Время на прочтение
13 мин
Количество просмотров 48K

Всем разработчикам известна ситуация, когда приложение заглючило и пользователь не может сделать то, что ему нужно. Причины разные: пользователь ввёл неправильные данные, у него медленный интернет и многое другое. Без системы логирования разобрать эти ошибки сложно, а порой невозможно. С другой стороны, система логирования — хороший индикатор проблемных мест в работе системы. Я расскажу, как построить систему логирования в своём проекте (да, ещё раз). В статье расскажу об Elasticsearch + Logstash + Kibana и Prometheus и как их заинтегрировать со своим приложением.
2ГИС — это веб-карта и справочник организаций. У фирмы может быть дополнительный контент — фотографии, скидки, логотип и прочее. И чтобы владельцам бизнеса было удобно управлять этим добром, был создан Личный кабинет. С помощью Личного кабинета можно:
- Добавлять или изменять контакты организации
- Загружать фотографии, логотип
- Смотреть, что делают пользователи при открытии организации и многое другое.
Личный кабинет состоит из двух проектов: бэкенд и фронтенд. Бэкенд написан на PHP версии 5.6, используется фреймворк Yii 1 (да, да). Активно используем Сomposer для управления зависимостями в проекте, автозагрузку классов в соответствии PSR-4, namespace, trait. В будущем планируем обновлять версию PHP до семёрки. В качестве веб-сервера используем Nginx, данные храним в MongoDB и PostgreSQL. Фронтенд написан на JavaScript, используем фреймворк нашего приготовления Catbee. Бэкенд предоставляет API для фронтенда. Далее в докладе буду говорить исключительно про бэкенд.
Вот схема наших интеграций. Нам это напоминает звёздное небо. Если приглядеться, можно увидеть Большую медведицу:

Внешние сервисы разнородные — разрабатываются дюжиной команд, со своим стеком технологий и API. Сценарии интеграции получаются нетривиальными — сначала ходим в один сервис, получаем данные, накладываем свою бизнес-логику, идём ещё в несколько сервисов с новыми данным, объединяем ответы и отдаём результат на фронтенд. И если у пользователя возникает проблема и он не может осуществить желаемое, например, продлить рекламную кампанию, то без системы логирования нам не понять, где была проблема — либо неправильно отправляем данные во внешний сервис, либо неправильно интерпретируем ответ, либо внешний сервис недоступен, либо неправильно накладываем свою бизнес-логику.
У нас было логирование ошибок, но с появлением новых сервисов стало всё труднее отслеживать интеграции и отвечать на запросы техподдержки о возникающей проблеме. Поэтому мы выработали новые требования к нашей системе логирования:
- Нужно больше контекста об ошибках — что произошло и у какого пользователя.
- Собирать входящие запросы в удобном виде.
- Если методы долго отвечают, то нужно уведомить команду об этом.
Логирование ошибок
Исторически сложилось, что в нашей компании для сбора и просмотра логов используется стэк технологий Elasticsearch + Logstash + Kibana, сокращённо ELK. Elasticsearch — NoSQL-хранилище документов, с возможностью полнотекстового поиска. Logstash настроен на приём логов по TCP/UDP-протоколам, читает сообщения из Redis и сохраняет в Elasticsearch. Kibana предоставляет визуальный интерфейс для поиска и отображения собранных данных.
Если у клиента идёт что-то не так, то он обращается в техподдержку из своего аккаунта с описанием проблемы. У нас было логирование ошибок, но не было ни email пользователя, ни вызванного API-метода, ни стэка вызова. В сообщениях была лишь строка из необработанного Exception вида «Запрос вернул некорректный результат». Из-за этого мы искали проблему по времени обращения клиента и ключевым словам, что не всегда было точно — клиент мог обратиться через день, и помочь было очень сложно.
Помучавшись, мы решили, что надо что-то делать и добавили необходимую информацию — email пользователя, API-метод, тело запроса, стэк вызова и наши контроллер и экшен, которые обрабатывали запрос. В итоге мы упростили жизнь техподдержке и себе — ребята нам скидывают email пользователя, а мы по нему находим записи в логах и разбираемся с проблемой. Мы точно знаем, у какого пользователя была проблема, какой метод был вызван и какая часть нашего кода обработала его. Никаких сравнений по времени обращения!
Сообщения об ошибках отправляем во время работы приложения по протоколу UDP в формате Graylog Extended Log Format, или сокращенно GELF. Формат хорош тем, что сообщения могут быть сжаты популярными алгоритмами и разделены на части, тем самым снижая объем передаваемого трафика из нашего приложения в Logstash. Протокол UDP пусть и не гарантирует доставку сообщений, но накладывает минимум накладных расходов на время ответа, поэтому такой вариант нас устраивает. В приложении используем библиотеку gelf-php, которая предоставляет возможности по отправке логов в разных форматах и протоколах. Рекомендую использовать её в своих PHP-приложениях.
Вывод — если ваше приложение работает с внешними пользователями и вам нужно искать ответы на возникающие вопросы техподдержки, смело добавляйте информацию, которая поможет идентифицировать клиента и его действия.
Пример нашего сообщения:
{
"user_email": "test@test.ru",
"api_method": "orgs/124345/edit",
"method_type": "POST",
"payload": "{'name': 'Новое название'}",
"controller": "branches/update",
"message": "Undefined index: 'name'
File: /var/www/protected/controllers/BranchesController.php
Line: 50"
}Логирование запросов
Логирования запросов в структурированном виде и сбор статистики отсутствовали, поэтому было непонятно, какие методы чаще всего вызываются и сколько по времени отвечают. Это привело к тому, что мы не могли:
- оценить допустимое время ответа методов.
- причину возникновения тормозов — на нашей стороне или на стороне внешнего сервиса (помните схему со звёздным небом?)
- как можно оптимизировать наш код, чтобы уменьшить время ответа.
В рамках данной задачи нам предстояло решить вопросы:
- выбор параметров ответа для логирования
- отправка параметров в Logstash
Мы используем веб-сервер Nginx, и он умеет писать access-логи в файл. Для решения первой задачи указали новый формат сохранения логов в конфигурации:
log_format main_logstash
'{'
'"time_local": "$time_local",'
'"request_method": "$request_method",'
'"request_uri": "$request_uri",'
'"request_time": "$request_time",'
'"upstream_response_time": "$upstream_response_time",'
'"status": "$status",'
'"request_id": "$request_id"'
'}';
server {
access_log /var/log/nginx/access.log main_logstash;
}Большинство метрик, думаю, вопросов не вызывает, расскажу подробнее про наиболее интересную — $request_id. Это уникальный идентификатор, UUID версии 4, который генерируется Nginx для каждого запроса. Данный заголовок мы пробрасываем в запросе во внешние сервисы и можем отследить ответ запроса в логах других сервисах. Очень удобно при поиске проблем в других сервисах — никаких сравнений по времени, урлу вызванного метода.
Для отправки логов в Logstash используем утилиту Beaver. Устанавливается на все ноды приложения, с которых планируется отправка логов. В конфигурации указывается файл, который будет парситься для получения новых логов, указываются поля, которые будут отправляться с каждым сообщением. Сообщения отправляются в Redis-кластер, из которого Logstash забирает данные. Вот наша конфигурация Beaver:
[/var/log/nginx/access.log]
type: nginx_accesslog
add_field: team,lk,project,backend
tags: nginx_jsonПо полям type и tags в Logstash по нашим значениям сделана фильтрация и обработка логов, у вас эти значения могут быть свои. Кроме того, добавляем поля team и project, чтобы можно было идентифицировать команду и проект, которым принадлежат логи.
Научившись собирать access-логи, мы перешли к определению SLA методов. SLA, договор на уровень оказания услуг, в нашем случае мы гарантируем, что 95-ый перцентиль по времени ответа методов будет не более 0.4 секунд. Если не укладываемся в допустимое время, то значит, что в приложении либо одна из интеграций тормозит и обращаемся к связанной команде, либо что-то не так в нашем коде и необходима оптимизация.
Вывод по сбору access-логов — мы определили наиболее часто вызываемые методы и их допустимое время ответа.
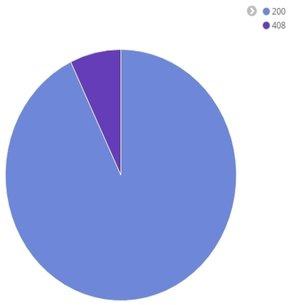
Вот примеры наших отчётов на одном из измеряемых методов. Первый — чему равны 50, 95 и 99 перцентили времени ответа и среднее время ответа:

Диаграмма статусов ответа:
Среднее время ответа за промежуток времени:

Оповещения команды о падении SLA
После сбора логов нам пришла идея, что нужно оперативно узнавать о падении скорости. Постоянно держать открытым браузер с Kibana, нажимать F5, сравнивать в уме текущее значение 95-ого перцентиля с допустимым оказалось не очень практично — есть много других интересных задач в проекте. Поэтому для формирования оповещений мы добавили интеграцию с системой Prometheus. Prometheus — это система с открытым исходным кодом для сбора, хранения и анализа метрик работающего приложения. Официальный сайт с документацией.
Нам система понравилась тем, что в случае срабатывания триггера можно отправить оповещение на почту. Возможность предоставляется из коробки, без заморочек с доступами к серверам и без написания кастомных скриптов для формирования оповещения. Система написана на языке Go, создатели — компания SoundCloud. Существуют библиотеки для сбора метрик на разными языками — Go, PHP, Python, Lua, C#, Erlang, Haskell и другие.
Я не буду рассказывать, как установить и запустить Prometheus. Если вам интересно это, предлагаю почитать статью. Я сделаю упор на тех моментах, которые имели практическое значение для нас.
Схема интеграции выглядит так — клиентское приложение по адресу отдаёт набор метрик, Prometheus заходит на данный адрес, забирает и сохраняет метрики в своём хранилище.

Давайте разберёмся, как выглядят метрики.

- Название — это идентификатор изучаемой характеристики. Например, количество входящих запросов.
- У метрики в момент времени есть определённое значение. Время проставляет Prometheus при сборе метрик.
- У метрики могут быть лейблы. Они содержат дополнительную информацию о собранном числе. В примере указана нода приложения и API-метод. Основная фишка лейблов в том, что по ним можно осуществлять поиск и делать необходимые выборки данных.
Хранилища данных формата «время — значение» называются Базами данных временных рядов. Это узкоспециализированные NoSQL-хранилище для хранения изменяющихся во времени показателей. Например, количество пользователей на сайте в 10 часов утра, за день, за неделю и так далее. Из-за особенностей решаемых задач и способа хранения такие БД обеспечивают высокую производительность и компактное хранение данных.
Prometheus поддерживает несколько типов метрик. Рассмотрим первый тип, называется Счётчик. Значение Счётчика при новых измерениях всегда растёт вверх. Идеально подходит для измерения общего количества входящих запросов за всю историю — не может быть такого, чтобы сегодня было 100 суммарно запросов, а завтра количество уменьшилось до 80.
Но как быть с измерением времени ответа? Оно не обязательно растёт вверх, более того, может упасть вниз, быть какое-то время на одном уровне, а потом вырасти вверх. Изменение может произойти менее чем за 10 секунд, и нам хочется видеть динамику изменения времени ответа для каждого запроса. К счастью, есть тип Гистограмма. Для формирования необходимо определить интервал измерения времени ответа. В примере возьмём от 0.1 до 0.5 секунды, всё что больше будем считать как Бесконечность.
Вот как выглядит начальное состояние Гистограммы:
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.1"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.2"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.3"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.4"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.5"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="+Inf"} 0
api_request_time_sum{node="api1.2gis.com",handler="/users"} 0
api_request_time_count{node="api1.2gis.com",handler="/users"} 0На каждое значение из интервала мы создаём Счётчик по определённым правилам:
- В названии обязательно должен быть постфикс _bucket
- Должен быть лейбл le, в котором указывается значение из интервала. Плюс должен быть Счётчик со значением +Inf.
- Должны быть Счётчики с постфиксом _sum и _count. В них сохраняется суммарное общее время всех ответов и количество запросов. Нужны для удобного подсчёта 95-ого перцентиля средствами Prometheus.
Давайте разберёмся, как правильно заполнять Гистограмму временем ответа. Для этого нужно найти серии, у которых значение лейбла le больше либо равно времени ответа, и их увеличить на единицу. Предположим, что наш метод ответил за 0.4 секунды. Мы находим те Счётчики, у которых лейбл le больше либо равен 0.4, и к значению добавляем единицу:
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.1"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.2"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.3"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.4"} 1
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.5"} 1
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="+Inf"} 1
api_request_time_sum{node="api1.2gis.com",handler="/users"} 0.4
api_request_time_count{node="api1.2gis.com",handler="/users"} 1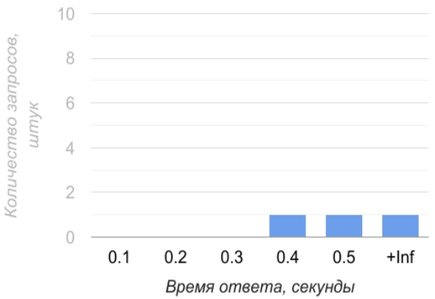
Если метод отвечает за 0.1 секунду, то мы увеличиваем все серии. Если отвечает за 0.6 секунд, то увеличиваем лишь счётчик со значением «+Inf». Не забываем увеличивать счётчики api_request_time_sum и api_request_time_count. С помощью Гистограммы можно измерять время ответа, которое за короткий промежуток может часто меняться.
Prometheus поддерживает ещё два типа метрик — Шкала и Сводка результатов. Шкала описывает характеристику, значение которой может как увеличиваться, так и уменьшаться. В задачах не используем, так как такие показатели у нас не измеряются. Сводка результатов — это расширенная Гистограмма, которая сохраняет вычисляемые на стороне приложения квантили. Теоретически можно было бы рассчитывать 95-процентный перцентиль, или 0.95 квантиль, но это добавило бы кода по подсчёту на клиентской стороне и лишило бы гибкости в отчётах — могли бы использовать только вычисленные нами квантили. Поэтому свой выбор остановили на Гистограмме.
Формирование Гистограммы мы реализовали в Nginx на языке Lua. Нашли готовый проект на GitHub, который подключается в конфигурации Nginx и формирует Гистограмму описанным выше способом. Собирать данные нам необходимо с наиболее часто вызываемых методов, которые, как вы помните, мы определили после отправки access-логов в Logstash. Поэтому потребовалось добавить бизнес-логики по проверке, нужно запрос логировать или нет.
В итоге интеграция заняла неделю, вместе с изучением матчасти Prometheus и основ языка Lua. На наш взгляд, это отличный результат. Ещё очень здорово, что на время ответа добавляется незначительный, порядка 5-10 мс, оверхеад из-за формирования Гистограмм и проверки нашей бизнес-логики, что меньше, чем предполагали.
Но есть и минусы у этого решения — не учитываем время запросов, у которых статус не 200. Причина — директива log_by_lua, в которую мы добавили логирование, в таком случае не вызывается. Вот подтверждение. С другой стороны, нам время ответа таких запросов неинтересно, потому что это ошибка. Ещё один минус — Гистограмма хранится в shared-памяти Nginx. При перезапуске Nginx память очищается, и собранные метрики теряются. С этим тоже можно жить — перезапускать Nginx командой reload, и настроить Prometheus, чтобы он чаще забирал метрики.
Вот конфигурация Nginx для создания Гистограммы:
lua_shared_dict prometheus_metrics 10M;
init_by_lua '
prometheus = require("prometheus").init("prometheus_metrics")
prometheusHelper = require("prometheus_helper")
metric_request_time = prometheus:histogram("nginx_http_request_time", {"api_method_end_point", "request_method"})
'Здесь мы выделяем общую память, подключаем библиотеку и хэлпер с нашей бизнес-логикой и инициализируем Гистограмму — присваиваем имя и лейблы.
За логирование запроса отвечает данная конфигурация:
location / {
log_by_lua '
api_method_end_point = prometheusHelper.convert_request_uri_to_api_method_end_point(ngx.var.request_uri, ngx.var.request_method)
if (api_method_end_point ~= nil) then
metric_request_time:observe(tonumber(ngx.var.request_time),{api_method_end_point, ngx.var.request_method})
'
}Здесь мы в директиве log_by_lua проверяем, нужно ли логировать запрос, и если да, то добавляем его время ответа в Гистограмму.
Метрики отдаются через Nginx по endpoint:
server {
listen 9099;
server_name api1.2gis.com;
location /metrics {
content_by_lua 'prometheus:collect()';
}
}Теперь нужно в конфигурации Prometheus указать ноды нашего приложения для сбора метрик:
- targets:
- api1.2gis.com:9099
- api2.2gis.com:9199
labels:
job: bizaccount
type: nginx
role: monitoring-api-methods
team: lk
project: backendВ разделе targets указываются endpoint наших нод, в разделе labels — лейблы, которые добавляются к собираемым метрикам. По ним определяем назначение метрики и отправителя.
Сбор метрик у нас настроен каждые 15 секунд — Prometheus заходит на указанные ноды и сохраняет себе метрики.
После того, как мы разобрались с метриками, научились их собирать, отдавать в Prometheus, мы перешли к тому, ради чего затевалась интеграция — оповещения на командную почту при падении скорости работы нашего приложения. Вот пример оповещения:
ALERT BizaccountAPI95PercentileUnreachebleGetUsers
IF (sum(rate(nginx_http_request_time_bucket{le="0.4",api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)
/
sum(rate(nginx_http_request_time_count{api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)) * 100 < 95
FOR 5m
LABELS { severity = "critical", team = "lk"}
ANNOTATIONS {
summary = "API-method {{ $labels.request_method}} {{ $labels.api_method_end_point}} is not in SLA",
description = "For API-method {{ $labels.request_method}} {{ $labels.api_method_end_point }} 95 percentile is unreacheble in last 5 minutes. Current percentile is {{ $value }}.",
}У Prometheus лаконичный язык формирования запросов, при помощи которого можно выбирать значения метрик за период и фильтровать по лейблам. В директиве IF с помощью конструкций языка указываем условие срабатывания триггера — если за 0.4 секунды отвечают менее 95 процентов запросов за последние 5 минут. Считается это отношением. В числителе мы высчитываем, сколько запросов укладываются за 0.4 секунды за последние 5 минут:
sum(rate(nginx_http_request_time_bucket{le="0.4",api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)В знаменателе считаем общее количество запросов за последние 5 минут:
sum(rate(nginx_http_request_time_count{api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)Полученную дробь умножаем на 100 и получаем процент запросов, которые отвечают за 0.4 секунды. Функция rate здесь возвращает время ответа за каждый момент в указанный интервале. Функция sum суммирует полученный ряд. Оператор by — это аналог оператора GROUP BY, который выполняет группировку по указанным лейблам.
В разделе FOR указывается интервал между первым срабатываем триггера и моментом, когда нужно отправить оповещения. У нас интервал равен 5 минутам — если за 5 минут ситуация не меняется, то нужно отправить оповещение. В разделе LABELS указываются лейблы с указанием команды и критичности проблемы. В разделе ANNOTATIONS указывается проблемный метод и какой процент запросов отвечает за 0.4 секунды.
В случае возникновения повторяющихся оповещений Prometheus умеет делать дедупликацию, и отправит одно оповещение на командную почту. И это всё из коробки, нам нужно лишь указать правила и интервал срабатывания триггера.
Оповещения в Prometheus получились именно такими, какими мы и хотели — с понятной конфигурацией, без своих велосипедов с дедупликацией оповещений и без реализации логики срабатывания оповещения на каком-либо языке.
Вот как выглядит сообщение:

Заключение
Мы улучшили нашу систему логирования и теперь у нас не возникает проблем с недостатком информации.
- При возникновении ошибки мы обладаем достаточной информацией о проблеме. Теперь на 99 процентов запросов техподдержки мы имеет представление, что произошло у пользователя и точно сориентировать техподдержку о проблеме и возможных сроках исправления.
- С помощью оповещений мы определяем проблемные места в производительности приложения и оптимизируем их, делая приложение быстрее и надёжнее.
- Через Prometheus мы оперативно узнаём о падении скорости, а уже после смотрим в ELK и начинаем детально изучать, что случилось. У связки ELK + Prometheus мы видим большой потенциал, планируем добавить оповещения в случае увеличения ошибок и мониторинг внешних сервисов.
Whether you capture them for application security and compliance, production monitoring, performance monitoring, or troubleshooting, logs contain valuable information about the health of your apps. But it all comes down to what and how you log, which is where log management tools come into play. Log centralization and log analysis give you a real-time view of how your applications and systems are being used by your users and provide deeper insights and opportunities you can leverage to improve the code quality, increase efficiency, mitigate risks and offer a better customer experience.
Whether you’re looking for free, open-source, or commercial, we’ve reviewed the best log management and monitoring tools and software to help you get started. Regardless if they’re on-premises or cloud-based, paid log management and monitoring tools aim to offer end-to-end functionality for all your logging needs. Here are the ones that we’ve found are the best in their field:
1. Sematext Logs
Sematext Logs is a log management system that exposes the Elasticsearch API, part of the Sematext Cloud full-stack monitoring solution. You can send data using syslog or any tool that works with Elasticsearch, such as Logstash or Filebeat. Visualizing can be done with Kibana or the native Sematext Logs UI. If you prefer a self-hosted solution, Sematext Logs is also available via Sematext Enterprise, the on-premise service.
Sematext’s auto-discovery of logs and services lets you automatically start monitoring logs and forwarding them from both log files and containers directly through the user interface.
Key Features:
- Agent-free: any log shipper or library that works with syslog or Elasticsearch will work with Sematext Logs
- Elasticsearch API access beyond indexing: you can run searches, export data, create custom templates, and more
- Extra features on top of the ELK stack are available, such as role-based access control, alerting, and anomaly detection
Pricing:
- Free: 500MB per day
- Paid plans start at $50/month (1GB/day, 1-week retention)
Pros:
- Fully hosted: get all the flexibility of the ELK stack without having to manage/scale Elasticsearch
- Integration with other Sematext Cloud components, such as Infrastructure Monitoring, Synthetics and Experience. For example, you can have dashboards with widgets from any component, so you can see which error caused that CPU spike
- Spike-friendly pricing. Ingestion is averaged out and calculated on top of the “base” plan. For example, if you have the cheapest paid plan ($50/month, supports 1GB/day) and send 60GB in a month (2GB per day, on average), you end up paying $100
- Configurable overage – you can choose when Sematext stops accepting logs, to control your cost
- Per-silo pricing. You can create multiple “apps”, for example, Production and QA. Each can have its own plan (volume, retention) and overage configuration
Cons:
- Currently, Sematext Logs only parses Syslog and JSON on the server side. Custom parsing has to be done in the log shipper
- You can’t mix Kibana and native UI widgets in the same dashboard
If you’re interested in learning more about its analysis features, we went into detail in our articles about the best log analysis tools and the top cloud logging services. Check them out if you’re into that! Or, check out the short video below on Sematext Logs.
2. Splunk
Splunk is one of the first commercial log centralizing tools, and the most popular. The typical deployment is on-premises (Splunk Enterprise), though it’s also offered as a service (Splunk Cloud). You can send both logs and metrics to Splunk and analyze them together.
Key Features:
- Powerful query language for search and analytics
- Search-time field extraction (beyond parsing at ingestion-time)
- Automatically moves frequently-accessed data to fast storage and infrequently-accessed data to slow storage
Pricing:
- Free: 500MB data per day
- Paid plans are available upon request, but the FAQ suggests they start at $150/month for 1GB
Pros:
- Mature and feature-rich
- Good data compression for most use-cases (assuming limited indexing, as recommended)
- Logs and metrics under one roof
Cons:
- Expensive
- Slow queries for longer time ranges (assuming limited indexing, as recommended)
- Less efficient for metrics storage than monitoring-focused tools
Want to see how Sematext stacks up? Check out our page on Sematext vs Splunk.
3. Sumo Logic
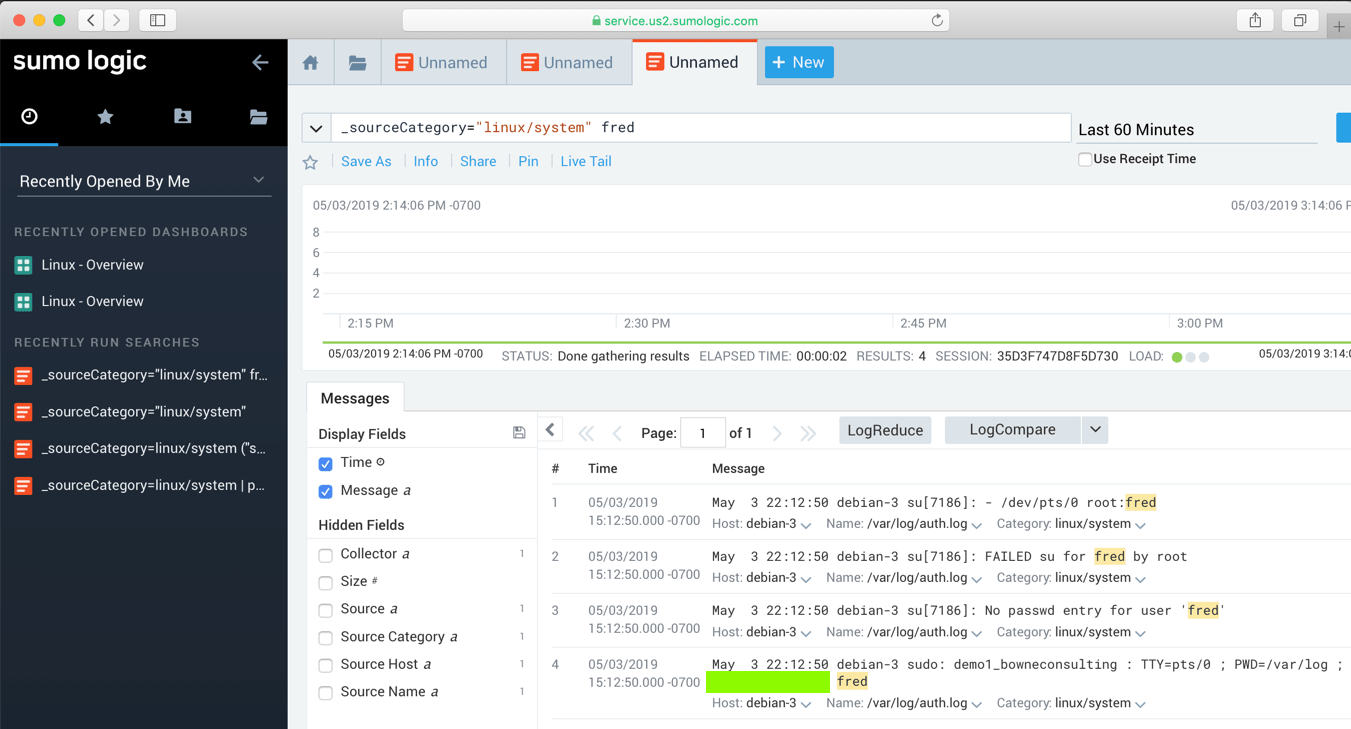
Sumo Logic is a log management software where you can store both logs and metrics. More similar to Sematext Cloud than Splunk, in the sense that metrics and logs can be viewed (and paid for) as separate entities. Like Splunk, it has a powerful search syntax, where you can define operations in a similar way to UNIX pipes.
Key Features:
- Powerful query language
- Ability to detect common patterns of logs (LogReduce)
- Ability to detect trends for patterns of logs (LogCompare)
- Centralized management of agents
Pricing:
- Free: 500MB/day
- Paid plans start at $324/month for 3GB/day ingestion and 10 days (30GB) storage
Pros:
- Easy agent setup
- Good query and visualization functionality
- Spike-friendly (like in Sematext Cloud, ingestion is averaged out for a month)
Cons:
- Not available on premises
- Some users complain about performance (e.g. querying lots of data) and latency (i.e. delay between sending the log and seeing it in search)
- No overage support: you need a higher plan for a larger quota (or a custom plan)
4. SolarWinds PaperTrail
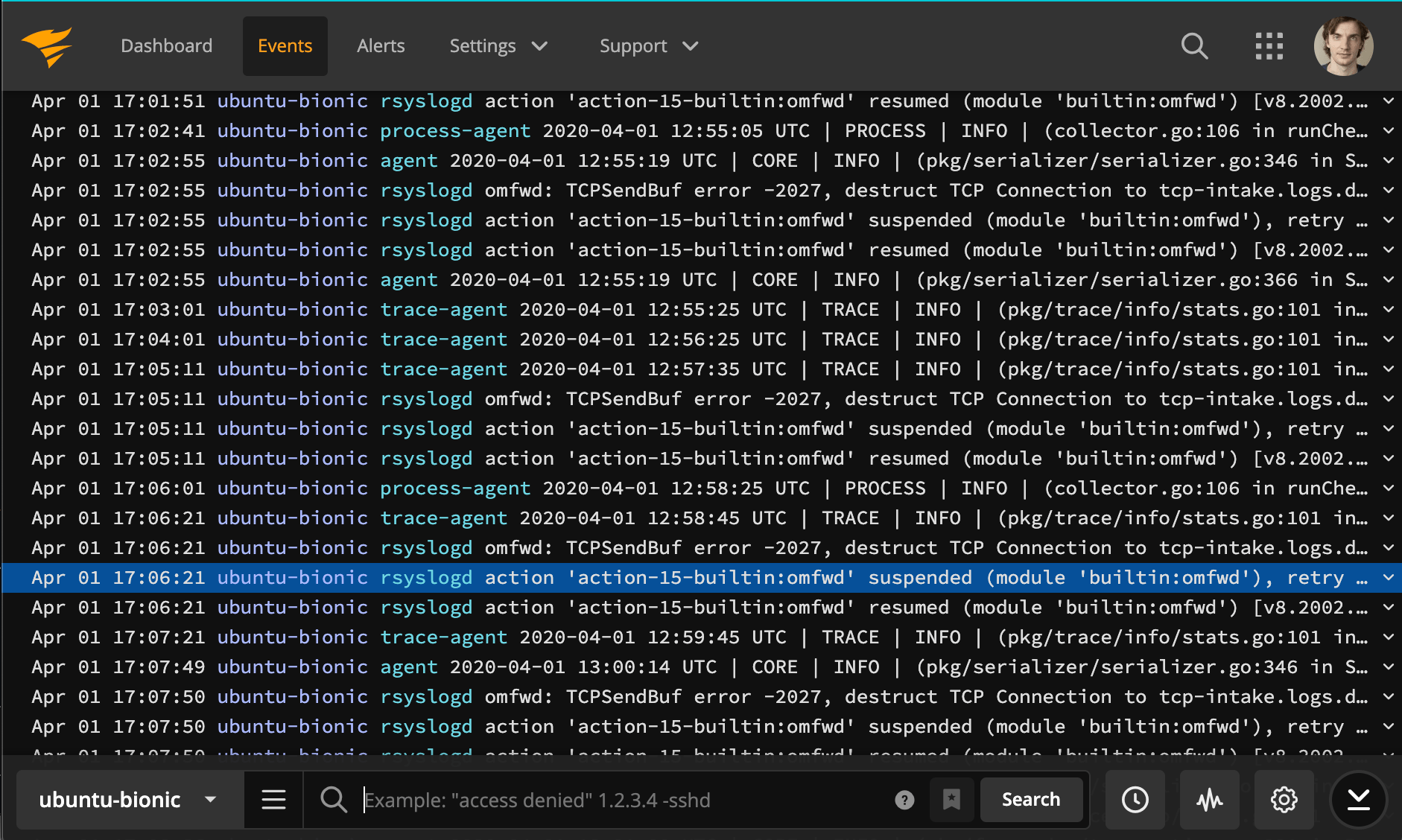
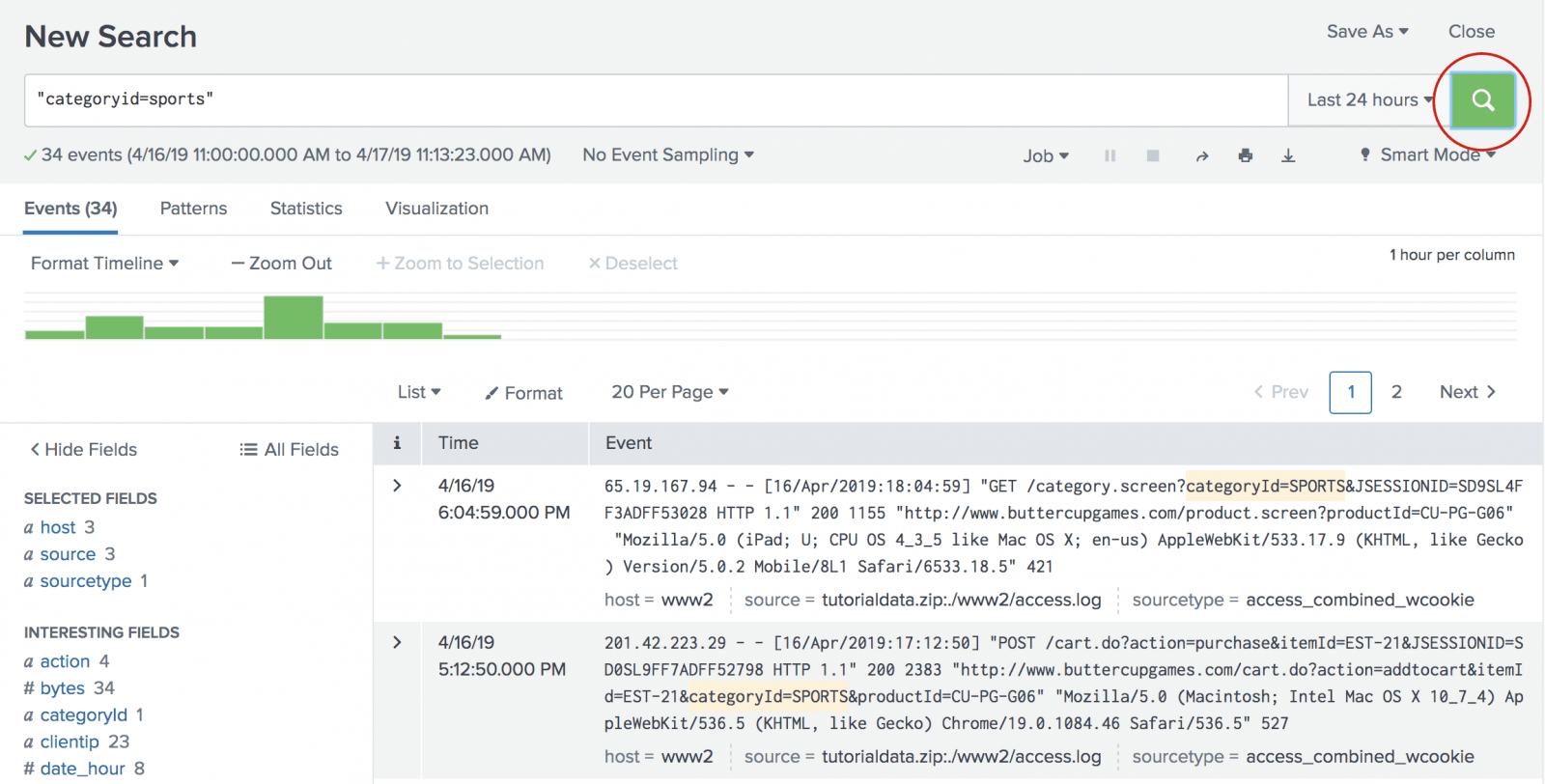
SolarWinds provides multiple tools designed for IT operations. For logging, they have Log Analyzer, but they are better known for services they acquired in the meantime, such as PaperTrail and Loggly (see below).
PaperTrail is a simple, easy-to-use service that provides a logging experience closer to the terminal. You’d send data over syslog, so you can tail and search it in the UI.
Key Features:
- Simple and user-friendly interface.
- Built-in archiving
- Spike-friendly: volumes are averaged per month (similar to Sematext Cloud)
Pricing:
- Free: 50MB/month
- Paid plans start at $7/month for 1GB/month ingestion, 1-week searchable storage, and 1-year archive
Pros:
- Quick setup
- Intuitive UI
- Affordable for low volumes
Cons:
- No visualizations, besides log volume
- Higher volume pricing is actually more expensive than e.g. Sematext Cloud
- +30% overage cost, limited to 200% the base plan
5. SolarWinds Loggly
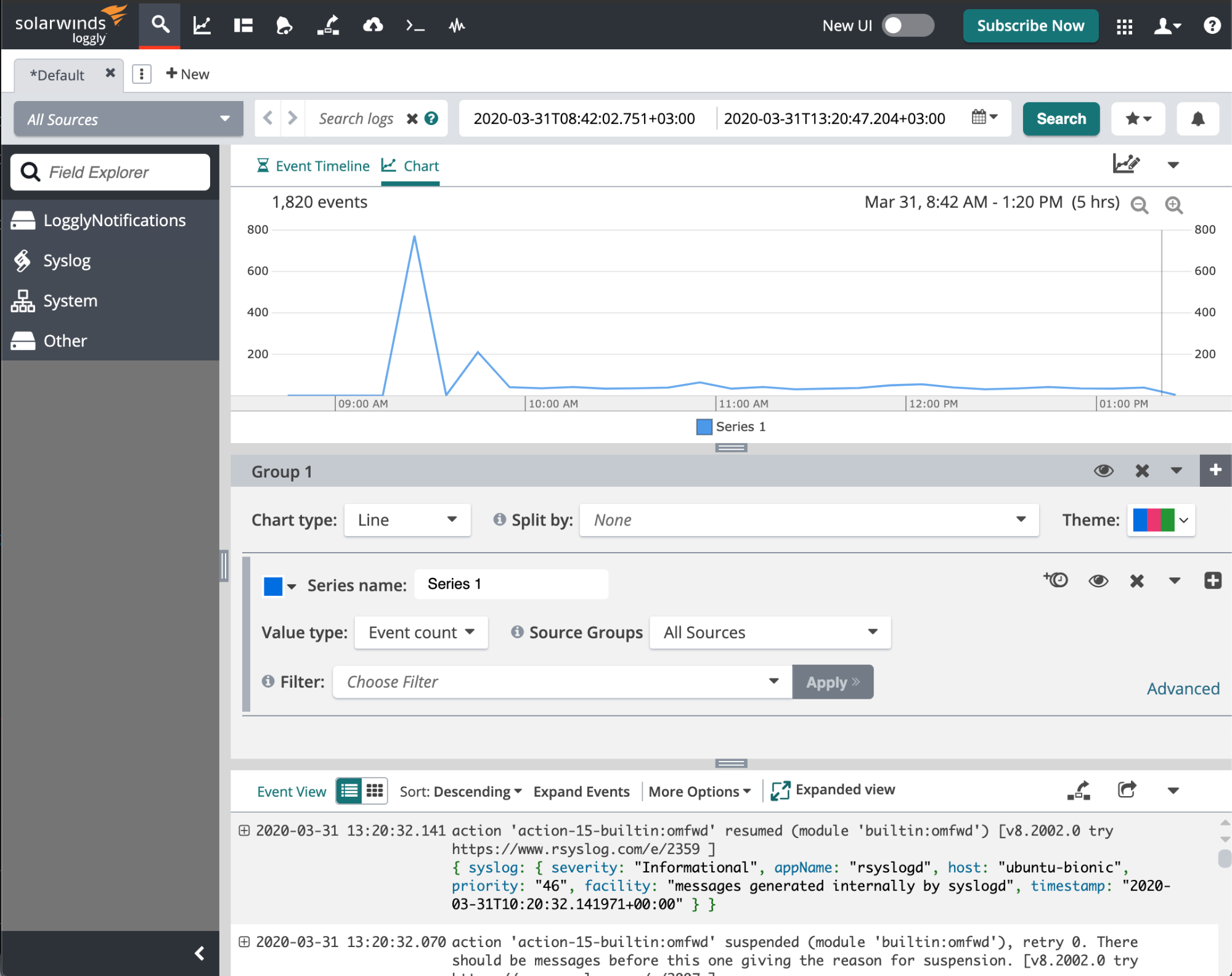
Loggly is another log management tool provided by SolarWinds. Compared to PaperTrail, it provides richer visualizations, more parsing functionality but not built-in archiving. That said, with a Pro/Enterprise plan, you can archive to your own AWS S3 bucket like you can do in Sematext Cloud.
Key Features:
- Agent-free log collection: supports syslog and HTTP(S)
- Server-side log parsing
- Search-time field extraction
Pricing:
- Free: 200MB/day
- Paid plans start at $79/month for 1GB/day ingestion, 2 weeks retention
Pros:
- Good support for popular log shippers (e.g. Logstash plugin)
- Parses common logging formats out of the box
- Some overage (100% or 50GB up to 3 days per month) is included in higher plans
Cons:
- Some basic features, like API access or more than a few users are only available in higher plans
- Overage rules are restrictive. Though they are negotiable via custom plans
Want to see how Sematext stacks up? Check out our page on Sematext vs Loggly.
6. ManageEngine EventLog Analyzer
ManageEngine EventLog Analyzer is on-premises log management software. It runs on Windows but accepts logs from both Windows and UNIX sources. On top of the typical log monitoring and analysis features (search, visualize, alert, report), it provides some SIEM capabilities, especially for Windows.
Features:
- Agentless log collection (can pull events from Windows hosts)
- Host auto-discovery
- Query-time field extraction
- Event correlation for threat detection (e.g. N failed login attempts get reported as a brute force attack)
Pricing:
- Free edition, supports up to 5 log sources
- Paid editions start at $595/year
Pros:
- Good support for Windows logging
- Common log format parsing out of the box, especially for Windows services, such as IIS, DHCP, MS SQL
Cons:
- Only available on-premises and only available on Windows
- Deploying EventLog Analyzer on multiple servers requires a more expensive “Distributed” license
7. Datadog
Datadog is a SaaS that started up as a monitoring (APM) tool and later added log management capabilities as well. You can send logs via HTTP(S) or syslog, either via existing log shippers (rsyslog, syslog-ng, Logstash, etc.) or through Datadog’s own agent. It features Logging without Limits™, which is a double-edged sword: harder to predict and manage costs, but you get pay-as-you-use pricing (see below) combined with the fact that you can archive and restore from archive.
Key Features:
- Server-side processing pipeline for parsing and enriching logs
- Automatically detects common log patterns
- Can archive logs to AWS/Azure/Google Cloud storage and rehydrate them later
Pricing separates processing from storage:
- Processing starts at $0.10 per ingested GB per month (e.g. $3 for 1GB/day)
- Processing also applies to rehydration from archive, though here data is compressed
- Storage starts at $1.59 for 3 days for 1M events (e.g. $47.7 for 1GB/day at 1K each, stored for 3 days)
Pros:
- Easy search with good autocomplete (based on facets)
- Integration with DataDog metrics and traces
- Affordable, especially for short retention and/or if you rely on the archive for a few searches going back
Cons:
- Not available on premises
- Some users complain about cost getting out of control (due to flexible pricing). Though you can set daily processing quotas
Want to see how Sematext stacks up? Check out our page on Sematext vs Datadog.
8. Mezmo (Formerly LogDNA)
Mezmo (Formerly LogDNA) is a newer player in the log management space. Available as both SaaS and on premises, LogDNA provides all the logging basics: agent-based and agentless log collection, via syslog and HTTP(S) plus full-text search and visualizations, with clear and competitive pricing.
Key Features:
- Embedded views to share logs outside the organization
- Automatically parses common log formats
Pricing:
- Free: no storage, just live tail
- Paid plans start at $1.50 per ingested GB in a month at 7 days retention
Pros:
- Simple UI for searching logs, similar to Papertrail
- Easy to understand plans
Cons:
- Limited visualization capabilities
- Retention depends on the plan (from 7 up to 30 days). So does the number of users (the cheapest plan only allows 5)
Want to see how Sematext stacks up? Check out our page on Sematext vs Mezmo.
9. Logz.io
Logz.io is one of the “purest” versions of hosted ELK, in the sense that you can use the Logstash protocol to send logs (as well as syslog), and you have Kibana to visualize them. Similar to Sematext Cloud, there are some added features, such as alerting.
Key Features:
- Built on top of the ELK stack, meaning you can send data through the Logstash protocol (e.g. from Beats) and use Kibana to visualize logs
- Logs and metrics in one place (though metrics are in Beta as of April 2020)
- Automatically parses common log formats
Pricing:
- Free: 1GB/day, 1 day retention
- Paid plans start at $82/month+taxes for 2GB/day and 3 days retention
Pros:
- Fully hosted: get most of the flexibility of the ELK stack without having to manage/scale Elasticsearch
- Pre-built dashboards are available as “ELK apps”
- Server-side parsing available, with intuitive UI to define new parsing rules
Cons:
- Not available on premises
- API available only with the Enterprise plan
- As metrics are visualized with Grafana, you can’t have a dashboard with both logs and metrics
10. Logentries (now Rapid7 InsightOps)
Rapid7 acquired Logentries, rebranding the product InsightOps and adding it to its line of security- and automation-focused products. InsightOps covers all the logging basics: you can send data via TCP/TLS (which includes syslog), you can search, visualize logs and set up alerts.
Key Features:
- SQL-like query language
- Intuitive UI for search and dashboards
- Monthly volume quota means it’s easier to deal with daily spikes
Pricing:
- Starts at $58/month with 30GB/month ingestion and 30 days retention
Pros:
- Agent runs on Windows, Linux, and Mac
- Can automatically parse syslog and Apache logs and NGINX logs
- Good price if you’re looking for 30 days retention
Cons:
- Rest API is available for searches, alerts, etc. but it’s currently in beta
- Retention is fixed for 30 days (unless you go for a custom plan)
- Not available on premises
11. Scalyr
Scalyr is a logging and monitoring software that doesn’t index data. Instead, they use a proprietary columnar data store, acting as a destination for both logs and metrics. They take a similar one-size-fits-all approach to data ingestion, which is only possible through the Scalyr agent.
Key Features:
- Powerful query syntax
- Logs and metrics in one place
Pricing:
- Starts at $35/month for 1GB/day average ingestion and 7 days retention. Overage is possible but costs 10% more than the “base” volume
Pros:
- Server-side parsing, with the possibility to define custom rules
- Easy setup via Scalyr agent
- Good API access
Cons:
- Not available on premises
- Requires installing Scalyr agent, no support for popular tools and protocols (e.g. syslog, though you can send syslog to Scalyr agent)
If you want to go the do-it-yourself route, there are OSS tools that get you most of the way. Being open-source, you can either extend them yourself or pick other tools from their respective ecosystems. From said ecosystems, we’ll also concentrate on log shippers, the tools that fetch your logs – sometimes buffer, parse and enrich them – and finally send them one or more destinations.
12. Elasticsearch, Logstash and Kibana (ELK stack or Elastic Stack)
The ELK stack contains most of the tools needed for a log management solution:
- Log shippers such as Logstash and Filebeat
- Elasticsearch as a scalable search engine
- Kibana as the UI to search for logs or build visualizations
It’s very popular for centralizing logs, with lots of tutorials on how to use it all around the web. There’s a vast ecosystem of tools that you can use on top of the basic setup to enhance it with alerting, role-based access control, and more. We go into details about these extra additions in this blog post where we discuss Elastic Stack features alternatives.
- Elasticsearch indexes every field by default, making searches fast
- Real-time visualizations via API and Kibana
- Data parsing and enriching before indexing
Pricing: Free & Open source. Some companies offer forms of hosted ELK, see above. There’s also Elastic Cloud which is a pure form of ELK in the cloud, that you’d mostly have to manage yourself.
Pros:
- Scalable search engine as log storage
- Mature log shippers
- Web UI and visualizations in Kibana
Cons:
- At scale, it may become difficult to maintain. Which is why Sematext offers ELK stack consulting, production support, and training
- The open-source version of the ELK Stack misses some features like role-based access control and alerting. You can get these features through a commercial “Elastic Stack Features” or its alternatives or visa Open Distro for Elasticsearch.
13. Graylog
Source: Graylog Documentation
Like the ELK stack, Graylog is an open-source log management tool, using Elasticsearch as its storage. Unlike the ELK stack, which is built from individual components (Elasticsearch, Logstash, Kibana), Graylog is built as a complete package that can do everything.
Key Features:
- One package with all the essentials of log processing: collect, parse, buffer, index, search, analyze
- Additional features that you don’t get with the open-source ELK stack, such as role-based access control and alerts
Pricing: Free & Open source, though there’s an Enterprise version as well (with pricing available upon request)
Pros:
- Fits the needs of most centralized log management use-cases in one package
- Easily scale both the storage (Elasticsearch) and the ingestion pipeline
Cons:
- Visualization capabilities are limited, at least compared to ELK’s Kibana
- Can’t use the whole ELK ecosystem, because they wouldn’t directly access the Elasticsearch API. Instead, Graylog has its own API
14. GoAccess
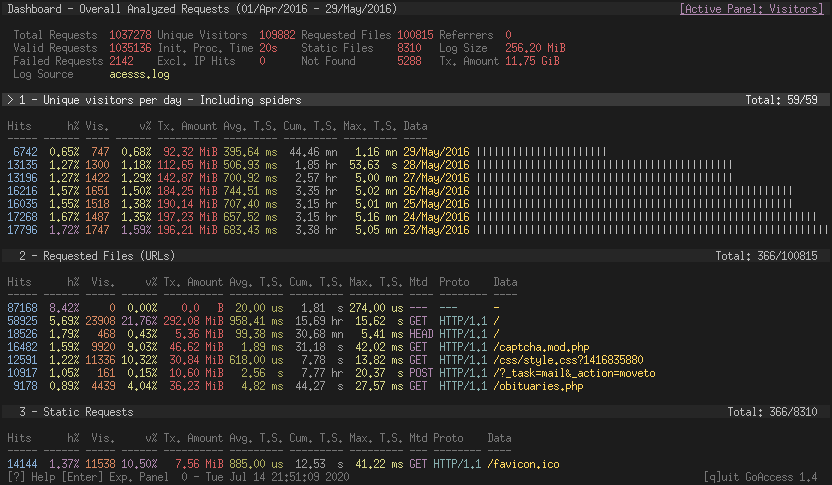
GoAccess is a free and open source log analysis and monitoring tool specialized for web logs formats such as Nginx, Apache, and Amazon S3. Dashboards can be rendered in your *nix terminal or in your browser. Reports are available as well.
Key features:
- Easy to use and get started. Just point it to any supported log file
- Lean and mean. Written in C, only depends on ncurses
Pricing:
- Free & Open source
Pros:
- Easily monitors key web traffic metrics
- Dashboards can be rendered in the terminal
Cons:
- GoAccess is intended to be used only for web logs, although custom log formats are supported
- Limited scale: in-memory storage (hash tables) that can spill to disk is the only storage option
15. Grafana Loki
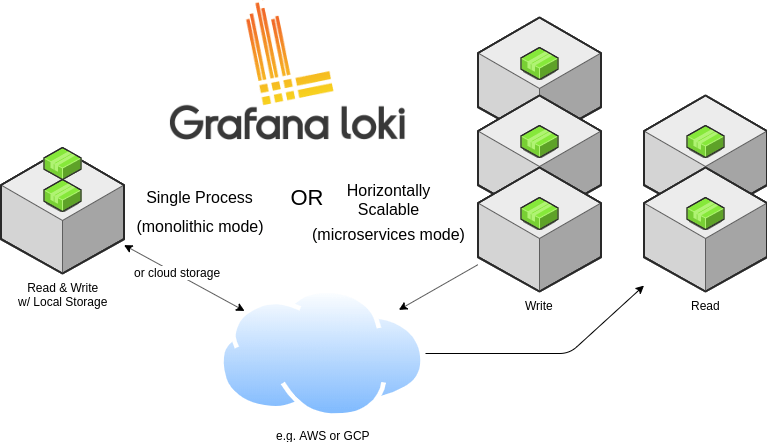
Source: Grafan Loki GitHub Page
Loki and its ecosystem are an alternative to the ELK stack, but it makes different trade-offs. By indexing only some fields (labels), it can have a completely different architecture. Namely, the main write component (Ingester) will keep chunks of logs in memory, making recent queries fast. As chunks get older, they are written in two places: a key-values store (e.g. Cassandra) for labels and an object store (e.g. Amazon S3) for the chunk data. Neither of them need background maintenance as you add data (like Elasticsearch/Solr need merges).
If you query older data, you typically filter by labels and timeframe. This restricts the number of chunks that have to be retrieved from the long term storage.
Key features:
- Logs and metrics in the same UI (Grafana)
- Loki labels can be consistent with Prometheus labels
Pricing:
- Free & Open source
- There’s also Grafana Cloud, offering Loki as SaaS (with an on-premises option as well). Prices start at $49, which includes 100GB of log storage (30 days retention) and 3000 metrics series
Pros:
- Faster ingestion compared to ELK: less indexing, no merging
- Small storage footprint: smaller index, data is only written once to the long term storage (which typically has built-in replication)
- Uses cheaper storage (e.g. AWS S3)
Cons:
- Slower queries and analytics for longer time frames compared to ELK
- Fewer log shipper options compared to ELK (e.g. Promtail or Fluentd)
- Less mature than ELK (e.g. more difficult to install)
16. Systemd Journal
Did you know that most Linux systems have a complete log management solution on board? Distributions based on systemd contain journald and journalctl.
systemd-journald – All Linux system processes write logs to the system journal, which is managed by journald. The system journal is local log storage. Check out this tutorial to learn more about journald, from what is and how to configure it to the most useful commands you should know and how to use it for centralizing Linux logs.
and how you can use it for centralized logging from this t
journalctl is the command line client to display logs with various filter options like time, system unit or any other field stored in the log event. Journalctl is not only useful for log search, but it also provides various other functions such as management of the system journal storage.
Journal-upload is a service to forward log events to a remote endpoint. Though if you’re interested in log centralization, have a look at forwarding journald logs via log shippers into the Elastic Stack to benefit from Elastic Stack features.
Key features:
- Supports structured logging out of the box
- Indexes all fields for fast searches
- Built-in compression
- Syslog-compatible API
Pricing: Free & Open source
Pros:
- Comes with every major Linux distribution
- No need for logrotate: you can configure retention in journald.conf
Cons:
- Binary storage means you can’t use text tools, such as grep
- No built-in centralization features
17. Logstash
Logstash is a log collection and processing engine that comes with a wide variety of plugins that enable you to easily ingest data from various sources, transform and forward it to a defined destination. It’s part of the Elastic Stack along with Elasticsearch and Kibana, which is why it’s most often used to ship data to Elasticsearch.
Key features:
- Lots of built-in plugins for input, filter/transform, and output
- Flexible configuration format: you can add in-line scripts, include other configuration files, etc
Pricing: Free & Open source
Pros:
- Easy to get started and move to complex configurations
- Flexible: Logstash is used in various logging use-cases and even for non-logging data
- Well-written documentation and lots of how-tos on the web
Cons:
- High resource usage, compared to other log shippers
- Lower performance, compared to alternatives
If you want to understand better how Logstash works, check out our Logstash tutorial, as well as other related posts:
- 5 Logstash Alternatives
- Elasticsearch Ingest Node vs Logstash Performance
- Handling Multiline Stack Traces with Logstash
- Recipe: Reindexing Elasticsearch Documents with Logstash
- Replaying Elasticsearch Slowlogs with Logstash and JMeter
18. rsyslog

Originally a syslog daemon, rsyslog has evolved into a free general-purpose logging tool that can read data from multiple sources, parse or enrich it, buffer it, and finally ship it to various destinations. It implements basic syslog protocol and extends it with content-based filtering, flexible configuration options, advanced filtering capabilities and adds new features such as using TCP, SSL, and RELP for transport. It offers high-performance, high security, and modular design.
Key features:
- Low memory and CPU footprint
- Fast, grammar-based parsing
- Modular architecture, suits centralizing logs
Pricing: Free & Open source
Pros:
- Comes out-of-the-box with most Linux distributions
- Great performance for most supported use-cases
- Well-suited for large-scale use-cases with features like rulesets, input and output queues, and built-in
scripting language
Cons:
- More difficult to configure, compared to other log shippers
- Documentation isn’t as well-organized, which makes for a steeper learning curve
If you want to learn more, download our free e-book on how to use ryslog to collect and parse data and/or go through the following related articles:
- Recipe: rsyslog + Redis + Logstash
- Recipe: rsyslog + Elasticsearch + Kibana
- Recipe: How to Integrate rsyslog with Kafka and Logstash
- Recipe: Apache Logs + rsyslog (parsing) + Elasticsearch
- Monitoring rsyslog’s Performance with impstats and Elasticsearch
- Monitoring rsyslog with Kibana and Sematext Infrastructure Monitoring
- Rsyslog 8.1 Elasticsearch Output Performance
- Structured Logging with Rsyslog and Elasticsearch
19. syslog-ng
Source: Syslog-ng Documentation
syslog-ng is a log shipper that evolved in a similar way to rsyslog, into a multi-functional data processing engine. In fact, it’s the other way around, as rsyslog was created later. Functionality is very similar, though each has its own unique features.
Key features:
- Great packaging support for many flavors of UNIX
- Grammar-based parser (PatternDB)
- Can use its buffer to correlate
log messages
Pricing: Free & Open source
Pros:
- Great performance and low resource usage
- Easy to use configuration format
- Good documentation
Cons:
- Buffers after parsing (like Fluentd below) which may lead to backpressure
20. Fluentd
Source: Fluentd GitHub Page
A good Logstash alternative, Fluentd is a favorite among DevOps, especially for Kubernetes deployments, as it has a rich plugin library. Like Logstash, it can structure data as JSON and touches all aspects of log data processing: collecting, parsing, buffering, and outputting data across various sources and destinations.
Key features:
- Good integrations with libraries and with Kubernetes
- Lots of built-in plugins, easy to write new ones
Pricing: Free & Open source
Pros:
- Good performance and resource usage
- Good plugin ecosystem
- Easy to use configuration
- Good documentation
Cons:
- No buffering before parsing, which may cause back pressure in the logging pipeline
- Limited support for transforming data, like you could do with Logstash’s mutate filter or rsyslog’s variables and templates
21. Filebeat
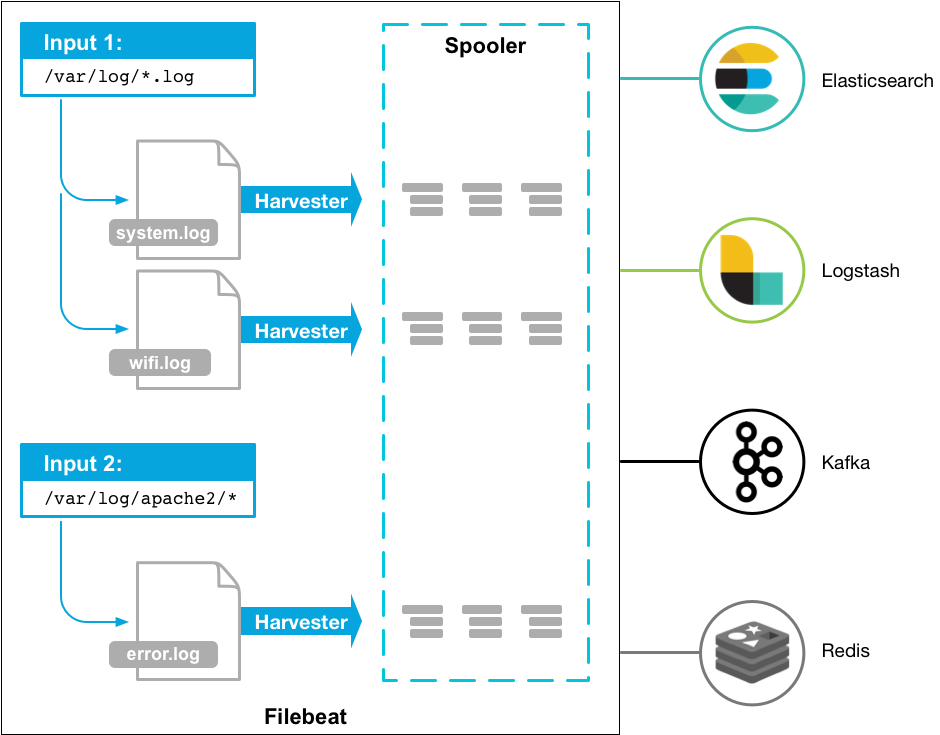
Source: Filebeat Documentation
Filebeat is a lightweight log shipper designed to complement Logstash, which is heavier. Typically, you’d send logs from Filebeat to Logstash and then Elasticsearch. Larger deployments may use Apache Kafka as a buffer. Filebeat can also send data directly to Elasticsearch. Minimal parsing can be done on the Filebeat side (e.g. JSON parsing) or on the Elasticsearch side, on Ingest nodes.
Key features:
- Lightweight and easy to use
- Modules are available for common use-cases (such as Apache access logs). You can use them to set up Filebeat, Ingest and Kibana dashboards with just a few commands
Pricing: Free & Open source
Pros:
- Low resource usage
- Good performance
Cons:
- Limited parsing and enriching capabilities
Further reading:
- Using Filebeat to Send Elasticsearch Logs to Sematext Logs
- How to Ship Kibana Server Logs to Elasticsearch
22. Logagent
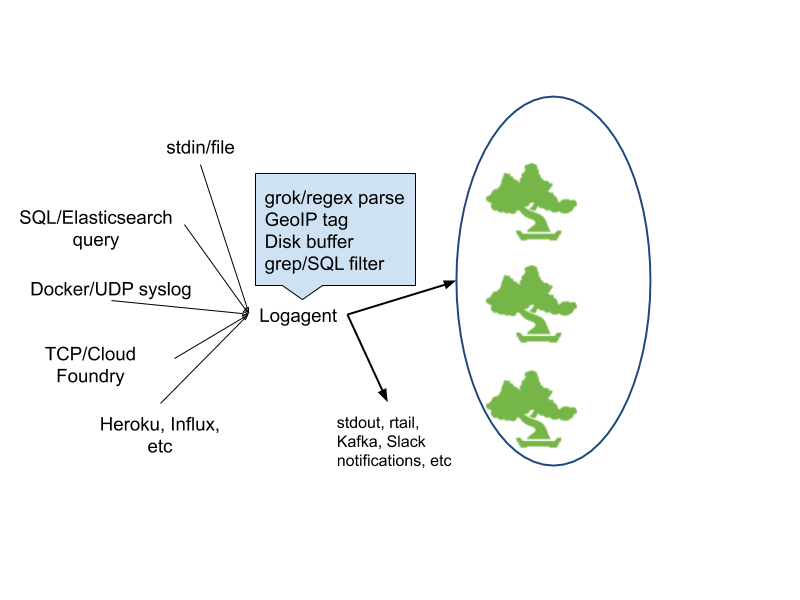
Logagent is a modern, lightweight, and open-source log shipper featuring extensible log parsing, on-disk buffering, secure transport and bulk indexing to Elasticsearch or Sematext Cloud.
As it uses few system resources, it’s suitable for deploying on edge notes and devices, while its ability to parse and structure logs make it a great Logstash alternative. Logagent is designed to be very easy to use even for those who haven’t used a log shipper before.
Key features:
- Includes lots of parsing rules and can automatically detect common types of logs and parse them
- Easy integration with Docker and Kubernetes
Pricing: Free & Open source
Pros:
- Easy to use, especially on Docker and Kubernetes
- Good performance and resource usage
- Easy to extend. Which is why, beyond the “usual” inputs, like files, TCP and Kafka, you’ll find some that are more specific: from querying Elasticsearch or Cassandra to acting as an MQTT client or collecting dust sensor measurements
Cons:
- Ecosystem isn’t as rich as that of Logstash or Fluentd
If you’re interested in finding out more about how Logagent works, read our dedicated blog posts:
- How to Monitor Docker Containers with Sematext Logagent
- Logagent Meets Apache Kafka
- Shipping data to AWS Elasticsearch with Logagent
There are some great tools in the log management landscape e that you can choose from, but it depends on your particular specifications and even personal preferences on which one suits your use-case best. You may be fine starting with an open-source framework, but keep in mind that it may not have full-blown features like Sematext Logs or Datadog.
If you need help deciding, feel free to reach out. If you need help with an open-source tool, please note that Sematext offers Logging Consulting as well as ELK production support.
You might also be interested in:
- Best Cloud Logging Services
- Best Log Analysis Tools
- Best NGINX Log Analyzers
- Best Apache Log Analysis Tools
Start Free Trial

Файлы журнала скажут вам, что пошло не так, когда система внезапно перестает работать. Они также помогут вам отслеживать любые системные изменения и даже могут помочь вам обеспечить безопасность вашей сети. Файлы журналов являются настолько важным элементом источников информации о вашем сетевом администрировании, что существуют инструменты, разработанные специально для того, чтобы помочь вам управлять ими..
Ниже мы подробно рассмотрим каждый из инструментов, которые попали в эту статью, но в случае, если у вас есть время только для быстрого ознакомления, вот наши Список лучших инструментов управления журналами:
- Менеджер событий SolarWinds Security (бесплатная пробная версия) Этот инструмент автоматически генерирует отчеты HIPAA, PCI DSS, SOX, ISO, NCUA, FISMA, FERPA, GLBA, NERC CIP, GPG13, DISA STIG..
- ManageEngine EventLog Analyzer (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ) Инструмент SIEM, который охотится за угрозами злоумышленников. Устанавливается на Windows, Windows Server или Linux.
- SolarWinds Papertrail (БЕСПЛАТНЫЙ ПЛАН) Облачная служба имеет функции фильтрации содержимого файлов и может извлекать записи по дате, чтобы помочь вам с вашими задачами управления событиями.
- Loggly (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ) Облачный анализатор логов, который передает данные на удаленные серверы для анализа. Доступен в бесплатной и платной версиях.
- Сетевой монитор Paessler PRTG (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ) Эта система мониторинга охватывает сети, серверы и приложения; он включает в себя датчик журнала событий Windows и приемник системного журнала.
- Splunk Комплексная система управления журналами для MacOS, Linux и Windows.
- Fluentd Облачный концентратор для информации файла журнала, собранной агентом в вашей системе.
- Logstash Является частью бесплатного Elastic Stack, это инструмент сбора данных журнала.
- Kibana Это приложение для просмотра данных Elastic Stack; Команды, доступные с Kibana, включают базовое управление файлами, которое может разбить любой файл журнала по дате.
- Graylog Бесплатная система с открытым исходным кодом на основе файлов журналов для Ubuntu, Debian, CentOS и SUSE Linux.
- XpoLog Эта утилита может анализировать данные из журналов сервера Apache, журналов событий AWS, Windows и Linux и Microsoft IIS.
- Экспедитор системного журнала ManageEngine Бесплатный менеджер сообщений журнала для Windows, который может отфильтровывать ненужные, обычные или неважные сообщения журнала.
- Managelogs Бесплатная утилита с открытым исходным кодом для управления журналами веб-сервера Apache..
Как только вы найдете инструмент управления журналами, который вам нравится, вы начнете зависеть от него для ряда задач администратора, включая управление информацией о безопасности и событиями (SIEM) и мониторинг вашей сети и ее оборудования в режиме реального времени. Если ваш любимый инструмент выходит из производства, вам нужно будет быстро найти замену, чтобы вы могли продолжать управлять журналами событий и сортировать все данные журналов..
Contents
- 1 Лучшие инструменты управления журналами для Windows, Linux и Mac
- 1.1 1. Менеджер событий SolarWinds Security (бесплатная пробная версия)
- 1.2 2. ManageEngine EventLog Analyzer (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
- 1.3 3. Papertrail (БЕСПЛАТНЫЙ ПЛАН)
- 1.4 4. Loggly (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
- 1.5 5. Paessler PRTG Сетевой монитор (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
- 1.5.1 PRTG Windows Event Log Sensor
- 1.5.2 PRTG Syslog Receiver Sensor
- 1.6 6. Splunk
- 1.7 7. Свободно
- 1.8 8. Logstash
- 1.9 9. Кибана
- 1.10 10. Graylog
- 1.11 11. XpoLog
- 1.12 12. ManageEngine Syslog Forwarder
- 1.13 13. Managelogs
- 2 Архивация журнала
- 3 Заменить Cronolog
Лучшие инструменты управления журналами для Windows, Linux и Mac
К сожалению, Analog был прекращен еще в 2010 году, но вы можете найти наш следующий список инструментов управления и анализа журналов полезным, чтобы помочь вам найти альтернативу. Нашими критериями при выборе следующих инструментов являются в основном их надежность в различных отраслевых применениях, простота использования и установки, обширная документация и поддержка, а также общая производительность и функции..
1. Менеджер событий SolarWinds Security (бесплатная пробная версия)
В отличие от Cronolog, Менеджер событий SolarWinds Security не бесплатно Тем не менее, вы можете получить доступ к нему на 30-дневную бесплатную пробную версию. Это очень комплексная система управления журналами, и она будет особенно полезна для крупных организаций. Это позволит вам в режиме реального времени контролировать и поможет вам быстро найти каждый журнал событий.
Это программное обеспечение работает на Windows Server операционная система, но она не ограничивается управлением зарегистрированными событиями, которые возникают только в Windows. Менеджер — это кроссплатформенная утилита это будет иметь дело со всеми вашими задачами регистрации системы, независимо от того, из какой операционной системы они берутся.
Удивительная особенность этого менеджера журнала заключается в том, что он проверит информацию в ваших файлах журнала, отдельно отслеживая данные в реальном времени. Это отличная функция безопасности в наши дни передовых постоянных угроз, когда хакеры регулярно меняют файлы журналов, чтобы скрыть свои следы. Это пример того, как SolarWinds Security Event Manager выходит за рамки исторической необходимости проверять, что произошло, когда что-то пошло не так.
Сегодня управление файлами журналов стало функцией безопасности системы и процедур целостности данных.. Благодаря новым требованиям ЕС к ВВПР защита данных стала жизненно важным приоритетом системного администрирования.. Необходимость быстро исправлять утечки данных делает файлы журналов основным источником информации. Дополнительные функции этого инструмента включают в себя управление USB-накопителем и функции анализа событий.
Этот менеджер журналов также является хорошим выбором для сайтов, которые требуют соответствия стандартам. Диспетчер журналов и событий автоматически генерирует HIPAA, PCI DSS, SOX, ISO, NCUA, FISMA, FERPA, GLBA, NERC CIP, GPG13, DISA STIG отчеты для демонстрации соответствия или выделения пробелов для корректирующих действий.
Чувствительные к безопасности сайты нуждаются в гораздо большем количестве программного обеспечения для управления журналами, чем Cronolog. Итак, если вы ищете утилиту для замены и вам также нужны функции SIEM, подумайте о том, что нужно вашей компании сейчас из системы управления журналами, не то, что вы могли сойти с рук, когда Cronolog был впервые написан.
Управление событиями журнала SolarWindsСкачать 30-дневную бесплатную пробную версию на SolarWinds.com
2. ManageEngine EventLog Analyzer (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
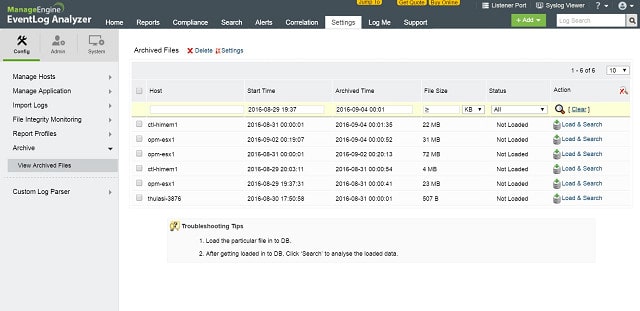
ManageEngine EventLog Analyzer это больше, чем файл-сервер журнала. Это Система обнаружения вторжений который ищет угрозы в сети.
Почти каждая единица оборудования и программного обеспечения в вашем бизнесе генерирует сообщения журнала периодически и в ответ на исключительные события. EventLog Analyzer ловит эти сообщения при их перемещении по сети и сохраняет их в файл.
Основным источником сообщений является Журнал событий Windows система и Syslog сообщения, поступающие из систем Linux. EventLog Analyzer также получает сообщения журнала от веб-сервера Apache, систем баз данных, брандмауэров, сетевого оборудования и программного обеспечения для обеспечения безопасности..
Как только сообщения журнала сохраняются в файлах, их необходимо периодически архивировать. Файлы должны быть организованы в логической манере, что облегчает доступ к событиям определенных дат. EventLog Analyzer обрабатывает всю эту работу по управлению файлами журналов. В качестве источника раскрытия информации о несанкционированной деятельности хакеры часто используют файлы журналов для удаления следов своего вторжения. EventLog Manager отслеживает изменения в журналах и блокирует несанкционированный доступ.
Данные журнала являются богатым источником информации о состоянии оборудования вашей системы. модуль анализа EventLog Analyzer использует информацию журнала для аудита доступа пользователей к критическим ресурсам. Это особенно важно при охоте на злоумышленников. Вторжение может быть не только несанкционированным доступом посторонних лиц, но и несоответствующим доступом к данным со стороны персонала..
EventLog Analyzer также проверяет действия приложений, проверяя работу веб-серверов, DHCP-серверов, баз данных и других важных служб в вашей системе. Информация, полученная в результате этих действий по мониторингу, важна как для показателей производительности, так и для безопасности..
ManageEngine EventLog Analyzer устанавливается на Windows, Windows Server и RHEL, Mandrake, SUSE, Fedora и CentOS Linux. Это платный продукт, но есть и бесплатная версия, которая собирает журналы из пяти источников. Вы можете получить 30-дневную бесплатную пробную версию Premium Edition. Сетевая версия, называемая Distributed Edition, также доступна для 30-дневной бесплатной пробной версии..
ManageEngine EventLog AnalyzerDownload 30-дневная бесплатная пробная версия
3. Papertrail (БЕСПЛАТНЫЙ ПЛАН)
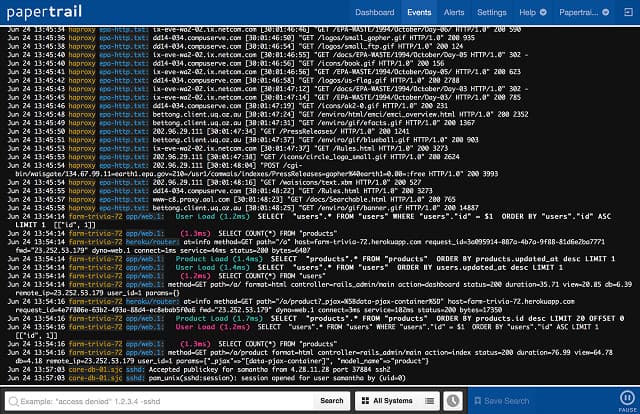
Papertrail — это система управления бревнами производится SolarWinds, ведущим производителем сетевого программного обеспечения. Основной целью Papertrail является централизация всех данных файла журнала в одном месте, поэтому это журнал агрегатор. Это заметно отличает его от Coronolog, лог-файла синтаксический анализатор. Что сказал, Возможности фильтрации содержимого файлов Papertrail позволяют извлекать записи по дате, чтобы помочь вам в решении задач управления событиями..
Вы можете использовать Papertrail для проверки ряда файлов журнала, включая события Windows, программные сообщения Ruby on Rails, уведомления маршрутизатора и брандмауэра, а также файлы журнала сервера Apache.. Сервис основан на облаке, поэтому вам не нужно беспокоиться о том, будет ли он работать в вашей операционной системе.. Вы получаете доступ к панели инструментов через веб-браузер.
Цена на услугу варьируется в зависимости от объема поиска, который вы через него ставите. Есть бесплатный план это дает вам пропускную способность данных 100 МБ в месяц. Это не очень много, но если вы ограничите покрытие услуг только журналами Apache, вам, возможно, удастся сойти с рук. Самый дешевый платный тариф дает вам надбавку за данные в 1 ГБ в месяц по цене 7 долларов. Платные планы работают по подписке, и вы платите ежемесячную плату.
Каждый план позволяет вам просматривать период данных и архивировать данные за различный промежуток времени. Например, бесплатный сервис позволяет вам работать с данными за последние 48 часов, и вы можете архивировать данные в течение семи дней. Этого было бы достаточно, чтобы подражать Cronolog, потому что для этого, вам нужно только смотреть на данные за один день за один раз.
SolarWinds Papertrail Log ManagementЗарегистрируйся для бесплатного плана
4. Loggly (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)
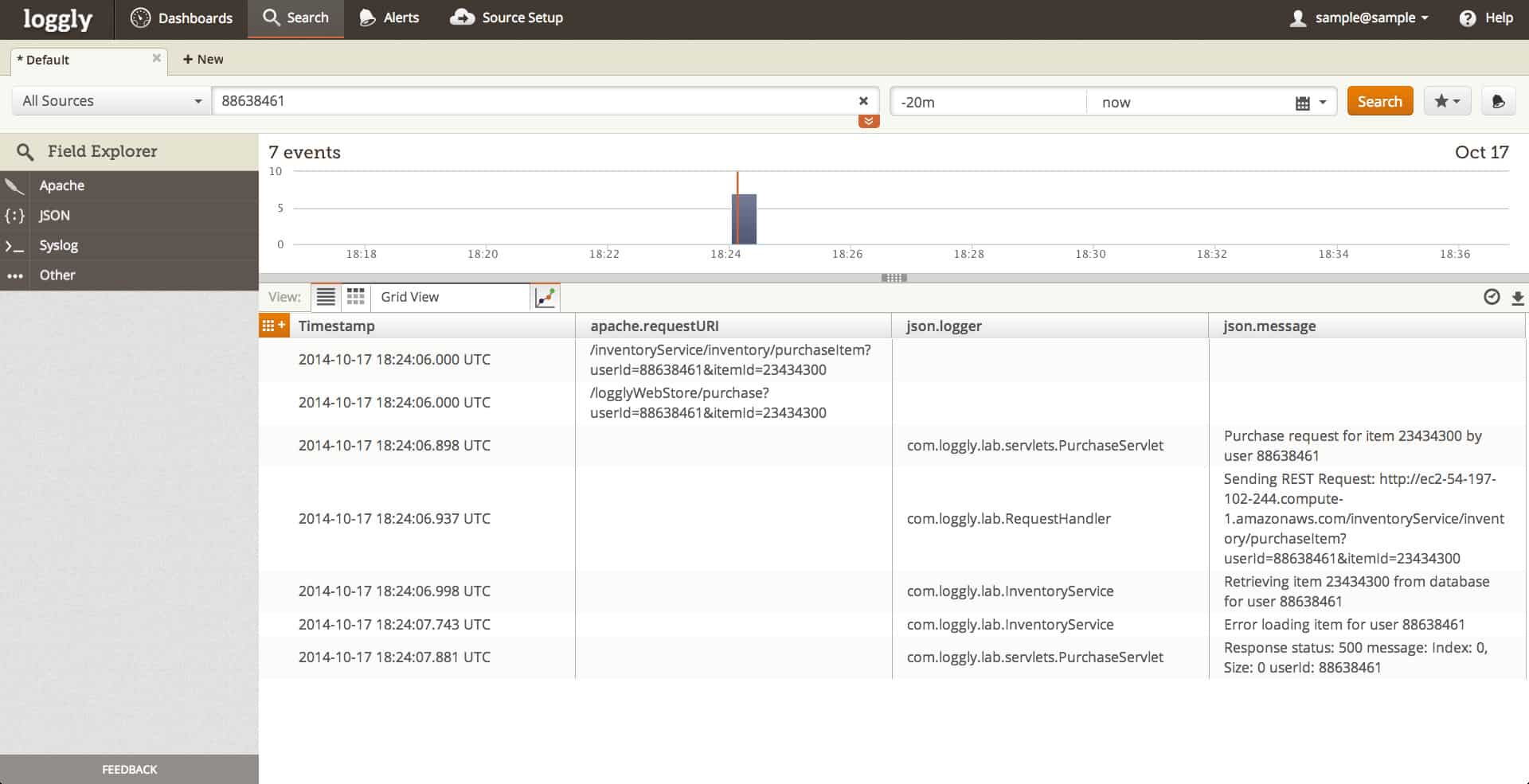
Loggly это консолидатор журналов, который базируется в облаке. Этот онлайн-сервис также предлагает средства анализа журналов. Большим преимуществом этого облачного подхода является то, что вам не нужно поддерживать какое-либо программное обеспечение для использования утилиты. Ваша локальная система должна быть скоординирована со службой Loggly, чтобы она периодически загружала ваши стандартные файлы журнала на онлайн-сервер.
Как консолидатор, Loggly переформатирует загруженные записи файла журнала в стандартный формат. Это позволяет анализатору обрабатывать записи из нескольких разных источников и позволяет отслеживать события в вашей системе независимо от операционной системы или методологии, которая генерировала эти записи событий. Источники сообщений файла журнала не ограничиваются вашими локальными серверами. Он также может обрабатывать записи, созданные онлайн-серверами, такими как AWS, и может включать в себя сообщения, созданные приложениями, такими как Docker и Logstash..
Возможная точка уязвимости в этой операционной модели заключается в передаче данных. Тем не менее, вы, несомненно, уже используете защищенную систему передачи файлов, такую как FTPS. Встроенная в этот стандарт защита TLS защитит ваши данные во время загрузки. TLS также охватывает передачу данных с сервера Loggly на ваш браузер через HTTPS протокол.
Услуга Loggly предлагается в трех тарифных планах. Пакет начального уровня можно использовать бесплатно. Это называется Loggly Lite. Каждый план имеет лимит обработки данных, и вы можете обнаружить, что ограничения на бесплатную услугу не дают вам достаточно места для ваших данных журнала. Вам разрешено загружать 200 МБ данных журнала в день с помощью Loggly Lite, и система будет хранить каждую запись в течение семи дней..
стандарт Пакет Loggly дает вам возможность загрузки 1 ГБ в день и сохраняет каждую запись в течение 30 дней. Вы также получаете доступ к нескольким учетным записям с платными пакетами. В стандартном пакете вы можете иметь три учетных записи. Пакет с более высокой платой не ограничивает количество пользователей, которых вы можете настроить в своей учетной записи. Тот план, который называется Loggly Enterprise, пакет на заказ с ценами в зависимости от объема загрузки и требуемого периода хранения.
Loggly — это сервис подписки, который вы можете оплачивать ежегодно или ежемесячно. Ты можешь получить 14-дневная бесплатная пробная версия Стандартного плана. Если вы решите не использовать этот план в конце пробного периода, ваша учетная запись будет автоматически переключена на бесплатный план Loggly Lite.
logglyСкачать 13-дневную бесплатную пробную версию
5. Paessler PRTG Сетевой монитор (БЕСПЛАТНАЯ ПРОБНАЯ ВЕРСИЯ)

Paessler PRTG Сетевой монитор это комплексный инструмент мониторинга сетей, серверов и приложений. Управление журналами является важной частью системного администрирования, поэтому Paessler позаботился о том, чтобы включить раздел мониторинга журналов в PRTG.
Каждый интерфейс мониторинга в PRTG называется датчиком. Есть два датчика, которые управляют журналами. Эти Журнал событий Windows датчик и Syslog Receiver датчик.
PRTG Windows Event Log Sensor

Журнал событий Windows API-датчик ловит все сообщения журнала, которые генерирует система Windows. Это включает в себя оповещения приложений и уведомления операционной системы. Датчик контролирует скорость сообщений журнала, а не содержание каждого сообщения. Тем не менее, он классифицирует эти тревоги по источнику или типу события. Датчик генерирует сигнал тревоги на приборной панели, если скорость сообщений журнала событий возрастает. Эти уведомления могут быть отправлены вам в виде электронного письма или SMS-сообщения. Вы можете настроить оповещения так, чтобы они отправлялись разным членам команды в зависимости от их серьезности или источника..
PRTG Syslog Receiver Sensor
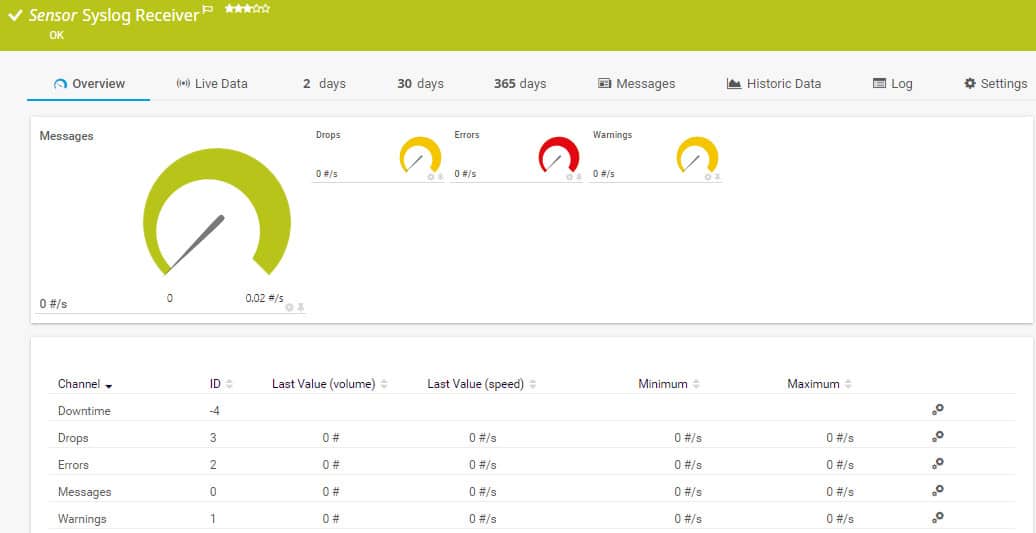
Датчик приемника системного журнала получает, контролирует и сохраняет сообщения системного журнала. Это дает вам инструмент управления файлами системного журнала, но датчик — это не просто пассивная функция создания файлов. Элемент мониторинга обязанностей получателя генерирует сигналы тревоги, если возникают тревожные условия, например, увеличение скорости создания файла. Вы можете установить условия, которые вызывают оповещения, и вы можете решить, кому и как доставляются уведомления..
Paessler PRTG может контролировать до 100 датчиков. Если вы хотите использовать инструмент для мониторинга всей вашей сети, вам понадобится намного больше датчиков, и за этот уровень обслуживания взимается плата. Вы можете получить 30-дневная бесплатная пробная версия с неограниченным количеством датчиков.
Скачать бесплатную пробную версию (42.6MB) Скачать 30-дневную бесплатную пробную версию
6. Splunk
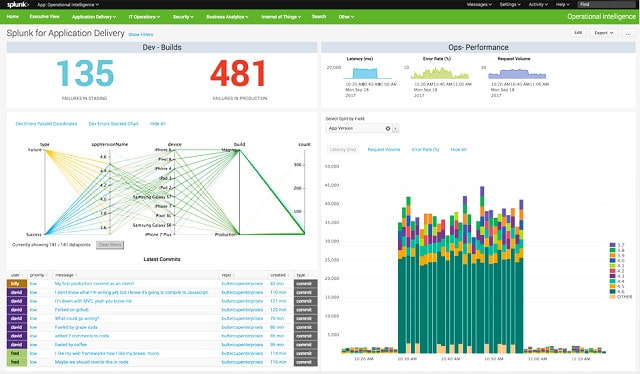
Splunk — это комплексная система управления журналами для macOS, Linux и Windows. Система является широко известной утилитой в сообществе системного администратора. Splunk, Inc выпускает три версии своего программного обеспечения для мониторинга сетевых данных. Самая популярная версия называется Splunk Enterprise, которая стоит 173 доллара в месяц. Это система управления сетью, а не просто органайзер файла журнала. к счастью, Splunk также доступен бесплатно, сделать его в наш список альтернатив Cronolog.
Бесплатный Splunk ограничен анализом входных файлов. Вы можете подавать любые ваши стандартные журналы или направлять текущие данные через файл в анализатор. Бесплатная утилита может иметь только одну учетную запись пользователя, и ее пропускная способность ограничена до 500 МБ в день. Система явно не работает с сетевыми оповещениями, но Вы могли бы форсировать эту функцию, получая оповещения, записанные в файл, а затем перешли в Splunk.
Утилита сортировки и фильтрации данных встроена в Splunk, и вы можете записывать в файлы из анализатора. Эти функции могут эмулировать Cronolog, разделяя записи журнала по дате и записывая каждую группу в новые файлы..
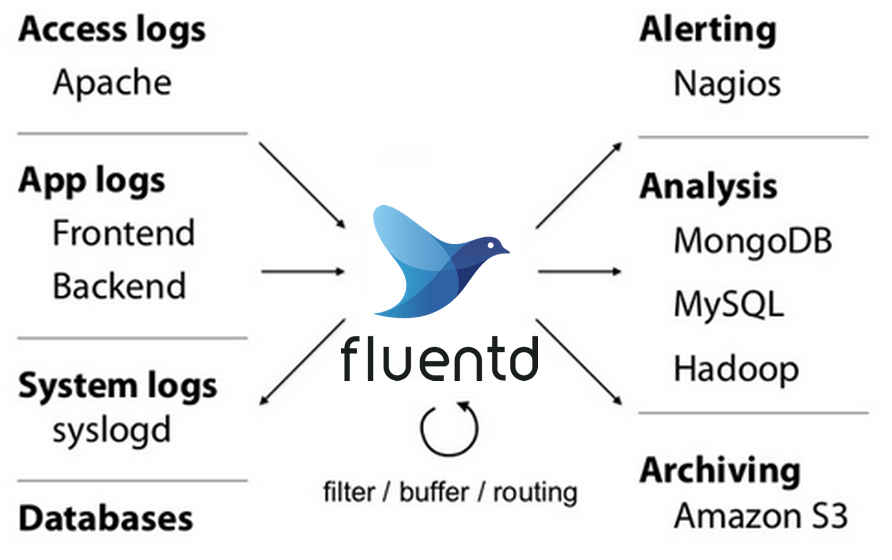
7. Свободно
Как и Cronolog, Fluentd работает в системах Linux — Debian, CentOS и Ubuntu. Он также может быть установлен на Mac OS, Amazon Linux, RHEL и Windows. Эта облачная утилита выступает в роли концентратора для информации из файла журнала, собранной агентом в вашей системе. Инструмент может собирать потоки данных в реальном времени для создания файлов журналов, а также отслеживать и управлять существующими файлами.. Одним из источников данных, которым Fluentd предназначен для управления, является система журналирования Apache..
Результаты анализа записей журнала могут быть использованы для запуска предупреждений, но они должны обрабатываться Nagios или системой мониторинга на основе Nagios. Fluentd — это проект с открытым исходным кодом, поэтому вы можете скачать исходный код. Этот инструмент можно использовать бесплатно.
Сайт Fluentd является источником программы, а также местом нахождения страницы сообщества, где вы можете получить помощь и совет по запуску инструмента от других пользователей. Базовый пакет может быть расширен с помощью плагинов, написанных другими участниками сообщества. Эти плагины, как правило, бесплатно.
Вы можете использовать много других бесплатных интерфейсов в качестве внешнего интерфейса для Fluentd, например, Kibana. Утилита Fluentd также может быть интегрирована с инструментами, которые включают Elasticsearch, MongoDB и InfluxDB для анализа.
8. Logstash

Logstash — это средство для создания бревен, производимое Elastic. Эта голландская организация по разработке программного обеспечения создала ряд продуктов для исследования данных, которые объединены в «Эластичный стек.«Этот пакет программ с открытым исходным кодом, и каждый продукт доступно бесплатно. Основным элементом Elastic Suite является Elasticsearch. Это утилита поиска и сортировки, которая может обрабатывать данные из нескольких файлов в единые результаты. Elasticsearch может быть интегрирован в другие инструменты и доступен для использования со многими другими утилитами в этом списке.
Logstash — это инструмент сбора данных Elastic Stack. Функции Logstash могут быть адаптированы к подражать Cronolog. Средство создает исходные файлы для анализа другими инструментами, такими как Elasticsearch. Сила этого инструмента в том, что он может сопоставлять данные из нескольких разных источников. Однако, если вы хотите реорганизовать файлы журналов Apache, нет никаких причин, по которым вы не можете ограничить поиск данных только одним исходным файлом журнала..
Возможности Logstash включают в себя разбор файлов, поэтому вы можете использовать эту функцию для разделения файлов журнала по дате.. Выходные данные Logstash могут быть отформатированы, чтобы соответствовать длинному списку утилит для анализа или отображения. Его также можно записать в простой текстовый файл на диске, что и делал Cronolog..
9. Кибана
Эластик производит Kibana, который является отличный бесплатный интерфейс для любого инструмента сбора данных. Другие полезные инструменты в этом списке могут передавать данные в Kibana, поэтому вам не нужно полагаться только на другие программы Elastic Stack для получения данных для этого приложения..
Все возможности Kibana выходят далеко за рамки функции разбора файлов в Cronolog.. Однако широкий спектр команд, доступных в Kibana, включает базовое управление файлами, которое может разбить любой файл журнала по дате. Kibana имеет консоль на командном языке, которая позволяет создавать сценарии и программы для обработки файлов. Тем не менее, если у вас нет навыков программирования, предустановленные средства управления данными интерфейса предоставляют вам множество мощных утилит сортировки и фильтрации данных. это поможет вам управлять файлами журналов.
Интерфейс включает инструменты анализа на основе времени, включая фильтры, так что вы можете легко изолировать записи в файле журнала, которые относятся к определенной дате. Необработанные данные, графики и другие визуализации могут быть записаны в файлы или использованы для создания отчетов. Стандартные отчеты можно запускать периодически, поэтому создание фильтра по дате и настройка его ежедневной работы и вывода в простой текстовый файл даст вам те же самые результаты, которые вы использовали в Cronolog..
Преимущество использования Kibana состоит в том, что он может оказать гораздо большую помощь, чем Cronolog.. Вы можете сравнивать данные из разных источников и визуализировать информацию из всех файлов системного журнала. анализировать производительность и прогнозировать требования к мощности. Чтобы получить полное средство управления данными, вам, вероятно, следует использовать Logstash для сопоставления исходных данных, Elasticsearch для сортировки данных и Kibana для отображения результатов. В Kibana имеется множество возможностей для сбора и обработки данных, поэтому его можно использовать как самостоятельный инструмент для анализа данных..
10. Graylog
Graylog является бесплатная система с открытым исходным кодом это может дать вам гораздо больше функциональности, чем просто утилита архивирования журналов. Этот анализатор журналов имеет графический интерфейс пользователя и может работать в Ubuntu, Debian, CentOS и SUSE Linux. Вы также можете запустить его на виртуальной машине в Microsoft Windows и установить систему Graylog в Amazon AWS..
Это средство управления журналами может работать с любыми журналами. Вы можете вводить в него данные из других источников: направлять системные отчеты в файл, создавая собственные журналы. Интерфейс не получает копии журналов, а размещается в оперативных журналах, обновляя информацию, которая поступает в механизм анализа по мере записи новых записей в журнал..
Сценарии действий могут пересылать данные журнала на экран, в другие журналы или в другие приложения.. На панели инструментов отображаются данные в виде гистограмм, круговых диаграмм, линейных графиков и списков с цветовой кодировкой.. Интерфейс включает функцию поиска и запроса, которая позволяет фильтровать записи в журнале, чтобы получать информацию о конкретных типах событий или конкретных источниках..
Graylog обрабатывает агрегированные данные, чтобы упростить отображение на домашней странице панели мониторинга, а также дать возможность указывать условия оповещения для разных источников данных и с течением времени. Эти общие представления данных не единственный вариант, потому что Вы можете развернуть и посмотреть подробные записи это создало резюме. Это делает Graylog инструментом для анализа данных.
Условия оповещения могут быть настроены, и вы можете написать действия, которые будут выполняться в случае возникновения оповещений. Эти действия включают выполнение сценариев или уведомление определенных членов команды по электронной почте или с помощью сообщения Slack..
Это удивительный и очень всеобъемлющий инструмент, который может автоматизировать обработку вашего файла журнала и автоматически выполнять устранение неисправностей..
11. XpoLog
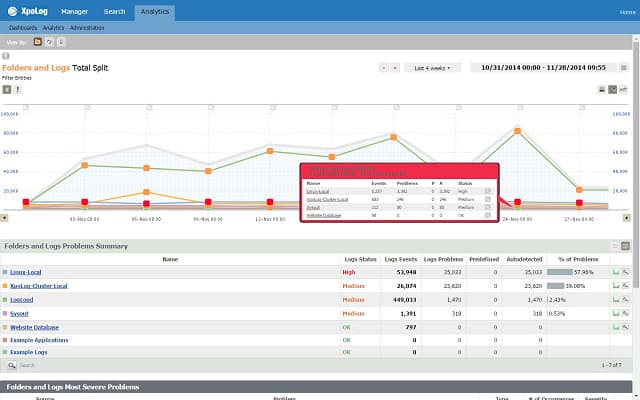 Два важных элемента Cronolog заключаются в том, что он может разбивать файлы журналов по дате и запускаться автоматически. XpoLog включает в себя обе эти функции. Однако это большое улучшение в Cronolog, поскольку XpoLog включает в себя множество других функций. Это огромное улучшение в этом прекращенном инструменте анализа логов.
Два важных элемента Cronolog заключаются в том, что он может разбивать файлы журналов по дате и запускаться автоматически. XpoLog включает в себя обе эти функции. Однако это большое улучшение в Cronolog, поскольку XpoLog включает в себя множество других функций. Это огромное улучшение в этом прекращенном инструменте анализа логов.
XpoLog может анализировать данные из разных источников, включая журналы сервера Apache, журналы событий AWS, Windows и Linux и Microsoft IIS. Утилита может быть установлена на Mac OS X 10.11, macOS 10.12 и 10.13, Windows Server 2008 R2, Windows Server 2012, Windows Server 2016, Windows 8, 8.1 и 10. Это программное обеспечение также можно установить на Linux Kernel 2.6 и более поздних версиях.. Вы можете выбрать облачную версию, если не хотите устанавливать программное обеспечение. Вы можете получить к нему доступ через Chrome, Firefox, Internet Explorer или Microsoft Edge.
Помимо простого управления файлами журналов, механизм анализа XpoLog обнаруживает несанкционированный доступ к файлам и помогает оптимизировать использование приложений и оборудования.. XpoLog собирает данные из выбранных источников и будет контролировать эти файлы что вы включаете в его сферу. После централизации данных XpoLog объединяет все источники данных и создает собственную базу данных записей. Эти записи можно искать и фильтровать для анализа, а результаты можно записывать в файлы. Эта функциональность предлагает такой же анализ файла как Cronolog. Результаты могут быть записаны в файлы или сохранены в виде архивов для просмотра через панель управления XpoLog.
XpoLog это доступно бесплатно. Если вы просто хотите разделить файлы журнала Apache, то бесплатная версия будет достаточно хорошей. Чтобы работать с большими объемами данных и использовать систему для анализа, вам, возможно, придется перейти на один из платных планов.
Бесплатная версия позволяет обрабатывать до 1 ГБ данных в день, и система будет хранить эти данные в течение пяти дней.. Вы всегда можете записать записи в текстовые файлы, чтобы обойти этот пятидневный лимит. Самый дешевый платный план предлагает тот же лимит пропускной способности и срок хранения данных, что и бесплатный сервис, поэтому трудно понять, почему кто-то заплатил бы 9 долларов в месяц за этот пакет. Более дорогие планы дают вам неограниченный срок хранения данных, с самым дешевым неограниченным вариантом, включая пропускную способность 1 ГБ в день за 39 долларов в месяц. Вы получаете постепенно увеличивающиеся суточные пропускные способности для данных в каждой ценовой категории. Лучший план обеспечивает пропускную способность 8 ГБ в день и стоит 534 доллара в месяц. Вы должны платить за услугу ежегодно заранее, даже если цена указана за месяц. Вы также можете купить бессрочную лицензию.
12. ManageEngine Syslog Forwarder
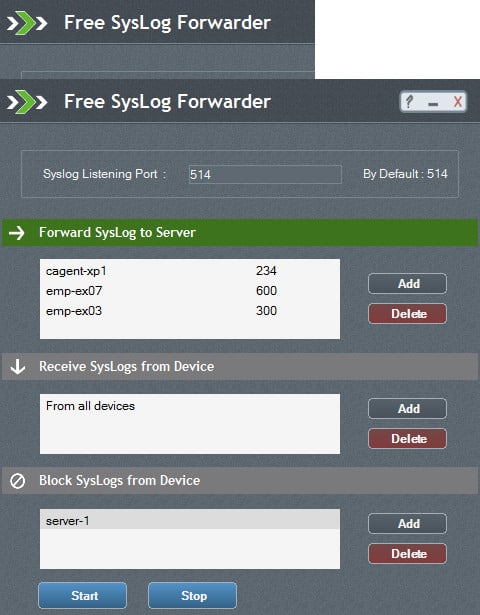
Пересылка системного журнала работает в операционной системе Windows и совершенно бесплатно использовать. Он перехватывает записи системного журнала и направляет их на разные серверы системного журнала в соответствии с базой правил.. Функции сервера пересылки позволяют отфильтровывать несущественные, обычные или неважные сообщения журнала.. Все заблокированные сообщения отправляются в исходный файл журнала, но не отправляются в конечный файл журнала.
База правил Syslog Forwarder позволяет вам ежедневно записывать новые файлы журналов, тем самым эмулируя функциональность Cronolog. Большая разница между Syslog Forwarder и Cronolog заключается в том, что этот существующий менеджер журналов работает в Windows с графическим интерфейсом, тогда как Cronolog был функцией командной строки для систем Unix и Linux..
13. Managelogs

Вероятно, ближайшая альтернатива Cronolog, Managelogs написана на «С». Утилита не только бесплатная, но исходный код доступен для чтения. Программа специально разработана для управления журналами веб-сервера Apache..
Managelogs имеет различные режимы работы, активируемые переменными, указанными при запуске программы. Вы можете установить утилиту для архивирования файлов журнала по дате, или вы можете указать максимальный размер файла, который будет копировать файл журнала под новым именем, а затем очищать текущий файл журнала, чтобы он мог начинать заново с нуля и создавать новые записи..
Если вы укажете, что журналы должны быть разбиты по дате, Managelogs обеспечит консолидацию файлов между сеансами, поэтому остановка и перезапуск диспетчера сервера не сотрут существующие записи в неполный день..
Архивация журнала
Вы можете написать свою собственную копию Cronolog в виде сценария для Unix или Unix-подобных операционных систем, таких как Linux и Mac OS. Хотя есть много умных вещей, которые вы можете сделать с помощью регулярных выражений и сопоставления с образцом, чтобы выбрать записи на определенную дату, Самый простой способ получить архив журналов в день — написать сценарий копирования, а затем запланировать его запуск в полночь.. Если последние инструкции в сценарии удаляют существующий файл, новые записи будут накапливаться в отдельном файле в течение дня, чтобы снова архивироваться в полночь.
ДАТА = `дата +% Y% m% d`
MV = / USR / бен / мв
LogDir = / Opt / Apache / журналы
LOGARCH = / WWW / журналы
ФАЙЛЫ = «access_log error_log»
CP = / USR / бен / ф
для F в $ ФАЙЛЫ
делать
$ CP $ LOGDIR / $ f $ LOGARCH / $ f. $ DATE.log
$ MV $ LOGDIR / $ f $ LOGDIR / $ f. $ DATE.saved
сделано
cat / dev / null > / Опт / Apache / журналы / access_log
Заменить Cronolog
Не подчеркивайте, что cronolog.org больше не работает или что ни один из сайтов загрузки, которые раньше поставляли Cronolog, больше не перечисляет его. Cronolog был не очень хорош, и вы могли легко написать свою собственную версию всего за пару минут.
Утилиты управления журналами очень полезны, и, несмотря на ограниченные возможности Cronolog, многие системные администраторы стали полагаться на его услуги. Как вы можете видеть из этого обзора, многие другие инструменты управления журналами не только дает вам возможность анализировать файлы журналов по дате, но также дает вам некоторые удивительные возможности визуализации и анализа данных.
Каждая из рекомендаций в нашем списке замен Cronolog можно использовать или попробовать бесплатно. Все эти средства обеспечивают вам лучшее обслуживание, чем самостоятельная репликация Cronolog. Попробуйте любой из этих инструментов и посмотрите, какие из них предоставляют вам дополнительные функции, необходимые для улучшения управления журналами и средствами.

Евгений Холодов
техлид в Dunice
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
- статические анализаторы (ESLint, TSLint, Pylint и др.);
- контейнеризация (Docker, Vagrant и др.);
- различные виды тестирования (функциональное тестирование, тестирование производительности, системное тестирование, модульное тестирование, тестирование безопасности);
- менеджеры зависимостей (npm, yarn, pip и др.);
- логирование + мониторинг;
- менеджеры процессов;
- системные менеджеры.
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.
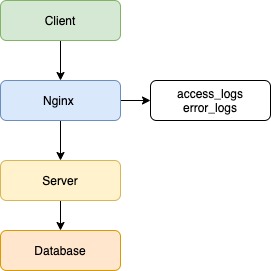
В данном примере не важны язык/фреймворк бэкенда, фронтенда или тип базы данных, а вот про веб-сервер Nginx давайте поговорим. В данный момент Nginx популярнее остальных решений для высоконагруженных сайтов. Среди известных проектов, использующих Nginx: Рамблер, Яндекс, ВКонтакте, Facebook, Netflix, Instagram, Mail.ru и многие другие. Nginx записывает логи по умолчанию, без каких-либо дополнительных настроек.
Логи доступны 2 типов:
- логи ошибок (logs/error.log) — хранят запросы, которые завершились с ошибкой;
- логи доступа (logs/access.log) — хранят информацию обо всех запросах, которые были отправлены на сервер.
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
2020/04/10 13:20:49 [error] 4891#4891: *25197 connect() failed (111: Connection refused) while connecting to upstream, client: 5.139.64.242, server: app.dunice-testing.com, request: "GET /api/v1/users/levels HTTP/2.0", upstream: "http://127.0.0.1:5000/api/v1/users/levels", host: "app.dunice-testing.com"
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.

При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.

В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.

Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.
Теги: devops, системы логирования, логи, graylog, elk, loggy, splunk, mongodb, микросервисы


К логам сервисов и приложений обращаются абсолютно все: администраторы читают логи, чтобы выяснить причину сбоя сервиса; программисты ищут в них исключения; «безопасники» проверяют, что в них нет каких-нибудь необычных записей, характерных для взлома.
Пока у вас один сервер, всё хорошо: каждый специалист может открыть файлы в vim и посмотреть, что ему нужно. А что если серверов у вас много? А что если по этим серверам разбросаны кучи сервисов и приложений? Как людям читать логи со всего этого?
Придётся же читать логи каждого сервиса, каким-то сложным методом находить логи того запроса, что сломался, и искать где именно что-то пошло не так. Как решить эти проблемы?
Существуют популярные системы логирования: Graylog, ELK, Loggy или Splunk
Эти системы занимаются тем, что собирают все логи всех сервисов в централизованное хранилище и предоставляют к нему интерфейс, дающий возможность искать по логам, фильтровать их, строить графики и дашборды.
Что эта система даёт администраторам?
Им больше не нужно подключаться ко всем серверам, достаточно открыть веб-интерфейс системы логирования и в поиске написать название сломанного сервиса. Например, вы вводите слово Mongo и получаете журнал MongoDB со всех своих серверов, с возможностью фильтровать их по полям.
Мы предполагаем, что где-то возникла ошибка, поэтому добавляем фильтр по полю. Указываем, что «критичность логов» должна быть «ERROR», после чего система нам покажет все ошибки с заданной критичностью. Если администратор не исправляет ошибку, а пишет «постмортем» по вчерашней аварии, он также может добавить фильтр по времени и посмотреть логи за весь вчерашний день, за конкретные его часы и т.д.
Что эта система даёт программистам?
В некоторых компаниях программистам не дают доступ к серверам, с этой системой они могут смотреть все интересующие их логи, не заходя в них! Частой проблемой является поиск сервера, на котором произошло исключение. Мы можем просто написать исключение в строке поиска, найти, на каком сервере это произошло, и посмотреть весь его журнал в считанные секунды. Поверх логов с исключениями можно построить график количества исключений в час/день/и т.д., чтобы отследить возрастание ошибок после деплоя и вовремя откатиться на предыдущий релиз.
Что эта система даёт Q/A?
Во-первых, они по логам могут проанализировать, состояние сервисов после прогона тестов – не появилось ли там новых ошибок. Если же ошибки появились, можно передать программисту ссылку на все эти сообщения.
Во-вторых, они могут построить график количества ошибок/предупреждений в логах и на их основе принимать решения, пропускать релиз дальше или нет.
Микросервисы
Это особенный случай. Тут серверов много, на одном сервере может быть несколько одинаковых микросервисов. Какой запрос где сломался, вообще не поймёшь. В таких сложных ситуациях прибегают к практике сквозного логирования, при которой каждому запросу присваивается ID, передающийся от сервиса к сервису на протяжении всей жизни запроса. Этот ID так же добавляют в логи, и когда мы получаем исключение, мы видим не только ошибку, но и в каком конкретно запросе оно произошло.
Вбиваем этот ID в систему логирования и видим полное развитие событий: от начала до конца. Ага, вот запрос прошёл балансировку, вот произошла авторизация пользователя, вот он начал собирать данные, обходя множество микросервисов, и вот тут конкретный микросервис вернул ошибку. Дальше можно проследить и обратную цепочку того, как ошибка прошла весь этот путь обратно и показалась пользователю, но, как правило, это уже не так важно.
Есть вопрос? Напишите в комментариях!