любого одного бита исходных данных (или контрольного разряда) результат суммирования
будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные
данные. Поэтому контроль по паритету применяется к небольшим порциям данных,
как правило, к каждому байту, что дает коэффициент избыточности для этого
метода 1/8. Метод редко применяется в вычислительных сетях из-за его большой
избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию
описанного выше метода. Его отличие состоит в том, что исходные данные
рассматриваются в виде матрицы, строки которой составляют байты данных.
Контрольный разряд подсчитывается отдельно для каждой строки и для каждого
столбца матрицы. Этот метод обнаруживает большую часть двойных ошибок, однако
обладает еще большей избыточностью. На практике сейчас также почти не
применяется.
Циклический избыточный контроль (Cyclic Redundancy Check, CRC) является в настоящее время наиболее
популярным методом контроля в вычислительных сетях (и не только в сетях,
например, этот метод широко применяется при записи данных на диски и дискеты).
Метод основан на рассмотрении исходных данных в виде одного многоразрядного
двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт,
будет рассматриваться как одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается остаток от деления этого числа на
известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцати
трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт)
или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток
от деления на тот же делитель R, но при этом к данным кадра добавляется и
содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю1 (1 Существуетнесколько
модифицированная процедура вычисления остатка, приводящая к получению в случае
отсутствия ошибок известного ненулевого остатка, что является более надежным
показателем корректности.), то делается вывод об отсутствии ошибок в полученном
кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его
диагностические возможности гораздо выше, чем у методов контроля по паритету.
Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном
числе бит. Метод обладает также невысокой степенью избыточности. Например, для
кадра Ethernet размером в 1024 байт контрольная информация длиной в 4 байт
составляет только 0,4 %.
Методы восстановления искаженных и потерянных кадров
Методы коррекции ошибок в вычислительных сетях основаны на повторной
передаче кадра данных в том случае, если кадр теряется и не доходит до адресата
или приемник обнаружил в нем искажение информации. Чтобы убедиться в
необходимости повторной передачи данных, отправитель нумерует отправляемые
кадры и для каждого кадра ожидает от приемника так называемой положительной
квитанции — служебного кадра, извещающего о том, что исходный кадр был
получен и данные в нем оказались корректными. Время этого ожидания ограничено —
при отправке каждого кадра передатчик запускает таймер, и, если по его
истечении положительная квитанция на получена, кадр считается утерянным.
Приемник в случае получения кадра с искаженными данными может отправить отрицательную
квитанцию — явное указание на то, что данный кадр нужно передать
повторно.
Существуют два подхода к организации процесса обмена квитанциями: с
простоями и с организацией «окна».
Метод с простоями (Idle Source) требует, чтобы источник, пославший кадр, ожидал получения квитанции
(положительной или отрицательной) от приемника и только после этого посылал
следующий кадр (или повторял искаженный). Если же квитанция не приходит в
течение тайм-аута, то кадр (или квитанция) считается утерянным и его передача
повторяется. На рис. 2.24, а видно, что в этом случае производительность обмена
данными существенно снижается, — хотя передатчик и мог бы послать следующий
кадр сразу же после отправки предыдущего, он обязан ждать прихода квитанции.
Снижение производительности этого метода коррекции особенно заметно на
низкоскоростных каналах связи, то есть в территориальных сетях.
Рис. 2.24. Методы восстановления искаженных и
потерянных кадров
Второй метод называется методом «скользящего окна» (sliding
window). В этом методе для повышения коэффициента использования линии
источнику разрешается передать некоторое количество кадров в непрерывном
режиме, то есть в максимально возможном для источника темпе, без получения на
эти кадры положительных ответных квитанций. (Далее, где это не искажает
существо рассматриваемого вопроса, положительные квитанции для краткости будут
называться просто «квитанциями».) Количество кадров, которые разрешается
передавать таким образом, называется размером окна. Рисунок 2.24, б
иллюстрирует данный метод для окна размером в W кадров.
В начальный момент, когда еще не послано ни одного кадра, окно определяет
диапазон кадров с номерами от 1 до W включительно. Источник начинает передавать
кадры и получать в ответ квитанции. Для простоты предположим, что квитанции
поступают в той же последовательности, что и кадры, которым они соответствуют.
В момент t1 при получении первой квитанции К1 окно сдвигается
на одну позицию, определяя новый диапазон от 2 до (W+1).
Процессы отправки кадров и получения квитанций идут достаточно независимо
друг от друга. Рассмотрим произвольный момент времени tn, когда источник
получил квитанцию на кадр с номером n. Окно сдвинулось вправо и определило
диапазон разрешенных к передаче кадров от (n+1) до (W+n). Все множество кадров,
выходящих из источника, можно разделить на перечисленные ниже группы (рис.
2.24, б).
- Кадры с номерами от 1 доп. уже были отправлены и квитанции на них
получены, то есть они находятся за пределами окна слева. - Кадры, начиная с номера (п+1) и кончая номером
(W+n), находятся в пределах окна и
потому могут быть отправлены не дожидаясь прихода какой-либо квитанции.
Этот диапазон может быть разделен еще на два поддиапазона: - кадры с номерами от (n+1) до
т, которые уже отправлены, но квитанции на них еще не получены; - кадры с номерами от m до
(W+n), которые пока не отправлены, хотя запрета на это нет. - Все кадры с номерами, большими или равными
(W+n+1), находятся за пределами окна
справа и поэтому пока не могут быть отправлены.
Перемещение окна вдоль последовательности номеров кадров показано на рис.
2.24, в. Здесь t0 — исходный момент, t1 и tn —
моменты прихода квитанций на первый и n-й кадр соответственно. Каждый раз,
когда приходит квитанция, окно сдвигается влево, но его размер при этом не
меняется и остается равным W. Заметим, что хотя в данном примере размер окна в
процессе передачи остается постоянным, в реальных протоколах (например, TCP)
можно встретить варианты данного алгоритма с изменяющимся размером окна.
Итак, при отправке кадра с номером n источнику разрешается передать еще W-1
кадров до получения квитанции на кадр n, так что в сеть последним уйдет кадр с
номером (W+n-1). Если же за это время квитанция на кадр n так и не пришла, то
процесс передачи приостанавливается, и по истечении некоторого тайм-аута кадр n
(или квитанция на него) считается утерянным, и он передается снова.
Если же поток квитанций поступает более-менее регулярно, в пределах допуска
в W кадров, то скорость обмена достигает максимально возможной величины для
данного канала и принятого протокола.
Метод скользящего окна более сложен в реализации, чем метод с простоями,
так как передатчик должен хранить в буфере все кадры, на которые пока не
получены положительные квитанции. Кроме того, требуется отслеживать несколько
параметров алгоритма: размер окна W, номер кадра, на который получена
квитанция, номер кадра, который еще можно передать до получения новой
квитанции.
Приемник может не посылать квитанции на каждый принятый корректный кадр.
Если несколько кадров пришли почти одновременно, то приемник может послать
квитанцию только на последний кадр. При этом подразумевается, что все
предыдущие кадры также дошли благополучно.
Некоторые методы используют отрицательные квитанции. Отрицательные
квитанции бывают двух типов — групповые и избирательные. Групповая квитанция
содержит номер кадра, начиная с которого нужно повторить передачу всех кадров,
отправленных передатчиком в сеть. Избирательная отрицательная квитанция требует
повторной передачи только одного кадра.
Метод скользящего окна реализован во многих протоколах: LLC2, LAP-B, X.25,
TCP, Novell NCP Burst Mode.
Метод с простоями является частным случаем метода скользящего окна, когда
размер окна равен единице.
Метод скользящего окна имеет два параметра, которые могут заметно влиять на
эффективность передачи данных между передатчиком и приемником, — размер окна и
величина тайм-аута ожидания квитанции. В надежных сетях, когда кадры искажаются
и теряются редко, для повышения скорости обмена данными размер окна нужно
увеличивать, так как при этом передатчик будет посылать кадры с меньшими
паузами. В ненадежных сетях размер окна следует уменьшать, так как при частых
потерях и искажениях кадров резко возрастает объем вторично передаваемых через
сеть кадров, а значит, пропускная способность сети будет расходоваться во
многом вхолостую — полезная пропускная способность сети будет падать.
Выбор тайм-аута зависит не от надежности сети, а от задержек передачи
кадров сетью.
Во многих реализациях метода скользящего окна величина окна и тайм-аут
выбираются адаптивно, в зависимости от текущего состояния сети.
Построение кодов обнаружения ошибок (защитных кодов)
В процессе
преобразования информации, представленной
в закодированной форме, часто возникают
ошибки, связанные со сбоями в работе
технических средств преобразования
информации ,а также допущенные людьми
при работе с компьютером и оргтехникой.
Построение кодов
обнаружения ошибок основано на трех
основных принципах:
1) Использование
признаков делимости
2) Запрещение
использования определенной части
кодовых слов.
3) Запрещение
использования определенных символов.
1. Построение кодов обнаружения ошибок с использованием признака делимости числа
Суть
данного способа построения кодов
обнаружения ошибок состоит в следующем:
допустим необходимо построить код
обнаружения ошибок для табельного
номера, состоящего из четырех цифр:
5621 а)
в данном случае выбирается число М,
называемое модулем (желательно простое
целое число) и исходное кодовое число
делится на модуль М. Например, М=9
5621
: 9
54
22
18
41
36
5
и
остаток от деления (в данном случае
равный 5) дописывается справа от исходного
кодового слова. Таким образом, табельный
номер примет вид 56215,
где первые четыре разряда информационные,
а последний контрольный.
б)
контроль по модулю «10». Допустим,
необходимо построить код обнаружения
ошибок для номенклатурного номера
материала 62154. Находим сумму чисел:
6+2+1+5+4=18.
Далее
определяется ближайшее, большее 18, число
кратное 10. Это число 20. Определяется
разность этих чисел 20-18=2. Полученное
значение и является контрольным разрядом.
Таким образом, будет обрабатываться
на всех стадиях число 621542,
содержащее 5 информационных разрядов
и 1 контрольный. В данном случае
присутствует избыточная информация,
введение которой оправдано необходимостью
контроля правильности преобразования
информации. Однако, данный способ не
позволяет обнаружить ошибки, связанные
с перестановкой цифр.
Для
этого существует способ построения
кодов обнаружения ошибок с
учетом весовых коэффициентов.
Суть которого в том, что на каждый разряд
числа «навешивается» весовой коэффициент.
Далее применяется контроль по модулю
«10», только с использованием весовых
коэффициентов числа.
Например, требуется
построить код инвентарного номера
оборудования 190624. Для каждого разряда
числа вводится весовой коэффициент,
причем, чем старше разряд, тем больше
коэффициент. Данное число имеет весовые
коэффициенты:
6
5 4 3 2 1
1
9 0 6 2 4
Находится
сумма цифр числа, умноженных на весовые
коэффициенты: 1*6+9*5+0*4+6*3+2*2+4*1=77.
Находится разность между ближайшим
большим числом, кратным 10, и данным
числом 80-77=3 и эта разность дописывается
к исходному кодовому числу в качестве
контрольного разряда: 1906243.
Построение
защитных кодов для информации,
представленной в двоичном коде
Одним
из основных способов контроля двоичной
информации является контроль «на
ЧЕТ». В
исходном кодовом числе подсчитывается
количество единиц, если оно является
нечетным, в качестве контрольного
разряда к числу приписывается 1,
если четным — 0.
В полученном кодовом слове число единиц
должно быть обязательно четным.
Например: а)
110011 — исходное кодовое слово
1100110
— кодовое слово с контрольным разрядом
б)
11001 — исходное кодовое слово
110011
— кодовое слово с контрольным разрядом
Коды
обнаружения ошибок, построенные по
принципу применения кодовых словарей
Данный способ
построения кодов обнаружения ошибок
заключается в использовании слов,
входящих в специальным образом
составленные кодовые словари. Только
данные слова являются разрешенными,
все остальные запрещенными для
использования. Если кодовое слово,
подлежащее преобразованию, содержится
в кодовом словаре, значит информация
преобразуется без ошибок, если данного
слова в кодовом словаре нет, значит
выдается сообщение об ошибке. Кодовые
словари могут быть построены на 10 и на
100 слов.
Пример построения
кодового словаря на 10 слов:01 12 23 34 45 56 67
78 89 90. Все остальные двузначные слова
являются запрещенными. В данном случае
коэффициент использования информационной
емкости кода равен: 10/99=0,1.
Здесь
10- количество слов в словаре , 99 —
максимально возможное количество цифр
в словаре.
Например, если
получено при передаче информации слово
13, то выдается сообщение об ошибке, т.к.
данное слово в кодовом словаре
отсутствует. В
случае одиночной ошибки она может быть
исправлена: это может быть либо слово
23,либо — 12.
Кодовый словарь
на 100 слов строится следующим образом:
|
Десятки |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
0 1 2 3 4 5 6 7 8 9 |
001 012 023 034 045 056 067 078 089 090 |
102 113 124 135 146 157 168 179 180 191 |
203 214 225 236 247 258 269 270 281 292 |
304 315 326 337 348 359 360 371 382 393 |
405 416 427 438 449 450 461 472 483 494 |
506 517 528 539 540 551 562 573 584 595 |
607 618 629 630 641 652 663 674 685 696 |
708 719 720 731 742 753 764 775 786 797 |
809 810 821 832 843 854 865 876 887 898 |
900 912 923 934 945 956 967 978 989 999 |
Проверка
правильности переданных кодовых слов
выполняется несколькими способами.
Основные способы контроля приведены
ниже:
-
похожие
по написанию цифры кодового слова (3 и
8, 5 и 6, 9 и 0, 6 и 9 и т.д.) ; -
ошибки,
совершенные при вводе с клавиатуры
(рядом расположенные клавиши: с 1 рядом
2 и 4, с 5 – рядом 2, 4 и 6 и т.д.); -
перестановка
цифр числа при вводе с клавиатуры.
Коды
обнаружения ошибок, построенные по
принципу запрещения использования
определенной части символов
Очень часто в
процессе преобразования информации
возникают ошибки, связанные с нечетким
заполнением первичных документов или
с нажатием на устройствах передачи или
подготовки данных ошибочно рядом
расположенной клавиши. При нечетком
заполнении документов бывает сложно
различить похожие по начертанию цифры
4 и 7, 0 и 6, 0 и 9. Для избежания подобного
рода ошибок, а также устранения возможности
ошибок при нажатии рядом расположенных
на клавиатуре клавиш запрещается
использовать для построения кодовых
слов следующие символы: например: 0,6,9.
Все остальные символы являются
разрешенными. В случае, если в процессе
преобразования информации возникает
кодовое слово, содержащее разрешенные
символы, выдается сообщение об ошибке.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Отличную передачу информации реализуют разные методы. Нужно учитывать по какой топологии происходит передача данных: Ethernet, token ring, PDH, dwdm. В этой статье рассмотрим самокорректирующихся кодов, которые не только обнаруживают ошибки но и исправляют их. Это очень важно при передачи информации для контроля удаленного доступа.
Функции выявления ошибок реализуются на транспортировке в составе блока избыточной служебной информации, по которой смотрят степень достоверности принятой информации.В сетях с коммутацией пакетов такой единицей данных может быть PDU различного уровня. Поэтому для точности будем считать, что мы работаем с кадрами.
Избыточную информацию называют контрольной последовательностью кадра, или контрольной суммой. Контрольная сума считается как функция от основной массы данных, причем это не обязательно функция суммирования. Сторона которая принимает информацию еще раз считает контрольную сумму кадра по на катаному шаблону и если есть совпадение, то делается вывод что данные были переданы корректно. Избыточные пакеты бывают из-за алгоритма покрывающего дерева и не правильно работающего сетевого адаптера или концентратора.
Искусственный интеллект C#. Обучение нейронных сетей. Алгоритм обратного распространения ошибки
Контроль по паритету является наиболее простой метод контроля данных. При этом это самый менее мощный метод контроля, так как он выявляет только одиночные ошибки в данных.
Принцип действия таков, что он суммирует все биты пакета по модулю 2. Несложно увидеть, что если информация имеет нечетное число единиц, то результат контрольной суммы будет равен — 1, при четном — 0. Итог суммирования записывается в один дополнительный бит, который передается вместе данными пакета. При передачи данных, если произошло искажение любого одного бита данных, то после суммирования будет видно что результаты отличаются.
Однако двойная ошибка, то есть искажение произошло на 2,4 и тд битов, будет не выявлена и неверная информация будет пропущена. А пропущенная искаженная информация уже создает угрозы информационной безопасности. Поэтому метод применяется к небольшим пересылкам данных, обычно к каждому байту, что дает характер избыточности 1/8. В компьютерных сетях метод редко применяется из-за невысоких диагностических функций да и значительной избыточности. Искажения возникают из-за не правильных характеристик проводных линий связи.
Горизонтальный и вертикальный контроль по паритету является по сути измененной версией выше описанного метода. Отличие в том, что начальные данные смотрятся в виде матрицы, строчки которых являются байты информации. Контрольный разряд считает для каждой строки и каждого столбика матрицы. Этот метод выявляет многую часть двойных ошибок, но все еще имеет большую избыточность. Впринципи он все так же почти не применяется в информационных сетях.
Циклический избыточный контроль представляется как наиболее используемым методом контроля в информационных сетях. Частично могу решать проблемы защиты информации в сетях. Также широко используется при записи информации на жесткие или другие диски. Принцип действия таков, что он смотрит начальные данные в виде одного багаторозрядного двоичного числа.
Стив Макконел. Совершенный код. Руководство по разработке программного обеспечения | #3
К примеру, кадр Ethernet который состоит из 1024 байт, будет расценен как число из 8192 бит.Контрольные данные считают остаток от деления числа на известный делитель R. Традиционно делитель выбирают с количеством разрядов 17 или 33, что бы остаток от деления приходился на 16 разрядов (2 байт) или 32 разряда (4 байт). Когда кадр приходит на пункт приема, считается остаток на тот же делитель, и если остаток равна нулю, то ошибок нету, в ином случае можно считать что кадр был искажен.
Этот метод имеет высокую вычислительную сложность. Но при этом диагностические возможности гораздо выше. Этот метод выявляет все двойные ошибки, одиночные и ошибки в нечетном числе битов. К примеру кадр Ethernet — 1024 байт имеет контрольную информацию 4 байта, что есть 0,4% от всего объема. Также нужно учитывать Полосу пропускания и пропускную способность канала передачи.
Техники кодирования позволяют приемник не только выявить возможные ошибки, но и исправлять их. Коды, которые реализуют исправление ошибок, требуют значительно большей избыточности в транспортируемой информации, чем те коды которые обнаруживают ошибки. Выбор техники кодирования должны быть согласованы в политике безопасности организации.
При использовании любого избыточного кода не все комбинации кодов есть разрешенными. К примеру, если есть контроль трех информационных битов, то разрешенными будут 4-битные коды и дополнением:
000 1, 001 0, 010 0, 011 1, 100 0, 101 1, 110 1, 111 0, то есть 8 кодов из 16 возможных. Также можете посмотреть пример шифрования RSA
Чтобы проанализировать количество дополнительных битов, нужных для исправления ошибок, нужно знать расстояние между разрешенными комбинациями кода (Хемминга).Расстояние Хемминга называют наименьшее число битовых разрядов, где отличается рандомная пара разрешенных кодов. Длина Хемминга равна 2 для схем контроля по паритету. Если мы создали избыточный код с длиной хемминга — n, то такой код сможет увидеть (n-1)-кратные ошибки и изменять (n-1)/2-кратные ошибки.

Коды Хемминга отлично находят и исправляют ошибки, даже изолированные, то есть искаженные отдельные биты которые могут быть разделены большим количеством правильных битов. Коды исправления есть частично одним из методов защиты информации Однако при пульсации ошибок(большая длина искаженных битов), коды Хемминга не помогают. Пульсации ошибок применимы для беспроводных каналов, где используются сверточные коды. Также они могу возникать при коммутации каналов и пакетов.
- служба информационной безопасности предприятия
- защита компьютера
- защита информации на андроид
- документирование информации
- shema_Rabina
- компьютерная преступность в России
- генерация псевдослучайных чисел
- поточные шифры
Источник: infoprotect.net
Методы обнаружения ошибок
Большая часть протоколов канального уровня выполняет только одну задачу — обнаружение ошибок, считая, что корректировать ошибки, то есть повторно передавать данные, должны протоколы верхних уровней. Однако существуют протоколы канального уровня, которые самостоятельно решают задачу восстановления искаженных или потерянных кадров.
Но нельзя считать, что один протокол лучше другого потому, что он восстанавливает ошибочные кадры, а другой протокол — нет. Каждый протокол должен работать в тех условиях, для которых он разработан.
Все методы обнаружения ошибок основаны на передаче служебной избыточной информации, по которой можно судить с некоторой степенью вероятности о достоверности принятых данных. Эту служебную информацию принято называть контрольной суммой. Контрольная сумма вычисляется как функция от основной информации, причем необязательно только путем суммирования. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения делает вывод о том, что данные были переданы корректно. Существует несколько распространенных алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать ошибки в данных.
Контроль по паритету – наиболее простой и наименее мощный метод контроля. С его помощью можно обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех бит контролируемой информации. Результат суммирования также представляет собой один бит данных.
При искажении любого одного бита исходных данных (или контрольного разряда) результат суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке. Однако двойная ошибка будет неверно принята за корректные данные. Поэтому контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод редко применяется в вычислительных сетях из-за его большой избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного выше метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд подсчитывается отдельно для каждой строки и для каждого столбца матрицы. Этот метод обнаруживает большую часть двойных ошибок, однако обладает еще большей избыточностью. На практике сейчас также почти не применяется.
Циклический избыточный контроль (CRC) является в настоящее время наиболее популярным методом контроля в вычислительных сетях (и не только в сетях, например, этот метод широко применяется при записи данных на диски и дискеты). Метод основан на рассмотрении исходных данных в виде одного многоразрядного двоичного числа.
Например, кадр стандарта Ethernet, состоящий из 1024 байт, будет рассматриваться как одно число, состоящее из 8192 бит. В качестве контрольной информации рассматривается остаток от деления этого числа на известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцати трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт) или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток от деления на тот же делитель R, но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю1, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо выше, чем у методов контроля, по паритету. Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном числе бит. Метод обладает также невысокой степенью избыточности. Например, для кадра Ethernet размером в 1024 байт контрольная информация длиной в 4 байт составляет только 0,4 %.
Источник: studopedia.ru
Общие сведения и классификация методов обнаружения ошибок передачи данных
Задача обнаружения ошибок, возникающих в процессе передачи информационных кадров по каналам связи телекоммуникационных сетей, решается протоколами канального уровня [14].
Большинство методов обнаружения ошибок основаны на передаче в составе кадра избыточной информации, по которой можно судить с некоторой степенью вероятности о достоверности принятых данных. Такую информацию принято называть контрольной суммой. Контрольная сумма (КС) вычисляется как функция от основной информации, причем необязательно только путем суммирования. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей стороной, делает вывод о том, что данные были переданы через сеть корректно.
Существует несколько распространенных методов обнаружения ошибок и соответствующих им алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать искажения (рис. 2.23).
Рис. 2.23. Методы обнаружения ошибок
Контроль по паритету на четность (нечетность) является одним из наиболее простых методов контроля данных, обладает весьма слабыми возможностями по контролю. Позволяет обнаруживать только одиночные или нечетной кратности ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех бит контролируемой информации. Значение контрольного разряда r, добавляемого к информационному сообщению U = (u0 . um), формируется в соответствии с (11.1) при контроле на четность или (11.2) ‑ при контроле на нечетность.
Сформированный контрольный разряд r пересылается вместе с контролируемой информацией. При искажении при пересылке любого одного бита исходных данных (или контрольного разряда) результат повторного суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке.
| Чет. | Нечет. |
| U = 100110111 | |
| U = 10011001 |
Контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод в настоящее время редко применяется в вычислительных сетях из-за его большой избыточности и невысоких диагностических возможностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного выше метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд подсчитывается отдельно для каждой строки и для каждого столбца матрицы (табл. 2.4).
Этот метод обнаруживает большую часть двойных ошибок, однако обладает еще большей избыточностью. На практике почти не применяется.
Циклический избыточный контроль (Cyclyc Redundancy Check, CRC) является разновидностью использования блочных кодов. В настоящее время широко применяется для контроля передачи данных в компьютерных и телекоммуникационных сетях. Вертикальный и горизонтальный контроль по паритету приведены в табл. 2.4.
| Байты | 0 р. | 1 р. | 2 р. | 3 р. | 4 р. | 5 р. | 6 р. | 7 р. | Нечет. |
| Нечет. |
Метод основан на представлении информационных кадров в виде единой совокупности двух блоков: информационной и проверочной последовательности двоичных символов (рис. 2.24). Наличие специальной проверочной последовательности позволяет не только выявлять факт искажения отдельных информационных разрядов, но и корректировать их.
| Информационная последовательность | Проверочная последовательность |
Рис. 2.24. Структура информационного кадра при циклическом контроле
Например, в кадре стандарта Ethernet, содержащего 8192 бита (1024 байта) в качестве контрольной последовательности используется остаток от деления этого числа на известный делитель P(x), представляющий собой порождающий полином. Обычно в качестве такого делителя выбирается семнадцати -или тридцати трехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байта) или 32 разряда (4 байта).
При получении кадра данных снова вычисляется остаток от деления на тот же делитель P(x), но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма. Если остаток от деления на P(x) равен нулю, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным.
Метод циклического контроля обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо выше, чем у методов контроля по паритету. Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном числе бит. Метод обладает также невысокой степенью избыточности. Например, для кадра Ethernet размером в 1024 байта контрольная информация длиной в 4 байт составляет только 0,4 %.
Рассмотрим пример использования метода циклического контроля.
Введем следующие обозначения:
1. U(x)=um-1x m -1 + um-2x m -2 +…+ u0x 0 ‑ полином, определяющий информационную последовательность данных (m — разрядность данных);
2. P(x) =pkx k + pk-1x k -1 +…+ p0x 0 ‑ порождающий полином (k – разрядность проверочной последовательности);
3. F(x) = fn-1x n -1 + fn-2x n — 2 +. + f0x 0 ‑ полином, определяющий кодовую комбинацию, передаваемую по каналу связи (n = m + k) — разрядность кодовой комбинации);
4.Q(x) = qm-1x m -1 + qm-2 x m -2 + . + q0 x 0 ‑ частное от деления кодовой комбинации F(x) на порождающий полином P(x);
5.R(x) = rk-1 x k -1 + гk-2х k -2 +…+ r0х 0 ‑ остаток от деления кодовой комбинации F(x) на порождающий полином P(x), образующий проверочную последовательность символов;
Алгоритм кодирования передаваемых данных при циклическом контроле:
1. Для формирования блоков информационных и проверочных символов исходная информационная последовательность U(x) сдвигается на k разрядов влево. Освободившиеся младшие разряды заполняются нулями. В дальнейшем их место займут проверочные символы. Аналитически данная операция может быть представлена выражением x k U(x).
2. Сдвинутая последовательность информационных символов делится на порождающий полином Р(х).
3. Для формирования кодовой комбинации F(x), выдаваемой в канал связи, полученный в результате деления k — разрядный остаток R(x) добавляется к младшим разрядам сдвинутой последовательности информационных символов. Операция сложения выполняется по модулю 2: F(x) = x k U(x)ÅR(x).
Формирование кодовой комбинации. Дано:
1. U(x) = x 4 + x 2 + x + 1 = 10111 ‑ информационная последовательность (m=5).
2. P(x) = x 4 + x + 1 = 10011 ‑ порождающий полином (k=4).
1. Сдвиг информационной последовательности на k=4 разряда влево.
U(x) x 4 = (x 4 + x 2 + x + 1) x 4 = x 8 + x 6 + x 5 + x 4 = 101110000.
2. Формирование проверочной последовательности путем деления U(x) x 4 на порождающий полином Р(х). Проверочные символы определяются остатком отделения.
3. Формирование кодовой комбинации F(x).
Обнаружение ошибок при циклическом кодировании сводится к делению принятой кодовой комбинации на тот же порождающий полином, который использовался для кодирования. Если ошибок в принятой комбинации нет, то деление на порождающий полином производится без остатка. Наличие остатка свидетельствует о присутствии ошибок.
При использовании в циклических кодах декодирования с исправлением ошибок остаток от деления может играть роль синдрома. Нулевой синдром указывает на то, что принятая комбинация является разрешенной. Всякому ненулевому синдрому соответствует определенная конфигурация ошибок, которая и исправляется.
Однако обычно в телекоммуникационных сетях исправление ошибок при использовании циклических кодов не производится, а при обнаружении ошибок выдается запрос на повтор испорченной ошибками комбинации. Такие системы называются системами с обратной связью.
Источник: infopedia.su
Методы обнаружения ошибок
Для обнаружения ошибок применяются методы (техники кодирования), основанные па определении вероятности получения приемником достоверной кодовой комбинации. В качестве такой комбинации может выступать любая протокольная единица данных (PDU, Protocol Data Unit) — блок битов, передаваемый как единое целое и имеющий определенную структуру, включающую как саму передаваемую информацию, так и служебные данные. Служебную информацию принято называть контрольной суммой. Она вычисляется по специальным алгоритмам на основе информационных данных, причем не обязательно в виде суммирования.
Будем считать для определенности, что при передаче протокольных единиц данных контролируются кадры. В этом случае контрольную сумму называют контрольной последовательностью кадра. (FCS, Frame Check Sequence). Передатчик отправляет контрольную последовательность кадра как часть PDU.
Приемник на своей стороне вычисляет FCS по известному алгоритму и сравнивает с переданной контрольной последовательностью. Если FCS передатчика и приемника совпадают, то принимается решение, что передача данных по сети выполнена корректно.
Основными методами контроля данных (обнаружения ошибок) являются следующие:
- — контроль по паритету;
- — вертикальный и горизонтальный контроль по паритету;
- — контроль контрольной суммой;
- — контроль циклическим избыточным кодом.
Указанные методы отличаются друг от друга как вычислительной сложностью, так и способностью обнаруживать ошибки.
Контроль по паритету является наиболее простым и в то же время наименее мощным методом контроля. Он предназначен для обнаружения битовых ошибок данных. Его суть заключается в следующем. К информационным данным добавляется один контрольный бит (г = 1), который дополняет количество единичных бит до четного или нечетного значения.
В первом случае говорят о контроле четности данных, во втором — о контроле нечетности. Соглашение о выборе вида контроля принимается заранее.
Для обнаружения ошибки все передаваемые биты блока (как информационные, так и контрольный) суммируются по модулю 2. При наличии ошибки в передаваемом блоке (как исходных, так и контрольном) результат суммирования будет отличаться от контрольного разряда, который был принят. Это свидетельствует о наличии ошибки. Однако, если ошибок было четное количество (две, четыре и т.д.), то такое искажение останется незамеченным. Из-за этой особенности данный метод контроля применяется к небольшим блокам данных, обычно байтам. В этом случае избыточность кода составляет 1/8, что является довольно значительным, поэтому в компьютерных сетях контроль но паритету используется редко.
Пример 5.3. Рассмотрим ситуацию нечетного контроля трех информационных бит. В этом случае кодовые слова будут состоять из 4 бит. Разрешенными кодовыми комбинациями будут следующие:

Пробелом отделен контрольный бит. ?
Пример 5.3 иллюстрирует два факта, верных для произвольного количества информационных бит:
- 1. При контроле по паритету только половина кодовых комбинаций оказывается разрешенной (8 кодов из 16 возможных).
- 2. Минимальное расстояние кода dmm = 2, т.е. возможно только обнаруживать битовые ошибки, по нс исправлять их.
Вертикальный и горизонтальный контроль по парит,егпу во многом похож на рассмотренный выше метод с тем отличием, что информационные данные представляются (располагаются) в виде матрицы. Строками этой матрицы являются отдельные байты данных. Контрольные биты данных добавляются как для каждой строки, так и для каждого столбца (рис. 5.1).
Бит паритета «р» (горизонтальный контроль) добавляется к каждому передаваемому символу. Бит паритета вертикального контроля рассчитывается для каждой

Рис. 5.1. Вертикальный и горизонтальный контроль по паритету
позиции бита в символе. Вертикальные контрольные биты собираются в отдельный контрольный символ (байт).
Данный метод позволяет обнаружить большую часть ошибок кратности 2. В то же время он обладает еще большей избыточностью но сравнению с обычным контролем по паритету, поэтому в реальных СПД вертикальный и горизонтальный контроль по паритету почти не применяется.
Контрольная сумма представляет собой дополнительный код (см. пример 3.2) суммы всех байт кодового слова. Суммирование выполняется но модулю разрядности поля контрольного кода. Дополнение суммы происходит до нуля (до следующего за максимально возможным числом разрядной сетки, когда все разряды представляют собой двоичные единицы, например, FF).
Передатчик отправляет информационные данные и контрольную сумму. Прием- пик на своей стороне суммирует все байты или слова кадра,, включая контрольные биты. Суммирование выполняется по тому же модулю (разрядности поля контрольного кода). В результате должно получиться то же число 0 (следующее за FF). Отличие в значении позволяет сделать вывод, что при передаче была допущена ошибка.
Вычисление контрольных сумм является одним из самых простых способов контроля кадров (вероятность определения ошибок достигает 99,9%). При постоянной длине контрольного кода с увеличением количества информационных данных в одной PDU вероятность обнаружения ошибок снижается. Метод контрольных сумм применяется для выявления битовых ошибок.
Рассмотренные три метода обнаружения ошибок являются достаточно простыми как с алгоритмической точки зрения, так и в технической реализации. Однако все они не позволяют обнаружить пакетные ошибки заданной кратности. Для решения этой проблемы может быть применен метод циклического избыточного контроля.
Циклический избыточный контроль (Cyclic Redundancy Check, CRC) является популярным методом обнаружения ошибок в СПД и других задачах, где не требуется исправление пакетных ошибок, например, при записи данных на жесткие и оптические носители.
Суть метода CRC заключается в следующем. На передатчике формируется п-бит- нос кодовое слово, состоящее из к информационных и г проверочных бит (поле FCS). До передачи кадра все проверочные биты имеют значение 0. Кадр целиком (все п бит, включая и обнуленные проверочные) в виде двоичного числа делится за некоторый делитель Р.
Остаток от деления по модулю 2 помещается в иоле FCS. На стороне приемника принятый кадр целиком делится на тот же делитель Р. Если остаток от деления на приемнике равен 0, то принимается решение, что ошибок при передаче данных не произошло, иначе данные считаются искаженными.
Число бит в кадре может быть достаточно большим. Например, стандартный кадр Ethernet имеет длину 1024 байт, т.с. число будет содержать 8096 бит.
В циклических кодах передаваемые кадры имеют определенную структуру, т.е. информационные и проверочные биты всегда располагаются на определенных местах. С целью упрощения кодирования и декодирования проверочные биты обычно располагают в конце блока. Каждый блок данных кодируется и декодируется независимо от других блоков.
При практической реализации CRC значения бит представляются в виде многочленов от некоторой фиксированной переменной х. Коэффициентами многочленов являются двоичные числа, которые соответствуют передаваемым битам. Например, блок данных 10011010 представляется в виде многочлена 7-й степени с коэффициентами 1, 0, 0, 1, 1,0, 1,0 соответственно, т.е. х 7 + х 4 + х 2 + х.
Операции в циклических кодах можно рассматривать как с точки зрения операций над двоичными числами, так и с точки зрения операций над полиномами. При вычислениях используют операции сложения и деления полиномов. Сложение осуществ-

Деление также выполняется обычным образом, только операция вычитания заменяется сложением по модулю 2:

В циклических кодах разрешенные комбинации имеют два важных с точки зрения реализации свойства:
- 1. Для разрешенной комбинации циклический побитовый сдвиг приводит к разрешенной комбинации. Именно этот факт и послужил основой для названия метода.
- 2. Все разрешенные комбинации (в полиномиальном представлении) делятся без остатка на некоторый полином Р(х).
Полином Р(х) называют образующим или порождающим полиномом. Вид образующего полинома определяется желаемой разрядностью остатка и способностью определять ошибки. Число проверочных бит обычно совпадает со степенью порождающего полинома. Младший и старший биты Р(х) должны быть равны 1. Имеются и другие требования к образующему полиному. Некоторые конкретные порождающие полиномы определены в стандартах международных организаций.
Алгоритм построения циклического кода (кодирование передаваемых данных) имеет следующий вид:
- 1. Передаваемый ^-битовый блок данных умножается на число 2 Г . Данная операция равносильна умножению полинома D(x), соответствующему А:-битовой последовательности, на полином х г . В результате длина битовой последовательности увеличивается на г разрядов, причем эти последние г разрядов (блок FCS) заполнены нулями.
- 2. Полученная последовательность бит (как информационных, так и проверочных) делится на образующий многочлен Р(х) с остатком Q(x). Количество разрядов остатка на единицу меньше, чем у Р(х).
- 3. Полученный остаток Q(x) складывается с полиномом D(x)x r . Данная операция равносильна размещению в битах FCS коэффициентов полинома Q(x). Полученная новая битовая последовательность (кадр) Т(х) = D(x)x r +Q(x) и должна быть передана но сети.
Нетрудно видеть, что передаваемый кадр должен делиться на образующий полином без остатка. Действительно, если некоторое число (делимое) делится на делитель с остатком, то при вычитании остатка из делимого полученный результат будет без остатка делиться на делитель. Если, например, разделить в десятичной системе счисления 210 278 на 10 941, то получится остаток 2 399. Если вычесть полученный остаток из делимого (210278), то результат 207879 будет нацело (т.е. без остатка) делиться на 10941.
Пример 5.4. Рассмотрим передачу блока данных 1011101. Этому блоку соответствует полином D(x) = х 6 + х 4 + х 3 + х 2 + 1. Пусть в качестве образующего полинома выбран Р(х) = х 4 4- х 4- 1, которому соответствует число 10011. Количество проверочных бит совпадает со степенью полинома Р(х), т.е. г = 4, последовательность передаваемых данных будет содержать п = 7 4- 4 = 11 бит.
Выполним умножение полинома D(x) на полином х 4 :

что соответствует битовой последовательности 10111010000.
Произведем деление полинома D(x)x 4 на образующий полином:

Остаток от деления D(x)x x на Р(х) равен Q(x) = х 2 + х, что соответствует числовому значению 110, которое и будет размещено в поле проверочных бит (так как их количество г = 4, то будет размещено число ОНО).
Передаче подлежит кадр, который в виде полинома является суммой Т(х) = = D + Q(x) = х 10 И- х 8 + х 7 + х 6 + х л 4- х 2 4- х, что соответствует числовому значению 10111010110.
Осуществим проверку, выполнив деление Т(х) на Р(х):

Таким образом, если был получен кадр 10111010110, то принимается решение, что ошибок при передаче не произошло. В противном случае полагается, что в данных имеются искажения. ?
Рассмотренный метод циклического избыточного контроля обладает большей вычислительной сложностью, нежели контроль но паритету и применение контрольных сумм, но имеет гораздо более высокие диагностические возможности. Кодирование CRC позволяет обнаружить все битовые ошибки, все двойные, ошибки нечетной кратности, а также пакетные ошибки. Вероятность нахождения ошибок оценивается в 99,9984%. Избыточность метода считается невысокой. Например, кадр в 1024 бит может иметь контрольные данные размером в 4 бита, что составляет 0,4%.
Дальнейшим развитием метода циклического избыточного контроля является ЕСС-коитроль (контроль достоверности с исправлением ошибок, Error Correction Code), позволяющий не только обнаруживать, но и исправлять некоторые ошибки.
Источник: studme.org
Построение кодов обнаружения ошибок (защитных кодов)
В процессе преобразования информации, представленной в закодированной форме, часто возникают ошибки, связанные со сбоями в работе технических средств преобразования информации ,а также допущенные людьми при работе с компьютером и оргтехникой.
Построение кодов обнаружения ошибок основано на трех основных принципах:
1) Использование признаков делимости
2) Запрещение использования определенной части кодовых слов.
3) Запрещение использования определенных символов.
1. Построение кодов обнаружения ошибок с использованием признака делимости числа
Суть данного способа построения кодов обнаружения ошибок состоит в следующем: допустим необходимо построить код обнаружения ошибок для табельного номера, состоящего из четырех цифр: 5621 а) в данном случае выбирается число М, называемое модулем (желательно простое целое число) и исходное кодовое число делится на модуль М. Например, М=9
и остаток от деления (в данном случае равный 5) дописывается справа от исходного кодового слова. Таким образом, табельный номер примет вид 56215, где первые четыре разряда информационные, а последний контрольный.
б) контроль по модулю «10». Допустим, необходимо построить код обнаружения ошибок для номенклатурного номера материала 62154. Находим сумму чисел: 6+2+1+5+4=18.
Далее определяется ближайшее, большее 18, число кратное 10. Это число 20. Определяется разность этих чисел 20-18=2. Полученное значение и является контрольным разрядом. Таким образом, будет обрабатываться на всех стадиях число 621542, содержащее 5 информационных разрядов и 1 контрольный.
В данном случае присутствует избыточная информация, введение которой оправдано необходимостью контроля правильности преобразования информации. Однако, данный способ не позволяет обнаружить ошибки, связанные с перестановкой цифр.
Для этого существует способ построения кодов обнаружения ошибок с учетом весовых коэффициентов. Суть которого в том, что на каждый разряд числа «навешивается» весовой коэффициент. Далее применяется контроль по модулю «10», только с использованием весовых коэффициентов числа.
Например, требуется построить код инвентарного номера оборудования 190624. Для каждого разряда числа вводится весовой коэффициент, причем, чем старше разряд, тем больше коэффициент. Данное число имеет весовые коэффициенты:
Находится сумма цифр числа, умноженных на весовые коэффициенты: 1*6+9*5+0*4+6*3+2*2+4*1=77. Находится разность между ближайшим большим числом, кратным 10, и данным числом 80-77=3 и эта разность дописывается к исходному кодовому числу в качестве контрольного разряда: 1906243.
Построение защитных кодов для информации, представленной в двоичном коде
Одним из основных способов контроля двоичной информации является контроль «на ЧЕТ». В исходном кодовом числе подсчитывается количество единиц, если оно является нечетным, в качестве контрольного разряда к числу приписывается 1, если четным — 0. В полученном кодовом слове число единиц должно быть обязательно четным.
Например: а) 110011 — исходное кодовое слово
1100110 — кодовое слово с контрольным разрядом
б) 11001 — исходное кодовое слово
110011 — кодовое слово с контрольным разрядом
Коды обнаружения ошибок, построенные по принципу применения кодовых словарей
Данный способ построения кодов обнаружения ошибок заключается в использовании слов, входящих в специальным образом составленные кодовые словари. Только данные слова являются разрешенными, все остальные запрещенными для использования. Если кодовое слово, подлежащее преобразованию, содержится в кодовом словаре, значит информация преобразуется без ошибок, если данного слова в кодовом словаре нет, значит выдается сообщение об ошибке. Кодовые словари могут быть построены на 10 и на 100 слов.
Пример построения кодового словаря на 10 слов:01 12 23 34 45 56 67 78 89 90. Все остальные двузначные слова являются запрещенными. В данном случае коэффициент использования информационной емкости кода равен: 10/99=0,1.
Здесь 10- количество слов в словаре , 99 — максимально возможное количество цифр в словаре.
Например, если получено при передаче информации слово 13, то выдается сообщение об ошибке, т.к. данное слово в кодовом словаре
отсутствует. В случае одиночной ошибки она может быть исправлена: это может быть либо слово 23,либо — 12.
Кодовый словарь на 100 слов строится следующим образом:
Сотни
Источник: studfile.net
Defensive Programming

Защитное программирование (Defensive Programming)Это полезное средство для улучшения качества программного обеспечения.
Как понять это? Понимание идей защитного программирования может относиться к безопасному вождению:
При безопасном вождении выработайте установку на то, что никогда нельзя быть уверенным в том, что сделает другой водитель. Это гарантирует, что вы не пострадаете, когда другие сделают опасные шаги. Вы должны взять на себя ответственность защитить себя, даже если это ошибки, допущенные другими водителями.

Основные идеи защитного программирования:
Подпрограмма не должна быть уничтожена входящими данными об ошибках, даже если это данные об ошибках, сгенерированные другими подпрограммами.
В более общем смысле, основная идея состоит в том, чтобы признать, что у программ будут проблемы и их необходимо будет изменить. Умные программисты должны компилировать программы на основе этого момента. Эта идея состоит в том, чтобы ограничить влияние возможных ошибок ограниченным диапазоном. Внутри.
Защитите программу от уничтожения незаконных входных данных
В компьютерном поле есть предложениеGIGO(Garbage In Garbage Out)Разговор, переводМусор на входе, мусор на выходе,это значитПосле того, как поступают ненужные данные, они также становятся ненужными.。

На данный момент этот принцип сам по себе не может применяться к продуктам, которые были сформированы, но его следует выполнять.Мусор, ничего、Мусор внутри, сообщение об ошибке、Мусор поступает, фильтруется и извлекается, и получается полезная информация.ИлиНикакого мусора в. другими словами,GIGOСегодняшние стандарты кажутся признаком плохих процедур.
В случае защитного программирования есть три способа справиться с этой ситуацией:
1. Проверьте все данные из внешних источников.
При получении данных из файлов, пользователей, сетей или других внешних интерфейсов проверьте полученное значение данных, чтобы убедиться, что оно находится в допустимом диапазоне.
2. Проверьте значения всех входных параметров подпрограммы.
Проверка значения входного параметра подпрограммы фактически такая же, как проверка данных извне, за исключением того, что данные поступают из других подпрограмм, а не из внешних интерфейсов.
3. Решите, что делать с неверными входными данными.
Как с этим бороться после обнаружения недопустимого параметра? В зависимости от ситуации вы можете выбрать тот, который вам подходитТехнология обработки ошибокилиутверждениеИметь дело с.
Далее мы объясним методы, которые необходимо освоить в защитном программировании для вышеупомянутой ситуации:
утверждение

Утверждения — это код (обычно макрос или подпрограмма), который используется во время разработки, чтобы позволить программе выполнять самопроверку во время выполнения. Если утверждение верно, программа работает нормально, а если утверждение ложно, это означает, что в коде произошла ошибка.
Например: программа информации о клиентах требует, чтобы количество записей не превышало 10, мы добавляем утверждение. Когда количество записей меньше 10, утверждение будет молчать с двумя слезами, когда оно больше 10, утверждение будет громко говорить, что в программе ошибка!
Утверждения особенно важны для больших и сложных программ или программ с чрезвычайно высокими требованиями к надежности. Используя утверждения, программисты могут быстрее устранять несовпадающие интерфейсы и ошибки в программе из-за модификации кода или по другим причинам.
Утверждения, встроенные в OC: (Каждый поток iOS может указывать обработчик утверждений. Если вы хотите настроить подкласс NSAssertionHandler для обработки неудачных утверждений, установите поле NSAssertionHandlerKey в объекте threadDictionary потока.)
Для детской обуви, интересующейся NSAssertionHandler, переместите:Портал
#define NSAssert(condition, desc, ...)
do {
__PRAGMA_PUSH_NO_EXTRA_ARG_WARNINGS
if (__builtin_expect(!(condition), 0)) {
NSString *__assert_file__ = [NSString stringWithUTF8String:__FILE__];
__assert_file__ = __assert_file__ ? __assert_file__ : @"<Unknown File>";
[[NSAssertionHandler currentHandler] handleFailureInMethod:_cmd
object:self file:__assert_file__
lineNumber:__LINE__ description:(desc), ##__VA_ARGS__];
}
__PRAGMA_POP_NO_EXTRA_ARG_WARNINGS
} while(0)
#endif
Ниже представлены предложения при использовании утверждений:
1. Создайте свой собственный механизм утверждения.
Во многих случаях встроенные утверждения системы не могут удовлетворить наши потребности. Например, утверждения iOS не будут работать в режиме выпуска, поэтому мы можем настроить утверждения для адаптации к нашему проекту.
Ниже приведен пример макроса утверждения C ++:
#define ASSERT(condition, message) {
if (!condition) {
Log("ERROR ",condition,message);
exit( EXIT_FAILURE );
}
}
Пример в OC:
#define WYHAssert(condition, desc)
if (DEBUG) {
NSAssert(condition, desc);
}else {
NSString *app_build = [[NSBundle mainBundle].infoDictionary objectForKey:@"CFBundleVersion"];
NSLog (@ "Состояние ошибки утверждения:% @ (desc:% @) n Возникновение в <% s> <строка% d>, AppBuildVersion:% @", condition, desc, __ FILE __, __ LINE __, app_build);
[LogModule postLog];
}
2. Используйте коды обработки ошибок, чтобы справиться с ожидаемыми ситуациями, и используйте утверждения, чтобы справиться с ошибками, которые не могут возникнуть!
Разница между кодом утверждения и кода обработки ошибок:
Утверждения используются для проверки ситуаций, которые никогда не должны происходить, а коды обработки ошибок используются для проверки ситуаций, которые вряд ли будут часто возникать.Эти ситуации можно ожидать, когда код написан и официально присутствует в продукте. С этими ситуациями также следует обращаться при подключении к сети, поэтому обработка ошибок обычно используется для проверки вредоносных входных данных, а утверждения используются для проверки ошибок в коде!
Есть способ лучше понять утверждения:
Думайте об утверждении как об исполняемом комментарии. Вы не можете полагаться на него, чтобы заставить код работать должным образом, но он более проактивен в объяснении предположений в программе, чем комментарии на языке программирования.
3. Используйте утверждения для аннотирования предварительных и постусловий.
Существительные предварительных условий (предшествующих условий) и постусловий (постусловий) первоначально произошли отДизайн по контракту (DbC)При использовании дизайна контракта каждая подпрограмма или класс формирует контракт с остальной частью программы.
Многие языки поддерживают это утверждение. Однако DbC считает, что эти контракты критически важны для правильности программного обеспечения и должны быть частью процесса проектирования. Фактически, DbC рекомендует сначала писать утверждения. (Энциклопедия Baidu)
Предварительное условие: вызывающий код подпрограммы или класса должен гарантировать, что свойство истинно, прежде чем вызывать подпрограмму или создавать экземпляр объекта. Предварительным условием является обязанность вызывающего абонента выполнять вызываемый код.
Постусловие: после выполнения подпрограммы или класса убедитесь, что атрибут истинен. Постусловие — это ответственность подпрограммы или класса перед кодом вызывающего.
Утверждение — полезный инструмент для объяснения условий до и после.
Вот пример:
/// Координаты станции сигнализации
private class EStationCoordinate: NSObject {
var latitude: Float?
var longitude: Float?
var elevation: Float = 0.0
init(_ latitude: Float,_ longitude: Float,_ elevation: Float) {
super.init()
self.latitude = latitude
self.longitude = longitude
self.elevation = elevation
}
}
/// Получаем координаты станции сигнализации
///
/// - Parameters:
/// - latitude: <#latitude description#>
/// - longitude: <#longitude description#>
/// - elevation: <#elevation description#>
/// - Returns: <#return value description#>
private func createEmergencyCoordinate(_ latitude: Float,_ longitude: Float,_ elevation: Float) -> EStationCoordinate {
// precondition
assert(-90 <= latitude && latitude <= 90, "latitude must within range !");
assert(0 <= longitude && longitude < 360, "longitude must within range !");
assert(100 <= elevation && elevation < 500, "elevation must within range !");
// handle .... searching in local
// postcondition
assert(isContain, "local not contain this coordinate !")
var coordinate = EStationCoordinate(latitude,longitude,elevation)
return coordinate
}
Если переменные широта, долгота и высота находятся вне системы, то для проверки и работы с недопустимыми значениями следует использовать код обработки ошибок, и если значение переменной находится в надежной системе, и эта программа основана на этих Разработанный с предположением, что значение не будет превышать допустимый диапазон, использование утверждений очень уместно.
4. Избегайте добавления подпрограмм, которые необходимо выполнить, в утверждение.
Если вы напишете код подпрограммы, который должен быть выполнен в условии кодификации утверждения, то, когда вы отключите функцию утверждения, компилятор, скорее всего, исключит эти коды. Вот пример:
- (void)postFileToServer {
// .... make file
NSAssert([self compressFileToZip], @"File can't be compressed !");
// ... post to server
}
- (BOOL)compressFileToZip {
//... compress file and create a zip path !
if (zipPath.length > 0) {
return YES;
}
return NO;
}
Таким образом, если утверждение не скомпилировано, подпрограмма оператора условия не будет выполняться, и ее следует изменить следующим образом:
- (void)postFileToServer {
// .... make file
BOOL isCompressSuccess = [self compressFileToZip];
NSAssert(isCompressSuccess, @"File can't be compressed !");
// ... post to server
}
Технология обработки ошибок

Как мы упоминали ранее, утверждения имеют дело с ошибками, которые не должны возникать в программном коде, так как же поступать с ошибками, которые могут возникнуть в рамках наших ожиданий?
Прежде всего, мы должны прояснить, что для программ наиболее подходящий способ обработки ошибок зависит от типа программного обеспечения. Кроме того, есть две концепции для программ:Надежность и правильность
Устойчивость программы:Под устойчивостью понимается, в частности, степень, в которой система все еще может нормально вести себя при аномальном входе или ненормальной внешней среде.
Принцип надежности:
- Постоянно старайтесь принимать меры, чтобы допускать неправильный ввод, чтобы программа могла нормально работать (будьте консервативны со своим собственным кодом и открыты для поведения пользователя)
- Учитывайте всевозможные экстремальные ситуации, нет невозможного
- Даже если выполнение прекращено, необходимо точно / недвусмысленно показать пользователю подробное сообщение об ошибке.
- Сообщения об ошибках полезны для отладки
Например, если подпрограмма рисования в видеоигре получает неверный ввод цвета, вы можете использовать цвет фона или переднего плана по умолчанию, чтобы продолжить рисование, вместо сбоя или выхода из программы.
Правильность процедуры:Корректность означает, что программа никогда не вернет неточные результаты, даже если это не вернет никаких результатов или выйдет из программы напрямую.
Например, при разработке программного обеспечения для управления радиотерапевтическим оборудованием для лечения онкологических больных, когда программное обеспечение получает неправильную дозу облучения, может быть лучшим выбором напрямую закрыть программу. Даже перезапуск лучше, чем рисковать неправильной дозой облучения.
Таким образом, разница между ними заключается в следующем:
- Корректность: никогда не давайте пользователям неправильные результаты, даже если они вышли из программы.
- Надежность: поддерживайте работу программного обеспечения как можно дольше вместо того, чтобы постоянно выходить
Зная надежность и корректность программы, мы можем использовать следующие методы или комбинацию техник обработки ошибок:
1. Верните нейтральное значение:
Иногда лучший способ справиться с ошибками — продолжить операцию и просто вернуть безобидное значение.
Например, если подпрограмма рисования, основанная на цвете ввода, получает неправильный ввод цвета, она может игнорировать неправильный цвет и использовать цвет фона или переднего плана по умолчанию, чтобы продолжить рисование вместо сбоя.
2. Перейти к следующим правильным данным.
При обработке подпрограммы состояния опроса запроса, если выходные данные запроса неверны или неверны, вы можете игнорировать ошибочные данные и продолжать ждать, пока правильные данные будут считаны во время следующего опроса (например, если вы Считайте данные клинического термометра со скоростью 100 раз в секунду. Если данные, полученные в определенное время, неверны, мы можем подождать 1/100 секунды и продолжить считывание правильных данных)
3. Верните те же данные, что и в предыдущий раз.
Возьмем предыдущий пример: если термометр считывает неверные данные за 1/100 секунды, он может вернуться к последним правильным данным, потому что температура не сильно изменится в течение 1/100 секунды.
4. Выберите ближайшее допустимое значение.
Например, когда мы пишем программу, в которой ползунок скользит в указанной области, если ползунок превышает указанную область, мы можем взять безопасное значение, ближайшее к превышенной области, и вернуться.
5. Запишите информацию о предупреждении в файл журнала.
При обнаружении ошибочных данных вы можете записать предупреждающее сообщение в файл журнала и продолжить выполнение.
6. Верните код состояния ошибки.
Вы можете разрешить только определенным частям системы обрабатывать ошибки, а другие части не будут обрабатывать ошибки локально, а просто будут возвращать код ошибки.
Например, на странице редактирования информации о пользователе есть кнопка сохранения. Если некоторая информация введена неправильно, записывается только код ошибки. При нажатии кнопки сохранения определяется, существует ли код ошибки и разрешено ли пользователю выполнить следующую операцию.
7. Вызов подпрограмм или объектов обработки ошибок.
Обработка ошибок сосредоточена в подпрограмме или объекте глобальной обработки ошибок.Преимущество этого метода состоит в том, что функции обработки ошибок могут быть сосредоточены вместе, что упрощает отладку. Цена в том, что вся программа должна знать эту точку концентрации и быть тесно с ней связана.
Что это значит? Например, в серии контекстных запросов для всех ошибок запроса мы инкапсулируем только класс управления ошибками для централизованного управления этими ошибками.
8. Отображение сообщения об ошибке при возникновении ошибки.
Этот метод может минимизировать накладные расходы на обработку ошибок. Однако вам необходимо определить, является ли сообщение об ошибке удобным для пользователя. Напротив, для злоумышленника постарайтесь не позволить ему использовать сообщение об ошибке, чтобы узнать, как атаковать это. система.
9. Закройте программу.
Некоторые более склонны кПравильностьПри обнаружении ошибки лучше всего закрыть программу.
Как упоминалось вышеПрограммное обеспечение для радиотерапевтического оборудования для онкологических больных
аномальный

Исключение — это специальное средство передачи ошибок или аномальных событий в коде вызывающему коду.
Обработка исключений, называемая на английском языке исключительной обработкой, — это новый метод, который заменяет метод отклонения кода ошибки, обеспечивая определенные преимущества, недоступные для кода ошибки.Обработка исключений разделяет получение и обработку кодов ошибок.Эта функция проясняет мысли программиста, помогает повысить удобочитаемость кода и облегчает чтение и понимание сопровождающим. Функция обработки исключений (также известная как обработка ошибок) обеспечивает способ обработки любых непредвиденных или ненормальных ситуаций, возникающих во время работы программы. Обработка исключений использует ключевые слова try, catch и finally, чтобы попытаться выполнить операции, которые могут быть неудачными, обработать сбои и очистить ресурсы после их завершения. (Энциклопедия Baidu)
Если вы столкнулись с неожиданной ситуацией в подпрограмме, но не знаете, как с ней справиться, вы можете выбросить исключение.
Основная структура исключения следующая: подпрограмма использует throw для создания объекта исключения, который затем перехватывается оператором try-catch других подпрограмм в цепочке вызовов. (Встроенный механизм исключения предназначен для поиска в обратном направлении по вызову функции стека вызовов функций, пока не встретится код обработки исключения.)
Я знаю, что кто-то, должно быть, был ошеломлен, услышав это. Давайте посмотрим на следующий пример:
+ (void)tryFirstException {
@try {
// 1
[self trySecondException];
} @catch (NSException *exception) {
//2
NSLog(@"First reason:%@",exception.reason);
} @finally {
//3
}
//4
}
+ (void)trySecondException {
@try {
//5
[self tryThirldException];
} @catch (NSException *exception) {
//6
@throw exception; // Что будет, если вы прокомментируете этот код?
NSLog(@"Second reason:%@",exception.reason);
} @finally {
//7
}
//8
}
+ (void)tryThirldException {
//9
@throw [NSException exceptionWithName:@"Exc" reason:@"no reason!" userInfo:nil];
}
Кто-нибудь знает, как должна выполняться программа?
Многие распространенные языки программирования, включая Actionscript, Ada, BlitzMax, C ++, C #, D, ECMAScript, Eiffel, Java, ML, Object Pascal (например, Delphi, Free Pascal и т. Д.), Objective-C, Ocaml, PHP (версия 5) , PL / 1, Prolog, Python, REALbasic, Ruby, Visual Prolog и большинство языков программирования .NET, встроенный механизм исключений должен выполнять поиск в обратном направлении по стеку вызовов функции для вызова функции, пока не встретит код обработки исключения.Как правило, раскрутка стека выполняется поэтапно в процессе поиска этого кода обработки исключений.. Но Common Lisp является исключением. Он не использует откат стека, поэтому он позволяет возобновить выполнение кода, который генерирует исключение, на месте после обработки исключения.
Вот несколько советов по использованию исключений:
1. Используйте исключение, чтобы сообщить другим частям программы, что произошла неотвратимая ошибка.
Преимущество механизма исключений состоит в том, что он может предоставить механизм уведомления об ошибках, который нельзя игнорировать. Другие методы обработки ошибок могут вызвать распространение ошибок по незнанию, а исключения исключают эту возможность.
2. Выбрасывать исключения только в случае реальных исключений.
Используйте исключения только в том случае, если они действительно исключительные — другими словами, используйте исключения только тогда, когда другие методы кодирования не могут их решить. Эта ситуация похожа на утверждения — они используются для решения ситуаций, которые не только редки, но и никогда не должны происходить.
3. Не используйте исключения, чтобы уклониться от ответственности.
Если с определенной ошибкой можно справиться локально, то ее следует обрабатывать локально.Не создавайте ошибку, которую можно обработать как неперехваченное исключение.
4. Избегайте создания исключений в конструкторе и деструкторе, если вы не перехватываете их в одном месте.
Если вы попытаетесь вызвать исключение в конструкторе или деструкторе, обработка исключения станет очень сложной.
Например, в C ++ деструктор может быть вызван только после того, как объект будет полностью построен, то есть, если в конструкторе возникнет исключение, деструктор не будет вызван, что приведет к потенциальной утечке ресурсов.
5. Выбрасывайте исключения на соответствующем уровне абстракции.
Когда вы решите передать исключение вызывающей стороне, убедитесь, что уровень абстракции исключения согласован с уровнем абстракции интерфейса подпрограммы.
(Например, в подпрограмме типа A есть метод getDefenseId. На некоторых этапах метода мы генерируем исключение ошибки чтения и записи файла. Это должно было быть выполнено внутренним классом F нижнего уровня на постоянной основе, но он неправильно генерирует исключение в классе A, разрушает инкапсуляцию, а также раскрывает некоторые частные детали реализации, что, очевидно, не то, что мы хотим)
6. Добавьте всю информацию, вызвавшую исключение, в сообщение об исключении.
Например, если оно выбрано из-за ошибки значения индекса, сообщение об исключении должно включать верхнюю и нижнюю границы индекса, недопустимые значения индекса индекса и другую информацию.
7. Избегайте использования пустых операторов catch.
Не просматривайте исключение, с которым не знаете, как справиться
8. Рассмотрите возможность создания централизованного механизма отчетности об исключениях.
Подпрограмма (или базовый класс), которая инкапсулирует отчет об исключении, предназначена для быстрого и удобного сообщения об исключениях, которые необходимо активно генерировать в программе (обработчик исключений), а использование исключений будет более стандартизированным.
9. Рассмотрите ненормальный механизм замены.
Хотя некоторые языки программирования поддерживают исключения в течение 5-10 лет и более, все еще очень мало опыта в том, как безопасно использовать исключения.
Возьмем, к примеру, iOS,Apple.incХотя также предусмотрена обработка ошибок (NSError) И обработка исключений (ExceptionДва механизма, но Apple не рекомендует брать на себя инициативу по использованию Exception и рекомендует разработчикам использовать NSError для обработки исправимых ошибок во время работы программы. Исключение рекомендуется для устранения неисправимых ошибок.
Important: In many environments, use of exceptions is fairly commonplace. For example, you might throw an exception to signal that a routine could not execute normally—such as when a file is missing or data could not be parsed correctly. Exceptions are resource-intensive in Objective-C. You should not use exceptions for general flow-control, or simply to signify errors. Instead you should use the return value of a method or function to indicate that an error has occurred, and provide information about the problem in an error object. For more information, see Error Handling Programming Guide.
(developer.apple.com)
Если вас интересует детская обувь, посетите официальный сайт Apple.Портал
Еще одна вещь, хотя Apple не рекомендует часто активно использовать Exception, но для захвата исключений сбоя iOS может пройтиNSSetUncaughtExceptionHandlerЧтобы зафиксировать большинство сбоев, но стоит отметить, чтоПереполнение памяти、Дикий указатель BAD_ACCESSПроизошел сбой, напримерFlurryСредняя параcrashТак работает обработка.
- (void) uncaughtExceptionHandler(NSException *exception)
{
[Flurry logError:@"Uncaught" message:@"Crash!" exception:exception];
}
- (void)applicationDidFinishLaunching:(UIApplication *)application
{
NSSetUncaughtExceptionHandler(&uncaughtExceptionHandler);
[Flurry startSession:@"YOUR_API_KEY"];
// ....
}
Барьер

Barrier — это стратегия, допускающая потери в защитном программировании. Например, вы можете понять ее так:
Оболочка корпуса оборудована изоляционной кабиной. В случае столкновения корабля с айсбергом и разрыва корпуса изоляционная кабина будет закрыта для защиты остальной части корпуса от повреждений.
(БарьерИспользуется для звонкаБрандмауэр,но сейчасБрандмауэрЭтот термин часто используется для обозначения предотвращения злонамеренных кибератак)
Как показано ниже:

5 центов спецэффектыПеревод такой:

Предполагается, что данные внешнего интерфейса слева являются грязными и ненадежными, и эти классы (подпрограммы) в середине составляютБарьер, Ответственные за очистку и проверку данных и возврат доверенных данных, самые правые классы (подпрограммы) все работают в предположении, что данные чистые (безопасные), так что большая часть кода больше не должна отвечать за проверку неправильных данных !
Эту стратегию можно представить как более яркий пример, который можно рассматривать как стратегию, используемую в операционной.
Перед тем, как попасть в операционную, все должно быть продезинфицировано, чтобы все в операционной можно было считать безопасным. Основное дизайнерское решениеВ нем оговаривается, что можно и что нельзя входить в операционную и где установить дверь в операционную.
То же самое и в программировании. Согласовано, какие подпрограммы можно считать находящимися в безопасной зоне, какие — за пределами безопасной зоны, и которые отвечают за очистку данных (самый простой способ завершить эту работу — начать работу сразу после получения внешних данных. Очистка, но данные часто нуждаются в очистке более чем на одном уровне, поэтому иногда требуется многоуровневая очистка)
Применение барьеров:
Использование барьеров делает четкое различие между утверждением и обработкой ошибок. Программы за пределами барьеров должны использоватьТехнология обработки ошибок, Любые предположения относительно обработки данных небезопасны. И его нужно использовать в программе внутри отсекаТехника утверждения, Потому что входящие данные должны были быть очищены при прохождении через барьер. Если подпрограмма внутри отсека обнаруживает неверные данные, это должно быть ошибкой в программе, а не ошибкой вне программы.
Вспомогательный код отладки
Другим важным аспектом защитного программирования является использование помощников отладки (вспомогательный код отладки). Помощники отладки очень мощные и могут помочь нам быстро проверить наличие ошибок.
Во время разработки приложения следует пожертвовать некоторой скоростью и использованием ресурсов в обмен на некоторые встроенные инструменты, которые могут сделать разработку более плавной.
1. Вспомогательный отладочный код должен быть представлен как можно скорее.
Чем раньше вы вводите вспомогательный отладочный код, тем большую помощь он может оказать. Если вы часто сталкиваетесь с определенными проблемами, попробуйте написать или представить некоторыеВспомогательный код отладки, Это поможет вам на протяжении всего проекта.
2. Используйте наступательное программирование.

Что такое наступательное программирование? По сути, это тоже привычка защитного программирования. Идея заключается в следующем:
Постарайтесь выявить ненормальную ситуацию во время разработки и самовосстановления, когда продукт появится в сети.
Например, если у вас есть оператор switch case для обработки событий, вы должны попытаться рассмотреть все возможные ситуации и справиться с ними во время разработки.Кроме того, в операторе case по умолчанию вы можете использовать его, если он находится на этапе разработки.Наступательное программирование, И во время официального запуска продукта случай по умолчанию должен быть более безопасным, например, запись журнала ошибок.
Вот методы наступательного программирования:
- Убедитесь, что оператор утверждения вызывает завершение программы.
- Полностью заполнить всю выделенную память
- Полностью заполнить все файлы или потоки, которые были выделены
- Убедитесь, что ветвь по умолчанию или ветвь else в каждом операторе case может вызывать серьезные ошибки (например, завершение программы).
- Перед удалением заполните объект данными мусора
- Позвольте программе отправить журнал ошибок разработчику по электронной почте или push (в настоящее время используется службой безопасности)
3. Запланируйте удаление кода помощи отладки.
Если это коммерческое программное обеспечение, код, используемый для отладки, иногда делает программное обеспечение больше и медленнее, что оказывает огромное влияние на производительность программы. Заранее подготовьте планы, чтобы избежать путаницы между кодом отладки и исходным кодом программы. Вот несколько альтернативных методов удаления:
-
Используйте инструменты контроля версий, такие как ant и make
(Вы можете компилировать разные версии программы из одного и того же исходного кода. В режиме разработки вы можете позволить инструменту make включать все коды отладки и компилировать их вместе. Во время запуска продукта Исключите этот код отладки.) -
Используйте встроенный препроцессор (
C ++ # символ - это директива препроцессора, включая #if, #warning, #include, #define и т. Д.)
(если в вашей среде программирования есть препроцессор, вы можете использовать препроцессор для включения или исключения отлаженного кода)
- (void)handleSomething {
#ifdef DEBUG
[self debugF]; // Обычно отладка требует много времени
#else
[self releaseF];
#endif
}
- Добавить запись режима отладки для приложения
Если ваше приложение должно поддерживать оба режима (выпуск и отладка) одновременно, то мы можем настроить запись для перехода в режим отладки вместо DEBUG для уровня компиляции. Внедрение нашего кода отладки также зависит от того, включен ли этот режим отладки. Ниже будет продемонстрирован режим отладки, определенный в приложении безопасности.
Занять оборонительную позицию против защитного программирования
Сказав это, не лучше ли иметь более защитный код?
На самом деле это не так. Излишнее защитное программирование также может вызвать проблемы. Если вы будете использовать все мыслимые методы для проверки параметров и обработки ошибок во всех мыслимых местах, ваша программа станет раздутой и медленной. Что еще хуже, чрезмерный защитный код обменивается сложностью программного обеспечения.
Это показывает, что код, введенный защитным программированием, не лишен недостатков.Как и другие коды, вы можете легко найти ошибки в коде, добавленном защитным программированием, особенно если вы пишете эти коды случайно.
Поэтому подумайте, где вам нужно защищаться, а затем измените свой приоритет для защитного программирования с учетом местных условий.
подводить итоги
-
Способ обработки ошибок в программном коде намного лучше, чем
GIGOГораздо сложнее. -
Приемы защитного программирования могут упростить поиск ошибок, исправить их и уменьшить ущерб, наносимый ошибками коду продукта.
-
Следование идее защитного программирования для разработки позволит вам решать многие проблемы заранее на этапе разработки, улучшить качество кода, сократить циклы тестирования и проявить инициативу в поиске ошибок и их устранении (Не повезло, вы, конечно, можете рассмотреть еще несколько ситуаций, но вы должны игнорировать их возможности) Вместо того, чтобы ждать неожиданной катастрофы, вызванной неявным появлением ошибок.
-
Методы обработки ошибок больше подходят для открытых интерфейсных программ или классов, в то время как утверждения подчеркивают недопустимые ошибки и в основном подходят для закрытых методов (или внутренних классов), которые не отображаются.
-
Наиболее подходящий способ борьбы с ошибками основан на типе программного обеспечения, более склонном кПравильностьвсе ещеНадежность。
-
Исключения обеспечивают метод обработки ошибок, который отличается от обычного потока кода, но в то же время следует искать компромисс и сравнение между исключениями и другими методами обработки ошибок. Например, iOS редко использует механизмы обработки исключений.
-
Разумное использование вспомогательного отладочного кода позволит вам быстрее обнаруживать проблемы и спокойно их решать независимо от стадии разработки или выпуска. (Препроцессор — хороший выбор)
Наконец, мое понимание защитного программирования таково, что я считаю, что качество программы во многом зависит от ее надежности (и правильности). Все разработчики программ должны уделять ей достаточно внимания и проявлять инициативу в борьбе с ошибками. Начните с малого. Не игнорируйте никаких деталей. Не полагайтесь слепо на тесты для поиска ошибок. Вместо этого используйте программирование на основе тестов, постоянно думайте о возможных проблемах для их предотвращения и будьте умным программистом. Вот что нам говорит защитное программирование!
рекомендую
Наконец, перечислите цитируемые источники в статье и некоторые рекомендуемые статьи или книги:
-
«Энциклопедия кода 2-е издание» Глава 8 Защитное программирование
![]()
| Обноружение ошибок | ||||
| Исправление ошибок | ||||
| Коррекция ошибок | ||||
| Назад | ||||
Методы обнаружения ошибок
В обычном равномерном непомехоустойчивом коде число разрядов n в кодовых
комбинациях определяется числом сообщений и основанием кода.
Коды, у которых все кодовые комбинации разрешены, называются простыми или
равнодоступными и являются полностью безызбыточными. Безызбыточные коды обладают
большой «чувствительностью» к помехам. Внесение избыточности при использовании
помехоустойчивых кодов связано с увеличением n – числа разрядов кодовой комбинации. Таким
образом, все множество
 комбинаций можно разбить на два подмножества:
комбинаций можно разбить на два подмножества:
подмножество разрешенных комбинаций, обладающих определенными признаками, и
подмножество запрещенных комбинаций, этими признаками не обладающих.
Помехоустойчивый код отличается от обычного кода тем, что в канал передаются не все
кодовые комбинации N, которые можно сформировать из имеющегося числа разрядов n, а только
их часть Nk , которая составляет подмножество разрешенных комбинаций. Если при приеме
выясняется, что кодовая комбинация принадлежит к запрещенным, то это свидетельствует о
наличии ошибок в комбинации, т.е. таким образом решается задача обнаружения ошибок. При
этом принятая комбинация не декодируется (не принимается решение о переданном
сообщении). В связи с этим помехоустойчивые коды называют корректирующими кодами.
Корректирующие свойства избыточных кодов зависят от правила их построения, определяющего
структуру кода, и параметров кода (длительности символов, числа разрядов, избыточности и т. п.).
Первые работы по корректирующим кодам принадлежат Хеммингу, который ввел понятие
минимального кодового расстояния dmin и предложил код, позволяющий однозначно указать ту
позицию в кодовой комбинации, где произошла ошибка. К информационным элементам k в коде
Хемминга добавляется m проверочных элементов для автоматического определения
местоположения ошибочного символа. Таким образом, общая длина кодовой комбинации
составляет: n = k + m.
Метричное представление n,k-кодов
В настоящее время наибольшее внимание с точки зрения технических приложений
уделяется двоичным блочным корректирующим кодам. При использовании блочных кодов
цифровая информация передается в виде отдельных кодовых комбинаций (блоков) равной
длины. Кодирование и декодирование каждого блока осуществляется независимо друг от друга.
Почти все блочные коды относятся к разделимым кодам, кодовые комбинации которых
состоят из двух частей: информационной и проверочной. При общем числе n символов в блоке
число информационных символов равно k, а число проверочных символов:
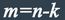
К основным характеристикам корректирующих кодов относятся:
|
— число разрешенных и запрещенных кодовых комбинаций; |
Для блочных двоичных кодов, с числом символов в блоках, равным n, общее число
возможных кодовых комбинаций определяется значением
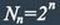
Число разрешенных кодовых комбинаций при наличии k информационных разрядов в
первичном коде:
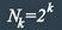
Очевидно, что число запрещенных комбинаций:
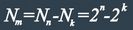
а с учетом ![]() отношение будет
отношение будет
![]()
где m – число избыточных (проверочных) разрядов в блочном коде.
Избыточностью корректирующего кода называют величину
![]()
откуда следует:
![]()
Эта величина показывает, какую часть общего числа символов кодовой комбинации
составляют информационные символы. В теории кодирования величину Bk называют
относительной скоростью кода. Если производительность источника информации равна H
символов в секунду, то скорость передачи после кодирования этой информации будет
![]()
поскольку в закодированной последовательности из каждых n символов только k символов
являются информационными.
Если число ошибок, которые нужно обнаружить или исправить, значительно, то необходимо
иметь код с большим числом проверочных символов. Чтобы при этом скорость передачи
оставалась достаточно высокой, необходимо в каждом кодовом блоке одновременно
увеличивать как общее число символов, так и число информационных символов.
При этом длительность кодовых блоков будет существенно возрастать, что приведет к
задержке информации при передаче и приеме. Чем сложнее кодирование, тем длительнее
временная задержка информации.
Минимальное кодовое расстояние – dmin. Для того чтобы можно было обнаружить и
исправлять ошибки, разрешенная комбинация должна как можно больше отличаться от
запрещенной. Если ошибки в канале связи действуют независимо, то вероятность преобразования
одной кодовой комбинации в другую будет тем меньше, чем большим числом символов они
различаются.
Если интерпретировать кодовые комбинации как точки в пространстве, то отличие
выражается в близости этих точек, т. е. в расстоянии между ними.
Количество разрядов (символов), которыми отличаются две кодовые комбинации, можно
принять за кодовое расстояние между ними. Для определения этого расстояния нужно сложить
две кодовые комбинации «по модулю 2» и подсчитать число единиц в полученной сумме.
Например, две кодовые комбинации xi = 01011 и xj = 10010 имеют расстояние d(xi,xj) , равное 3,
так как:

Здесь под операцией ⊕ понимается сложение «по модулю 2».
Заметим, что кодовое расстояние d(xi,x0) между комбинацией xi и нулевой x0 = 00…0
называют весом W комбинации xi, т.е. вес xi равен числу «1» в ней.
Расстояние между различными комбинациями некоторого конкретного кода могут
существенно отличаться. Так, в частности, в безызбыточном первичном натуральном коде n = k это
расстояние для различных комбинаций может изменяться от единицы до величины n, равной
разрядности кода. Особую важность для характеристики корректирующих свойств кода имеет
минимальное кодовое расстояние dmin, определяемое при попарном сравнении всех кодовых
комбинаций, которое называют расстоянием Хемминга.
В безызбыточном коде все комбинации являются разрешенными и его минимальное
кодовое расстояние равно единице – dmin=1. Поэтому достаточно исказиться одному символу,
чтобы вместо переданной комбинации была принята другая разрешенная комбинация. Чтобы код
обладал корректирующими свойствами, необходимо ввести в него некоторую избыточность,
которая обеспечивала бы минимальное расстояние между любыми двумя разрешенными
комбинациями не менее двух – dmin ≥ 2..
Минимальное кодовое расстояние является важнейшей характеристикой помехоустойчивых
кодов, указывающей на гарантируемое число обнаруживаемых или исправляемых заданным
кодом ошибок.
Число обнаруживаемых или исправляемых ошибок
При применении двоичных кодов учитывают только дискретные искажения, при которых
единица переходит в нуль («1» → «0») или нуль переходит в единицу («0» → «1»). Переход «1» →
«0» или «0» → «1» только в одном элементе кодовой комбинации называют единичной ошибкой
(единичным искажением). В общем случае под кратностью ошибки подразумевают число
позиций кодовой комбинации, на которых под действием помехи одни символы оказались
замененными на другие. Возможны двукратные (g = 2) и многократные (g > 2) искажения
элементов в кодовой комбинации в пределах 0 ≤ g ≤ n.
Минимальное кодовое расстояние является основным параметром, характеризующим
корректирующие способности данного кода. Если код используется только для обнаружения
ошибок кратностью g0, то необходимо и достаточно, чтобы минимальное кодовое расстояние
было равно dmin ≥ g0 + 1.
В этом случае никакая комбинация из go ошибок не может перевести одну разрешенную
кодовую комбинацию в другую разрешенную. Таким образом, условие обнаружения всех ошибок
кратностью g0 можно записать
![]()
Чтобы можно было исправить все ошибки кратностью gu и менее, необходимо иметь
минимальное расстояние, удовлетворяющее условию dmin ≥ 2gu
![]()
В этом случае любая кодовая комбинация с числом ошибок gu отличается от каждой
разрешенной комбинации не менее чем в gu+1 позициях. Если условие ![]() не выполнено,
не выполнено,
возможен случай, когда ошибки кратности g исказят переданную комбинацию так, что она станет
ближе к одной из разрешенных комбинаций, чем к переданной или даже перейдет в другую
разрешенную комбинацию. В соответствии с этим, условие исправления всех ошибок кратностью
не более gи можно записать:
![]()
Из ![]() и
и ![]()
следует, что если код исправляет все ошибки кратностью gu, то число
ошибок, которые он может обнаружить, равно go = 2gu. Следует отметить, что эти соотношения
устанавливают лишь гарантированное минимальное число обнаруживаемых или
исправляемых ошибок при заданном dmin и не ограничивают возможность обнаружения ошибок
большей кратности. Например, простейший код с проверкой на четность с dmin = 2 позволяет
обнаруживать не только одиночные ошибки, но и любое нечетное число ошибок в пределах go < n.
Корректирующие возможности кодов
Вопрос о минимально необходимой избыточности, при которой код обладает нужными
корректирующими свойствами, является одним из важнейших в теории кодирования. Этот вопрос
до сих пор не получил полного решения. В настоящее время получен лишь ряд верхних и нижних
оценок (границ), которые устанавливают связь между максимально возможным минимальным
расстоянием корректирующего кода и его избыточностью.
Коды Хэмминга
Построение кодов Хемминга базируется на принципе проверки на четность веса W (числа
единичных символов «1») в информационной группе кодового блока.
Поясним идею проверки на четность на примере простейшего корректирующего кода,
который так и называется кодом с проверкой на четность или кодом с проверкой по паритету
(равенству).
В таком коде к кодовым комбинациям безызбыточного первичного двоичного k-разрядного
кода добавляется один дополнительный разряд (символ проверки на четность, называемый
проверочным, или контрольным). Если число символов «1» исходной кодовой комбинации
четное, то в дополнительном разряде формируют контрольный символ «0», а если число
символов «1» нечетное, то в дополнительном разряде формируют символ «1». В результате
общее число символов «1» в любой передаваемой кодовой комбинации всегда будет четным.
Таким образом, правило формирования проверочного символа сводится к следующему:
![]()
где i – соответствующий информационный символ («0» или «1»); k – общее их число а, под
операцией ⊕ здесь и далее понимается сложение «по модулю 2». Очевидно, что добавление
дополнительного разряда увеличивает общее число возможных комбинаций вдвое по сравнению
с числом комбинаций исходного первичного кода, а условие четности разделяет все комбинации
на разрешенные и неразрешенные. Код с проверкой на четность позволяет обнаруживать
одиночную ошибку при приеме кодовой комбинации, так как такая ошибка нарушает условие
четности, переводя разрешенную комбинацию в запрещенную.
Критерием правильности принятой комбинации является равенство нулю результата S
суммирования «по модулю 2» всех n символов кода, включая проверочный символ m1. При
наличии одиночной ошибки S принимает значение 1:
![]() — ошибок нет,
— ошибок нет,
![]() — однократная ошибка
— однократная ошибка
Этот код является (k+1,k)-кодом, или (n,n–1)-кодом. Минимальное расстояние кода равно
двум (dmin = 2), и, следовательно, никакие ошибки не могут быть исправлены. Простой код с
проверкой на четность может использоваться только для обнаружения (но не исправления)
однократных ошибок.
Увеличивая число дополнительных проверочных разрядов, и формируя по определенным
правилам проверочные символы m, равные «0» или «1», можно усилить корректирующие
свойства кода так, чтобы он позволял не только обнаруживать, но и исправлять ошибки. На этом и
основано построение кодов Хемминга.
Коды Хемминга позволяют исправлять одиночную ошибку, с помощью непосредственного
описания. Для каждого числа проверочных символов m =3, 4, 5… существует классический код
Хемминга с маркировкой
![]()
т.е. (7,4), (15,11) (31,26) …
При других значениях числа информационных символов k получаются так называемые
усеченные (укороченные) коды Хемминга. Так для кода имеющего 5 информационных символов,
потребуется использование корректирующего кода (9,5), являющегося усеченным от
классического кода Хемминга (15,11), так как число символов в этом коде уменьшается
(укорачивается) на 6.
Для примера рассмотрим классический код Хемминга (7,4), который можно сформировать и
описать с помощью кодера, представленного на рис. 1 В простейшем варианте при заданных
четырех информационных символах: i1, i2, i3, i4 (k = 4), будем полагать, что они сгруппированы в
начале кодового слова, хотя это и не обязательно. Дополним эти информационные символы
тремя проверочными символами (m = 3), задавая их следующими равенствами проверки на
четность, которые определяются соответствующими алгоритмами, где знак ⊕ означает
сложение «по модулю 2»: r1 = i1 ⊕ i2 ⊕ i3, r2 = i2 ⊕ i3 ⊕ i4, r3 = i1 ⊕ i2 ⊕ i4.
В соответствии с этим алгоритмом определения значений проверочных символов mi, в табл.
1 выписаны все возможные 16 кодовых слов (7,4)-кода Хемминга.
Таблица 1 Кодовые слова (7,4)-кода Хэмминга
|
k=4 |
m=4 |
|
i1 i2 i3 i4 |
r1 r2 r3 |
|
0 0 0 0 |
0 0 0 |
|
0 0 0 1 |
0 1 1 |
|
0 0 1 0 |
1 1 0 |
|
0 0 1 1 |
1 0 1 |
|
0 1 0 0 |
1 1 1 |
|
0 1 0 1 |
1 0 0 |
|
0 1 1 0 |
0 0 1 |
|
0 1 1 1 |
0 1 0 |
|
1 0 0 0 |
1 0 1 |
|
1 0 0 1 |
1 0 0 |
|
1 0 1 0 |
0 1 1 |
|
1 0 1 1 |
0 0 0 |
|
1 1 0 0 |
0 1 0 |
|
1 1 0 1 |
0 0 1 |
|
1 1 1 0 |
1 0 0 |
|
1 1 1 1 |
1 1 1 |
На рис.1 приведена блок-схема кодера – устройства автоматически кодирующего
информационные разряды в кодовые комбинации в соответствии с табл.1
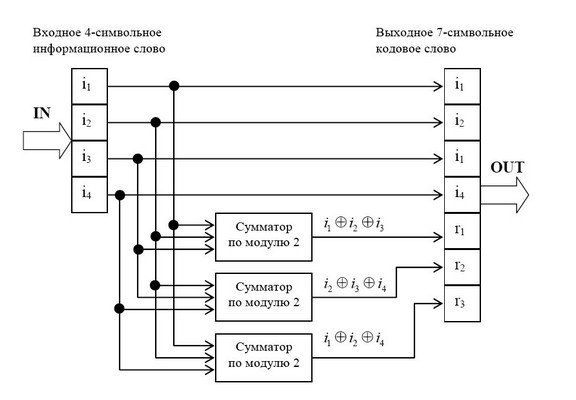
Рис. 1 Кодер для (7,4)-кода Хемминга
На рис. 1.4 приведена схема декодера для (7,4) – кода Хемминга, на вход которого
поступает кодовое слово
![]() . Апостроф означает, что любой символ слова может
. Апостроф означает, что любой символ слова может
быть искажен помехой в телекоммуникационном канале.
В декодере в режиме исправления ошибок строится последовательность:
![]()
![]()
![]()
Трехсимвольная последовательность (s1, s2, s3) называется синдромом. Термин «синдром»
используется и в медицине, где он обозначает сочетание признаков, характерных для
определенного заболевания. В данном случае синдром S = (s1, s2, s3) представляет собой
сочетание результатов проверки на четность соответствующих символов кодовой группы и
характеризует определенную конфигурацию ошибок (шумовой вектор).
Число возможных синдромов определяется выражением:
![]()
При числе проверочных символов m =3 имеется восемь возможных синдромов (23 = .
Нулевой синдром (000) указывает на то, что ошибки при приеме отсутствуют или не обнаружены.
Всякому ненулевому синдрому соответствует определенная конфигурация ошибок, которая и
исправляется. Классические коды Хемминга имеют число синдромов, точно равное их
необходимому числу (что позволяет исправить все однократные ошибки в любом информативном
и проверочном символах) и включают один нулевой синдром. Такие коды называются
плотноупакованными.
Усеченные коды являются неплотноупакованными, так как число синдромов у них
превышает необходимое. Так, в коде (9,5) при четырех проверочных символах число синдромов
будет равно 24 =16, в то время как необходимо всего 10. Лишние 6 синдромов свидетельствуют о
неполной упаковке кода (9,5).
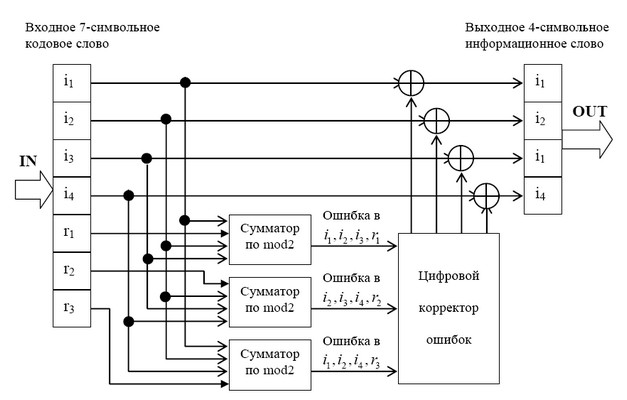
Рис. 2 Декодер для (7, 4)-кода Хемминга
Для рассматриваемого кода (7,4) в табл. 2 представлены ненулевые синдромы и
соответствующие конфигурации ошибок.
Таблица 2 Синдромы (7, 4)-кода Хемминга
|
Синдром |
001 |
010 |
011 |
100 |
101 |
110 |
111 |
|
Конфигурация ошибок |
0000001 |
0000010 |
0000100 |
0001000 |
0010000 |
0100000 |
1000000 |
|
Ошибка в символе |
m1 |
m2 |
i4 |
m1 |
i1 |
i3 |
i2 |
Таким образом, (7,4)-код позволяет исправить все одиночные ошибки. Простая проверка
показывает, что каждая из ошибок имеет свой единственный синдром. При этом возможно
создание такого цифрового корректора ошибок (дешифратора синдрома), который по
соответствующему синдрому исправляет соответствующий символ в принятой кодовой группе.
После внесения исправления проверочные символы ri можно на выход декодера (рис. 2) не
выводить. Две или более ошибок превышают возможности корректирующего кода Хемминга, и
декодер будет ошибаться. Это означает, что он будет вносить неправильные исправления и
выдавать искаженные информационные символы.
Идея построения подобного корректирующего кода, естественно, не меняется при
перестановке позиций символов в кодовых словах. Все такие варианты также называются (7,4)-
кодами Хемминга.
Циклические коды
Своим названием эти коды обязаны такому факту, что для них часть комбинаций, либо все
комбинации могут быть получены путем циклическою сдвига одной или нескольких базовых
комбинаций кода.
Построение такого кода основывается на использовании неприводимых многочленов в поле
двоичных чисел. Такие многочлены не могут быть представлены в виде произведения
многочленов низших степеней подобно тому, как простые числа не могут быть представлены
произведением других чисел. Они делятся без остатка только на себя или на единицу.
Для определения неприводимых многочленов раскладывают на простые множители бином
хn -1. Так, для n = 7 это разложение имеет вид:
(x7)=(x-1)(x3+x2)(x3+x-1)
Каждый из полученных множителей разложения может применяться для построения
корректирующего кода.
Неприводимый полином g(x) называют задающим, образующим или порождающим
для корректирующего кода. Длина n (число разрядов) создаваемого кода произвольна.
Кодовая последовательность (комбинация) корректирующего кода состоит из к информационных
разрядов и n — к контрольных (проверочных) разрядов. Степень порождающего полинома
r = n — к равна количеству неинформационных контрольных разрядов.
Если из сделанного выше разложения (при n = 7) взять полипом (х — 1), для которого
r=1, то k=n-r=7-1=6. Соответствующий этому полиному код используется для контроля
на чет/нечет (обнаружение ошибок). Для него минимальное кодовое расстояние D0 = 2
(одна единица от D0 — для исходного двоичного кода, вторая единица — за счет контрольного разряда).
Если же взять полином (x3+x2+1) из указанного разложения, то степень полинома
r=3, а k=n-r=7-3=4.
Контрольным разрядам в комбинации для некоторого кода могут быть четко определено место (номера разрядов).
Тогда код называют систематическим или разделимым. В противном случае код является неразделимым.
Способы построения циклических кодов по заданному полиному.
1) На основе порождающей (задающей) матрицы G, которая имеет n столбцов, k строк, то есть параметры которой
связаны с параметрами комбинаций кода. Порождающую матрицу строят, взяв в качестве ее строк порождающий
полином g(x) и (k — 1) его циклических сдвигов:
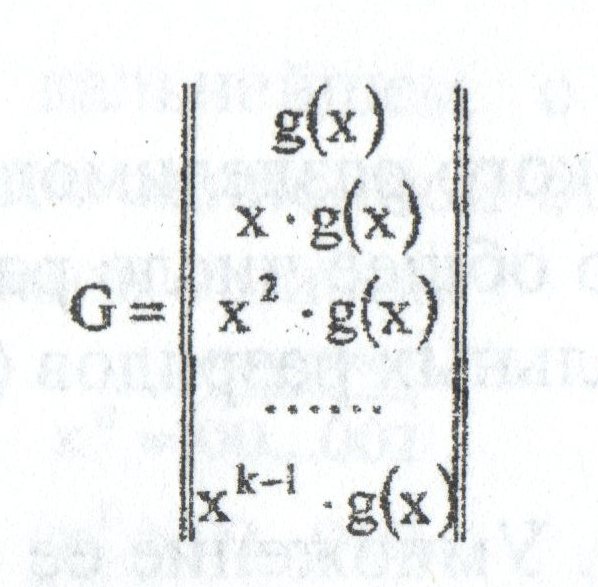
Пример; Определить порождающую матрицу, если известно, что n=7, k=4, задающий полином g(x)=x3+х+1.
Решение: Кодовая комбинация, соответствующая задающему полиному g(x)=x3+х+1, имеет вид 1011.
Тогда порождающая матрица G7,4 для кода при n=7, к=4 с учетом того, что k-1=3, имеет вид:

Порождающая матрица содержит k разрешенных кодовых комбинаций. Остальные комбинации кода,
количество которых (2k — k) можно определить суммированием по модулю 2 всевозможных сочетаний
строк матрицы Gn,k. Для матрицы, полученной в приведенном выше примере, суммирование по модулю 2
четырех строк 1-2, 1-3, 1-4, 2-3, 2-4, 3-4 дает следующие кодовые комбинации циклического кода:
001110101001111010011011101010011101110100
Другие комбинации искомого корректирующего кода могут быть получены сложением трех комбинаций, например,
из сочетания строк 1-3-4, что дает комбинацию 1111111, а также сложением четырех строк 1-2-3-4, что
дает комбинацию 1101001 и т.д.
Ряд комбинаций искомого кода может быть получено путем дальнейшего циклического сдвига комбинаций
порождающей матрицы, например, 0110001, 1100010, 1000101. Всего для образования искомого циклического
кода требуется 2k=24=16 комбинаций.
2) Умножение исходных двоичных кодовых комбинаций на задающий полином.
Исходными комбинациями являются все k-разрядные двоичные комбинации. Так, например, для исходной
комбинации 1111 (при k = 4) умножение ее на задающий полином g(x)=x3+х+1=1011 дает 1101001.
Полученные на основе двух рассмотренных способов циклические коды не являются разделимыми.
3) Деление на задающий полином.
Для получения разделимого (систематического) циклического кода необходимо разделить многочлен
xn-k*h(x), где h(x) — исходная двоичная комбинация, на задающий полином g(x) и прибавить полученный
остаток от деления к многочлену xn-k*h(x).
Заметим, что умножение исходной комбинации h(x) на xn-k эквивалентно сдвигу h(x) на (n-к) разрядов влево.
Пример: Требуется определить комбинации циклического разделимого кода, заданного полиномом g(x)=x3+х+1=1011 и
имеющего общее число разрядов 7, число информационных разрядов 4, число контрольных разрядов (n-k)=3.
Решение: Пусть исходная комбинация h(x)=1100. Умножение ее на xn-k=x3=1000 дает
x3*(x3+x2)=1100000, то есть эквивалентно
сдвигу исходной комбинации на 3 разряда влево. Деление комбинации 1100000 на комбинацию 1011, эквивалентно задающему полиному, дает:

Полученный остаток от деления, содержащий xn-k=3 разряда, прибавляем к полиному, в результате чего получаем искомую комбинацию
разделимого циклического кода: 1100010. В ней 4 старших разряда (слева) соответствуют исходной двоичной комбинации, а три младших
разряда являются контрольными.
Следует сделать ряд указаний относительно процедуры деления:
1) При делении задающий полином совмещается старшим разрядом со старшим «единичными разрядом делимого.
2) Вместо вычитания по модулю 2 выполняется эквивалентная ему процедура сложения по модулю 2.
3) Деление продолжается до тех пор, пока степень очередного остатка не будет меньше степени делителя (задающего полинома). При достижении
этого полученный остаток соответствует искомому содержанию контрольных разрядов для данной искомой двоичной комбинации.
Для проверки правильности выполнения процедуры определения комбинации циклического кода необходимо разделить полученную комб1шацию на задающий полином с
учетом сделанных выше замечаний. Получение нулевого остатка от такого деления свидетельствует о правильности определения комбинации.
Логический код 4В/5В
Логический код 4В/5В заменяет исходные символы длиной в 4 бита на символы длиной в 5 бит. Так как результирующие символы содержат избыточные биты, то
общее количество битовых комбинаций в них больше, чем в исходных. Таким образом, пяти-битовая схема дает 32 (25) двухразрядных буквенно-цифровых символа,
имеющих значение в десятичном коде от 00 до 31. В то время как исходные данные могут содержать только четыре бита или 16 (24) символов.
Поэтому в результирующем коде можно подобрать 16 таких комбинаций, которые не содержат большого количества нулей, а остальные считать запрещенными кодами
(code violation). В этом случае длинные последовательности нулей прерываются, и код становится самосинхронизирующимся для любых передаваемых данных.
Исчезает также постоянная составляющая, а значит, еще более сужается спектр сигнала. Но этот метод снижает полезную пропускную способность линии,
так как избыточные единицы пользовательской информации не несут, и только «занимают эфирное время». Избыточные коды позволяют приемнику распознавать
искаженные биты. Если приемник принимает запрещенный код, значит, на линии произошло искажение сигнала.
Итак, рассмотрим работу логического кода 4В/5В. Преобразованный сигнал имеет 16 значений для передачи информации и 16 избыточных значений. В декодере
приемника пять битов расшифровываются как информационные и служебные сигналы.
Для служебных сигналов отведены девять символов, семь символов — исключены.
Исключены комбинации, имеющие более трех нулей (01 — 00001, 02 — 00010, 03 — 00011, 08 — 01000, 16 — 10000). Такие сигналы интерпретируются символом
V и командой приемника VIOLATION — сбой. Команда означает наличие ошибки из-за высокого уровня помех или сбоя передатчика. Единственная
комбинация из пяти нулей (00 — 00000) относится к служебным сигналам, означает символ Q и имеет статус QUIET — отсутствие сигнала в линии.
Такое кодирование данных решает две задачи — синхронизации и улучшения помехоустойчивости. Синхронизация происходит за счет исключения
последовательности более трех нулей, а высокая помехоустойчивость достигается приемником данных на пяти-битовом интервале.
Цена за эти достоинства при таком способе кодирования данных — снижение скорости передачи полезной информации.
К примеру, В результате добавления одного избыточного бита на четыре информационных, эффективность использования полосы
частот в протоколах с кодом MLT-3 и кодированием данных 4B/5B уменьшается соответственно на 25%.
Схема кодирования 4В/5В представлена в таблице.
|
Двоичный код 4В |
Результирующий код 5В |
|
0 0 0 0 |
1 1 1 1 0 |
|
0 0 0 1 |
0 1 0 0 1 |
|
0 0 1 0 |
1 0 1 0 0 |
|
0 0 1 1 |
1 0 1 0 1 |
|
0 1 0 0 |
0 1 0 1 0 |
|
0 1 0 1 |
0 1 0 1 1 |
|
0 1 1 0 |
0 1 1 1 0 |
|
0 1 1 1 |
0 1 1 1 1 |
|
1 0 0 0 |
1 0 0 1 0 |
|
1 0 0 1 |
1 0 0 1 1 |
|
1 0 1 0 |
1 0 1 1 0 |
|
1 0 1 1 |
1 0 1 1 1 |
|
1 1 0 0 |
1 1 0 1 0 |
|
1 1 0 1 |
1 1 0 1 1 |
|
1 1 1 0 |
1 1 1 0 0 |
|
1 1 1 1 |
1 1 1 0 1 |
Итак, соответственно этой таблице формируется код 4В/5В, затем передается по линии с помощью физического кодирования по
одному из методов потенциального кодирования, чувствительному только к длинным последовательностям нулей — например, в помощью
цифрового кода NRZI.
Символы кода 4В/5В длиной 5 бит гарантируют, что при любом их сочетании на линии не могут встретиться более трех нулей подряд.
Буква ^ В в названии кода означает, что элементарный сигнал имеет 2 состояния — от английского binary — двоичный. Имеются
также коды и с тремя состояниями сигнала, например, в коде 8В/6Т для кодирования 8 бит исходной информации используется
код из 6 сигналов, каждый из которых имеет три состояния. Избыточность кода 8В/6Т выше, чем кода 4В/5В, так как на 256
исходных кодов приходится 36=729 результирующих символов.
Как мы говорили, логическое кодирование происходит до физического, следовательно, его осуществляют оборудование канального
уровня сети: сетевые адаптеры и интерфейсные блоки коммутаторов и маршрутизаторов. Поскольку, как вы сами убедились,
использование таблицы перекодировки является очень простой операцией, поэтому метод логического кодирования избыточными
кодами не усложняет функциональные требования к этому оборудованию.
Единственное требование — для обеспечения заданной пропускной способности линии передатчик, использующий избыточный код,
должен работать с повышенной тактовой частотой. Так, для передачи кодов 4В/5В со скоростью 100 Мб/с передатчик должен
работать с тактовой частотой 125 МГц. При этом спектр сигнала на линии расширяется по сравнению со случаем, когда по
линии передается чистый, не избыточный код. Тем не менее, спектр избыточного потенциального кода оказывается уже
спектра манчестерского кода, что оправдывает дополнительный этап логического кодирования, а также работу приемника
и передатчика на повышенной тактовой частоте.
В основном для локальных сетей проще, надежней, качественней, быстрей — использовать логическое кодирование данных
с помощью избыточных кодов, которое устранит длительные последовательности нулей и обеспечит синхронизацию
сигнала, потом на физическом уровне использовать для передачи быстрый цифровой код NRZI, нежели без предварительного
логического кодирования использовать для передачи данных медленный, но самосинхронизирующийся манчестерский код.
Например, для передачи данных по линии с пропускной способностью 100М бит/с и полосой пропускания 100 МГц,
кодом NRZI необходимы частоты 25 — 50 МГц, это без кодирования 4В/5В. А если применить для NRZI еще и
кодирование 4В/5В, то теперь полоса частот расширится от 31,25 до 62,5 МГц. Но тем не менее, этот диапазон
еще «влазит» в полосу пропускания линии. А для манчестерского кода без применения всякого дополнительного
кодирования необходимы частоты от 50 до 100 МГц, и это частоты основного сигнала, но они уже не будут пропускаться
линией на 100 МГц.
Скрэмблирование
Другой метод логического кодирования основан на предварительном «перемешивании» исходной информации таким
образом, чтобы вероятность появления единиц и нулей на линии становилась близкой.
Устройства, или блоки, выполняющие такую операцию, называются скрэмблерами (scramble — свалка, беспорядочная сборка) .
При скремблировании данные перемешиваються по определенному алгоритму и приемник, получив двоичные данные, передает
их на дескрэмблер, который восстанавливает исходную последовательность бит.
Избыточные биты при этом по линии не передаются.
Суть скремблирования заключается просто в побитном изменении проходящего через систему потока данных. Практически
единственной операцией, используемой в скремблерах является XOR — «побитное исключающее ИЛИ», или еще говорят —
сложение по модулю 2. При сложении двух единиц исключающим ИЛИ отбрасывается старшая единица и результат записывается — 0.
Метод скрэмблирования очень прост. Сначала придумывают скрэмблер. Другими словами придумывают по какому соотношению
перемешивать биты в исходной последовательности с помощью «исключающего ИЛИ». Затем согласно этому соотношению из текущей
последовательности бит выбираются значения определенных разрядов и складываются по XOR между собой. При этом все разряды
сдвигаются на 1 бит, а только что полученное значение («0» или «1») помещается в освободившийся самый младший разряд.
Значение, находившееся в самом старшем разряде до сдвига, добавляется в кодирующую последовательность, становясь очередным
ее битом. Затем эта последовательность выдается в линию, где с помощью методов физического кодирования передается к
узлу-получателю, на входе которого эта последовательность дескрэмблируется на основе обратного отношения.
Например, скрэмблер может реализовывать следующее соотношение:
![]()
где Bi — двоичная цифра результирующего кода, полученная на i-м такте работы скрэмблера, Ai — двоичная цифра исходного
кода, поступающая на i-м такте на вход скрэмблера, Bi-3 и Bi-5 — двоичные цифры результирующего кода, полученные на
предыдущих тактах работы скрэмблера, соответственно на 3 и на 5 тактов ранее текущего такта, ⊕ — операция исключающего
ИЛИ (сложение по модулю 2).
Теперь давайте, определим закодированную последовательность, например, для такой исходной последовательности 110110000001.
Скрэмблер, определенный выше даст следующий результирующий код:
B1=А1=1 (первые три цифры результирующего кода будут совпадать с исходным, так как еще нет нужных предыдущих цифр)
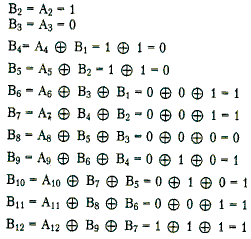
Таким образом, на выходе скрэмблера появится последовательность 110001101111. В которой нет последовательности из шести нулей, п
рисутствовавшей в исходном коде.
После получения результирующей последовательности приемник передает ее дескрэмблеру, который восстанавливает исходную
последовательность на основании обратного соотношения.
![]()
Существуют другие различные алгоритмы скрэмблирования, они отличаются количеством слагаемых, дающих цифру
результирующего кода, и сдвигом между слагаемыми.
Главная проблема кодирования на основе скремблеров — синхронизация передающего (кодирующего) и принимающего
(декодирующего) устройств. При пропуске или ошибочном вставлении хотя бы одного бита вся передаваемая информация
необратимо теряется. Поэтому, в системах кодирования на основе скремблеров очень большое внимание уделяется методам синхронизации.
На практике для этих целей обычно применяется комбинация двух методов:
а) добавление в поток информации синхронизирующих битов, заранее известных приемной стороне, что позволяет ей при ненахождении
такого бита активно начать поиск синхронизации с отправителем,
б) использование высокоточных генераторов временных импульсов, что позволяет в моменты потери синхронизации производить
декодирование принимаемых битов информации «по памяти» без синхронизации.
Существуют и более простые методы борьбы с последовательностями единиц, также относимые к классу скрэмблирования.
Для улучшения кода ^ Bipolar AMI используются два метода, основанные на искусственном искажении последовательности нулей запрещенными символами.
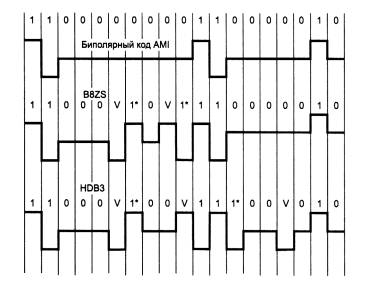
Рис. 3 Коды B8ZS и HDB3
На этом рисунке показано использование метода ^ B8ZS (Bipolar with 8-Zeros Substitution) и метода HDB3 (High-Density Bipolar 3-Zeros) для корректировки
кода AMI. Исходный код состоит из двух длинных последовательностей нулей (8- в первом случае и 5 во втором).
Код B8ZS исправляет только последовательности, состоящие из 8 нулей. Для этого он после первых трех нулей вместо оставшихся пяти нулей вставляет пять
цифр: V-1*-0-V-1*. V здесь обозначает сигнал единицы, запрещенной для данного такта полярности, то есть сигнал, не изменяющий полярность предыдущей
единицы, 1* — сигнал единицы корректной полярности, а знак звездочки отмечает тот факт, что в исходном коде в этом такте была не единица, а ноль. В
результате на 8 тактах приемник наблюдает 2 искажения — очень маловероятно, что это случилось из-за шума на линии или других сбоев передачи. Поэтому
приемник считает такие нарушения кодировкой 8 последовательных нулей и после приема заменяет их на исходные 8 нулей.
Код B8ZS построен так, что его постоянная составляющая равна нулю при любых последовательностях двоичных цифр.
Код HDB3 исправляет любые 4 подряд идущих нуля в исходной последовательности. Правила формирования кода HDB3 более сложные, чем кода B8ZS.
Каждые четыре нуля заменяются четырьмя сигналами, в которых имеется один сигнал V. Для подавления постоянной составляющей полярность сигнала
V чередуется при последовательных заменах.
Кроме того, для замены используются два образца четырехтактовых кодов. Если перед заменой исходный код содержал нечетное число единиц, то
используется последовательность 000V, а если число единиц было четным — последовательность 1*00V.
Таким образом, применение логическое кодирование совместно с потенциальным кодированием дает следующие преимущества:
Улучшенные потенциальные коды обладают достаточно узкой полосой пропускания для любых последовательностей единиц и нулей,
которые встречаются в передаваемых данных. В результате коды, полученные из потенциального путем логического кодирования,
обладают более узким спектром, чем манчестерский, даже при повышенной тактовой частоте.
Линейные блочные коды
При передаче информации по каналам связи возможны ошибки вследствие помех и искажений сигналов. Для обнаружения и
исправления возникающих ошибок используются помехоустойчивые коды. Упрощенная схема системы передачи информации
при помехоустойчивом кодировании показана на рис. 4
Кодер служит для преобразования поступающей от источника сообщений последовательности из k информационных
символов в последовательность из n cимволов кодовых комбинаций (или кодовых слов). Совокупность кодовых слов образует код.
Множество символов, из которых составляется кодовое слово, называется алфавитом кода, а число различных символов в
алфавите – основанием кода. В дальнейшем вследствие их простоты и наибольшего распространения рассматриваются главным
образом двоичные коды, алфавит которых содержит два символа: 0 и 1.
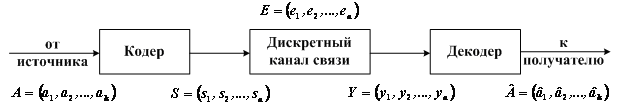
Рис. 4 Система передачи дискретных сообщений
Правило, по которому информационной последовательности сопоставляется кодовое слово, называется правилом кодирования.
Если при кодировании каждый раз формируется блок А из k информационных символов, превращаемый затем в n-символьную
кодовую комбинацию S, то код называется блочным. При другом способе кодирования информационная последовательность на
блоки не разбивается, и код называется непрерывным.
С математической точки зрения кодер осуществляет отображение множества из 2k элементов (двоичных информационных
последовательностей) в множество, состоящее из 2n элементов (двоичных последовательностей длины n). Для практики
интересны такие отображения, в результате которых получаются коды, обладающие способностью исправлять часть ошибок
и допускающие простую техническую реализацию кодирующих и декодирующих устройств.
Дискретный канал связи – это совокупность технических средств вместе со средой распространения радиосигналов, включенных
между кодером и декодером для передачи сигналов, принимающих конечное число разных видов. Для описания реальных каналов
предложено много математических моделей, с разной степенью детализации отражающих реальные процессы. Ограничимся рассмотрением
простейшей модели двоичного канала, входные и выходные сигналы которого могут принимать значения 0 и 1.
Наиболее распространено предположение о действии в канале аддитивной помехи. Пусть S=(s1,s2,…,sn)
и Y=(y1,y2,…,yn) соответственно входная и выходная последовательности двоичных символов.
Помехой или вектором ошибки называется последовательность из n символов E=(e1,e2,…,en), которую
надо поразрядно сложить с переданной последовательностью, чтобы получить принятую:
Y=S+E
Таким образом, компонента вектора ошибки ei=0 указывает на то, что 2-й символ принят правильно (yi=si),
а компонента ei=1 указывает на ошибку при приеме (yi≠si).Поэтому важной характеристикой вектора ошибки
является число q ненулевых компонентов, которое называется весом или кратностью ошибки. Кратность ошибки – дискретная случайная величина,
принимающая целочисленные значения от 0 до n.
Классификация двоичных каналов ведется по виду распределения случайного вектора E. Основные результаты теории кодирования получены в
предположении, что вероятность ошибки в одном символе не зависит ни от его номера в последовательности, ни от его значения. Такой
канал называется стационарным и симметричным. В этом канале передаваемые символы искажаются с одинаковой вероятностью
P, т.е. P(ei=1)=P, i=1,2,…,n.
Для симметричного стационарного канала распределение вероятностей векторов ошибки кратности q является биноминальным:
P(Ei)=Pq(1-P)n-q
которая показывает, что при P<0,5 вероятность β2=αj является убывающей функцией q,
т.е. в симметричном стационарном канале более вероятны ошибки меньшей кратности. Этот важный факт используется при построении
помехоустойчивых кодов, т.к. позволяет обосновать тактику обнаружения и исправления в первую очередь ошибок малой кратности.
Конечно, для других моделей канала такая тактика может и не быть оптимальной.
Декодирующее устройство (декодер) предназначено оценить по принятой последовательности Y=(y1,y2,…,yn)
значения информационных символов A‘=(a‘1,a‘2,…,a‘k,).
Из-за действия помех возможны неправильные решения. Процедура декодирования включает решение двух задач: оценивание переданного кодового
слова и формирование оценок информационных символов.
Вторая задача решается относительно просто. При наиболее часто используемых систематических кодах, кодовые слова которых содержат информационные
символы на известных позициях, все сводится к простому их стробированию. Очевидно также, что расположение информационных символов внутри кодового
слова не имеет существенного значения. Удобно считать, что они занимают первые k позиций кодового слова.
Наибольшую трудность представляет первая задача декодирования. При равновероятных информационных последовательностях ее оптимальное решение
дает метод максимального правдоподобия. Функция правдоподобия как вероятность получения данного вектора Y при передаче кодовых слов
Si, i=1,2,…,2k на основании Y=S+E определяется вероятностями появления векторов ошибок:
P(Y/Si)=P(Ei)=Pqi(1-P)n-qi
где qi – вес вектора Ei=Y+Si
Очевидно, вероятность P(Y/Si) максимальна при минимальном qi. На основании принципа максимального правдоподобия оценкой S‘ является кодовое слово,
искажение которого для превращения его в принятое слово Y имеет минимальный вес, т. е. в симметричном канале является наиболее вероятным (НВ):
S‘=Y+EHB
Если несколько векторов ошибок Ei имеют равные минимальные веса, то наивероятнейшая ошибка EHB определяется случайным выбором среди них.
В качестве расстояния между двумя кодовыми комбинациями принимают так называемое расстояние Хэмминга, которое численно равно количеству символов, в которых одна
комбинация отлична от другой, т.е. весу (числу ненулевых компонентов) разностного вектора. Расстояние Хэмминга между принятой последовательностью Y и всеми
возможными кодовыми словами 5, есть функция весов векторов ошибок Ei:
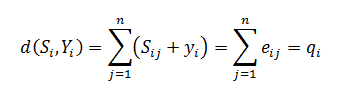
Поэтому декодирование по минимуму расстояния, когда в качестве оценки берется слово, ближайшее к принятой
последовательности, является декодированием по максимуму правдоподобия.
Таким образом, оптимальная процедура декодирования для симметричного канала может быть описана следующей последовательностью операций. По принятому
вектору Y определяется вектор ошибки с минимальным весом EHB, который затем вычитается (в двоичном канале — складывается по модулю 2) из Y:
Y→EHB→S‘=Y+EHB
Наиболее трудоемкой операцией в этой схеме является определение наи-вероятнейшего вектора ошибки, сложность которой
существенно возрастает при увеличении длины кодовых комбинаций. Правила кодирования, которые нацелены на упрощение
процедур декодирования, предполагают придание всем кодовым словам технически легко проверяемых признаков.
Широко распространены линейные коды, называемые так потому, что их кодовые слова образуют линейное
подпространство над конечным полем. Для двоичных кодов естественно использовать поле характеристики p=2.
Принадлежность принятой комбинации Y известному подпространству является тем признаком, по которому
выносится решение об отсутствии ошибок (EHB=0).
Так как по данному коду все пространство последовательностей длины n разбивается на смежные классы,
то для каждого смежного класса можно заранее определить вектор ошибки минимального веса,
называемый лидером смежного класса. Тогда задача декодера состоит в определении номера смежного класса,
которому принадлежит Y, и формировании лидера этого класса.
Кодирование и защита от ошибок
Существует три наиболее распространенных орудия борьбы с ошибками в процессе передачи данных:
- коды обнаружения ошибок;
- коды с коррекцией ошибок, называемые также схемами прямой коррекции ошибок (Forward Error Correction — FEC);
- протоколы с автоматическим запросом повторной передачи (Automatic Repeat Request — ARQ).
Код обнаружения ошибок позволяет довольно легко установить наличие ошибки. Как правило, подобные коды используются совместно с определенными протоколами канального или транспортного уровней, имеющими схему ARQ. В схеме ARQ приемник попросту отклоняет блок данных, в котором была обнаружена ошибка, после чего передатчик передает этот блок повторно. Коды с прямой коррекцией ошибок позволяют не только обнаружить ошибки, но и исправить их, не прибегая к повторной передаче. Схемы FEC часто используются в беспроводной передаче, где повторная передача крайне неэффективна, а уровень ошибок довольно высок.
1) Методы обнаружения ошибок
Методы обнаружения ошибок основаны на передаче в составе блока данных избыточной служебной информации, по которой можно судить с некоторой степенью вероятности о достоверности принятых данных.
Избыточную служебную информацию принято называть контрольной суммой, или контрольной последовательностью кадра (Frame Check Sequence, FCS). Контрольная сумма вычисляется как функция от основной информации, причем не обязательно путем суммирования. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей стороной, делает вывод о том, что данные были переданы через сеть корректно. Рассмотрим несколько распространенных алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать ошибки в данных.
Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же время это наименее мощный алгоритм контроля, так как с его помощью можно обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех битов контролируемой информации. Нетрудно заметить, что для информации, состоящей из нечетного числа единиц, контрольная сумма всегда равна 1, а при четном числе единиц — 0. Например, для данных 100101011 результатом контрольного суммирования будет значение 1. Результат суммирования также представляет собой один дополнительный бит данных, который пересылается вместе с контролируемой информацией. При искажении в процессе пересылки любого бита исходных данных (или контрольного разряда) результат суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке.
Однако двойная ошибка, например 110101010, будет неверно принята за корректные данные. Поэтому контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод редко применяется в компьютерных сетях из-за значительной избыточности и невысоких диагностических способностей.
Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного выше метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд подсчитывается отдельно для каждой строки и для каждого столбца матрицы. Этот метод обнаруживает значительную часть двойных ошибок, однако обладает еще большей избыточностью. Он сейчас также почти не применяется при передаче информации по сети.
Циклический избыточный контроль (Cyclic Redundancy Check — CRC) является в настоящее время наиболее популярным методом контроля в вычислительных сетях (и не только в сетях; в частности, этот метод широко применяется при записи данных на гибкие и жесткие диски). Метод основан на рассмотрении исходных данных в виде одного многоразрядного двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт, будет рассматриваться как одно число, состоящее из 8192 бит. Контрольной информацией считается остаток от деления этого числа на известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцатитрехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт) или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток от деления на тот же делитель R, но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма.
Если остаток от деления на R равен нулю, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным.
Этот метод обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо шире, чем у методов контроля по паритету. Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном числе битов. Метод также обладает невысокой степенью избыточности. Например, для кадра Ethernet размером 1024 байта контрольная информация длиной 4 байта составляет только 0,4 %.
2) Методы коррекции ошибок
Техника кодирования, которая позволяет приемнику не только понять, что присланные данные содержат ошибки, но и исправить их, называется прямой коррекцией ошибок (Forward Error Correction — FEC). Коды, обеспечивающие прямую коррекцию ошибок, требуют введения большей избыточности в передаваемые данные, чем коды, которые только обнаруживают ошибки.
При применении любого избыточного кода не все комбинации кодов являются разрешенными. Например, контроль по паритету делает разрешенными только половину кодов. Если мы контролируем три информационных бита, то разрешенными 4-битными кодами с дополнением до нечетного количества единиц будут:
000 1, 001 0, 010 0, 011 1, 100 0, 101 1, 110 1, 111 0, то есть всего 8 кодов из 16 возможных.
Для того чтобы оценить количество дополнительных битов, необходимых для исправления ошибок, нужно знать так называемое расстояние Хемминга между разрешенными комбинациями кода. Расстоянием Хемминга называется минимальное число битовых разрядов, в которых отличается любая пара разрешенных кодов. Для схем контроля по паритету расстояние Хемминга равно 2.
Можно доказать, что если мы сконструировали избыточный код с расстоянием Хемминга, равным n, такой код будет в состоянии распознавать (n-1) -кратные ошибки и исправлять (n-1)/2 -кратные ошибки. Так как коды с контролем по паритету имеют расстояние Хемминга, равное 2, они могут только обнаруживать однократные ошибки и не могут исправлять ошибки.
Коды Хемминга эффективно обнаруживают и исправляют изолированные ошибки, то есть отдельные искаженные биты, которые разделены большим количеством корректных битов. Однако при появлении длинной последовательности искаженных битов (пульсации ошибок) коды Хемминга не работают.
Наиболее часто в современных системах связи применяется тип кодирования, реализуемый сверхточным кодирующим устройством (Сonvolutional coder), потому что такое кодирование несложно реализовать аппаратно с использованием линий задержки (delay) и сумматоров. В отличие от рассмотренного выше кода, который относится к блочным кодам без памяти, сверточный код относится к кодам с конечной памятью (Finite memory code); это означает, что выходная последовательность кодера является функцией не только текущего входного сигнала, но также нескольких из числа последних предшествующих битов. Длина кодового ограничения (Constraint length of a code) показывает, как много выходных элементов выходит из системы в пересчете на один входной. Коды часто характеризуются их эффективной степенью (или коэффициентом) кодирования (Code rate). Вам может встретиться сверточный код с коэффициентом кодирования 1/2.
Этот коэффициент указывает, что на каждый входной бит приходится два выходных. При сравнении кодов обращайте внимание на то, что, хотя коды с более высокой эффективной степенью кодирования позволяют передавать данные с более высокой скоростью, они, соответственно, более чувствительны к шуму.
В беспроводных системах с блочными кодами широко используется метод чередования блоков. Преимущество чередования состоит в том, что приемник распределяет пакет ошибок, исказивший некоторую последовательность битов, по большому числу блоков, благодаря чему становится возможным исправление ошибок. Чередование выполняется с помощью чтения и записи данных в различном порядке. Если во время передачи пакет помех воздействует на некоторую последовательность битов, то все эти биты оказываются разнесенными по различным блокам. Следовательно, от любой контрольной последовательности требуется возможность исправить лишь небольшую часть от общего количества инвертированных битов.
3) Методы автоматического запроса повторной передачи
В простейшем случае защита от ошибок заключается только в их обнаружении. Система должна предупредить передатчик об обнаружении ошибки и необходимости повторной передачи. Такие процедуры защиты от ошибок известны как методы автоматического запроса повторной передачи (Automatic Repeat Request — ARQ). В беспроводных локальных сетях применяется процедура «запрос ARQ с остановками» (stop-and-wait ARQ).
В этом случае источник, пославший кадр, ожидает получения подтверждения (Acknowledgement — ACK), или, как еще его называют, квитанции, от приемника и только после этого посылает следующий кадр. Если же подтверждение не приходит в течение тайм-аута, то кадр (или подтверждение) считается утерянным и его передача повторяется. На
рис.
1.13 видно, что в этом случае производительность обмена данными ниже потенциально возможной; хотя передатчик и мог бы послать следующий кадр сразу же после отправки предыдущего, он обязан ждать прихода подтверждения.
Цель функционального тестирования — обнаружение несоответствий между реальным поведением реализованных функций и ожидаемым поведением в соответствии со спецификацией и исходными требованиями. Функциональные тесты должны охватывать все реализованные функции с учетом наиболее вероятных типов ошибок. Тестовые сценарии, объединяющие отдельные тесты, ориентированы на проверку качества решения функциональных задач.
Функциональные тесты создаются по внешним спецификациям функций, проектной информации и по тексту на ЯП, относятся к функциональным его характеристикам и применяются на этапе комплексного тестирования и испытаний для определения полноты реализации функциональных задач и их соответствия исходным требованиям.
В задачи функционального тестирования входят:
· идентификация множества функциональных требований;
· идентификация внешних функций и построение последовательностей функций в соответствии с их использованием в ПС;- идентификация множества входных данных каждой функции и определение областей их изменения;
· построение тестовых наборов и сценариев тестирования функций;
· выявление и представление всех функциональных требований с помощью тестовых наборов и проведение тестирования ошибок в программе и при взаимодействии со средой.
Тесты, создаваемые по проектной информации, связаны со структурами данных, алгоритмами, интерфейсами между отдельными компонентами и применяются для тестирования компонентов и их интерфейсов. Основная цель — обеспечение полноты и согласованности реализованных функций и интерфейсов между ними.
Комбинированный метод «черного ящика» и «прозрачного ящика» основан на разбиении входной области функции на подобласти обнаружения ошибок. Подобласть содержит однородные элементы, которые все обрабатываются корректно либо некорректно. Для тестирования подобласти производится выполнение программы на одном из элементов этой области.
Предпосылки функционального тестирования:
· корректное оформление требований и ограничений к качеству ПО;
· корректное описание модели функционирования ПО в среде эксплуатации у заказчика;
· адекватность модели ПО заданному классу.
Под инфраструктурой процесса тестирования понимается:
· выделение объектов тестирования;
· проведение классификации ошибок для рассматриваемого класса тестируемых программ;
· подготовка тестов, их выполнение и поиск разного рода ошибок и отказов в компонентах и в системе в целом;
· служба проведения и управление процессом тестирования;
· анализ результатов тестирования.
Объекты тестирования — компоненты, группы компонентов, подсистемы и система. Для каждого из них формируется стратегия проведения тестирования. Если объект тестирования относится к «белому ящику» или «черному ящику», состав компонентов которого неизвестный, то тестирование проводится посредством ввода внего входных тестовых данных для получения выходных данных. Стратегическая цель тестирования состоит в том, чтобы убедиться, что каждый рассматриваемый входной набор данных соответствует ожидаемым выходным выходных данным. При таком подходе к тестированию не требуется знания внутренней структуры и логики объекта тестирования.
Проектировщик тестов должен заглянуть внутрь «черного ящика» и исследовать детали процессов обработки данных, вопросы обеспечения защиты и восстановления данных, а также интерфейсы с другими программами и системами. Это способствует подготовке тестовых данных для проведения тестирования.
Для некоторых типов объектов группа тестирования не может сгенерировать представительное множество тестовых наборов, которые демонстрировали бы функциональную правильность работы компоненты при всех возможных наборах тестов.
Поэтому предпочтительным является метод «белого ящика», при котором можно использовать структуру объекта для организации тестирования по различным ветвям. Например, можно выполнить тестовые наборы, которые проходят через все операторы или все контрольные точки компонента для того, чтобы убедиться в правильности их работы.
Международный стандарт ANSI/IEEE-729-83 разделяет все ошибки в разработке программ на следующие типы.
Ошибка (error) — состояние программы, при котором выдаются неправильные результаты, причиной которых являются изъяны (flaw) в операторах программы или в технологическом процессе ее разработки, что приводит к неправильной интерпретации исходной информации, следовательно, и к неверному решению.
Дефект (fault) в программе — следствие ошибок разработчика на любом из этапов разработки, которая может содержаться в исходных или проектных спецификациях, текстах кодов программ, эксплуатационной документация и т.п. В процессе выполнения программы может быть обнаружен дефект или сбой.
Отказ (failure) — это отклонение программы от функционирования или невозможность программы выполнять функции, определенные требованиями и ограничениями, что рассматривается как событие, способствующее переходу программы в неработоспособное состояние из-за ошибок, скрытых в ней дефектов или сбоев в среде функционирования. Отказ может быть результатом следующих причин:
· ошибочная спецификация или пропущенное требование, означающее, что спецификация точно не отражает того, что предполагал пользователь;
· спецификация может содержать требование, которое невозможно выполнить на данной аппаратуре и программном обеспечении;
· проект программы может содержать ошибки (например, база данных спроектирована без средств защиты от несанкционированного доступа пользователя, а требуется защита);
· программа может быть неправильной, т.е. она выполняет несвойственный алгоритм или он реализован не полностью.
Таким образом, отказы, как правило, являются результатами одной или более ошибок в программе, а также наличия разного рода дефектов.
Ошибки на этапах процесса тестирования. Приведенные типы ошибок распределяются по этапам ЖЦ и им соответствуют такие источники их возникновения:
· непреднамеренное отклонение разработчиков от рабочих стандартов или планов реализации;
· спецификации функциональных и интерфейсных требований выполнены без соблюдения стандартов разработки, что приводит к нарушению функционирования программ;
· организации процесса разработки — несовершенная или недостаточное управление руководителем проекта ресурсами (человеческими, техническими, программными и т.д.) и вопросами тестирования и интеграции элементов проекта.
Рассмотрим процесс тестирования, исходя из рекомендаций стандарта ISO/IEC 12207, и приведем типы ошибок, которые обнаруживаются на каждом процессе ЖЦ.
Процесс разработки требований. При определении исходной концепции системы и исходных требований к системе возникают ошибки аналитиков при спецификации верхнего уровня системы и построении концептуальной модели предметной области.
Характерными ошибками этого процесса являются:
· неадекватность спецификации требований конечным пользователям;- некорректность спецификации взаимодействия ПО со средой функционирования или с пользователями;
· несоответствие требований заказчика к отдельным и общим свойствам ПО;
· некорректность описания функциональных характеристик;
· необеспеченность инструментальными средствами всех аспектов реализации требований заказчика и др.
Процесс проектирования. Ошибки при проектировании компонентов могут возникать при описании алгоритмов, логики управления, структур данных, интерфейсов, логики моделирования потоков данных, форматов ввода-вывода и др. В основе этих ошибок лежат дефекты спецификаций аналитиков и недоработки проектировщиков. К ним относятся ошибки, связанные:
· с определением интерфейса пользователя со средой;
· с описанием функций (неадекватность целей и задач компонентов, которые обнаруживаются при проверке комплекса компонентов);
· с определением процесса обработки информации и взаимодействия между процессами (результат некорректного определения взаимосвязей компонентов и процессов);
· с некорректным заданием данных и их структур при описании отдельных компонентов и ПС в целом;
· с некорректным описанием алгоритмов модулей;
· с определением условий возникновения возможных ошибок в программе;
· с нарушением принятых для проекта стандартов и технологий.
Этап кодирования. На данном этапе возникают ошибки, которые являются результатом дефектов проектирования, ошибок программистов и менеджеров в процессе разработки и отладки системы. Причиной ошибок являются:
· бесконтрольность значений входных параметров, индексов массивов, параметров циклов, выходных результатов, деления на 0 и др.;
· неправильная обработка нерегулярных ситуаций при анализе кодов возврата от вызываемых подпрограмм, функций и др.;
· нарушение стандартов кодирования (плохие комментарии, нерациональное выделение модулей и компонент и др.);
· использование одного имени для обозначения разных объектов или разных имен одного объекта, плохая мнемоника имен;- несогласованное внесение изменений в программу разными разработчиками и др.
Процесс тестирования. На этом процессе ошибки допускаются программистами и тестировщиками при выполнении технологии сборки и тестирования, выбора тестовых наборов и сценариев тестирования и др. Отказы в программном обеспечении, вызванные такого рода ошибками, должны выявляться, устраняться и не отражаться на статистике ошибок компонент и программного обеспечения в целом.
Процесс сопровождения. На процессе сопровождения обнаруживаются ошибки, причиной которых являются недоработки и дефекты эксплуатационной документации, недостаточные показатели модифицируемости и удобочитаемости, а также некомпетентность лиц, ответственных за сопровождение и/или усовершенствование ПО. В зависимости от сущности вносимых изменений на этом этапе могут возникать практически любые ошибки, аналогичные ранее перечисленным ошибкам на предыдущих этапах.
Все ошибки, которые возникают в программах, принято подразделять на следующие классы:
· логические и функциональные ошибки;
· ошибки вычислений и времени выполнения;
· ошибки ввода-вывода и манипулирования данными;
· ошибки интерфейсов;
· ошибки объема данных и др.
Логические ошибки являются причиной нарушения логики алгоритма, внутренней несогласованности переменных и операторов, а также правил программирования. Функциональные ошибки — следствие неправильно определенных функций, нарушения порядка их применения или отсутствия полноты их реализации и т.д.
Ошибки вычислений возникают по причине неточности исходных данных и реализованных формул, погрешностей методов, неправильного применения операций вычислений или операндов. Ошибки времени выполнения связаны с не обеспечением требуемой скорости обработки запросов или времени восстановления программы.
Ошибки ввода-вывода и манипулирования данными являются следствием некачественной подготовки данных для выполнения программы, сбоев при занесении их в базы данных или при выборке из нее.
Ошибки интерфейса относятся к ошибкам взаимосвязи отдельных элементов друг с другом, что проявляется при передаче данных между ними, а также при взаимодействии со средой функционирования.
Ошибки объема относятся к данным и являются следствием того, что реализованные методы доступа и размеры баз данных не удовлетворяют реальным объемам информации системы или интенсивности их обработки.
Приведенные основные классы ошибок свойственны разным типам компонентов ПО и проявляются они в программах по разному. Так, при работе с БД возникают ошибки представления и манипулирования данными, логические ошибки в задании прикладных процедур обработки данных и др. В программах вычислительного характера преобладают ошибки вычислений, а в программах управления и обработки — логические и функциональные ошибки. В ПО, которое состоит из множества разноплановых программ, реализующих разные функции, могут содержаться ошибки разных типов. Ошибки интерфейсов и нарушение объема характерны для любого типа систем.
Анализ типов ошибок в программах является необходимым условием создания планов тестирования и методов тестирования для обеспечения правильности ПО.
На современном этапе развития средств поддержки разработки ПО (CASE-технологии, объектно-ориентированные методы и средства проектирования моделей и программ) проводится такое проектирование, при котором ПО защищается от наиболее типичных ошибок и тем самым предотвращается появление программных дефектов.
Связь ошибки с отказом. Наличие ошибки в программе, как правило, приводит к отказу ПО при его функционировании. Для анализа причинно-следственных связей «ошибка отказ» выполняются следующие действия:
· идентификация изъянов в технологиях проектирования и программирования;
· взаимосвязь изъянов процесса проектирования и допускаемых человеком ошибок;
· классификация отказов, изъянов и возможных ошибок, а также дефектов на каждом этапе разработки;- сопоставление ошибок человека, допускаемых на определенном процессе разработки, и дефектов в объекте, как следствий ошибок спецификации проекта, моделей программ;
· проверка и защита от ошибок на всех этапах ЖЦ, а также обнаружение дефектов на каждом этапе разработки;
· сопоставление дефектов и отказов в ПО для разработки системы взаимосвязей и методики локализации, сбора и анализа информации об отказах и дефектах;
· разработка подходов к процессам документирования и испытания ПО.
Конечная цель причинно-следственных связей «ошибка отказ» заключается в определении методов и средств тестирования и обнаружения ошибок определенных классов, а также критериев завершения тестирования на множестве наборов данных; в определении путей совершенствования организации процесса разработки, тестирования и сопровождения ПО.
Приведем следующую классификацию типов отказов:
· аппаратный, при котором общесистемное ПО не работоспособно;
· информационный, вызванный ошибками во входных данных и передаче данных по каналам связи, а также при сбое устройств ввода (следствие аппаратных отказов);
· эргономический, вызванный ошибками оператора при его взаимодействии с машиной (этот отказ — вторичный отказ, может привести к информационному или функциональному отказам);
· программный, при наличии ошибок в компонентах и др.
Некоторые ошибки могут быть следствием недоработок при определении требований, проекта, генерации выходного кода или документации. С другой стороны, они порождаются в процессе разработки программы или при разработке интерфейсов отдельных элементов программы (нарушение порядка параметров, меньше или больше параметров и т.п.).
Источники ошибок. Ошибки могут быть порождены в процессе разработки проекта, компонентов, кода и документации. Как правило, они обнаруживаются при выполнении или сопровождении программного обеспечения в самых неожиданных и разных ее точках.
Некоторые ошибки в программе могут быть следствием недоработок при определении требований, проекта, генерации кода или документации. С другой стороны, ошибки порождаются в процессе разработки программы или интерфейсов ее элементов (например, при нарушении порядка задания параметров связи — меньше или больше, чем требуется и т.п.).
Причиной появления ошибок — непонимание требований заказчика; неточная спецификация требований в документах проекта и др. Это приводит к тому, что реализуются некоторые функции системы, которые будут работать не так, как предлагает
заказчик. В связи с этим проводится совместное обсуждение заказчиком и разработчиком некоторых деталей требований для их уточнения.
Команда разработчиков системы может также изменить синтаксис и семантику описания системы. Однако некоторые ошибки могут быть не обнаружены (например, неправильно заданы индексы или значения переменных этих операторов).